

文章目的
之前写过一篇文章讲连接建立和断开的过程 《TCP:三个角度看connection的建立和结束》。这篇文章中的三张图展示了tcp连接建立过程中的系统调用、建立连接的报文和状态机流转。这些问题归根结底解决的是“TCP连接建立和结束是什么”的问题,下一层次的知识点往往是“为什么这么设计”和“怎么样”,这就是本文要解决的问题。为了避免篇幅过长,文章拆成多篇,本文先讲安全问题下一篇解决为什么问题:)
注意理解本文的内容需要建立在了解TCP连接的过程的基础上,希望读者读到这里快速会议一下TCP连接建立的过程,进行知识预热。
怎么样的问题:从安全角度
要分析连接建立是否安全要再次看一下TCP的连接建立过程,TCP连接建立过程中有个重要的概念叫做backlog,关于backlog其实又是一个常见的TCP面试题。这里就正好通过backlog的展开讲解我们再看一次tcp连接建立里还有什么设计,哪些可能导致安全问题。(注意这里是指TCP连接过程中的安全隐患,而不是说TCP所有设计中的安全隐患)
关于backlog
二看连接建立
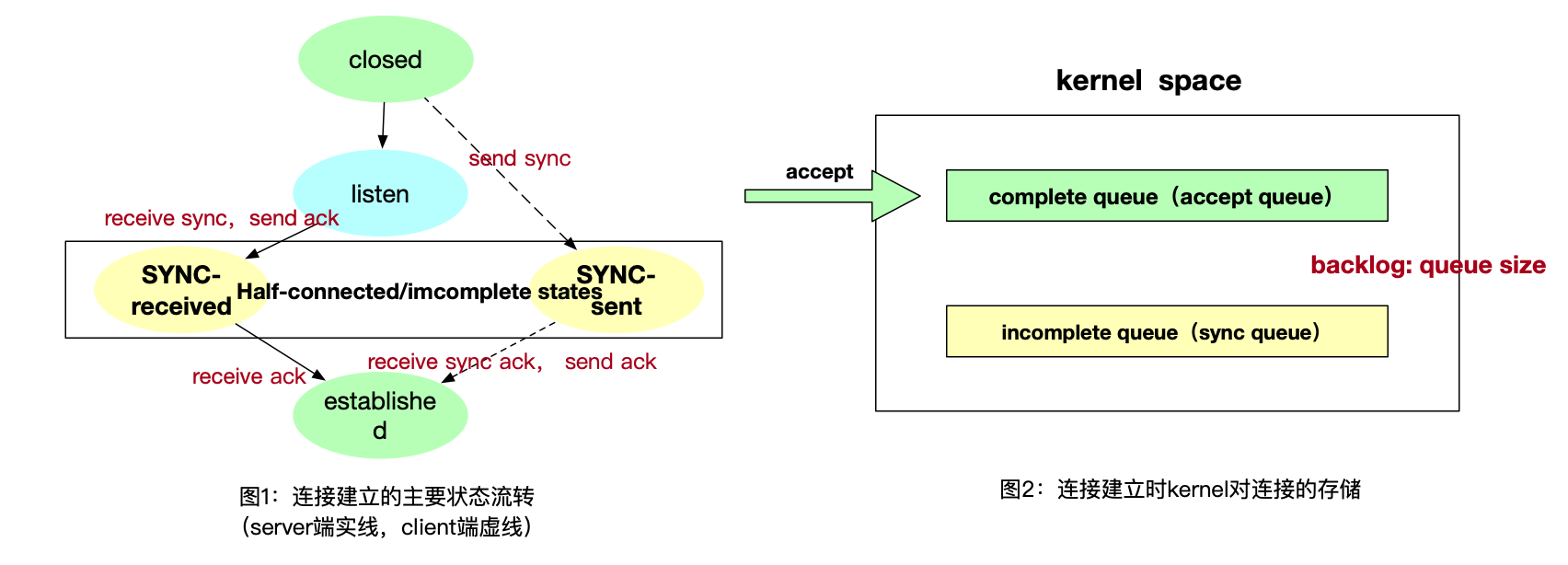
TCP连接的建立过程中,连接会处于中间状态,也就是图1中的黄色状态;accept是不能拿到这种连接的,TCP的连接建立时kernel负责而accept返回的是kernel建立好的连接(accept相关内容参考TCP三个角度这篇文章,有详细解释)。 所以kernel的具体实践者,无论是BSD还是linux,都采用了两个queue区分处于中间状态的,即图二中的两种queue,queue的名称直接对应了存放的连接状态和相关的动作,参考图不赘述。
backlog是什么
凡是遇到queue其实都应该下意识思考队列的容量的设置问题,为了设置kernel的TCP队列容量就有了backlog这个概念。backlog对中国同胞们太有迷惑性了,按中国象形文字设计看到log我们下意识就觉得是一种back的log,有没有!!!然而看看collins对backlog的解释: A backlog is a number of things which have not yet been done but which need to be done. 我来神翻译一下也就是backlog代表一堆要做还没来得及做的事儿!在tcp连接中也就传神的代表了queue size,毕竟没拿走的connection就是没来得及做的事儿么。
