

去年的一次需求中涉及到图片打码功能,整理并记录当时的思路,以及后来的一些发散思考。
这里的打码都是指毛玻璃效果(高斯模糊),不过根据我的思路马赛克或其他效果都是可以实现的
文中斜体部分大多是在表述我自己的理解
前言
接下来我会以实现图片打码为目标介绍一些思路和技术方案,在文末还会介绍一些有趣的图像处理功能,都是基于调研过程中了解到的api实现的,比如抠图、千图成像、绿幕技术,感兴趣的话可以一起了解下。
canvas
HTML 的 <canvas> 元素提供了一个空白绘图区域,可以使用 APIs (比如 Canvas 2D 或 WebGL)来绘制图形。
以上是MDN对canvas的介绍,既然是用来绘制图形的,可能大部分同学并没有接触过此类需求,对canvas处于听过看过没用过的状态。
下面我来快速介绍一下如何用canvas在浏览器上绘制出一个图形,这样大家就都在同一起跑线上了。
或者你可以在MDN上了解canvas的基本用法然后跳过这部分。
快速介绍
CanvasRenderingContext2D(渲染上下文)是canvas的一个重要对象,通过在<canvas>上调用getContext()并传入一个'2d'参数来获得,获得这个渲染上下文后就可以对该<canvas>上进行绘制操作了。
所以在使用canvas绘图时,起手来一个getContext是必不可少的
getContext()还可以传入'webgl'来获取三维上下文进行3d绘图。 既然<canvas>是画布,我觉得这些上下文可以理解成画笔,2d画笔画2d,3d画笔画3d
<canvas id="tutorial" width="150" height="150"></canvas>
<script>
let canvas = document.getElementById('tutorial');
let ctx = canvas.getContext('2d');
ctx.fillRect(25, 25, 100, 100);
</script>
上面这段代码就是获取canvas2d上下文后调用了fillRect在<canvas>上绘制了一个矩形,位置在<canvas>的左上起(25,25)处,长宽为100,默认颜色是#000

除了绘制矩形外,这个渲染上下文还提供了其他许多API用以实现各种绘图需求,比如绘制文本、绘制路径、绘制图像、像素控制、旋转变换等,接下来我只在用到的时候介绍他们。
技术方案
图片打码的需求简单描述下就是:通过浏览器上传一张图片,展示该图片后点击图片任何区域,该区域被打码,可以将打码后的图片保存或上传
高斯模糊的原理及算法这里就不介绍了,可以直接使用现成的库stackblur来处理,需要马赛克等其他效果也可以找到相应的库
这就需要canvas能做到下面几点:
- 能把图片写入canvas
- 能获取canvas指定位置的像素,能原地修改像素值更好
- 能保存当前canvas为图片或base64数据
看一下API列表,初步思考技术方案:
- 用drawImage()将图片写入<canvas>
- 用getImageData()获取像素数据,这里得到的数据中包含一个一维数组,数组的元素是图片所有像素点的rgba值,遍历这个数组,监听mousedown和mousemove事件,找到对应位置的像素点,计算并修改为打码后的新像素值,由于无法原地修改,所以修改之后需要重新调用drawImage,将打过码后的图像绘入<canvas>
- HTMLCanvasElement提供了canvas.toDataURL()和canvas.toBlob()方法,调用后可以获得当前画布中展示图像的base64数据或blob对象,可以用来展示或者下载上传
这里提到要用drawImage的地方都可以替换为putImageData,二者区别会在文末介绍
根据上面的技术方案,落地成代码就是:
<!-- 引入stackblur.js 处理高斯模糊区域-->
<script src="https://cdn.bootcss.com/stackblur-canvas/2.2.0/stackblur.min.js"></script>
<canvas id="canvas1"></canvas>
<script type="text/javascript">
var canvas = document.getElementById("canvas1");
var context = canvas.getContext("2d");
var imgObj = new Image();
imgObj.src = '../img.jpg';
//待图片加载完后,将其显示在canvas上
imgObj.onload = function () {
canvas.style.width = this.width + "px";
canvas.style.height = this.height + "px";
canvas.width = this.width;
canvas.height = this.height;
// 调用drawImage在canvas上绘制此图
context.drawImage(this, 0, 0, this.width, this.height);
// 开始监听鼠标事件
initEventListener();
}
function initEventListener() {
canvas.onmousedown = function (ev) {
var ev = ev || window.event;
var dx = ev.clientX - canvas.offsetLeft;
var dy = ev.clientY - canvas.offsetTop;
drawLine(dx, dy);
document.onmousemove = function (ev) {
var ev = ev || window.event;
var mx = ev.clientX - canvas.offsetLeft;
var my = ev.clientY - canvas.offsetTop;
drawLine(mx, my);
};
document.onmouseup = function () {
document.onmousemove = null;
document.onmouseup = null;
};
}
}
function drawLine(dx, dy) {
// 在canvas 距离左上角dx - 15, dy - 15的位置生成一个矩形高斯模糊区域,大小为30*30,模糊半径为10(模糊半径越大打码效果越强)
StackBlur.canvasRGBA(canvas, dx - 15, dy - 15, 30, 30, 10);
}
</script>
方案中描述调用getImageData()后处理像素点的操作由StackBlur.canvasRGBA完成
效果:

demo
完整代码
虽然能用,但有两个小问题:
- 每次只能处理一个矩形,可能圆形更符合设计和体验
