

项目在这里:github.com/codewithkai…
你可以点这个地址在线体验:w4u0q.sse.codesandbox.io/ (几分种不用就会自动休眠,打开需要耐心等待初始化,遇到错误请刷新)
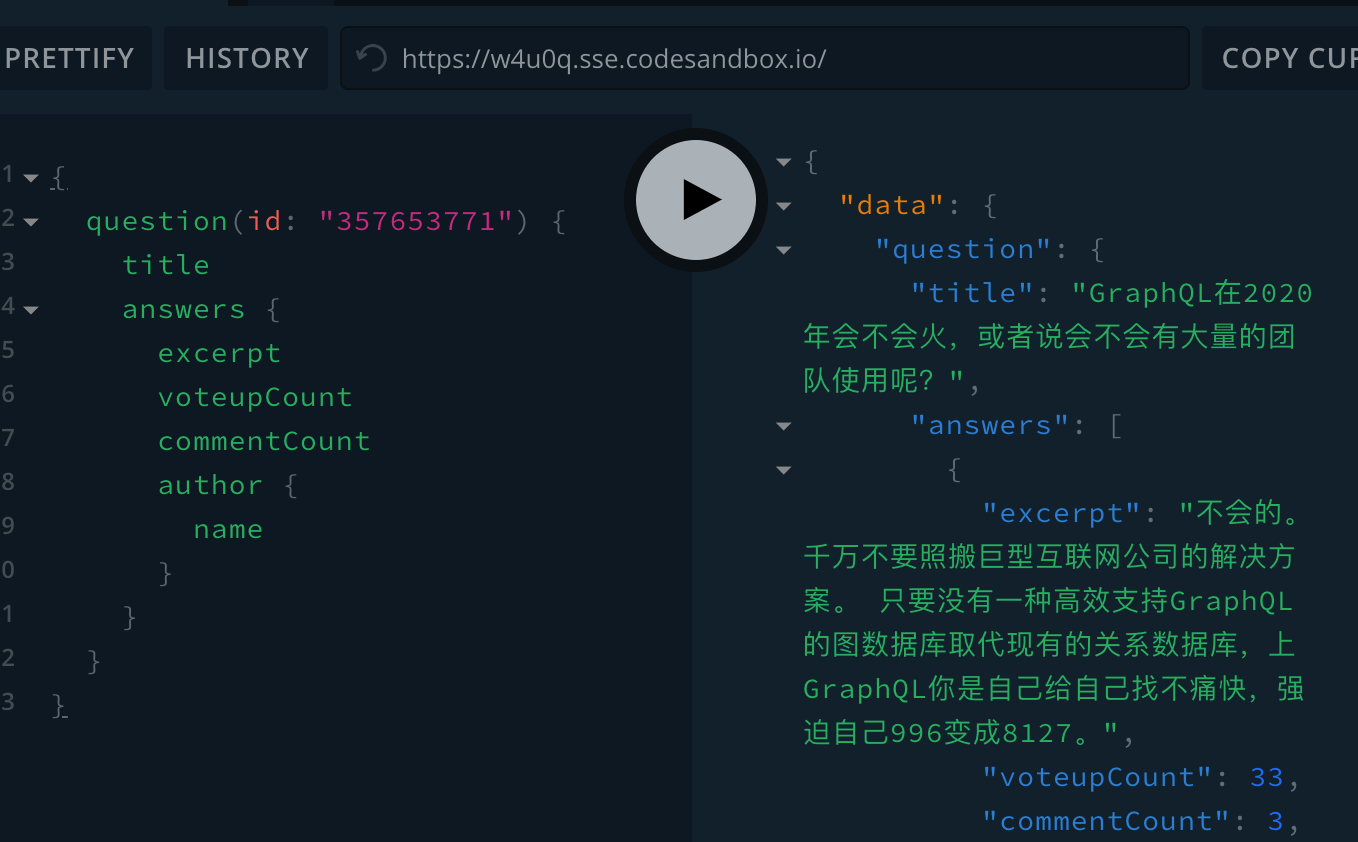
比如下面这个例子:查询一个问题、关联查询问题的答案以及答案的作者
{
question(id: "357653771") {
title
answers {
excerpt
voteupCount
commentCount
author {
name
}
}
}
}
先交代一下这个项目的背景。我想教一门关于Apollo全栈开发课程,Apollo官方给的示例项目用的是SpaceX的例子。我本来不想重新造轮子,但是我发现让很多国内程序员适应这些例子还是有些挑战的。
经过调研我发现开发者喜欢实战课程,并且喜欢仿照流行的互联网应用,比如仿知乎、仿网易云音乐、仿饿了吗,仿小米商城等等。于是我就蹭了一下知乎的名气。我的例子就是照着Apollo官方的例子改的,只不过内容换成了知乎。
因为知乎没有公开的API,所以我只能在Chrome开发工具了一点点观察,然后一点点把这些API调用记录下来。在这个过程中我有很多发现。
首先,知乎的API虽然是REST,但用起来已经很像GraphQL了。比如如下几点:
-
使用include参数限制返回的字段
https://www.zhihu.com/api/v4/members/c7e4de899635e9ce839d90d64f0b9602?include=answer_count,follower_count,articles_count -
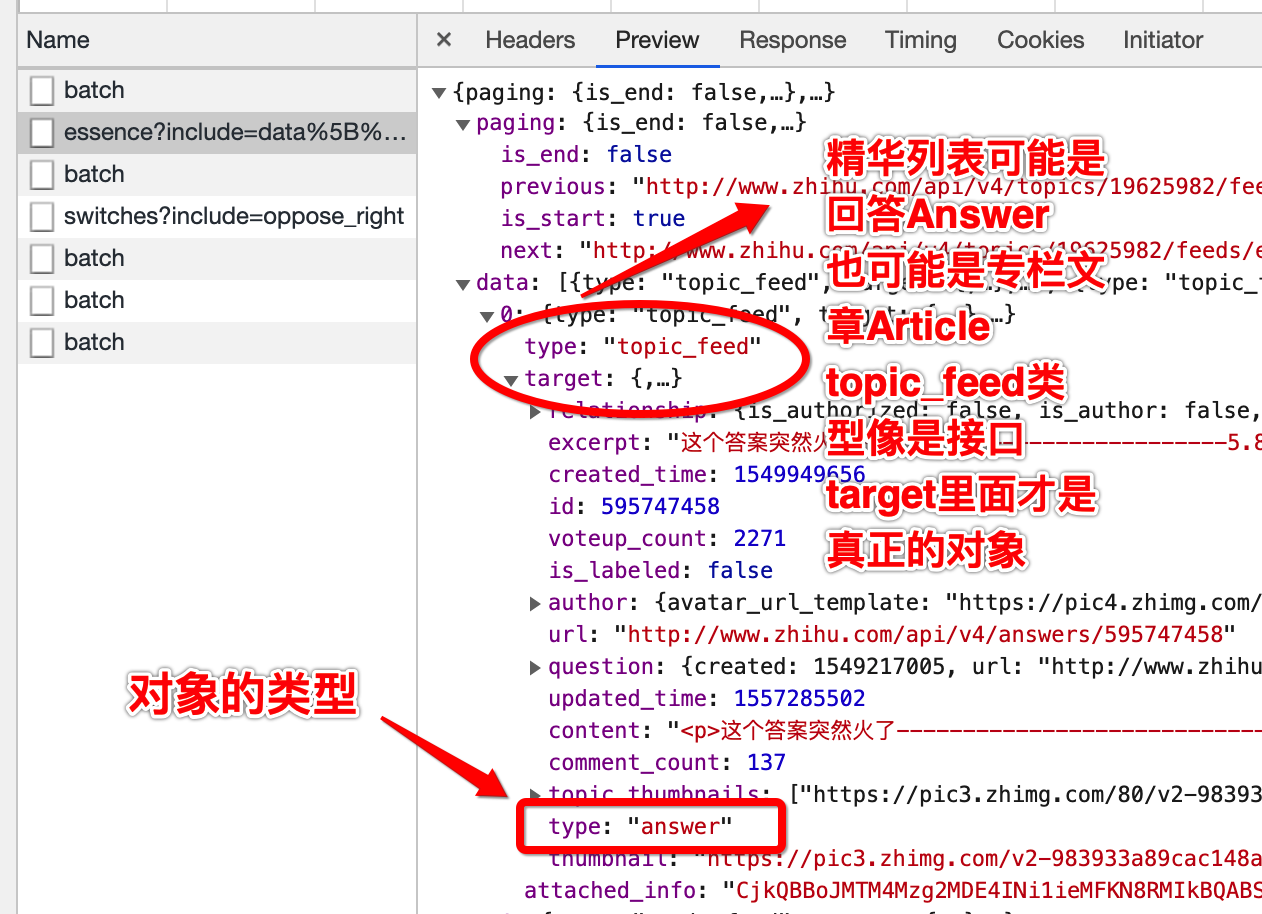
支持一定程度的嵌套查询,比如一个话题里面的热门讨论列表,除了返回回答列表之外,回答的对应的问题,回答的作者等新信息都一起返回了,比如:
https://www.zhihu.com/api/v4/topics/20031262/feeds/top_activity?include=data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.is_normal,comment_count,voteup_count,content,relevant_info,excerpt.author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=article)].target.content,voteup_count,comment_count,voting,author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=people)].target.answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics;data[?(target.type=answer)].target.annotation_detail,content,hermes_label,is_labeled,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[?(target.type=answer)].target.author.badge[?(type=best_answerer)].topics;data[?(target.type=article)].target.annotation_detail,content,hermes_label,is_labeled,author.badge[?(type=best_answerer)].topics;data[?(target.type=question)].target.annotation_detail,comment_count; -
如果仔细观察上面的URL,
data[?(target.type=question)]这种写法甚至有像GraphQL里面Inline Fragment的写法里根据__typename来判断具体类型,然后再查询这种具体类型的字段 -
REST里的对象是没有类型的,但是知乎API用返回的对象用type字段来标注对象的类型。一个主题下面,精华讨论列表的返回,甚至有点像GraphQL里的
Interface
看到这里,我们可能会想,REST的痛点都解决了,还有必要用GraphQL吗?
我大概想到以下两点:
-
前端的开发者体验差别会非常大。
include筛选简单字段的方式尚且可以接受,但是用include表达嵌套查询看起来简直是灾难。我猜知乎的前端开发应该不会直接写这一大坨东西,而是有专门封装好了的client?这样前端写的时候可以比较容易的表达嵌套关系,而最后生成了这么复杂的URL。如果用GraphQL写体验会非常不一样,如果加上Apollo Client这样的客户端会更不一样。参见我在B站的视频:在前端使用GraphQL开发是怎样一种体验?_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili -
为了处理
include以及更复杂的写法如data[?(target.type=question)],知乎的后端也需要像GraphQL后端那样做一些解析查询请求,确定执行方案,最后从数据源获取和拼装数据的工作,这些工作是在哪一层完成的?虽然可能不会像GraphQL实现那么复杂,但是其实有点像GraphQL了?
当然这只是想象,因为我从来没在大公司工作过,对知乎这样大的应用完全没有概念是怎么架构的,前端和后端的开发体验又是怎样的。
当然从现实的角度讲,知乎把API改造成GraphQL的收益恐怕比较小,而代价和带来的问题恐怕会比较大。但也或许未必。
另外,讲一下在我的这个例子中把REST变成GraphQL的局限:虽然Apollo说可以把REST当做数据源,但实际使用起来性能问题很大。比如一个问题有10个回答,然后关联查询这10个回答的作者,这样后端实际会产生11个REST请求。除非查询作者的REST接口支持根据多个id批量查询,这样就可以用dataloader模式把10个并成1个。这样,所谓的N+1问题被推到服务端,没有实际解决问题。
其实,知乎的API不是标准的RESTful,而是根据业务场景设计的API,本身已经支持嵌套查询了,我为了演示GraphQL的方式,是把关联数据扔掉,只留下ID,然后再用resolver单独去获取这个类型的数据,所以会显得低效。而如果底层的数据源是数据库的话,演示就会更清楚,性能也更好。
最后,我还想写一个仿知乎RESTAPI的课,就不得不去熟悉知乎的业务,从旁观者的角度看知乎,它的复杂程度是超过我的想象的,甚至是令人望而生畏的。如果要做一个仿知乎的课,恐怕也只能模仿最表面的东西,有很多问题是超出我的理解的:
- 作为社交网络,知乎面临跟Facebook一样的问题?各种社交关系是如何存储和提取的?
- 问题中的回答如何排序,话题下的讨论如何排序?
- 各种个性化推荐的内容,个性化的邀请回答等等又是如何做到的?
- 各种消息通知是如何推送的?
另外有兴趣的同学可以访问我的视频课程网站,刚刚开始:codewithkai.com
更多GraphQL等Web开发技术,关注我的公众号:

