

Q1:什么是闭包?闭包的用途是什么?闭包的缺点是什么?
答:
(1)什么是闭包
「函数」和「函数内部能访问到的变量」(也叫环境)的总和,就是一个闭包。闭包形成的原因是外部函数在被调用后,由于其作用域内的变量被内部函数引用所以该部分内存不能释放而被留在内存中。
(function a() {
var local = 1
function closure() {
console.log(local)
}
})()
(2)闭包的作用
如果我们想要得到一个全局变量但是不想在最外面声明它,那么我们就可以通过闭包函数来得到这个变量
function foo() {
var local = 1
function bar() {
local++
return local
}
return bar
}
var func = foo()
func()
这里当我们调用func()的时候就可以得到local+1的值,这里我们其实是用全局函数代替了全局变量 这里有道面试题也用到了闭包
function add(a, b) {
if (arguments.length === 2) {
return a + b
} else if (arguments.length === 1) {
let out = arguments[0]
//这里的out和后面的temp形成闭包
return function temp(num) {
if (arguments.length === 0) {
return out
} else {
out = out + num
return temp
}
}
}
}
这是一个求和函数的重载,里面的out和temp就形成了闭包
(3)闭包的优缺点
优点:闭包可以防止变量污染 缺点:由于外层函数的作用域对象AO无法释放所以会造成内存“泄露”,但是可以手动地把被引用的变量设置为null。还有就是闭包变量不可复用
Q2:call、apply、bind 的用法分别是什么?
它们的共同点
1、都是用来改变函数的this对象的指向的。 2、第一个参数都是this要指向的对象。 3、都可以利用后续参数传参。
不同之处
var exm1={
name : "小王",
gender : "男",
age : 24,
say : function() {
alert(this.name + " , " + this.gender + " ,今年" + this.age);}
}
var exm2={
name : "小白",
gender : "男",
age : 25,
}
如果我们想对exm2调用exm1的say方法,就可以用上述3种方法制定this
- 1.exm1.say.call(exm2,arg1,arg2)
- 2.exm1.say.apply(exm2,[arg1,arg2])
- 3.exm1.say.bind(exm2,arg1,arg2)()
上述几种方法的区别在于,apply参数以数组形式对于say函数形参,而bind返回的是一个函数,我们需要再次调用它,可以在第一次调用传入参数也可以第二次调用的时候传入
Q3:请说出至少 10 个 HTTP 状态码,并描述各状态码的意义。
首先我们可以吧http状态码分成5大类
- 1** 信息,服务器收到请求,需要请求者继续执行操作
- 2** 成功,操作被成功接收并处理
- 3** 重定向,需要进一步的操作以完成请求
- 4** 客户端错误,请求包含语法错误或无法完成请求
- 5** 服务器错误,服务器在处理请求的过程中发生了错误
几个典型状态码
- 100 continue
- 200 OK 请求成功。一般用于GET与POST请求
- 203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
- 301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
- 304 Not Modified 没有变更过
- 305 Use Proxy 使用代理。所请求的资源必须通过代理访问
- 400 Bad Request 客户端请求的语法错误,服务器无法理解
- 403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
- 403 Forbidden 访问禁止
- 406 Method Not Allowed
- 410 Gone 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置
- 414 请求过长
- 500 Internal Server Error 服务器内部错误,无法完成请求
- 504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
Q4:如何实现数组去重?
1.ES6 set
Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构,他们有以下特性
- Set
- 成员唯一、无序且不重复,成员可以是对象或者值
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有:add、delete、has
- 支持filter和map方法
- WeakSet
- 成员都是对象
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存DOM节点,不容易造成内存泄漏
- 不能遍历,方法有add、delete、has
- Map
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
- WeakMap
- 只接受对象作为键名(null除外),不接受其他类型的值作为键名
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有get、set、has、delete
function unique(arr){
return Array.from(new Set(arr))
}
//Set生成的是一个对象,得把他转成数组
//或者
function unique(arr){
return [...new Set(arr)]
}
ES6 提供了新的数据结构 Set它类似于数组,但是成员的值都是唯一的,没有重复的值(set本身是一个构造函数,用来生成 Set 数据结构)
2. 遍历数组
function map(arr){
let result=[]
let hashMap=new Map()
for(let i=0;i<arr.length;i++){
if(hashMap.has(arr[i])){
hashMap.set(arr[i],true)
}else{
hashMap.set(arr[i],false)
result.push(arr[i])
}
}
return result
}
ES6提供的Map数据结构是一种去重哈希表,他与js对象相似,但是他接受一个任意类型的key值,而js对象只能将string作为key,我们用new Map()构造一个哈希表,然后遍历数组,把没出现过的放到一个新数组里,同时把他的值设置为false,当再次遍历到相同元素的时候,我们把他的值设置为true。最后输出一个result去重数组和一个hashMap,hashMap标记了所有重复过的元素,我们还可以将true设置成计数,这样可以记录他重复的次数(Map数据结构的去重判定是看key的求值以后是否相等,期中NaN判定为等于自己,作为一个元素存在,-0和0值相等也作为一个元素存在)
Q5:DOM 事件相关
1.什么是事件委托
通俗的讲,事件就是onclick,onmouseover,onmouseout,等,委托呢,就是让别人来做,这个事件本来是加在某些元素上的,然而你却加到别人身上来做,完成这个事件。
2.事件委托的好处
(1) 可以为同一个DOM元素添加多个同类型事件
其实我们在用element.onclick绑定一个点击事件的时候,如果在同一个元素上挂载了多个click事件,那么后声明的会覆盖之前的事件,但是用addEventListener就可以做到
(2) 可以将事件分成事件捕获和事件冒泡两种机制
addEventListener(type,listener,useCapture),其中type是事件类型,数据类型是字符串, listener是一个事件函数,useCapture是Boolean类型,默认是false(事件冒泡)
-
事件捕获
当一个事件触发后,从Window对象触发,不断经过下级节点,直到目标节点。在事件到达目标节点之前的过程就是捕获阶段。所有经过的节点,都会触发对应的事件
-
事件冒泡
当事件到达目标节点后,会沿着捕获阶段的路线原路返回。同样,所有经过的节点,都会触发对应的事件
通过设置useCapture属性可以控制事件触发的先后,通过事件冒泡原理可以为一个元素的所有子元素绑定同一个事件,将事件绑定在父元素身上,这样即使是点击子元素,在冒泡的时候也会触发父元素的事件。
<script>
window.onload = function(){
let div = document.getElementById('div');
div.addEventListener('click',function(e){
console.log(e.target)
})
let div3 = document.createElement('div');
div3.setAttribute('class','div3')
div3.innerHTML = 'div3';
div.appendChild(div3)
}
</script>
<body>
<div id="div">
<div class="div1">div1</div>
