

前言
- Cache_t 是用来干嘛的?
- 探究Cache_t 的方法有些?
- Cache 的最终流程是什么样的?
Cache_t 用来干嘛的?
从名字中Cache 就可以看出 是用来缓存的。那么是缓存什么的呢?成员变量?属性?方法?协议? 说到这里自然就想到我们在汇编底层方法查询的时候先走的快速查找,然后进入c 和 c++ 一起混写的底层进入慢速查找流程。那么我猜测大概率是方法吧,接下来我们来看一看到底存的是什么。
前提知识
- object_class 的结构

Cache_t 的探究
- LLDB
在此处打断点,我们通过 x pClass 拿到objc_class 的地址

我们拿到首地址之后进行 内存地址的偏移,我们通过 object_class 可以看出,内存偏移 16 个字节就能拿到 cache_t 的内存地址。拿到内存地址之后我们强转一下,查看内部的结构。
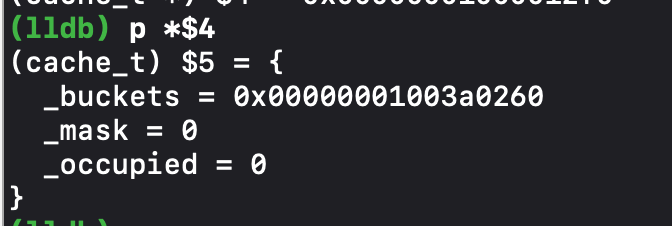
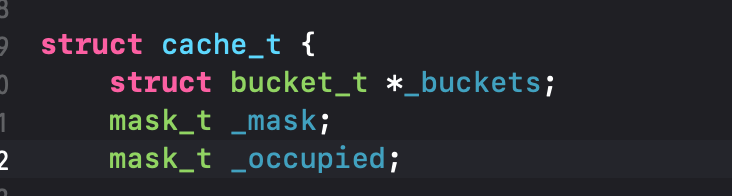
这里因为是强转当然是一摸一样的啦 😄
我们我们再通过LLDB 看到buckets 里面的内容我们看见具体的值
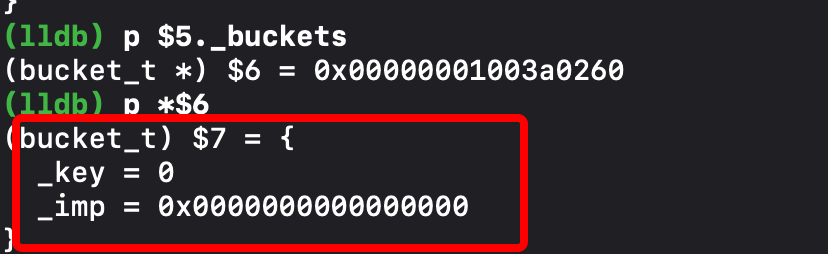
我们看到imp , key ? 不是方法里面三个比较重要的元素里面的方法编号和方法实现吗。那大概率是缓存的方法了。但是为什么 为0 ,还有 0x0 呢? 啥都没有?为啥呢?出啥错了?
当然没有了,因为我们还没有调用任何对象的方法,当然没有缓存啦,接下来我们代码继续走下去。走到第二句[person sayHello]。 我们在此处打个断点,同样的操作,我们打印出里面的东西看一下。
我们注意一下变化:
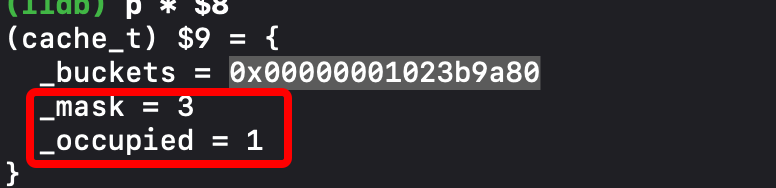
重点来了,我们看到_occupied 从 0 变成了1。正巧的是我们方法也走了一个。貌似可以肯定里面缓存的肯定是方法了。不过我们还是再看看到底是不是!我们继续 LLDB! 打印出 _buckets.
有东西了!! 原来是 0 ,看log。

到这里,我们就基本确定里面是存放的方法了。
方法二
我们都知道Class 是结构体指针。那么我们接下来自定义一下结构体指针,仿着写一下。
typedef uint32_t mask_t;
typedef uintptr_t cache_key_t;
typedef unsigned long uintptr_t;
struct lb_bucket_t {
IMP _imp;
cache_key_t _key;
};
struct lb_cache_t {
struct lb_bucket_t *_buckets;
mask_t _mask;
mask_t _occupied;
};
struct lb_class_data_bits_t {
uintptr_t bits;
};
struct lb_objc_class {
Class ISA;
Class superclass;
struct lb_cache_t cache; // formerly cache pointer and vtable
struct lb_class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
};
接下来我们在 探究代码中写入这些代码:
struct lb_objc_class *lb_pClass = (__bridge struct lb_objc_class *)(pClass);
for (mask_t i = 0; i<lb_pClass->cache._mask; i++) {
struct lb_bucket_t bucket = lb_pClass->cache._buckets[i];
NSLog(@"%lu - %p",bucket._key,bucket._imp);
}
我看看打印

我们是不是同样的也拿到了 相应的key 和 imp ?
综上
我们可以得知cache_t 里面存的是方法。
缓存的算法是什么样子呢?
在进入之前我们先来看上面,我们一开始只打印了 三个 key -- imp 吧。那么我们接下来多调用四五个方法,再输出打印一下,看一下有什么不同~
那么对应的打印呢?

我们再来看一下LLDB 对应的打印
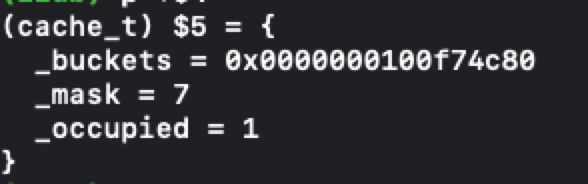
到这里大家对 _buckets 有什么想法呢?我们稍后再说~
这个时候我们发现打印的条数变多了,对应的就是mask 变多了吧。我们来猜一下,是不是很像数组的动态扩容?
我们继续看LLDB 打印出的方法:

我们再看看 mach-o ,对应上了~ 😄

我们可以看到这里有个调用方法:寻找方法


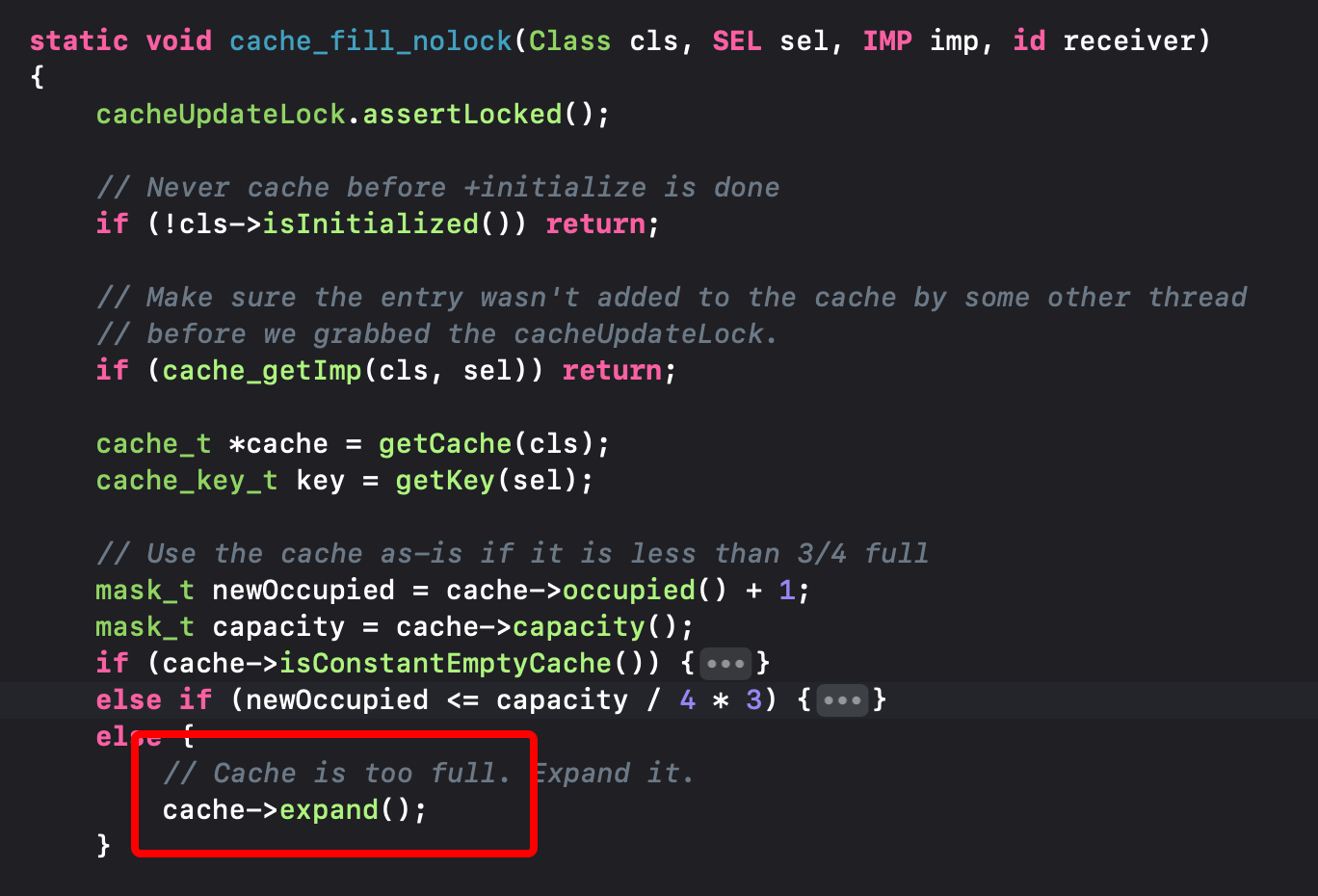
至此,我们看到了调用的方法~ ✌️
我们就可以打断点看了。
我们继续阅读代码
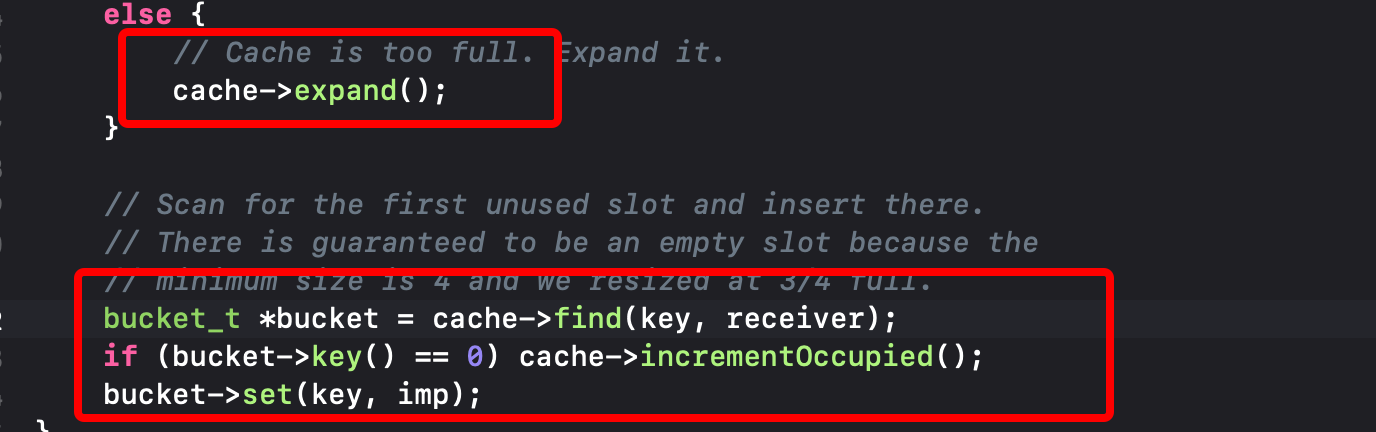
先扩容,然后进行填充!
我们先看看扩容代码:

void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity)
{
bool freeOld = canBeFreed();
bucket_t *oldBuckets = buckets();
bucket_t *newBuckets = allocateBuckets(newCapacity); // 分配一个新的buckets
// Cache's old contents are not propagated.
// This is thought to save cache memory at the cost of extra cache fills.
// fixme re-measure this
assert(newCapacity > 0);
assert((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1);
setBucketsAndMask(newBuckets, newCapacity - 1); // 设置新的,但是并没有拷贝以前的
if (freeOld) { // 释放旧的
cache_collect_free(oldBuckets, oldCapacity);
cache_collect(false);
}
}
bucket_t *allocateBuckets(mask_t newCapacity)
{
// Allocate one extra bucket to mark the end of the list.
// This can't overflow mask_t because newCapacity is a power of 2.
// fixme instead put the end mark inline when +1 is malloc-inefficient
bucket_t *newBuckets = (bucket_t *)
calloc(cache_t::bytesForCapacity(newCapacity), 1);
bucket_t *end = cache_t::endMarker(newBuckets, newCapacity);
#if __arm__
// End marker's key is 1 and imp points BEFORE the first bucket.
// This saves an instruction in objc_msgSend.
end->setKey((cache_key_t)(uintptr_t)1);
end->setImp((IMP)(newBuckets - 1));
#else
// End marker's key is 1 and imp points to the first bucket.
end->setKey((cache_key_t)(uintptr_t)1);
end->setImp((IMP)newBuckets);
#endif
if (PrintCaches) recordNewCache(newCapacity);
return newBuckets;
}
至此 大概原理我们就理清楚了~。
