

本文概述:如何使用 nodejs 在服务端将 html 批量转成 pdf 并客户端下载。
目标一:使用 node 在服务端实现 html 批量转成 pdf
分为两步:
- 找段 html 把它转成 pdf。
- 循环执行第一步就达到了批量操作目的。
- 准备html 片段:111
- 将html 片段转 pdf 。
- 自己转(存疑)?或者找个中间件。自己转的话。。。算了,找插件。
网上搜到了 html-pdf,看了下周下载量接近 7W,版本迭代 21 个,最近更新时间 latest,不错,整体满足心里预期。
api使用如图:

提供了三种接口:文件、stream 流、buffer。不同返回值类型,使用 toFile()需要 2 个参数:文件地址(末尾要有文件名)、回调函数。
toFile()结果会在指定文件夹生成 pdf 文件; toStream()、toBuffer()可以在回调里拿到pdf文件数据流
目标二:将 PDF 传到客户端
怎么传输?
经过分析归纳,可以浓缩为 3 个点:
- 传输者:谁是传输者?它肯定是个主动行为,就像点击事件你必须先有一个点击动作一样。由此联想:接口,回调,node,req,res,send,end,前端 success 接收 data,res 浮现而出。
- 传输方法:原生 res.end(),express 框架 res.send(),res.sendFile(),res.download(),fs 模块 res.createWriteStream(),管道 pipe()。
- 传输内容:PDF 文件,stream 流,buffer,二进制流,下载链接,base64 码。
以下分析可以略过直接到结果:
分析:测试用的是 express 框架,那么可以排除原生 res.end()(存疑),为啥排除它?有 send 我干嘛还用 end;将 pdf 传向客户端又不是下载或写入文件,排除 createWriteStream()方法;PDF 文件可以自己跑过去吗?肯定不行!如果啥都不动能不能成功下载文件?也可以。链接下载,好像挺万能。base64 能用吗?。。。好像是图片在用!不知道对文件好使不好使(存疑)。
筛选后: 传输方法:res.send()、管道 pipe(); 传输内容:stream 流、buffer、下载链接;
使用下载链接: 经过分析了,下载链接肯定能实现这个功能!为什么呢?只要把 pdf 的文件路径用变量存下来,然后返回给前端,拿着绝对路径地址模拟点击下载应该就能实现!但这种方法并没有在真正意义上跟要传输的内容打交道,所以还值得继续探索。
最终决定使用,管道pipe()发送stream流输出PDF文件流到客户端
目标三:客户端可以成功接收并自动下载
网上搜索有:Windows.open()方法,iframe 等。感觉都有点偏。
本文使用a标签实现,其他方法另行尝试。
ajax + a标签
$.ajax({
url:'url',
responseType:'blob',
success (res) {
console.log(res.toString('utf-8'));
// 创建 blob 对象,解析流数据
// , {
// 如何后端没返回下载文件类型,则需要手动设置:type: 'application/pdf;chartset=UTF-8' 表示下载文档为 pdf,如果是 word 则设置为 msword,excel 为 excel
// type: 'application/pdf;chartset=UTF-8'
// }
const blob = new Blob([res]);
const a = document.createElement('a')
// // 兼容 webkix 浏览器,处理 webkit 浏览器中 href 自动添加 blob 前缀,默认在浏览器打开而不是下载
const URL = window.URL || window.webkitURL
// // 根据解析后的 blob 对象创建 URL 对象
const herf = URL.createObjectURL(blob)
// 下载链接
// a.href = 'url'
a.href = herf
// // 下载文件名,如果后端没有返回,可以自己写 a.download = '文件.pdf'
a.download = '文件.pdf'
// document.body.appendChild(a)
a.click()
// document.body.removeChild(a)
// 在内存中移除 URL 对象
window.URL.revokeObjectURL(herf)
}
})
传统jQuery接收数据流后,需要使用new Blob([res])再处理才能继续使用, 而,fetch也需要,不过简便多了
fetch+ a标签
//1.请求
let res = await fetch([地址]);
//2.解析
let data = res.blob()
//3.创建a标签
let eleA = document.createElement('a')
//4.创建鼠标事件对象
let e = document.createEvent("MouseEvents")
//5.初始化事件对象
e.initEvent("click", false, false)
document.body.appendChild(eleA)
eleA.download = 'index.zip'
eleA.href = data
//给指定的元素,执行事件 click 事件
eleA.dispatchEvent(e)
document.body.removeChild(eleA)
报错:

eleA.href直接使用 blob 数据作为下载链接是不行的,必须使用 window.URL 对象,果然无知者无畏,更改后的代码如下:
//1.请求
let res=await fetch([地址]);
//2.解析
let data=await res.blob();
const a = document.createElement('a')
const URL = window.URL || window.webkitURL
const herf = URL.createObjectURL(data)
a.href = herf
a.download = '文件.zip'
a.click()
window.URL.revokeObjectURL(herf)
使用 oFile() 测试
server.get('/', async (req, res) => {
toPdf(res);
});
function toPdf (res) {
let archive = archiver('zip', {
zlib: { level: 9 } // 设置压缩级别
});
archive.on('error', function(err){
throw err;
});
archive.pipe(res);
for (let i = 0; i < 100; i++) {
let html = `<div style="width: 100px;height:100px;background:#fff;color:red;font-size:16px;font-weight:bold">这是第 <span>${i}</span> 个 pdf</div>`;
pdf.create(html, options).toFile(`./static/${i}.pdf`, () => {
archive.glob('static/*')
archive.finalize()
})
}
}
看命令窗口偶尔还会报 Queue Closed 错误;

观察发现程序一边转 pdf,一边下载,而且是按照顺序转换下载有 0.1.2.3...,最后压缩返回,这个过程循环很少时发现没问题,但次数增加很多后如20,100次,当for循环到最后一次时,直接执行archiver.finalize(),完。。。结束了,所以造成Queue Closed原因是没限制archiver.finalize()执行时机???
找证据:
官方文档显示: // finalize the archive (ie we are done appending files but streams have to finish yet) // 完成存档
// 'close', 'end' or 'finish' may be fired right after calling this method so register to them beforehand // 调用此方法后,可能会立即触发“ close”,“ end”或“ finish”,因此请事先注册 archive.finalize();
果然,,
添加结束条件:
pdf.create(html, options).toFile(`./static/${i}.pdf`, () => {
if (i === 99) {
archive.glob('static/*')
archive.finalize()
}
})
执行成功,Queue Closed没出现,并且在浏览器自动下载了一个压缩包,打开后
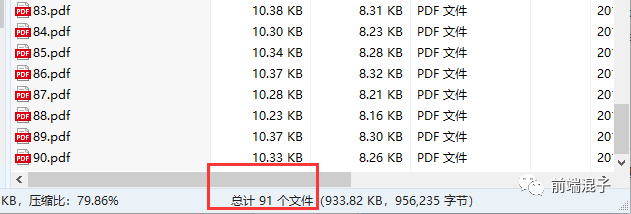
发现只有 91 个文件,缺少了最后几个文件,
for 循环明明执行了 100 次。百思不得解,开始我以为跟网络有关系,毕竟有传言只要(网络)够快什么(队列关闭)错误都追不上你。后来我发现用笔记本执行程序这个错误会频繁出现, 查看了 html-pdf 源码猜测会不会是同步在阻塞,导致循环结束后 PDF 生成文件还未完成导致 Queue Closed,怎么解决呢,闭包!具体原理未知(存疑),
经过修改
((html, i) => {
pdf.create(html).toFile(`./static/${i}.pdf`, () => {
if (i === 49) {
archive.glob('static/*')
archive.finalize();
}
})
})(html, i)
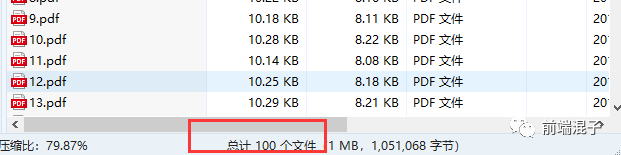
成功!!!打开压缩文件查看文件总数,
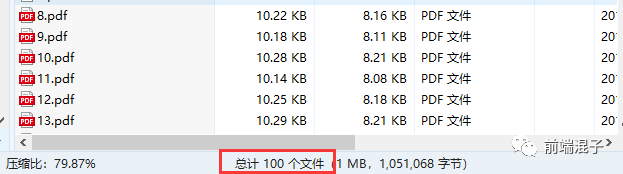
一切正常,Good!
使用 toStream()测试
(function(html, i) {
pdf.create(html).toStream((err, stream) => {
archive.append(stream, { name: `${i}.pdf`});
if (i === 99) {
archive.finalize();
}
});
})(html, i)
我去,第一次跑果然有问题,反复执行多次总是缺少前几个文件
第一次跑,少了第一个文件 1.pdf:

第二次,循环执行 50 次,结果只有 45 个成功,前 5 个失败:
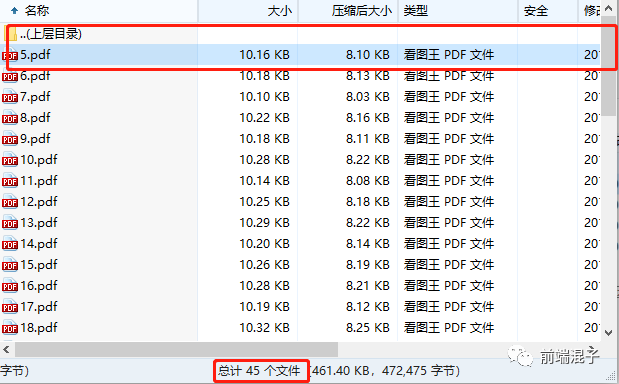
命令行打印也证明了这一点。。。每次失败个数竟然还不同,但还好有个规律它们都是前几个
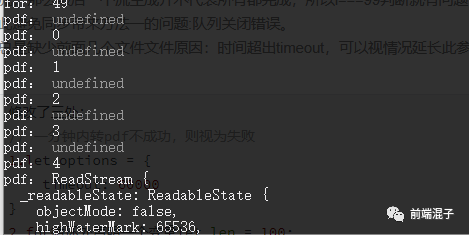
。。。 继续执行,竟然还有其他报错类型。。。无语。。

大致意思是:输入资源必须是 Stream 流或者 Buffer,可能是在使用 archiver.append 时塞入了 undefined 之类的,给它上个保险,如果值存在才执行
stream && archive.append(stream, { name: `${i}.pdf`});
综合问题共有 2 个:1.并不是所有 html 片段都进行了转换 PDF 的操作,可能会随机出现遗漏,比如 45.46.突然就到 48;2.即使所有 html 都进行了转换操作,还总是缺少前面几个文件。
问题一解决: html-pdf 源码如下图
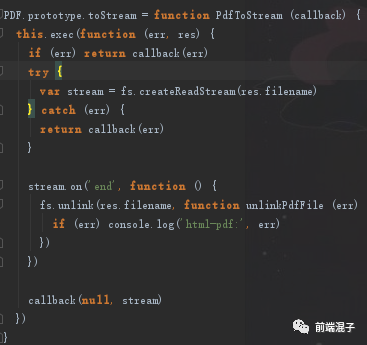
研究发现 html-pdf 的 toStream 应该是一个异步方法,查看源码后 stream.on('end')也证明了这一点。由于不是顺序生成 stream 流,那么最后一个流生成并不代表所有都完成,所以当用 i===99 判断结束就有问题,可能会跳过某一个不执行转换PDF需要len=50来避免,然而添加过后,每个文件都进行了PDF转换,但是stream显示为undefined,进而PDF文件也总是少前面几个,导致 i=99 出现时还有好多 toStream 没有完成,SO 第一个问题就出现了;(注:不过异步操作也因此避免同步带来方法一的问题:队列关闭错误。)
原因找到,解决办法就是添加变量手动强行控制进程: 如图,len 初始 100,减为 0 时代表所有都已经转换,可以结束
let len = 100;
然后,开始计数,不到最后一个完成 stream 流转换不结束
pdf.create(html).toStream((err, stream) => {
len--;
stream && archive.append(stream, { name: `${i}.pdf`});
if (len === 0) {
archive.finalize();
}
});
命令行打印下错误信息看看怎么回事控制台 问题二解决: 先打印下错误信息 console.log('err:', err)

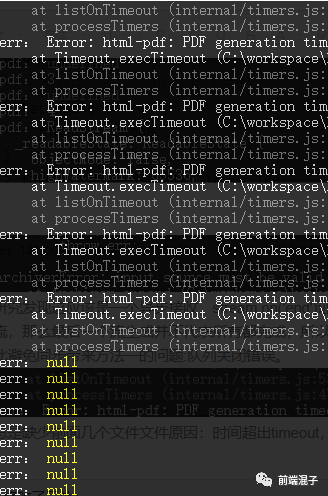
暴露了,PDF generation timeout. 一个 timeout 已经够了,能够说明很多问题,html-pdf 提供了转换超时限制,时间超出 timeout 自然无法成功转换成 stream 流输出,解决办法更简单: 官方文档,给出了一个配置项 options:{}对象,其中就有 timeout 设置,我们可以视情况放大此参数,
// 一分钟内转 pdf 不成功,则视为失败
1.let options = {
timeout: 60000
}
pdf.create(html, options).toStream((err, stream) => {
。。。。。。
});
继续测试,终于完成。。。
结语:
- 本文走了许多弯路,踩了多多个坑;
- 文中标记存疑的地方依然有很多,都是等待去学习理解的地方;
- 对于名词、问题的解释描述不够精准透彻,需要深度挖掘对知识点的认知;
- 对问题的解决方式不够标准、熟练,这才是造成多走弯路的原因;
- 虽然解决问题才是我们的最终目的,但是仍需追求解决方式的多样化,找到问题的根源 格物致知 才能给自己醍醐灌顶之感;
参考资料:
