

基础概念
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流(bounded)和无限数据流(unbounded)进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行基于内存快速计算。
特点(Feature)
主要是以下四点:
- 处理有界和无界数据流
Flink 具备统一的框架处理有界和无界两种数据流的能力,下文会详解两种流定义以及区别。
- 部署灵活
Flink集成所有常见的群集资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes),同时也可以作为独立群集运行,这种模式仅仅用来测试或学习时使用。
- 扩展性极高
Flink作业可以利用集群的CPU,主内存,磁盘和网络IO资源来达到以上千个tasks并行执行数万亿的数据,而且轻松维护数TB的程序状态,比如阿里巴巴双11大屏采用Flink 处理海量数据,使用过程中测得Flink峰值可达17亿/秒。
- 内存计算性能高
Flink会将作业状态保留在内存中,若是状态过大,则保留在能够访问到的磁盘中,从而保持低延迟,同时Flink会定时异步持久化状态数据到磁盘上,来保证故障之后一致性问题。
作业(Application)
对于Flink 应用开发需要先理解Streams、State、Time 等基础处理语义以及Flink 兼顾灵活性和方便性的多层次API。
Streams
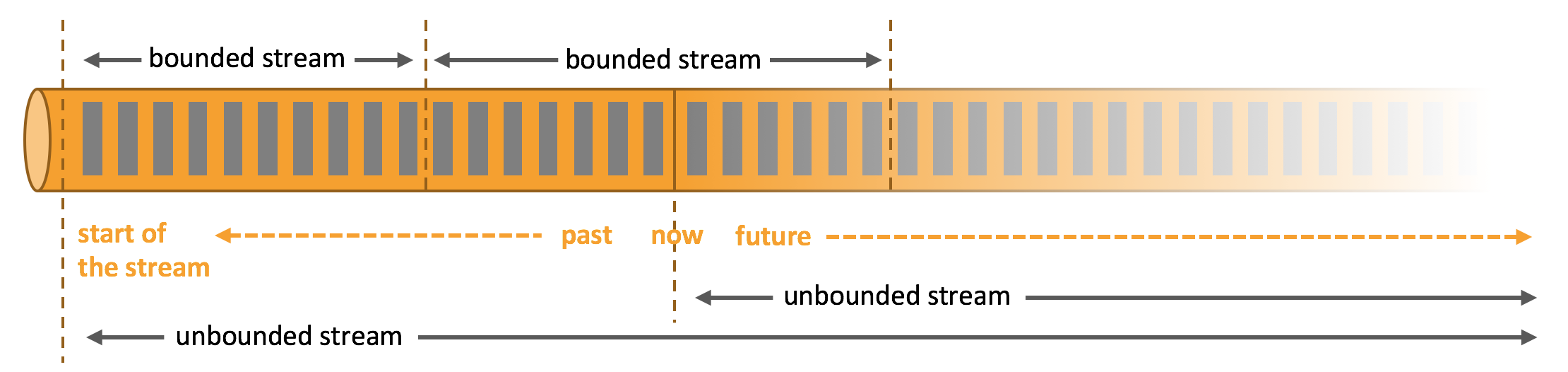
流分为有限数据流与无限数据流,unbounded stream 是有始无终的数据流,即无限数据流;而bounded stream 是限定大小的有始有终的数据集合,即有限数据流,二者的区别在于无限数据流的数据会随时间的推演而持续增加,计算持续进行且不存在结束的状态,相对的有限数据流数据大小固定,计算最终会完成并处于结束的状态。
State