- 鼠标移动速度过快时,打码路径不连续
这两个问题也是可以解决的:
- 第一个问题我们可能要深入stackblur内部,算出需要进行高斯模糊的圆形边界坐标集合,模糊处理时只处理圆内的像素
- 第二个问题是由于我们每次处理的区域只是一个点,要解决的话需要丰富一下onmousemove的逻辑,每个点跟之前的点相连,形成一条路径,对连线路径也进行模糊处理
这两个问题解决难点在于要计算一系列点坐标确定边界,只对边界内的像素模糊处理,需要用到高中数学知识,勾股定理,相似三角形等,非常的可怕
接下来是梦回高中环节,可以直接跳过看 新的技术方案
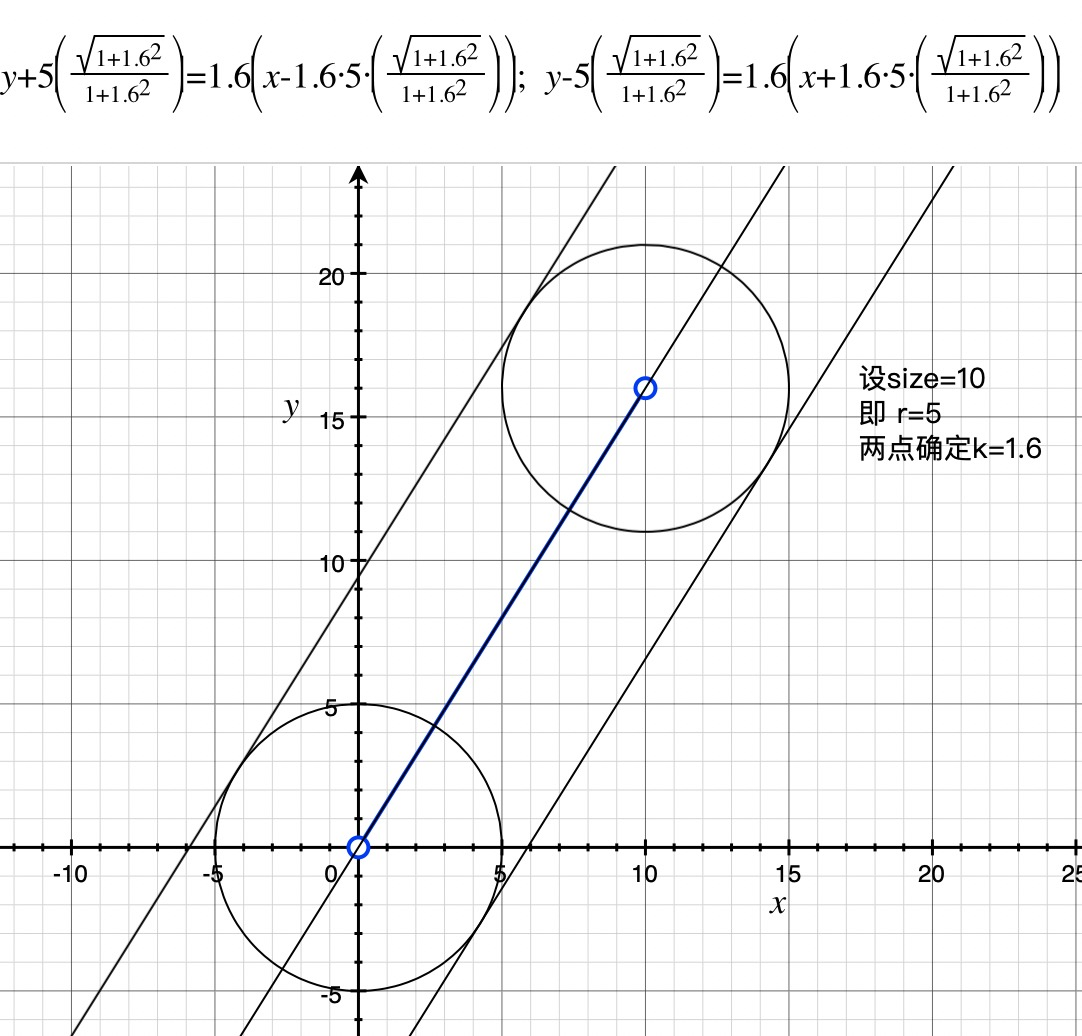
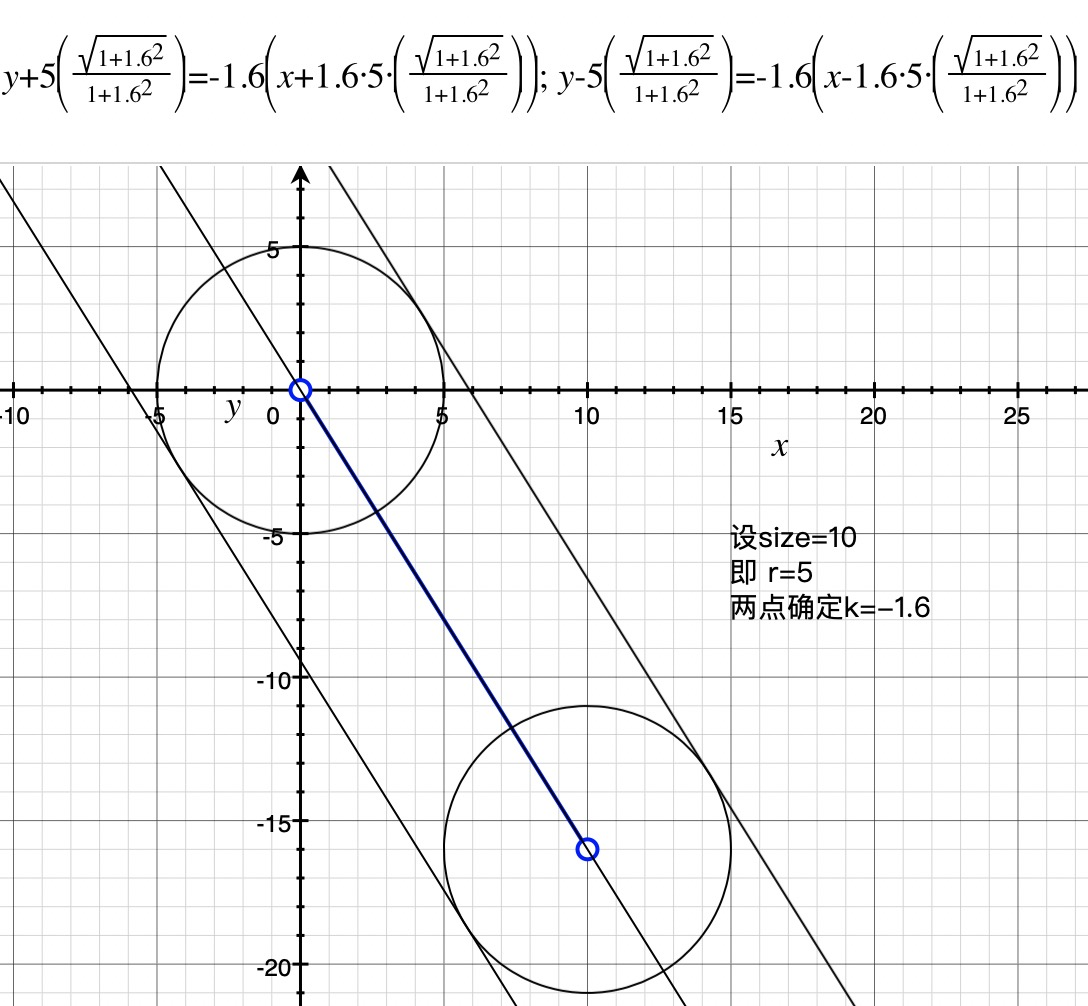
首先有常量size表示画笔粗细,在mousemove中拿到两个点P1,P2坐标已知,可以确定一条直线l: y=kx+b(为了方便介绍,我们假设这里以P1为原点,即方程为y=kx,实际中要变化坐标系计算),这条直线延其垂直方向平移正负size/2可以确定两条直线l1,l2,以P1和P2为圆心半径为size/2确定的两个圆记为c1,c2。 l1,l2,c1,c2组成的区域就是我们要确定的待模糊处理的范围,如下图中的胶囊型区域
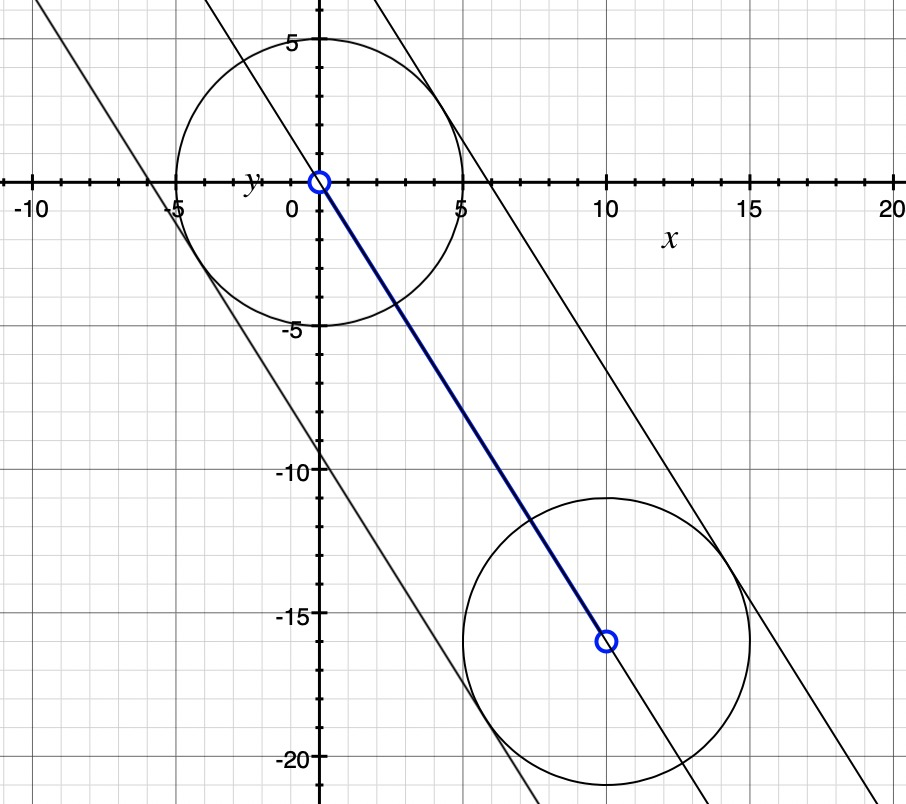
size/2记做r,可以表示圆的半径和直线l平移的距离经过计算,l1 ,l2的方程如下,需要分别讨论k > 0和k < 0的情况:
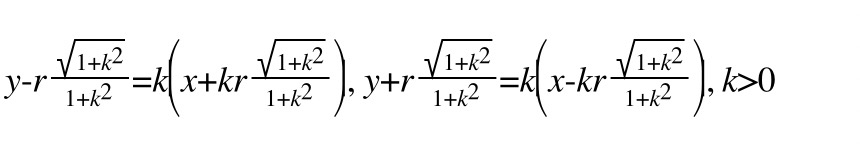
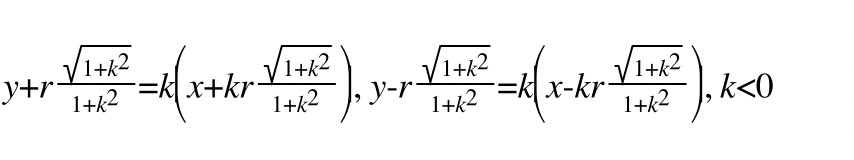
圆的方程根据点坐标(x1, y1)就可以确定:
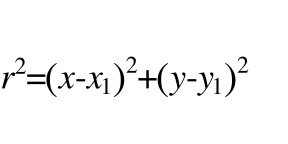
下面举两个🌰:
- 以size=10, P1(0, 0), P2(10, 16)即k>0为例:
- 以size=10, P1(0, 0), P2(10, -16)即k<0为例:
接着在遍历像素点的时候,把坐标代入这四个方程就可以判断该像素点是否在需要模糊的范围内了。
我们先知难而退,这个方案暂列为走投无路的最终方案 ,去捡回刚才掀飞的键盘再看一看API列表,把目光锁定在线型和路径上:


那么我们可以以路径为核心来实现需求吗?
当然可以,感受一下,上面我们按下鼠标来回划动的时候,像不像在用橡皮擦和刮刮乐,假设这里是刮刮乐的话,如果我们刮出的图像是模糊后的图像那不就大功告成了吗
新的技术方案
我们的新方案是把这个需求当作刮刮乐来做,待刮涂层是原始图像,下面露出的奖项是被高斯模糊处理后的图像,刮开任何位置对应的都是该部位高斯模糊后的图像。
接下来我们面临了两个新的问题:
- 在网上众多刮刮乐实现方案中,奖项涂层可以设置<canvas>的background来实现,也可以创建一个新的<canvas>来充当,要选哪种方案
- 新方案下如何得到最终图片数据进行下载上传
这就需要我们确定一件事: canvas.toDataURL()是否会连同canvas的background一起生成base64数据,如果不可以那就只能选用第二种刮刮乐方案: 双canvas,借助第三个canvas作为最终的容器,调用drawImage()按顺序写入我们的奖项canvas和涂层canvas,最后对这个容器调用toDataURL()得到base64数据
经过测试background是不会写入toDataURL()生成的数据里的,所以我们的最终技术方案可以确定下来:
- html中创建两个<canvas> 分别是「涂层」和「奖项」,涂层命名为upper-canvas,奖项层就称为canvas,upper-canvas用绝对定位置于canvas之上
- 图片加载完成后用drawImage把图片写入upper-canvas,用StackBlur.image将图片全部模糊处理后也用drawImage写入canvas
- 对upper-canvas赋予刮刮乐功能,具体原理就不讲了,网上一搜一麻袋。主要就是使用路径,结合globalCompositeOperation属性,这个属性可以控制画新图形(路径)与已有图形的遮盖策略,通过把它设置为
destination-out来实现刮刮乐效果 - 借助一个容器<canvas>,调用drawImage写入canvas和upper-canvas的图像,这个容器<canvas>调用toDataURL即可拿到最终图片的base64数据
用代码实现:
<script src="https://cdn.bootcss.com/stackblur-canvas/2.2.0/stackblur.min.js"></script>
<canvas id="canvas"></canvas>
<canvas id="upper-canvas" style="position: absolute; top: 0; left: 0;"></canvas>
<script>
let upperCanvas = document.getElementById("upper-canvas"),
upperContext = upperCanvas.getContext("2d");
upperContext.lineCap = "round";
upperContext.lineJoin = "round";
upperContext.lineWidth = size * 2;
upperContext.globalCompositeOperation = "destination-out";
let x1, y1,//绘制路径的起点坐标
size = 15;
let canvas = document.getElementById("canvas"),
context = canvas.getContext("2d");
let img = new Image();
img.src = '../img.jpg';
img.onload = function () {
// 绘入原始图片
upperCanvas.style.width = this.width + "px";
upperCanvas.style.height = this.height + "px";
upperCanvas.width = this.width;
upperCanvas.height = this.height;
upperContext.drawImage(this, 0, 0, this.width, this.height);
// 模糊处理图片, 绘入底部图片
StackBlur.image(this, "canvas", 10);
tapClip();
};
function getClipArea(e, hastouch) {
let x = hastouch ? e.targetTouches[0].pageX : e.clientX;
let y = hastouch ? e.targetTouches[0].pageY : e.clientY;
