

前言
贵有恒,何必三更眠五更起;最无益,只怕一日曝十日寒。毛爷爷年轻时用这幅对联激励自己。这段话我查了一下,其实原文来自于明代学者胡居仁自勉联。这席话的意思就是如果真的有恒心,又何必半夜刚睡下,天不亮就起床(拖延症患者经常有的症状)。最没有好处的,莫过于晒一天而又冻十天(激情四射想要热血干一场,结果一天之后就放弃了)。所以对于我们来说,就得天天持之以恒的输出。so,今天我们来研究 numberrange分片大法。
1.hash分区算法
2.stringhash分区算法
3.enum分区算法
4.numberrange分区算法
5.patternrange分区算法
6.date分区算法
7.jumpstringhash算法
numberrange分区算法的配置
<tableRule name="rule_range">
<rule>
<columns>id</columns>
<algorithm>func_range</algorithm>
</rule>
</tableRule>
<function name="func_range" class="NumberRange">
<property name="mapFile">partition-number-range.txt</property>
<property name="defaultNode">0</property><!--he default is -1,means unexpected value will report error-->
</function>
和之前的算法一样。需要在rule.xml中配置tableRule和function。
- tableRule标签,name对应的是规则的名字,而rule标签中的columns则对应的分片字段,这个字段必须和表中的字段一致。algorithm则代表了执行分片函数的名字。
- function标签,name代表分片算法的名字,算法的名字要和上面的tableRule中的标签相对应。class:指定分片算法实现类。此处需要填写为“numberrange”或者“com.actiontech.dble.route.function.AutoPartitionByLong"的分区规则,property指定了对应分片算法的参数。不同的算法参数不同。
- mapFile:指定配置文件名。其格式将在下面做详细说明。
- defaultNode:指定默认节点号。默认值为-1,不指定默认节点。
配置文件格式如下:
start1-end1=node1
start2-end2=node2
这个算法定义的是区间,比如start1-end1就是第一个区间,该区间的数据就落到node1分片里面。而start2-end2是第二个区间,这个区间的数据就落到node2分片里面。
1.启动加载配置
当启动的时候,会根据rule.xml中定义去读取mapfile。然后将文件中定义的各个范围加载到内存中形成映射表。例如下面的配置:
[root@dble conf]# more partition-number-range.txt
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
这个配置中有两个单位K和M,K默认等于1000,M默认等于10000。然后我们可以配置0-500万是存放在分片1上,500万-1000万存放在分片2,1000万-1500万存放在分片3上。
2.运行过程
如果有用户通过where查询id=5000的时候,就会访问这个numberrange算法。根据上面的映射表直接查询得到分片的编号。
3.我们建表来测试一下
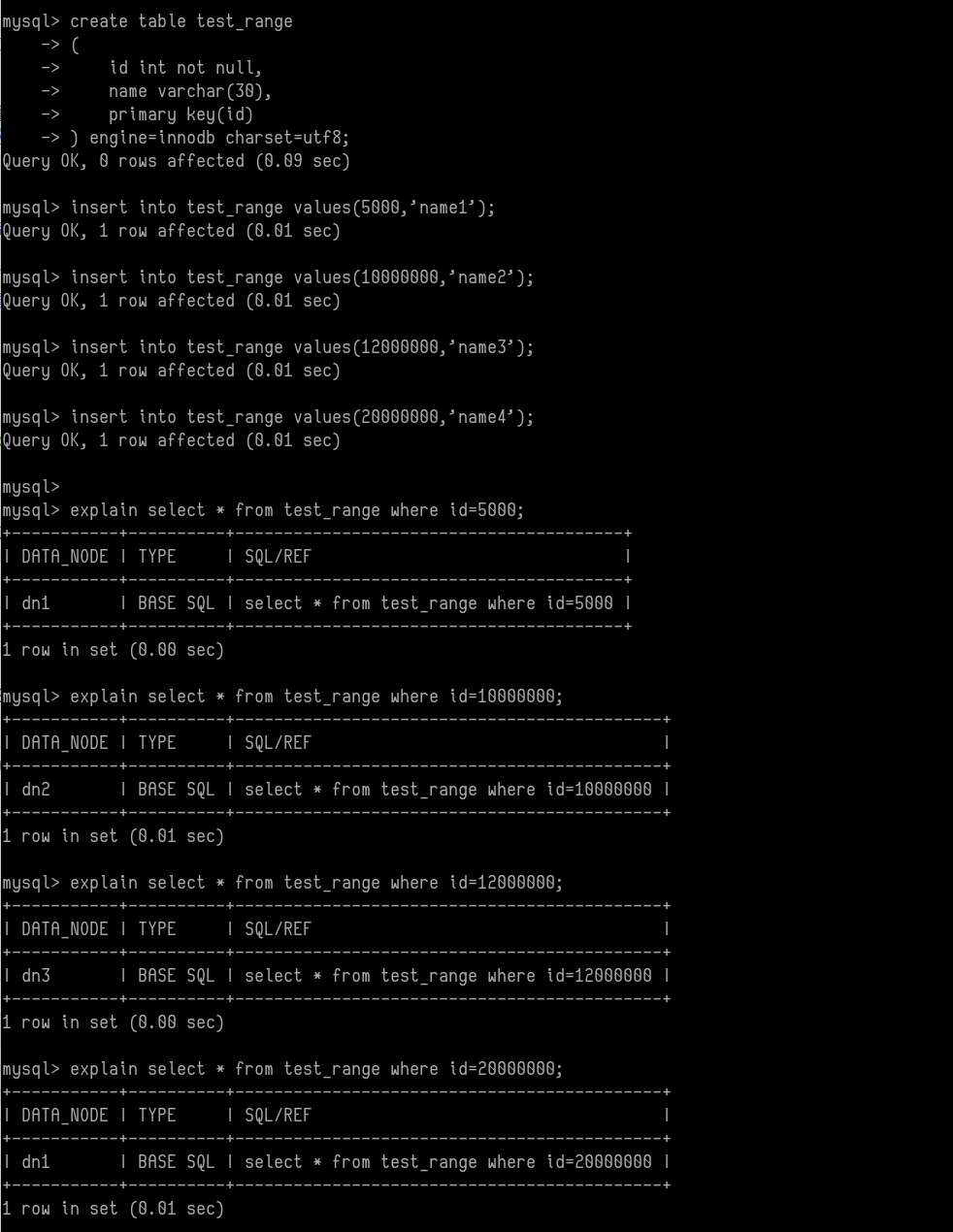
通过创建test_range表,我们插入了四条数据,分别是id=5000,10000000,12000000,20000000。可以看到5000存放在分片1上,10000000存放在分片2上,12000000存放在分片3上。这个和我们在partition-number-range.txt中配置的文件一样。而当我们插入20000000的时候,因为该值大于其他区间数字,不在任何区间范围,它就会存放到我们配置的defaultNode节点上。而如果我们不配置defaultNode的话,这里插入就会报错。
4.如何修改K和M
这里我们可以发现,K设置成了1000,而M设置成了10000,如果我们的客户想要个性化,需要修改这两个数字应该怎么做呢?可以查看/dble-master/src/main/java/com/actiontech/dble/route/function/NumberParseUtil.java的代码.
/**
* can parse values like 200M ,200K,200M1(2000001)
*
* @param val
* @return
*/
public static long parseLong(String val) {
val = val.toUpperCase();
int index = val.indexOf("M");
int plus = 10000;
if (index < 0) {
index = val.indexOf("K");
plus = 1000;
}
if (index > 0) {
String longVal = val.substring(0, index);
long theVale = Long.parseLong(longVal) * plus;
String remain = val.substring(index + 1);
if (remain.length() > 0) {
theVale += Integer.parseInt(remain);
}
return theVale;
} else {
return Long.parseLong(val);
}
}
}
我们可以在这个地方修改plus的值,设置成你想要设置的结果,修改完成之后需要重新编译。
5.测试一下分区重合的情况
还有一种比较特殊的情况,就是分区重合的情况。假设配置如下:
1K-5K=0
3K-10K=1
可以看到,当插入分区重合的数据4000的时候,落在了分片1上面。对于重合部分的分片值计算映射表,是根据配置文件中最先定义的区间相对应的分片节点作为选择的。
注意事项:
- 不包含“=”的行将被跳过。
- 如果区间存在重合,在对重合部分的分片字段值进行分片查找时在配置文件中最先定义的区间对应的数据节点为目的节点。
- 分片字段为整型。
- 分片字段为NULL时,数据落在defaultNode节点上,若此时defaultNode没有配置,则会报错;当真实存在于mysql的字段值为not null的时候,报错 "Sharding column can't be null when the table in MySQL column is not null"
后记
今天就介绍到这儿,有时候学习我会看看源代码。看源代码学习这是个好习惯,因为他可以帮助我们更加深入的理解软件作者写代码的一个思想。