<div class="div2">div2</div>
</div>
</body>
在点击了点击了div1或者div2的时候,冒泡阶段会触发父元素div的点击事件
3.阻止默认动作
var $a = document.getElementsByTagName("a")[0];
$a.onclick = function(e){
alert("跳转动作被我阻止了")
e.preventDefault();
//return false;//也可以
}
可以用e.preventDefault()来阻止默认动作,也可以返回false,他们的区别是 仅仅是在HTML事件属性 和 DOM0级事件处理方法中 才能通过返回 return false 的形式组织事件宿主的默认行为。
4.阻止事件冒泡
function stopBubble(e){
if(e&&e.stopPropagation){//非IE
e.stopPropagation();
}
else{//IE
window.event.cancelBubble=true;
}
}
通过事件的e的stopPropagation函数可以阻止事件冒泡,这样就算你点击触发了本元素的事件也不会向上传递从而触发父元素的事件,当然ie还是要照顾一下的。。。。
5. 考虑一种稍微复杂的事件委托情景,如果有一个页面有如下结构
<ul>
<li>li1
<span>span</span>
</li>
<li>li2</li>
</ul>
ul.addEventListener('click', function(e){
if(e.target.tagName.toLowerCase() === 'li'){
fn() // 执行某个函数
}
})
我们只想用户点击li的时候触发事件,在ul上绑定一个事件委托,如果li中有多个子代那么我们点击span的时候并不会触发li在ul上的事件委托,当结构简单的时候我们可以通过添加if实现,但是如果是动态添加的子代元素呢,所以我们要写一个能实现上述需求的事件委托,并封装一下
function delegate(element,eventType,selector,fn) {
element.addEventListener(eventType,(e)=>{
let el=e.target
while(!el.matches(selector)){
//matches用于匹配节点
if(el===element){
el=null
break
//点击元素的父元素中没有li,返回
}
el=el.parentNode
//判断当前点击元素的父元素是否是li
}
el&&fn.call(el,e,el)
})
return element
}
let ul=document.getElementsByTagName('ul')[0]
delegate(ul,'click','li',(e)=>{
console.log(1)
})
这样当一个子元素被点击时,我们查看其父元素是否存在li也就是我们需要触发的点击事件的元素,如果有则调用事件
Q5:JS 的继承
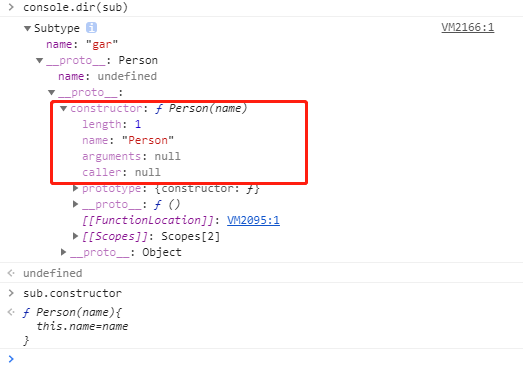
1. 原型链的继承
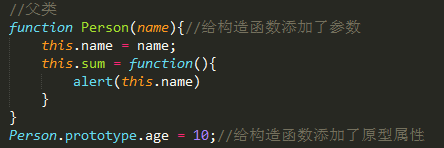
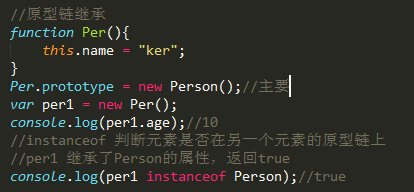
缺点:无法向Person构造函数传参,且改动原型会影响其他实例
2.构造函数继承
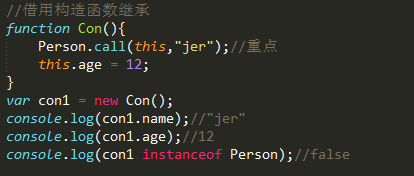
3.组合继承(组合原型链继承和借用构造函数继承)
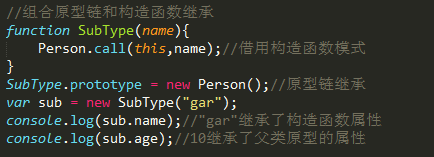
缺点:这里没有修复constructor,这会使得sub实例的constructor是Person而不是SubType
4.原型式继承
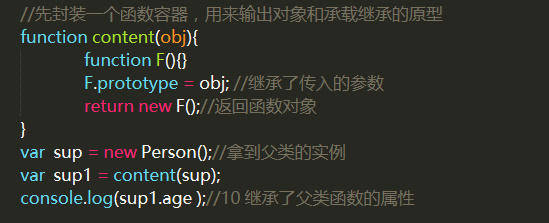
缺点:无法复用,生成的实例需自行添加属性
5.寄生式继承
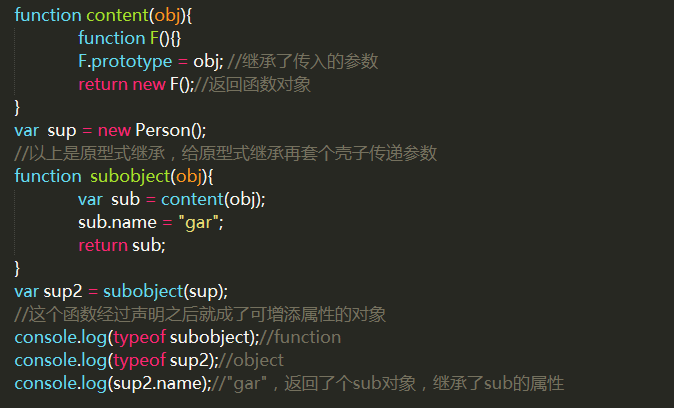
缺点:没用到prototype,无法复用
6.寄生组合式继承
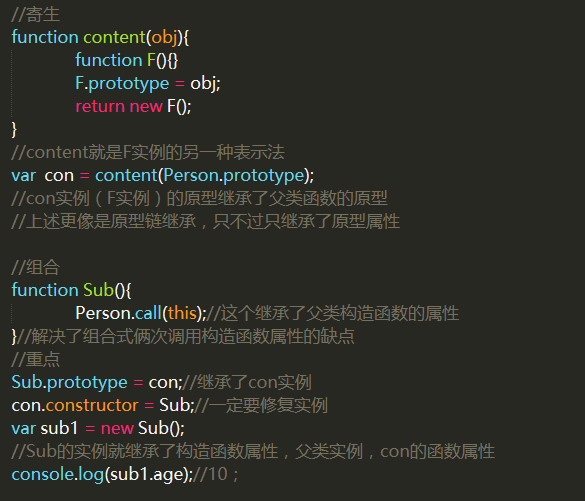
1.生成的实例拥有了原型con,con是一个Person实例,继承原型属性
2.Sub引用了其他构造函数,可以传入参数,可复用
3.修复了con的constructor,使得sub1的constructor属性正确的指向Sub
class的继承
class是es6的新语法,他是构造函数的一个语法糖 使用extend继承其父类原型上的属性和方法
class Parent{
constructor(name){
this.name = name;
}
static sayHello(){
console.log('hello');