let ndom = upperCanvas;
while (ndom.tagName !== "BODY") {
x -= ndom.offsetLeft;
y -= ndom.offsetTop;
ndom = ndom.parentNode;
}
return {
x: x,
y: y
};
}
function tapClip() {
let hastouch = "ontouchstart" in window ? true : false,
tapstart = hastouch ? "touchstart" : "mousedown",
tapmove = hastouch ? "touchmove" : "mousemove",
tapend = hastouch ? "touchend" : "mouseup";
let area;
let x2, y2;
upperContext.lineCap = "round";
upperContext.lineJoin = "round";
upperContext.lineWidth = size * 2;
upperContext.globalCompositeOperation = "destination-out";
upperCanvas.addEventListener(tapstart, function (e) {
e.preventDefault();
area = getClipArea(e, hastouch);
x1 = area.x;
y1 = area.y;
drawLine(x1, y1);
this.addEventListener(tapmove, tapmoveHandler);
this.addEventListener(tapend, function () {
this.removeEventListener(tapmove, tapmoveHandler);
});
function tapmoveHandler(e) {
e.preventDefault();
area = getClipArea(e, hastouch);
x2 = area.x;
y2 = area.y;
drawLine(x1, y1, x2, y2);
x1 = x2;
y1 = y2;
}
});
}
function drawLine(x1, y1, x2, y2) {
upperContext.beginPath();
if (arguments.length == 2) {
upperContext.arc(x1, y1, size, 0, 2 * Math.PI);
upperContext.fill();
} else {
upperContext.moveTo(x1, y1);
upperContext.lineTo(x2, y2);
upperContext.stroke();
}
}
</script>
借助一个canvas做容器实现下载的代码:
btn.onclick = function () {
// 创建隐藏的可下载链接
let eleLink = document.createElement('a');
eleLink.download = 'filename';
eleLink.style.display = 'none';
// 创建一个canvas作为临时容器
let tempCanvas = document.createElement('canvas');
let tempContext = tempCanvas.getContext('2d');
tempCanvas.width = upperCanvas.width;
tempCanvas.height = upperCanvas.height;
// 按顺序绘入两层canvas
tempContext.drawImage(canvas, 0, 0);
tempContext.drawImage(upperCanvas, 0, 0);
// 图片转base64地址
eleLink.href = tempCanvas.toDataURL('image/jpeg');
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除链接
document.body.removeChild(eleLink);
}
有些浏览器是支持filter属性的, 可以直接实现高斯模糊, 如果你的目标浏览器支持的话, 可以省去引入StackBlur
// 模糊处理图片, 绘入底部canvas
canvas.style.width = this.width + "px";
canvas.style.height = this.height + "px";
canvas.width = this.width;
canvas.height = this.height;
context.filter = "blur(10px)";
context.drawImage(this, 0, 0, this.width, this.height);
// StackBlur.image(this, "canvas", 10);
效果:

到这里我们的需求就完全实现了,代码细节方面还很粗糙,方案是完全行得通的
这个方案跟第一种方案相比,(这里假设第一种方案实现了😅)第一种方案在同一位置多次点击具有「码上加码」的特性,而刮刮乐方案中鼠标点多少次,模糊程度都是一样的,所以大家如果真的有这种需求,还是要跟产品确认下这个问题的。
打码需求就到此为止了🎉,优化下细节就能使用了,如果你要的效果不是高斯模糊,相信你也能按照这个思路完美实现自己的需求,下面我会说说这次调研的一些思考与收获
上面提到过drawImage的都可以替换为putImageData,下面我来聊聊他们的区别
drawImage VS putImageData
二者主要区别在于如果要绘制的目标区域已经有了图像,drawImage会在目标区域已有图像上绘制,putImageData则会把目标区域已有图像清空后再绘制。最明显的案例就是如果要绘制一片透明图像到目标位置上,drawImage后整个图像看起来是没有变化的,putImageData后目标位置的图像会被清空。所以上面讲的新的方案里我们借助第三个canvas作为容器,导出数据下载图片时只能使用drawImage,putImageData虽然也保留了透明部分,但是会把下面的模糊图层清空。
另一个区别在于接收的图源类型不同,drawImage主要接收各种图像类html元素,比如img, video,或者另一个canvas
putImageData只能接收ImageData作为图源
所以可以结合使用场景来选择绘制图片的方法,在处理完ImageData像素数据后直接调用putImageData会很方便(比如方案一),单纯的希望图像元素变成canvas就直接用drawImage
在性能方面drawImage是明显优于putImageData的
