

什么是压缩列表
压缩列表 ziplist 在 redis 中的应用也非常广泛,它是我们常用的 zset ,list 和 hash 结构的底层实现之一。当我们的容器对象的元素个数小于一定条件时,redis 会使用 ziplist 的方式储存,来减少内存的使用。
> hset test_hash me sidfate
(integer) 1
> object encoding test_hash
"ziplist"
为什么要在元素较少的时候使用 ziplist ?
因为 redis 中的集合容器中,很多情况都用到了链表的实现,元素和元素之间通过储存的关联指针有序的串联起来,但是这样的指针往往是 随机I/O,也就是指针地址是不连续的(分布不均匀)。而我们的 ziplist 它本身是一块连续的内存块,所以它的读写是 顺序I/O,从底层的磁盘读写来说,顺序I/O 的效率肯定是高于 随机I/O 。你可能会问了,那为什么不都用 顺序I/O 的 ziplist 代替 随机I/O 呢,因为 ziplist 是连续内存,当你元素数量多了,意味着当你创建和扩展的时候需要操作更多的内存,所以 ziplist 针对元素少的时候才能提升效率。
ziplist 如何减少内存使用的呢?
接下来让我们从源码中一探究竟。
源码结构
题外话:每当你想要去探究一个项目的源码的时候,首先应该去看的就是它的注释,好的注释即是文档。同时也告诉我们平时开始也要注意注释的编写。
首先从源码的注释中我们可以了解一些基础信息:
ziplist 是经过特殊编码的双向列表结构,用来提高内存使用效率。它可以储存字符串或者整数值,其中整数值被编码成实际的整数,而不是字符串形式。它可以在 O(1) 时间内对列表的两端进行 push 和 pop 操作。但是,因为每个操作都需要重新分配 ziplist 使用的内存,所以实际的复杂度与 ziplist 使用的内存大小有关。
ziplist 结构的布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
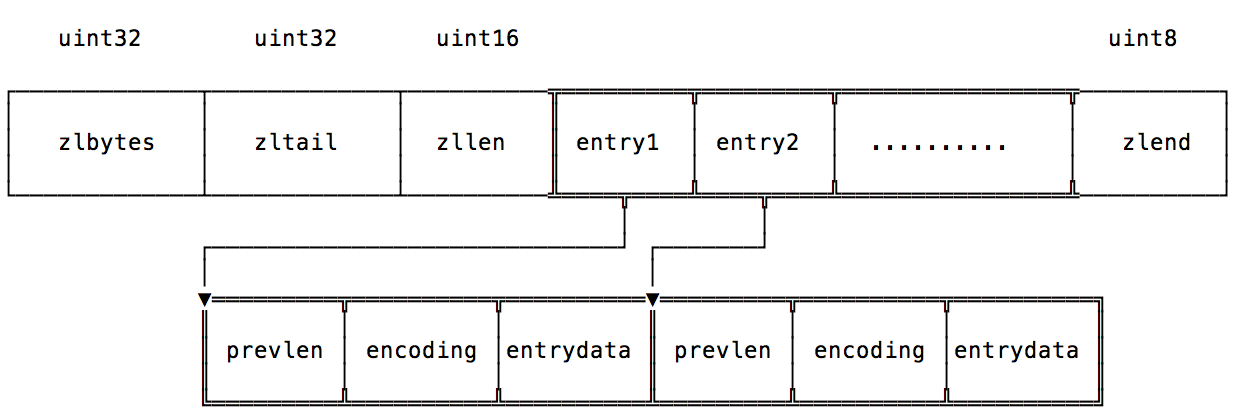
| 属性 | 字节数 | 含义 |
|---|---|---|
| zlbytes | 4 | 压缩列表占用的内存字节数:在对压缩列表进行内存重分配, 或者计算 zlend 的位置时使用。 |
| zltail | 4 | 压缩列表表尾节点的偏移量:用来倒序遍历压缩列表。 |
| zllen | 2 | 记录了压缩列表包含的节点数量: 当这个属性的值小于 UINT16_MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量; 当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry[] | 待定 | 节点数组,包含元素的具体信息 |
| zlend | 1 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ziplist中的每个节点 entry 的结构如下:
<prevlen> <encoding> <entry-data>
redis 为了节约内存在 ziplist 的 entry 这个结构上有很多骚操作,让我来一一说明。
prevlen
prevlen 表示前一个元素的长度,以便能够从后向前遍历列表。它有一套特别的编码方式:如果这个长度小于254字节,那么它占用1个字节;当长度大于或等于254时,占用5个字节,第一个字节被设置为254 (0xFE),其余的4个字节采用前一个条目的长度作为值。prevlen 用 5 bytes表示时,不代表长度一定大于等于254,这是为了减少 realloc 和 memmove 提高效率。
为什么临界值是 254 ?我们来算一笔,一个字节最大能储存值为255,那临界值应该是255啊,别忘了我们还有个 zlend,它的值是0xFF(255),为了避免混淆,所以用254区分。
encoding
encoding 表示元素的编码,它取决于元素的内容。当元素是一个字符串时,编码的第一个字节的前2位将保存用于存储字符串长度的编码类型,然后是字符串的实际长度。当条目是整数时,前2位都设置为1。下面的2位用于指定在这个报头之后将存储哪种类型的整数。对不同类型和编码的概述如下。第一个字节总是足以确定条目的类型。
-
|00pppppp| - 1 字节
长度小于或等于63字节的字符串,63可以用6个字节表示,所以 pppppp 表示字符串的实际长度。
-
|01pppppp|qqqqqqqq| - 2 字节
长度小于或等于16383字节(14 位)的字符串。
-
|10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 字节
长度大于16383(14位)的字符串,后4个字节代表长度。
-
|11000000| - 3 字节
11000000 + int16(2字节)。
-
|11010000| - 5 字节
11010000 + int32(4字节)。
-
|11100000| - 9 bytes
11010000 + int64(8字节)。
-
|11110000| - 4 bytes
11110000 + 24位有符号整数(3字节)。
-
|11111110| - 2 bytes
11110000 + int8(1字节)。
-
|1111xxxx|
极小整数,xxxx 的范围只能是 (0001~1101),也就是1~13,但是因为0000、1110、1111都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数 0~12 就是最终的 value。
-
|11111111|
表示 ziplist 的结束,也就是 zlend 的值 0xFF。
如果你觉得看的混乱了,别慌,上面的不需要全部记住,下面我会用一个鲜活的栗子(官方例子)来总结下。以下是一个包含了字符串 “2” 和 “5” 的压缩列表:
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
| | | | | |
zlbytes zltail zllen "2" "5" end
最前面的4个字节的代表着数字 0x0f = 15(zlbytes = 15),表示这个 ziplist 总共占用了15个字节。紧跟着的4个字节代表数字 0x0c = 12(zltail = 12),说明最后一个元素的偏移量是12,也就是 “5” 这个元素到 ziplist 开头的长度。接着是 zllen = 2,代表总共有2个元素。之后就是实际储存 “2” 和 “5” 的 entry。解读下 “2” 为什么是 00 f3,00表示前一个元素长度为0,因为它是第一个元素,f3 是 0x11110011,也就是我们的 1111xxxx encoding类型,3 - 1 = 2正好是我们的 “2”,“5” 也同理。 最后是 ff 结尾表示结束。
有没有童鞋注意到官方例子总我们储存的是字符串的 “2” 和 “5”,但是 redis 把它当成了整数来储存 ?这一点其实是 redis 故意做的,很多地方都会做类似处理,目的么,还是为了减少内存消耗。
最后我们再看一个储存字符串的例子,我们把上面的 “5” 换成 “Hello World”,那么原先的 “5” 这个 entry 会变成:
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
至于为什么的话,你们就对照的上面的自己试一遍,就当做练习题了。