}
sayName(){
console.log('my name is ' + this.name);
return this.name;
}
}
class Child extends Parent{
constructor(name, age){
super(name);
this.age = age;
}
sayAge(){
console.log('my age is ' + this.age);
return this.age;
}
}
let parent = new Parent('Parent');
let child = new Child('Child', 18);
这里引用知乎答主若川的一个图来解释
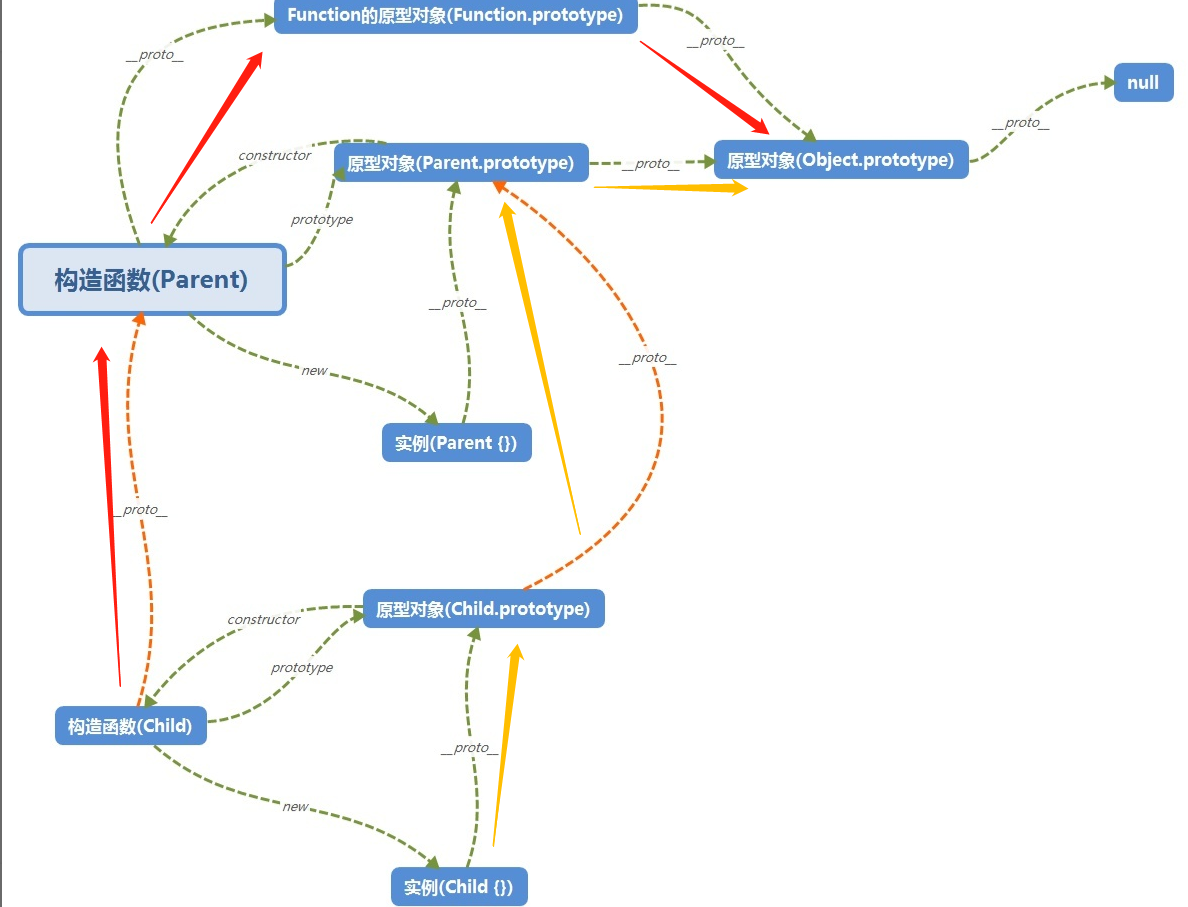

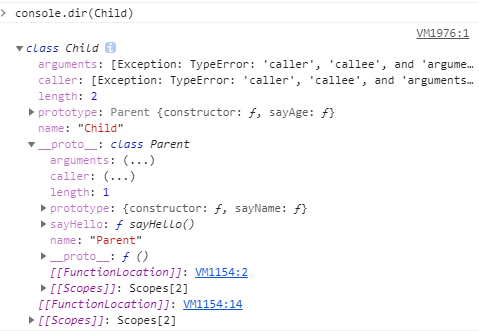
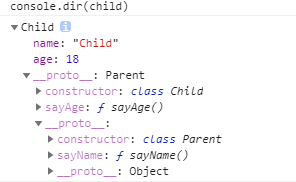
接下来是实例的原型链部分
最后说一说super()的用法,这里的super其实就是上文方法6中的Person.call,且ES6 要求,子类的构造函数必须执行一次super函数。
class A{
constructor(n){
console.log(n); //=>100;
this.x = 100;
}
getX(){
console.log(this.x);
}
}
class B extends A{//=>extends 类似实现原型继承
constructor(){
super(100);//=>类似于call的继承:在这里super相当于把A的constructor给执行了,并且让方法中的this是B的实例,super当中传递的实参都是在给A的constructor传递。
this.y = 200;
}
getY(){
console.log(this.y);
}
}
let f = new B();
console.log(f.x) //100
其实这里的super()相当于A.prototype.constructor.call(this),并且这里的this指向的是B
Q7:排序
计数排序
function sort(arr){
let result=[]
let hashTable={}
let max=0
for(let i=0;i<arr.length;i++){
if(!(arr[i] in hashTable)){
hashTable[arr[i]]=1
}else{
hashTable[arr[i]]+=1
}
if(arr[i]>max){max=arr[i]}
}
for(let j=0;j<=max;j++){
if(hashTable[j]>0){
for(k=0;k<hashTable[j];k++){
result.push(j)
}
}
}
return result
}
Q8:Promise
1.promise用途
ajax发送http请求后会得到一个返回值,有可能是请求成功也有可能是请求失败,为了处理这个失败的情况和统一处理的形式,所以采用了promise来作为一个统一的解决方案
2.创建一个promise
new Promise((resolve,reject)=>{})
整体的一个构造如上,我们构造一个发送ajax的函数,传入method,url,2个参数,然后返回一个Promise构造的对象,他接受两个函数作为参数 当我们调用ajax后返回这个对象,然后对这个对象调用then方法,传入两个函数,前者为成功时调用的函数,后者为失败时调用的函数
ajax = (method, url) => {
return new Promise((resolve, reject) => {
const request = new XMLHttpRequest()
request.open(method, url)
request.onreadystatechange = () => {
if (request.readyState === 4) {
if (request.status < 400) {
resolve.call(null, request.response)
} else {
reject.call(null, request)
}
}
}
})
request.send()
}
p.then(onFulfilled[, onRejected]);
p.then(value => {
// fulfillment
}, reason => {
// rejection
})
前者为成功执行,后者为失败执行
3.promise.all
Promise.all(iterable) 方法返回一个 Promise 实例,此实例在 iterable 参数内所有的 promise 都“完成(resolved)”或参数中不包含 promise 时回调完成(resolve);如果参数中 promise 有一个失败(rejected),此实例回调失败(reject),失败原因的是第一个失败 promise 的结果。