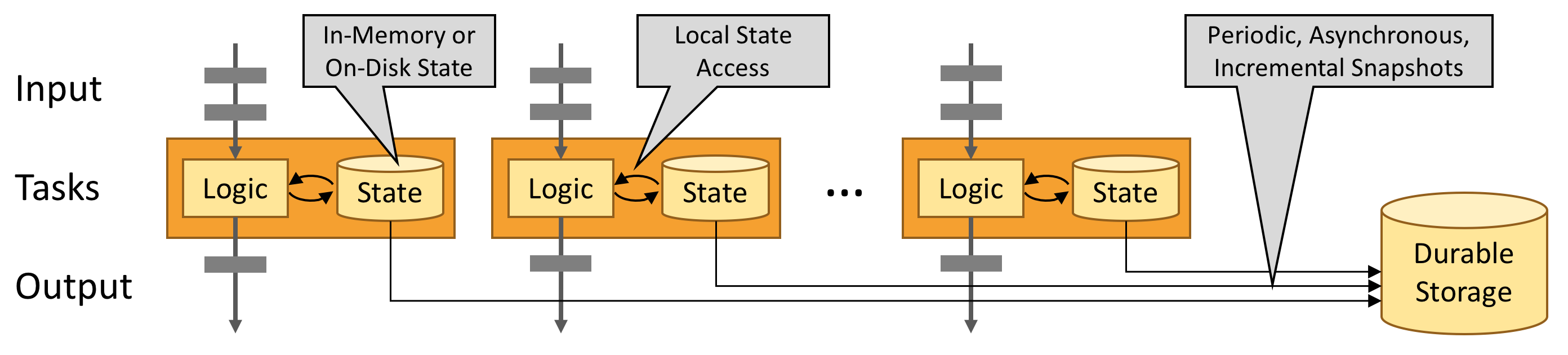
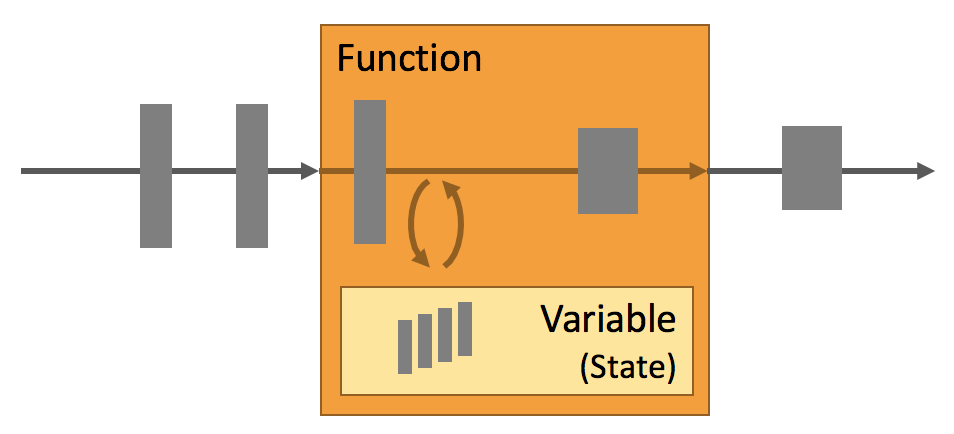
Flink提供状态机制使得作业能够记住中间结果或者一些数据用来之后计算使用,比如流计算的累加操作。状态机制有以下特点:
- 可以使用多种数据结构来存储状态,比如list、map等
- 保证故障之后的一致性问题,允许状态可以存储在内存或者基于磁盘的数据库,比如RocksDB等
- 将状态分发给多个工作节点来提高其扩展性以及状态大小
Time
流处理中大部分操作都于时间相关,比如窗口聚合、基于时间的join、模式检测等,时间又有Event time、Ingestion time、Processing time三类该如何选择来作为流处理的标准。如下图,Event time相当于事件,它在数据最源头产生时带有时间戳,后面都需要用时间戳来进行运算。用图来表示,最开始的队列收到数据,每小时对数据划分一个批次,这就是Event time Process 在做的事情。
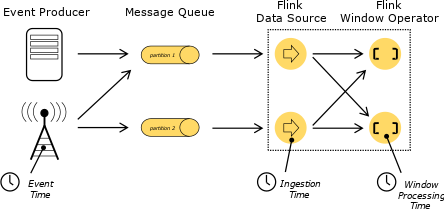
Event time的重要性在于记录引擎输出运算结果的时间。简单来说,流式引擎连续24小时在运行、搜集资料,假设Pipeline里有一个Windows Operator正在做运算,每小时能产生结果,何时输出Windows的运算值,这个时间点就是Event time处理的精髓,用来表示该收的数据已经收到。
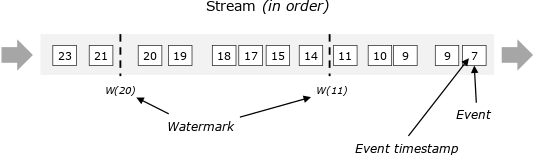
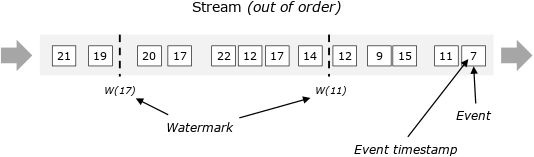
在实际数据流中不可避免就是数据延迟,Flink使用Watermark来解决这个问题,举个例子,假设预期收到数据时间与输出结果时间的时间差延迟5分钟,那么Flink中所有的Windows Operator搜索3点至4点的数据,但因为存在延迟需要再多等5分钟直至收集完4:05分的数据,此时方能判定4点钟的资料收集完成了,然后才会产出3点至4点的数据结果。这个时间段的结果对应的就是Watermarks的部分。
API
API通常分为三层,由上而下可分为SQL/Table API、DataStream API、ProcessFunction三层,API 的表达能力及业务抽象能力都非常强大,但越接近SQL层,表达能力会逐步减弱,抽象能力会增强,反之,ProcessFunction 层API的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。

应用场景(Use Cases)
Data Pipeline
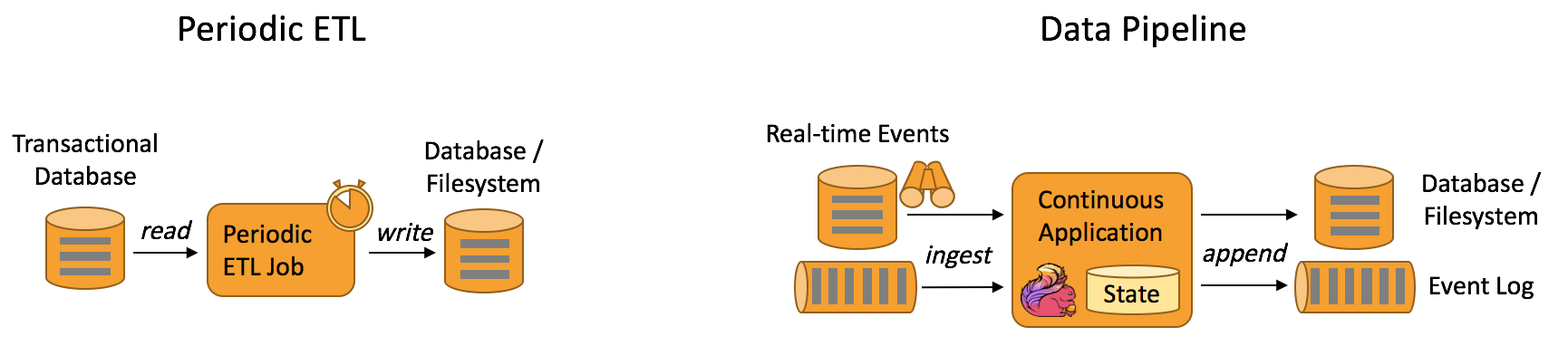
Data Pipeline的核心场景类似于数据搬运并在搬运的过程中进行部分数据清洗或者处理,而整个业务架构图的左边是Periodic ETL,它提供了流式ETL或者实时ETL,能够订阅消息队列的消息并进行处理,清洗完成后实时写入到下游的Database或File system中。场景举例:
- 实时数仓
当下游要构建实时数仓时,上游则可能需要实时的Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时Query。
- 搜索引擎推荐
搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。
Data Analytics
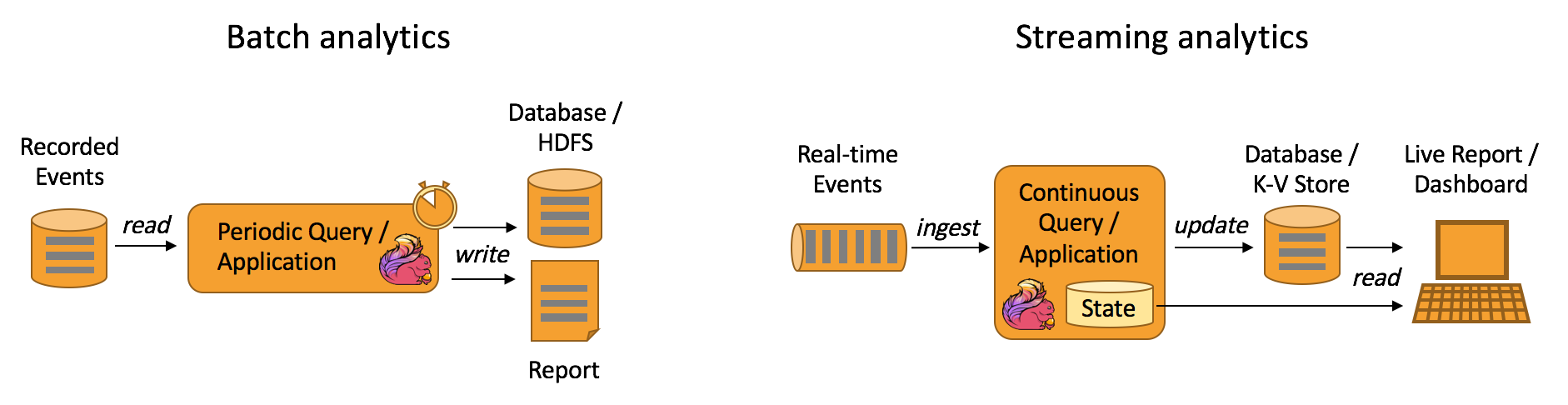
如图,左边是Batch Analytics,右边是Streaming Analytics。Batch Analytics就是传统意义上使用类似于Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表;Streaming Analytics使用流式分析引擎如Storm、Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
Data Driven
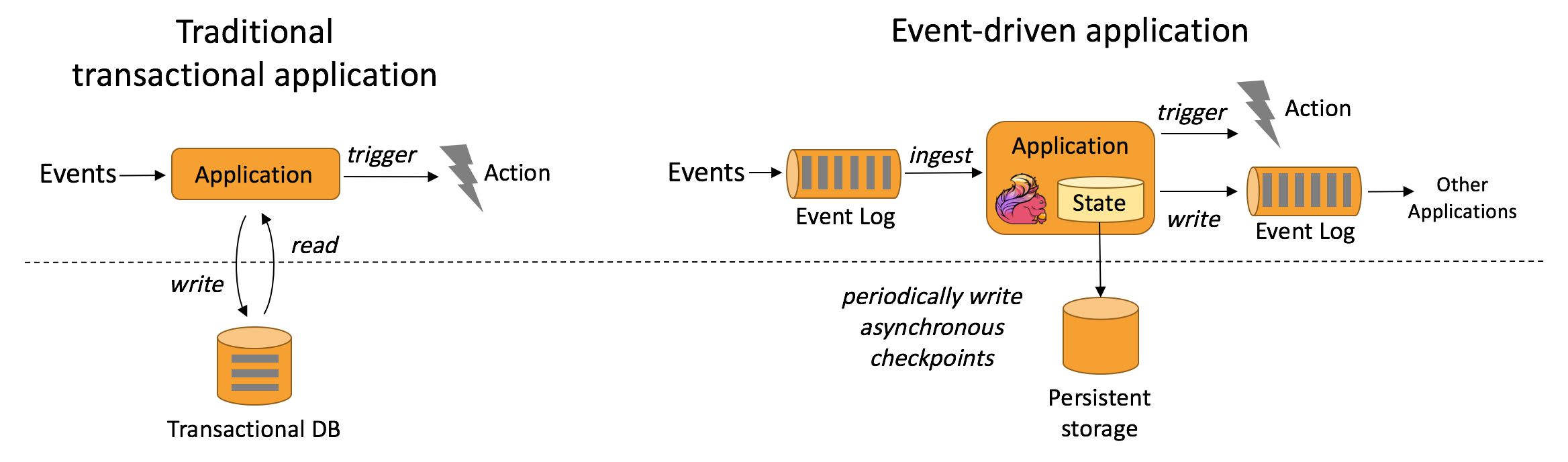
从某种程度上来说,所有的实时的数据处理或者是流式数据处理都是属于Data Driven,流计算本质上是Data Driven计算。应用较多的如风控系统,当风控系统需要处理各种各样复杂的规则时,Data Driven就会把处理的规则和逻辑写入到Datastream的API或者是ProcessFunction的API中,然后将逻辑抽象到整个Flink引擎,当外面的数据流或者是事件进入就会触发相应的规则,这就是Data Driven的原理。在触发某些规则后,Data Driven会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven的应用场景,Data Driven在应用上更多应用于复杂事件的处理。
环境准备
编译
前期准备
由于编译期间网络原因,有些JAR包下载不下来,建议专门去云厂商上按量付费买台国外的服务器去编译,收费不贵一个小时差不多一块钱,使用完销毁就行,之后再在服务器上安装以下工具:
| 工具名称 | 说明 |
|---|---|
| Java | 至少8+版本,官网推荐8u51 |
| Maven | 版本必须得是maven3以上,官网推荐Maven 3.2.5 |
| Git | 用于git clone flink代码 |
代码编译
先在服务器上执行git clone,将flink最新代码拉取到本地:
git clone https://github.com/apache/flink
看官网的小伙伴如果不仔细的话,直接执行mvn clean install命令的话只能得到集成Apache版本的Hadoop,但是一般来说我们都是使用的CDH版本,为了flink能够支持CDH的Hadoop必须在编译时指定Hadoop版本,所以官方推荐先去编译flink-shaded,这里是一个小坑。