putImageData绘图时会清空目标区域图像,性能又差,但并不能说它一无是处
几乎任何图片处理的底层原理都是通过修改ImageData像素数据实现的,而只有putImageData能够将ImageData变成图像,下面我来介绍下ImageData的一些应用
One more thing
ImageData 接口描述 <canvas> 元素的一个隐含像素数据的区域。
ImageData的data属性是一个Unit8类型的一维数组, 数组元素是这个图像的每个像素点的rgba值, 所以这个数组中每4个元素表示一个像素点, 分别代表rgba值, 浏览器根据ImageData的width和height属性结合data数组来绘制图像。
rgba每个维度范围是0-255, 也对应这里的Unit8表示的范围, 即[0, 2^8-1]
上面提到过图片处理的底层原理都是通过修改ImageData像素实现的,下面我来介绍几个相关应用
抠图
通过遍历图像每个像素点,与目标像素对比,符合条件的就把当前的像素点rgba中的a设为0,即透明度完全透明,得到一个新的ImageData,调用putImageData把新的ImageData绘入canvas即可
imgObj.onload = function () {
canvas.style.width = this.width + "px";
canvas.style.height = this.height + "px";
canvas.width = this.width;
canvas.height = this.height;
context.drawImage(this, 0, 0, this.width, this.height);
var modifyImgData = context.getImageData(0, 0, canvas.width, canvas.height);
var modifyPxData = modifyImgData.data;
let l = modifyPxData.length / 4;
for (let i = 0; i < l; i++) {
let r = modifyPxData[i * 4 + 0];
let g = modifyPxData[i * 4 + 1];
let b = modifyPxData[i * 4 + 2];
if (r > 100 && g > 120 && b > 120)
modifyPxData[i * 4 + 3] = 0;
}
context.putImageData(modifyImgData, 0, 0);
}
上面的代码我抠掉了一张图片中r > 100 && g > 120 && b > 120的像素,大概就是图中的天空,效果如下:

完整代码
以后可以自己换证件照底色了
千图成像
Photographic mosaic,经典的案例就是楚门的世界电影海报
了解过ImageData后在看这种图片,可以想像一下是把许多子图片作为一个个像素拼起来。这些子图片在缩小到一定程度时会表现出一个主要颜色,这个颜色与原图对应像素的rgb值越接近最终效果就越好。 所以这个需求实现起来需要先获取原图的ImageData,遍历每个像素点,获取该点的rgb值,以此值为标准,在子图库里寻找颜色最接近的子图
对于如何计算子图代表的颜色,以及颜色相近的判断标准是什么,我是这样想的(可能并不正确):
- 获取子图的ImageData,遍历像素数据,把每个像素的rgb累加后求和,得到一个平均值r,平均值g,平均值b,这个平均值代表这张图作为像素点时的颜色表现
