

问题
- PHP
- Safe_mode 打开后哪些地方受限?
- php7性能为什么提升这么高
- PHP的垃圾收集机制是怎样的
- Golang
-
阻塞的实现方式有哪些?
-
如何防止data race
-
Context的原理以及使用场景
-
Golang并发原理(协程有什么优势)以及GPM调度策略
1. 内存管理以及垃圾回收 2. Golang的网络IO模型?大量对象初始化如何优化,比如在http 接收数据时bufio的创建
-
答案
PHP
- php7性能为什么提升这么高
1. error 变为 exception
2. AST 抽象语法树
[php5] php code-> parser ->opcode -> excute
[php7] php code->parser->ast->opcode->excute
3. JIT 及时编译技术 再opcode 后面增加了类型判断以及及时编译,提升了8倍
4. zval 结构修改 内存从24 下降到16
5. zend_string 结构修改 val值从 char* 变成[]char 用来降低cpu cache miss
6. hasttable 之前是 buckets 是存储指针 指向各个bucket php7后 将怎么buchkets连在一块,分配在同一快内存
同时bucket 的大小也下降50%
7 函数调用机制 减少重复的指令 再预处理阶段就提前完成某些函数处理 ,提高处理效率
- PHP的垃圾收集机制是怎样的
1. 采用引用计数的方式 每个zval 都拥有 is_ref 跟ref_count 属性
每增加一次引用 ref_count就会加1
当ref_count = 0时,程序就自动进行gc
这里的问题在于循环引用会有问题 这个再php5.3之后就已经解决了
解决的方式是
php 会将 ref_count 减一后 还大于0 ,则就会认为他可能是一个垃圾
会将这些放入一个垃圾buffer池中。对这个池进行dfs 将每个节点进行ref_count -1 并标记是否是‘已减’状态
再遍历一次 将所有ref_count 不为1 的变量 清除并回收 改回收动作发送在buffer池满的情况下
GOLANG
- 阻塞的实现方式有哪些
1. sync.WaitGroup
var wg sync.WaitGroup
wg.add(1)
wg.wait
2. 空select
3. 空for 循环
4. sync.Mutex
锁上一个已经锁上的锁 会一直阻塞
var m sync.Mutex
m.lock
m.lock
5. os.Signal
信号会一直等待信号的到来
6.空channel
c := make(chan struct{})
<- c
- 如何防止data race
在代码运行先 先做竞争检测 --race
如果存在问题就会显示出来
通常有竞争检测的问题常常发生在 多goroutine 同时修改变量或者map
一般处理的方式就是加锁
- Context的原理以及使用场景
context 作用: 用来控制goroutine 的生命周期
type Context interface {
Deadline()
Done()
Err()
Value(key interface) interface()
}
有这四种方法,所以可以基于以下方式生成context 实例 WithDeadline WithCancel 等等
场景1 多goroutine 执行超时通知 使用 context.withiTimeout
场景2 函数方法之间传递父子状态,可以实现类似 tracelog 之类的全链路追踪
- Golang并发原理(协程有什么优势)以及GPM调度策略
golang 并发依照CSP模型,原理是使用goroutine 来传递数据而不是通过加锁的方式来实现数据共享