先去下载该源码,源码地址在这里,由于是国外服务器不用担心下不下来,之后进入源码中修改pom.xml,加上如下
<repositories>
<repository>
<id>alimaven</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
再去执行以下命令:
# 自己指定version
mvn clean install -Dhadoop.version=2.6.0-cdh5.16.2
⌛️等待flink-shaded编译完成之后,就可以进入flink源码开始编译了,记得也在pom.xml上加上上面的repositories,然后直接执行一行命令就可以编译啦。
# 自己指定version
mvn clean install -DskipTests -Dfast -Dhadoop.version=2.6.0-cdh5.16.2 -Pinclude-hadoop
当然,虽然使用的是国外的服务器但是也会出现个别JAR包下载不下来,这个时候建议去mvnrepository.com/ 搜对应的JAR下载下来放在本地repository对应文件夹中,当然国内用户也可以试试这一招来编译,但是比较费时。
如果小伙伴你的界面出现如下,恭喜你迈出了学习flink的第一步。
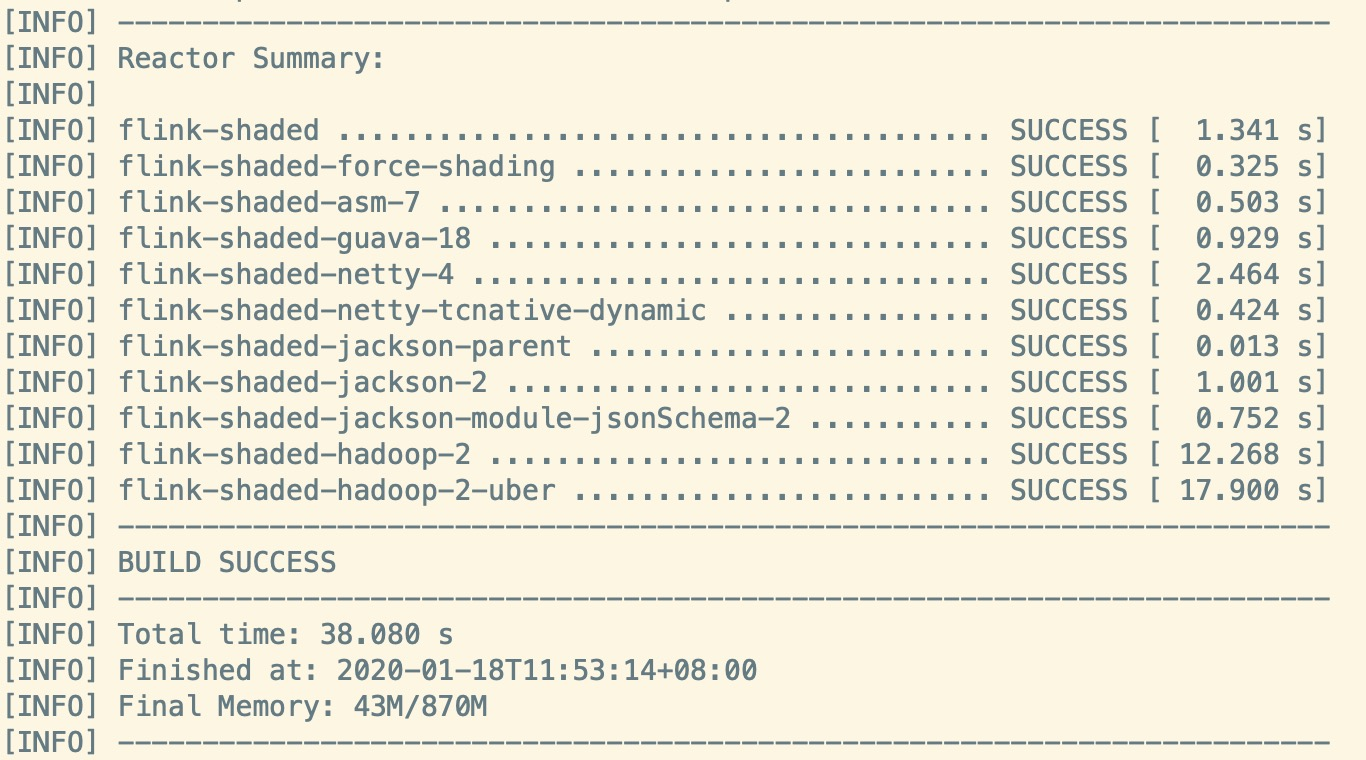
温馨提示:当你编译完之后,目录中会出现一个build的软连接,进入其中会发现没有tar包,需要你自己动手将其build路径下文件夹打成tar包,放在自己Linux机器上。
运行
架构
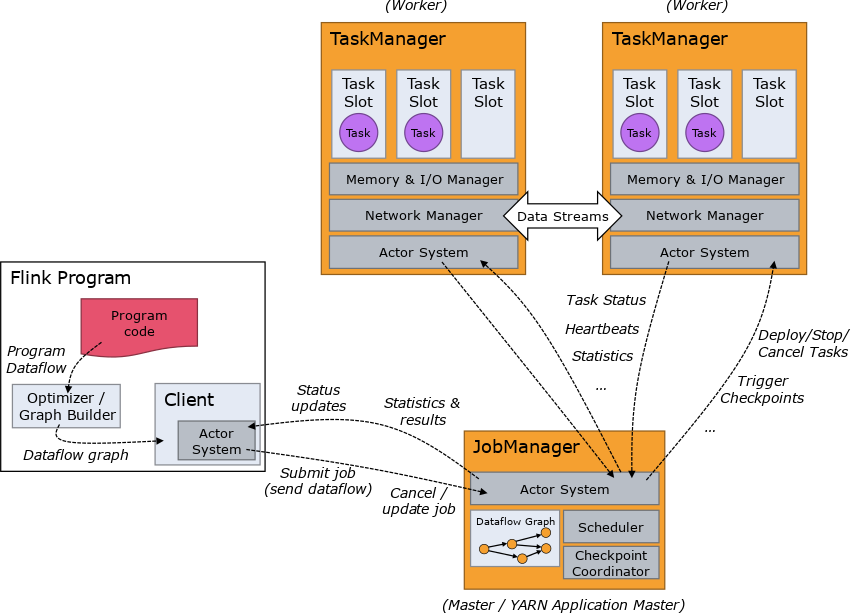
主要包含以下三个角色,通常以Standalone或者Yarn形式运行
- Job Manager(也叫Master):协调分布式作业执行,主要是规划task,管理checkpoint、故障恢复等,支持HA
- Task Manager(也叫Worker):用于执行task,缓存存储和数据交换,其中Task Slot主要是控制Worker能够并行执行多少任务