- 判断颜色相近的办法,对于rgb表示的颜色来说,rgb就像三个维度,可以构建成一个立方体,两点之间的距离即可表示颜色差异程度,计算方法和立体几何中一样(求三段距离平方和再开方):
Math.sqrt(dr ** 2 + dg ** 2 + db ** 2)
这里我使用rgb模型来计算颜色差异程度,换成hsv模型来计算会更精确
最终效果跟子图片质量也有关,子图片颜色越均匀效果越好
接下来就是把拿到的子图绘入新的大图里,所有的原始像素遍历完成, 这张大图就拼好了
为了减少计算量可以把子图和原图压缩一下,比如原图800x800,在不允许子图重复的情况下组成他需要64万张子图,如果每张子图是20x20的,那么最终的结果图片就是16000x16000(按上面我们提到的1个像素4bytes来算,这张图大小约为0.9G,生成jpg或png会更大)。如果把原图压缩至40x40,就需要1600张子图,子图压缩至20x20,最终图片就是800x800。 效果当然是不压缩比较好,但这取决于你是否有这么多子图,生成速度也依赖计算机性能
下面是我把一张800x800的图片按照40x40的分辨率,子图为20x20生成了一张效果图,由于图源是从百度图片的接口爬来的,数量有限,这里我按照可以重复使用的策略来生成,所以效果并不太好,不过有个“造假”的办法,就是把原图设置一定的透明度再画到结果图上。
下图左至右分别是 原图,结果图,造假图:

我感觉做好这几点会有更好的效果:
- 判断颜色相近的策略(子图rgb平均值代表它作为像素的颜色是否科学;计算颜色差异程度时使用hsv模型替代rgb模型)
- 子图片颜色最好均匀
- 结果与原图的压缩程度尽可能小
- 我的方案还很不成熟,子图全部截成了正方形以方便与原图像素一一对应,会不会有算法可以使用一张子图对应上多个原图像素点
「绿幕」
这里是MDN上介绍的应用,主要是利用了drawImage可以用video作为图像源这一特点,对视频的每一帧做处理,把每帧的ImageData中特定色值(绿色)的像素透明度替换为0(完全透明),再画到另一个canvas上,就实现了以特定图像替换「绿幕」的效果,利用这个思路我把两个视频合成起来:
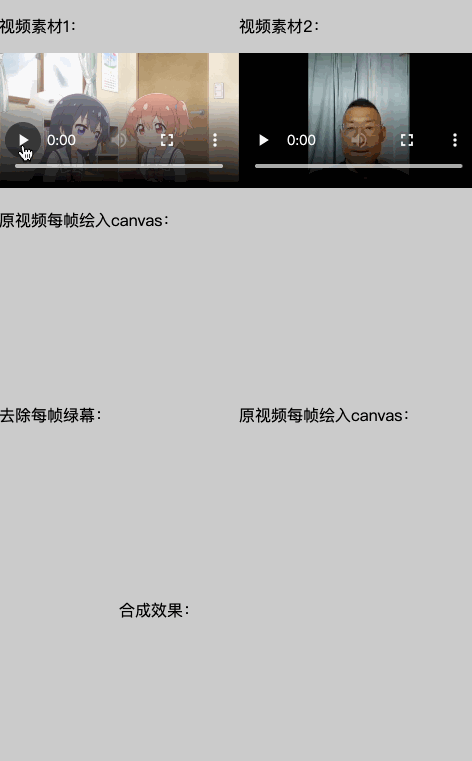
demo
完整代码
联想一下一些播放器的导入字幕功能,可能也是这个原理把字幕绘制到正在播放的视频上的
总结
最初拿到需求一顿百度谷歌,想找一个第三方插件来实现,现在回过头看实现起来是很简单的。自我反省一下长久以来的调包侠行为让自己变得不重视思考,以后用包或框架还是需要结合需求认真思考下是不是真的需要它。(如果当时找到了插件那也香啊)
最后这部分小功能的介绍 意义并不在于前端也能把p图,抠图,视频合成之类的功能搬到浏览器上,我觉得更多在于了解这些功能背后的原理,了解ps和视频剪辑软件是如何工作的,毕竟这些操作在浏览器上会占用很高的CPU和GPU,不过随着网络和硬件设备的不断升级,相信有一天这些功能也能在浏览器上流畅的运行
参考
- developer.mozilla.org/zh-CN/docs/…
- github.com/flozz/Stack…
- www.cnblogs.com/puyongsong/…
- juejin.cn/post/684490…
- github.com/WebKit/webk…
- stackoverflow.com/questions/7…
- blog.csdn.net/qidu1998/ar…