接受参数
一个可迭代对象,如 Array 或 String。或者是一个thenable
Promise.all([1,2,3, Promise.resolve(444)],[])
返回值
(1) 如果传入的参数是一个空的可迭代对象,则返回一个已完成(already resolved)状态的 Promise。 如果只传入一个参数,且此参数为空,则立刻返回已完成状态的Promise对象
Promise.all([])
(2) 如果传入的参数不包含任何 promise,则返回一个异步完成(asynchronously resolved) Promise。 且这些值将被忽略,但仍然会被放在返回数组中(如果 promise 完成的话) 注意:Google Chrome 58 在这种情况下返回一个已完成(already resolved)状态的 Promise。
Promise.all([1,2,3])
(3) 其它情况下返回一个处理中(pending)的Promise。这个返回的 promise 之后会在所有的 promise 都完成或有一个 promise 失败时异步地变为完成或失败。 返回值将会按照参数内的 promise 顺序排列,而不是由调用 promise 的完成顺序决定。
var p = Promise.all([]); // will be immediately resolved
var p2 = Promise.all([1337, "hi"]); // non-promise values will be ignored, but the evaluation will be done asynchronously
console.log(p);
console.log(p2)
setTimeout(function(){
console.log('the stack is now empty');
console.log(p2);
});
// logs
// Promise { <state>: "fulfilled", <value>: Array[0] }
// Promise { <state>: "pending" }
// the stack is now empty
// Promise { <state>: "fulfilled", <value>: Array[2] }
由于Promise.all具有异步性,所以他会等待所有的参数都处在已完成才会返回结果,或者是当有任何一个参数返回reject则会异步的返回第一个错误项的返回值,但是他的返回值都是异步的,你可以将它写入一个setTimeout函数中去执行他。
var p = Promise.all([1,2,3]);
var p2 = Promise.all([1,2,3, Promise.resolve(444)]);
var p3 = Promise.all([1,2,3, Promise.reject(555)]);
setTimeout(function(){
console.log(p);
console.log(p2);
console.log(p3);
});
// logs
// Promise { <state>: "fulfilled", <value>: Array[3] }
// Promise { <state>: "fulfilled", <value>: Array[4] }
// Promise { <state>: "rejected", <reason>: 555 }
(4)快速返回失败 Promise.all 在任意一个传入的 promise 失败时返回失败。例如,如果你传入的 promise中,有四个 promise 在一定的时间之后调用成功函数,有一个立即调用失败函数,那么 Promise.all 将立即变为失败。
4.Promise.race
Promise.race(iterable) 方法返回一个 promise,一旦迭代器中的某个promise解决或拒绝,返回的 promise就会解决或拒绝。 语法上跟Promise,all差不多,他也具有异步性,他的侧重点在于race,也就是比比谁更快,他会返回第一个完成的迭代参数,从而返回他的结果,可以使resolve或者reject,一般配合setTimeout使用
var p1 = new Promise(function(resolve, reject) {
setTimeout(resolve, 500, "one");
});
var p2 = new Promise(function(resolve, reject) {
setTimeout(resolve, 100, "two");
});
Promise.race([p1, p2]).then(function(value) {