- Client:提交作业,以命令行bin/flink run...,或者是程序executor()触发
Standalone
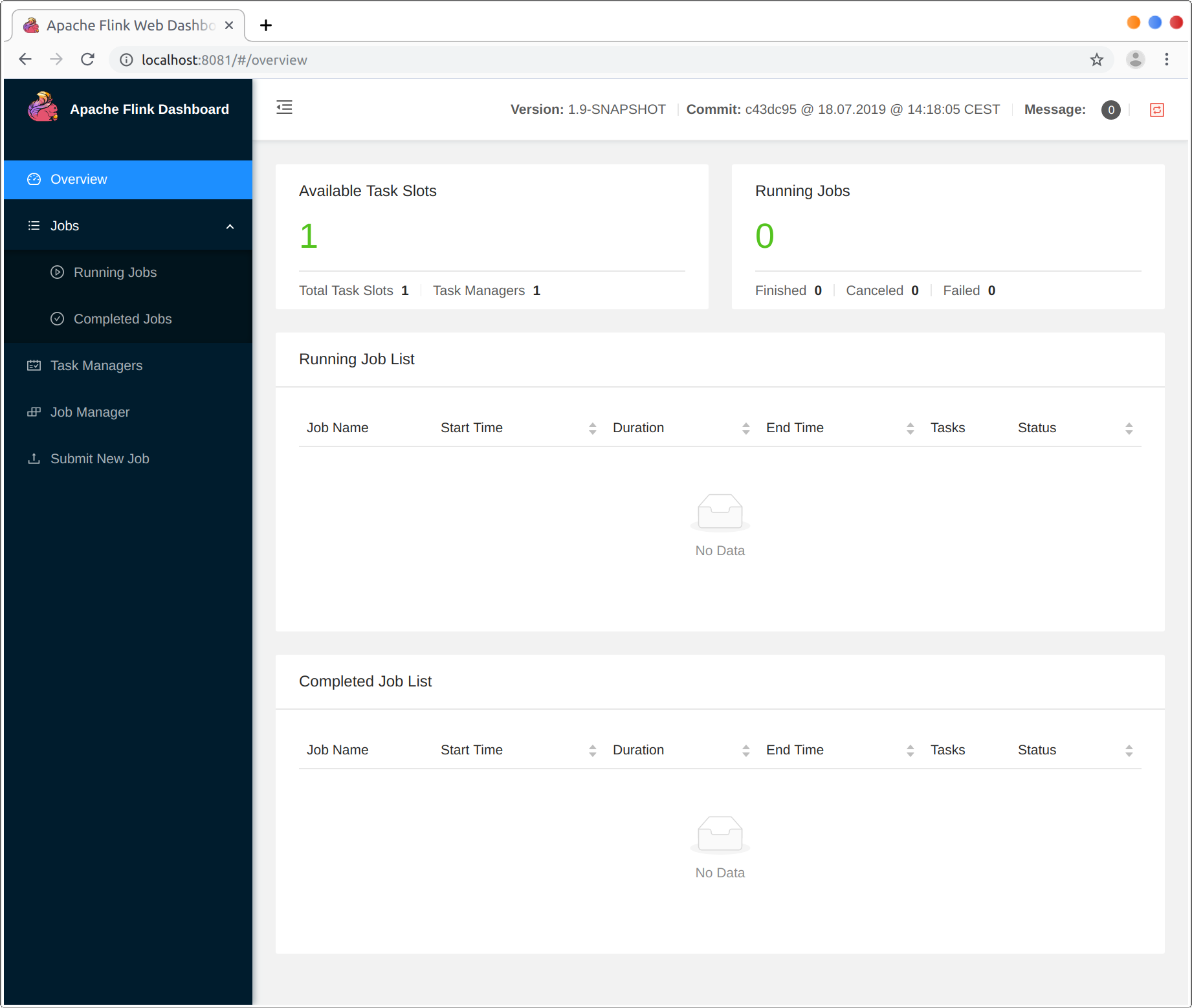
解压tar包,进入目录之后执行bin/start-cluster.sh,不过执行之前请你检查你的JAVA_HOME是否配置,之后浏览器输入 http://localhost:8081 就可以得到如下图的Web UI。
之后运行一个官网提供的运行基于窗口的WordCount示例,先在本机上启动netcat服务,然后再提交JAR:
# 打开netcat服务9000端口
nc -lk 9000
# 提交WC
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
输入测试单词,得到结果如下:
# 测试单词
nc -lk 9000
lorem ipsum
ipsum ipsum ipsum
bye
# 结果
tail -f log/flink-*-taskexecutor-*.out
lorem : 1
bye : 1
ipsum : 4
Yarn
架构图
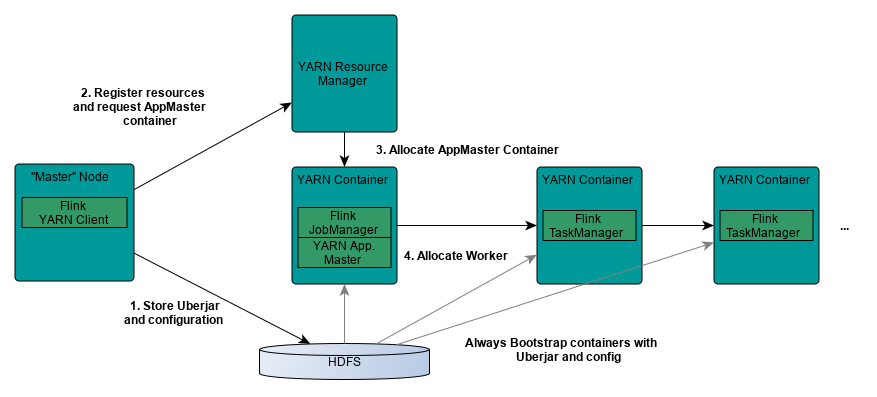
相对于Standalone模式,Yarn模式允许 Flink job的好处有:
- 资源按需使用,提高集群的资源利用率
- 任务有优先级,根据优先级运行作业
- 基于Yarn调度系统,能够自动化地处理各个角色的Failover
1. JobManager进程和TaskManager进程都由Yarn NodeManager监控
2. 如果JobManager进程异常退出,则Yarn ResourceManager会重新调度JobManager到其他机器
3. 如果TaskManager进程异常退出,JobManager会收到消息并重新向Yarn ResourceManager申请资源,重新启动TaskManager