看一下队列,有两个队列其实可以有三个size:每个队列的size,和总size。backlog笼统上都可以认为是连接队列的长度上限,但具体的含义在不同的kernel中实现是不一样的:
- kernel老干部BSD中,backlog代表总size,对两个queue对size的分配并没有限制;queue满时BSD系统会直接丢包不回复ack也不回复rst,让对方走timeout机制断开连接;
- kernel最流行之linux中,backlog被细粒度化了,backlog侠义指的是accept队列的长度,sync queue的大小通过tcp_max_syn_backlog来设置;
backlog作用
限制角度
- sync queue超限:快速的网络环境中tcp的建立过程非常快,但网络环境拥堵,c-s距离过长,或者异常的客户端的排队个数往往可能带来sync queue堆积;sync backlog过短会在网络延时或者客户端异常时使得tcp server不可用,因为kernel处理超过queue容量的sync请求的方案普遍是丢掉;但这个值如果设置的过长当一个很长的queue中堆积大量的conn时,kernel的工作线程的workload就增加了,kernel的对每个connection的处理就很难做到很及时,这时候网络正常的连接也要等待很长时间,整个TCP server的速度会下降;
- incomplete queue超限:正常accept queue应该是empty的,连接建立的过程的频率往往远低于用户进程创建socket的频率;如果发生拥堵主要来自于用户进程的处理能力不够或者有bug,accept无法取走连接创建socket;从这个角度讲accept backlog是对user process能力容忍度的衡量;
资源角度
这里再从资源角度看一下backlog
- sync backlog代表了分配给incomplete连接的kernel的一种资源,或者说为了容忍付出的代价;
- incomplete backlog代表了为等待user process占用的客户端时间与分配的系统内存;
从sync backlog引发的安全问题
DDoS
在讲sync backlog的两段话标红了,分析连接时的安全问题主要是指sync backlog, 这个原因是当conn进入complete queue时建立连接过程已经结束了。 红色部分是安全隐患的关键: 如果一个malicious hacker建立了极大数量的incomplete connection一下子打满了sync queue呢,鉴于所有的连接建立都要经历中间态,如果系统分配的资源都被用光了就会...?