console.log(value); // "two"
// 两个都完成,但 p2 更快
})
这里是失败调用
var p5 = new Promise(function(resolve, reject) {
setTimeout(resolve, 500, "five");
});
var p6 = new Promise(function(resolve, reject) {
setTimeout(reject, 100, "six");
});
Promise.race([p5, p6]).then(function(value) {
// 未被调用
}, function(reason) {
console.log(reason); // "six"
// p6 更快,所以调用他的失败函数
});
5. async / await
async 和await其实本质上就是promise的一个语法糖,是为了简化其写法而诞生的
async
async修饰的函数是一个异步函数,用法跟别的函数没区别,仅仅是异步而已。
(async function f() {
console.log('123');
console.log('321');
throw '666';
})().then(success=>{
console.log(success);
},reject=>{
console.log('e6');
})
console.log('xxx')
输出结果
123
321
xxx
e6
当函数执行时,先打印了'123'和'321'然后跑出错误,异步调用reject,所以不会立刻打印'e6',接着执行'xx'的打印,最后打印出'e6'
async修饰的函数是一个异步函数,如果代码中有return <非promise>语句,JavaScript会自动把返回的这个value值包装成promise的resolved值;调用就像普通函数一样调用,但是后面可以跟then()了
await
await只能在async中使用,必须等待直到一个promise执行并返回它的结果,JavaScript才会继续往下执行,他可以修饰一个promise对象,也可以是一个普通函数或者变量
async function f0() {
console.log('888');
return 'done0';
}
async function f1() {
console.log('777');
return 'done1';
}
(async function f2() {
console.log('123');
await f0().then((data)=>{console.log(data)});
await f1().then((data)=>{console.log(data)});
console.log('321');
throw '666';
})().then(data=>{
console.log(data)
},error=>{
console.log('e6')
});
console.log('456');
输出结果
123
888
456
done0
777
done1
321
e6
首先执行123,然后执行f0中的888打印,接着调用f0的resolve方法,参数为done0,由于是异步因此交出执行权,456打印,任务队列为空,执行异步回调,打印出done0,此时f1才得以调用,打印777,调用f1的resolve方法,打印done1,接着打印321,最后调用async的reject方法,打印出e6
async能保证函数的返回值一定是一个promise对象,所以他可以在class中使用来构造一个promise对象
class Waiter {
async wait () {
return await Promise.resolve(1)
}
}
new Waiter().wait().then(alert) // 1
最后用阮一峰的3幅图比较一下连续回调地狱,promise,async/await 3者的直观区别

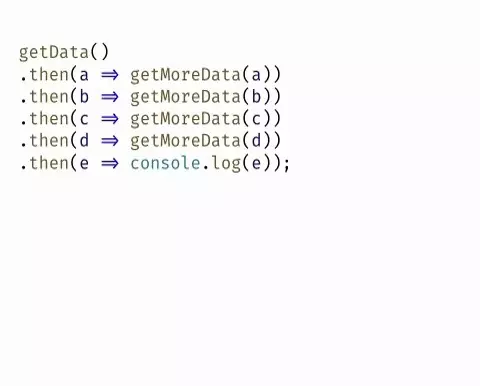

最后由于图二中最后可以接一个.catch()捕获错误,但是async中可以用try(),catch()
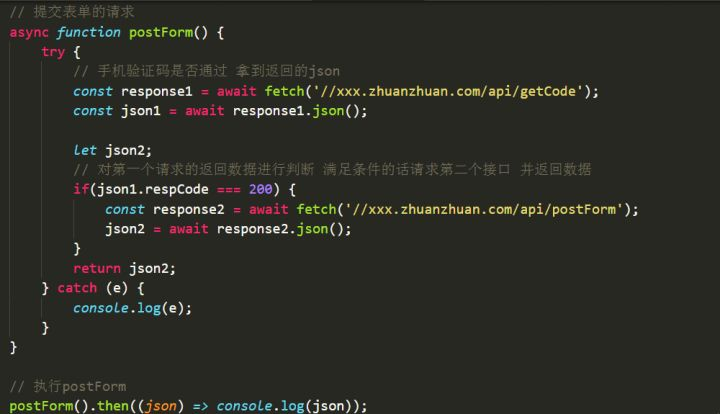
最后我们来试着手写一个Promise
class Promise2 {
succeed = null
fail = null
state = 'pending'
//用来存储then传入的处理函数
resolve(result) {
setTimeout(() => {
this.state = 'fulfilled'
if (this.succeed) {
this.succeed(result)
} else {
throw new Error('succeed is undefined')
}
}, 0)
}
//将resolve封装成异步操作,并改变state的值
reject(result) {
setTimeout(() => {
this.state = 'rejected'
if (this.fail) {
this.fail(result)
} else {
throw new Error('reject is undefined')
}
},0)
}
constructor(fn) {
fn(this.resolve.bind(this), this.reject.bind(this))
}
//new Promise2的时候接受一个参数fn,他的两个行参分别赋给resolve和reject
then(succeed, fail) {
this.succeed = succeed
this.fail = fail
}
}
//调用then方法的时候传入真实的成功与失败函数
Q9:跨域
1. 同源
什么叫做源,当一个url的协议,域名,端口部分都确定,那么他就是一个源,当两个url的这3部分都相同,他们就是同源。
2.跨域
跨域也叫跨源,这是浏览器为了保护用户信息安全而采取一种强制的访问限制,浏览器不允许不同源之间的ajax请求,但是带src属性的表情如<script>,<img>,<iframe>等都拥有跨域的功能,由于浏览器对js引用不做跨源限制,所以就引出了跨源的一种解决方案,JSONP,另外一种是cors
3.cors
cors是浏览器支持的一种跨域方法,当服务器返回一个响应的时候,在请求头中加入一句就可以使得发出请求的用户得到返回的内容,注意的是要制定上面的源的3要素,且只能是http协议
response.setHeader("Access-Control-Allow-Origin", "http://exam.com:port");
cors分为两种,简单请求和非简单请求
(1)简单请求
条件
- 请求方法时GET HEAD POST中的一种
- HTTP的头信息不超出以下几种字段:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
流程
对于简单请求,浏览器直接发出CORS请求。具体来说,就是在头信息之中,增加一个Origin字段,该字段用于服务器端识别该源是否允许跨域访问
GET /cors HTTP/1.1
Origin: http://api.bob.com
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0.
如果该源在服务器许可名单中,则返回的响应头中会有以下信息
Access-Control-Allow-Origin: http://api.bob.com
//该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求
Access-Control-Allow-Credentials: true
//该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。
//浏览器端ajax设置xhr.withCredentials = true;才会发送cookie
Access-Control-Expose-Headers: FooBar
//该字段可选。Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma之外的字段需要手动指定
//getResponseHeader('FooBar')
Content-Type: text/html; charset=utf-8
(2)非简单请求
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求的主要区别就是,会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求(preflight)。
//ajax请求
var url = 'http://api.alice.com/cors';
var xhr = new XMLHttpRequest();
xhr.open('PUT', url, true);
xhr.setRequestHeader('X-Custom-Header', 'value');
xhr.send();
浏览器发现这是个PUT类型请求,属于非简单请求,先发出一个预检请求
OPTIONS /cors HTTP/1.1
//options表示这不是正式请求
Origin: http://api.bob.com
Access-Control-Request-Method: PUT
//表示这是个PUT请求
Access-Control-Request-Headers: X-Custom-Header
//表示我额外添加的头信息字段
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...
服务器接收到这个预检请求后发出回应,允许或拒绝浏览器的请求,如果是拒绝则返回一个正常HTTP回应但不包含cors相关的头部信息,这时候浏览器默认请求拒绝,触发onerror
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
//3个allow明确浏览器可以请求的源,方法,和头部
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
通过了预检请求后,之后浏览器发送请求就跟简单请求无异
4. AJAX
AJAX其实就是用JS发送一个HTTP请求,但是AJAX是不能跨域的
当发送一个AJAX请求时,浏览器会查看请求的url是否和当前url同源,如果跨源,则在请求头中加上一个origin,内容是当前的url,服务器端接受到请求后,根据origin来判断是否应该给这个源返回数据,他会在回应头中添加access-control-allow-origin属性,当浏览器收到回应后,查看是否有此属性,若没有则拦截数据,这就是cors的原理
var request = new XMLHttpRequest()
request.open('GET', '/a/b/c?name=ff', true);
request.onreadystatechange = function () {
if(request.readyState === 4 && request.status === 200) {
console.log(request.responseText);
}};
request.send();
或者
var request = new XMLHttpRequest()
request.open('GET', '/a/b/c?name=ff', true)
request.onload = ()=> console.log(request.responseText)
request.send()
用promise来对其进行一个封装
function getJSON (url) {
return new Promise( (resolve, reject) => {
var xhr = new XMLHttpRequest()
xhr.open('GET', url, true)
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
if (this.status === 200) {
resolve(this.responseText, this)
} else {
var resJson = { code: this.status, response: this.response }
reject(resJson, this)
}
}
}
xhr.send()
})
}
5.JSONP(JSON padding)
当然cors很好用,但是无敌的ie他不支持啊,咋办,用JSONP 上面也说了,浏览器对于js的引用没有跨域限制,应该说有用src属性的标签都有跨域的能力,所以我们用浏览器去请求一个js文件,然后让目标服务器将我们需要的数据作为参数写到这个js文件的一个函数中并调用这个函数,但是这个函数还没有定义,所以我们在请求方的js文件中定义这个函数,等待被调用,这就是一个回调函数,当然你可以在这个回调函数中自定义数据处理方法。同时我们可以在服务器端referer来建立一个白名单,用于筛选允许访问的目标请求
//发起请求的部分
function jsonp(url) {
return new Promise((resolve, reject) => {
const random = "frankJSONPCallbackName" + Math.random();
window[random] = data => {
resolve(data);
};
const script = document.createElement("script");
script.src = `${url}?callback=${random}`;
//这里发起的请求是浏览器发起的,ajax是js发送http请求
//?后面的部分就是query,query.callback就是random
script.onload = () => {
script.remove();
};
script.onerror = () => {
reject();
};
document.body.appendChild(script);
});
}
//JSONP和AJAX的目的是相似的,就是跨域获取文件
//如果都是跨域,那我们可以cors解决,可以浏览器或者ajax发请求,但是ie只能用jsonp解决
jsonp("http://qq.com:8888/friends.js").then(data => {
console.log(data);
})
//server.js部分
if (request.headers["referer"].indexOf("http://frank.com:9999") === 0) {
//这里是JSONP部分,用refer检查可以筛选可以访问我数据的人有哪些
response.statusCode = 200;
response.setHeader("Content-Type", "text/javascript;charset=utf-8");
const string = `window['{{xxx}}']({{data}}) `//fs.readFileSync("./public/friends.js").toString()
const data = fs.readFileSync("./public/friends.json").toString();
const string2 = string.replace("{{data}}", data).replace('{{xxx}}', query.callback);
response.write(string2);
response.end();
//请求的js文件(friend.js)
window['{{xxx}}']( {{data}} )
//直接调用这个函数,函数部分在发起端定义,等待回调
JSONP的优缺点
优点:可以兼容ie
缺点:无法返回状态码和请求头,也无法进行POST请求
6. 服务器中转

由于服务器并不存在跨域的问题,跨域是浏览器对请求的限制,因此我们可以将请求发送到个人服务器上,然后让个人服务器去请求目标服务器资源,最后让个人服务器返回给浏览器数据
Q10:变量提升和函数提升
变量提升即将变量声明提升到它所在作用域的最开始的部分
而创建函数有两种形式,一种是函数声明,另外一种是函数字面量,只有函数声明才有变量提升
console.log(a) // f a() { console.log(a) }
console.log(b) //undefined
function a() {
console.log(a)
}
var b = function(){
console.log(b)
}
这里b并没有和a一样整体提升到头部,相当于这样
var a = 'function'
var b //只声明未定义
console.log(a)
console.log(b)
变量提升
console.log(c); //undefined
var c = "第一次没打印出来,第二次才出来";
console.log(c); //第一次没打印出来,第二次才出来
function fn(){
console.log(d); //undefined
var d = '第二次打印';
console.log(d); //第二次打印
}
fn();
这里相当于这样
var c ;//只声明未定义
console.log(c)
c = " xxxx "
console.log(c)
优先级问题
console.log(a); // f a() {console.log(10)}
console.log(a()); // undefined
var a = 3;
function a() {
console.log(10) //10 返回值是undefined
}
console.log(a) //3
a = 6;
console.log(a()); //a is not a function;
相当于
var a = funtion () {
console.log(10)
}
var a;
console.log(a); // f a() {console.log(10)}
console.log(a()); // undefined
a = 3;
console.log(a) //3
a = 6;
console.log(a()); //a() is not a function;
由此可见
- 函数提升优先于变量提升
- 函数不会被同名变量声明所覆盖
- 但是会被后续赋值所覆盖