Session Cluster模式
在Yarn上启动Long Running的Flink集群,支持同一Sesion跑不同的作业,该模式主要是减少提交作业时的资源开销。启动命令如下:
# 命令
bin/yarn-session.sh
# 可用选项
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the application on YARN
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
请注意:YARN_CONF_DIR或者HADOOP_CONF_DIR在启动之前必须设置,否则会报错。
其中,如果你不想一直前台保持Client运行,那么你可以选择detached使得后台运行,这样不能被Flink本身停止,只能被Yarn Kill。
提交一个Job到Flink集群:
bin/flink run examples/streaming/WordCount.jar
Job Cluster模式
如果你只想运行单个Flink Job后就退出,那么可以用下面这个命令:
# 命令
bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
# 可用选项
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <arg> Address of the JobManager (master) to
which to connect. Use this flag to
connect to a different JobManager than
the one specified in the
configuration.
-yat,--yarnapplicationType <arg> Set a custom application type for the
application on YARN
-yD <property=value> use value for given property
-yd,--yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,--yarnhelp Help for the Yarn session CLI.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-yj,--yarnjar <arg> Path to Flink jar file
-yjm,--yarnjobManagerMemory <arg> Memory for JobManager Container with
optional unit (default: MB)
-ynl,--yarnnodeLabel <arg> Specify YARN node label for the YARN
application
-ynm,--yarnname <arg> Set a custom name for the application
on YARN
-yq,--yarnquery Display available YARN resources
(memory, cores)
-yqu,--yarnqueue <arg> Specify YARN queue.
-ys,--yarnslots <arg> Number of slots per TaskManager
-yt,--yarnship <arg> Ship files in the specified directory
(t for transfer)
-ytm,--yarntaskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yz,--yarnzookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
上文如有错误或是纰漏,👏欢迎各位下方评论指出,大家一起交流学习📖