分析到这里就进入了大部分博客中直接写的问题了:SYNC Flooding(sync洪泛)和LAND。这两个攻击方法都属于DDoS/DoS 大类(DDoS定义参考 wikihttps://en.wikipedia.org/wiki/Denial-of-service_attack)只是两种的攻击方法不同。
就拿因为新冠病毒闭门在家这个黑天鹅事件为背景举例子。按照目前的国内的口罩产能,或者说是每日能共计到国内的全世界的口罩资源(无论是存量还是新生产的),假设能满足所有人每日拿到3个口罩。(数据假设的- -,为了说明道理),这个资源量大概就像我们分配的sync backlog,正好的量。但是呢大家总担心没有口罩用了,所以大部分人的做法是:我买了200个口罩- -,于是还有一大波人没买到口罩的时候,今日份的口罩就没了- -“口罩已售罄”就像我们的tcp server会无法服务直接丢了包或者返回RST。

其实DDoS这种攻击方法的本质很简单,系统的资源或者说能力是有限的, 想一个办法来用光这种资源 ,系统就挂了。那有了战略,用什么战术就要因“地”制宜了,主要解决两个问题:这个资源是什么,利用什么原理消耗掉这个资源。同时这种攻击可以处于不同层,比如一个httpserver可能在http层会发生DDoS攻击,也可能会在TCP层发生DDoS攻击,机制和防护的方案都不太一样。本文主要讲TCP层的:)
LAND,SYNC flooding
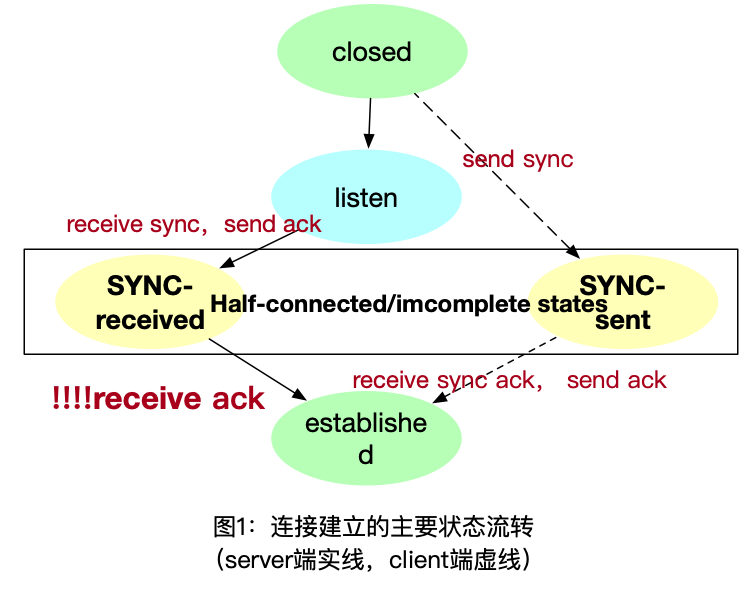
其实讲到这里攻击就显而易见了,攻击方要想办法建立一大堆incomplete states的连接,这里重新祭出图1然后开始反推,逻辑步骤如下:
- incomplete在服务端的状态是sync-received;
- 转化成complete/established的方法是收到ack,所以关键在于不返回ack给server;
- 那么不返回怎么操作呢,大概方向有两个:客户端是“自己人”故意不回,给服务端假地址;
SYNC flooding
sync的方法既可以用客户端是自己人故意不回复的方法,也可以乱给IP。
客户端是恶意的tcp实现
自己的客户端就是不回复ack;但这要怎么做呢,由于自己没当过hacker脑补了一下感觉主要解决以下两个问题,第一个是技术问题,第二个可能要有钱的问题了:
- 不用kernel的TCP,自己基于IP层实现TCP协议的客户端;
- 使用多台机器以解决客户端占用port和socket的资源问题; (具体怎么攻击经济实惠,后续看情况可以深入调研一波来一篇深挖)
随便给IP和port的方案
这种方案比前面的方案简单,只要串改本地host和ip就可以了,而且这种方案不用浪费自己真实的系统资源。 这里机制可行的逻辑是:位置的确认和ip的网络延时使得incomplete connection会持续一段时间,即使乱写ip对应的真实的无辜host返回了RST由于攻击者可以发极大量的乱ip并且对各种乱ip的网络耗时相对大可以在短时间内打满sync queue。
LAND
LAND全称成为local area network denial即局域网拒绝服务。(感觉这个命名有点歧义) 相较与SYNC flooding,LAND的方案感觉更巧妙。这个方法是一种特殊的给错误地址的方式,并产生了意想不到的效果: 如果我地址错到是server自己listen的地址呢,这样资源问题是不是就解决了server会进入死循环反复给自己发sync不断建立新的连接;
开放式结尾
本文遗留一个部分和一些疑问mark在这里,在写作的过程中又引发了自己的深入思考,假如读者有更深入的了解欢迎私聊:
- 遗留的部分:两种attack如何防御;(flag一周内写完)
- 问题关于kernel实现:如果client一个port发N次SYNC不同的ISN,服务端会认为是同一个conn还是2个,如果是2个那么就可以廉价的使用自己的机器sync flooding了?