do not communicate by sharing memory,instead sharing memory by communicating
而主流的编程如java 等 都是用过共享内存的方式实现传递数据的
协程有什么优势: 协程为轻量级线程
1.为什么轻量
线程并发执行流程:
线程是内核对外提供的服务。有内核对其进行调用和切换,线程再等待io操作时 线程会变成unrunnable,进而进行上下文切换。操作系统一般是抢占式调度。上下文切换一般发生在时钟中断或者系统调用返回前
上下文切换 顾名思义 context switch 先进行context的pop 需要进行save,然后进行switch 所以这一切流程会较为冗长
协程并发执行流程:
不依赖操作系统,golang 自己实现GMP 并发模型。并且协程称为用户态线程,其切换也发生在用户态。用户态并没有时钟中断以及系统调用
2 go协程占用内存少
go协程只占用栈内存 大约4~5kb 而一个协程约为1Mb
3 go 声明简单
一个go func 就能直接申明协程 并且能够随意创建上万个协程
- GPM 调度策略
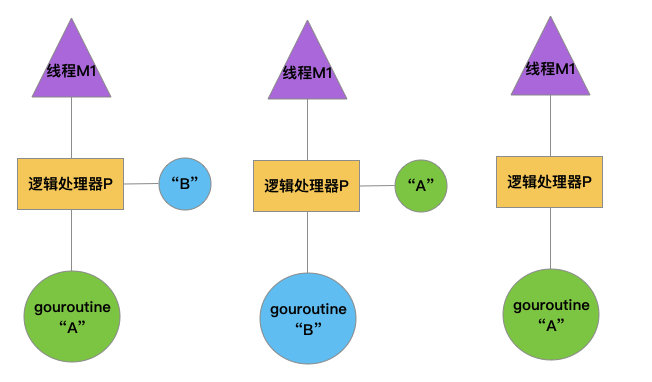
线程实现模型
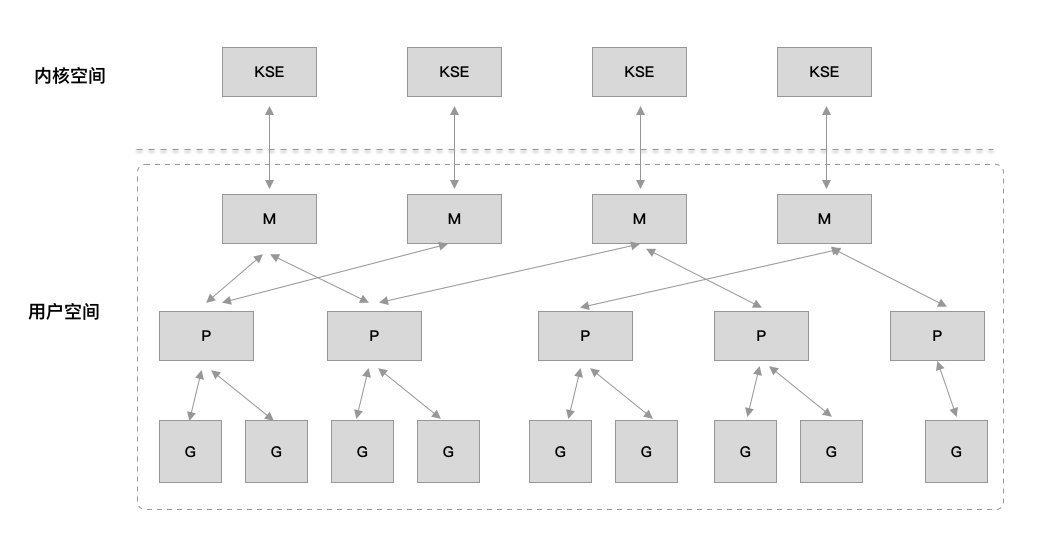
M:内核级线程的封装 G:代表goroutine P: 代表执行go代码片段的上下文环境
- go 内存管理
操作系统内存管理:
最初: 内存看成一个数组 每个元素大小为1B,CPU通过内存地址来选址,取到输入写入寄存器,进而执行机器指令。
此时遇到一个问题(如何处理多任务同时运行)
1. 内存访问冲突,2个程序同时访问同一个内存块 这是产生奔溃
2. 内存不足,因为每个程序员都需要自己申请内存。但是free 不及时,则会造成内存浪费
3. 程序开发成本高
改进I : 增加虚拟内存 所有程序使用统一的连续虚拟地址,系统会将虚拟地址翻译成真正的物理地址,再加载到内存中
改进II. 对于内存不足的情况 虚拟内存本质是将磁盘当成最终的存储,而内存当做cache,比如申请1G 的空间 其实最终内存不会用到1G的空间,只会开辟很小的一块给程序使用,以免造成申请过多内存而不使用的浪费,在内存寻址过程中,发现虚拟内存不指向真正的内存地址时,则会进行再次申请空间 本质就是常用的放在内存,不常用的放在磁盘中
CPU内存访问全过程
1. CPU使用虚拟内存访问数据,MOV指令加载到寄存器中,将地址传递给MMU
2. MMU生产PTE地址,并尝试从内存中得到他
3. 如果根据PTE地址获取到真实的内存地址,则会正常读取数据,流程结束
4. 如果无法获取到真实的内存地址,则会引起缺页异常
5. 操作系统捕捉到这个异常,会重新生成一页内存,并更新页表
6. 然后回到第三步,流程结束
这里3,4步 就会涉及到一个概念 内存命中率
如果物理内存不足,则会频繁导致3,4步骤,因为磁盘的读取速度缓慢,会导致整体性能下降。cpu指标中的iowait 会很高
这里还会延伸出 CPU cache 的概念
CPU cache 是位于 cpu 与内存之间的缓存 一般有L1,L2,L3 3级缓存,用来调节 cpu 与内存 至 磁盘之间的速度,性能差
GO内存管理:
基于 tcmalloc 实现的内存管理
内存池的概念:
如果不用池的话
{
malloc mmap 申请的代价:
1. 系统调用会导致 程序进入内核态,分配完成后,再返回用户态
2. 频繁的申请,会存在大量的内存碎片
}
使用池的优劣
{
1. 提前申请一大片内存,用户使用的时候不用频繁进入内核态
2. 因为是连续的空间,不会存在内存碎片的问题
3. 局部性良好 因为访问的是同一个空间
4.会造成一定的内存浪费,但是对于昂贵资源的申请,则建立资源池是个非常好的实现
}
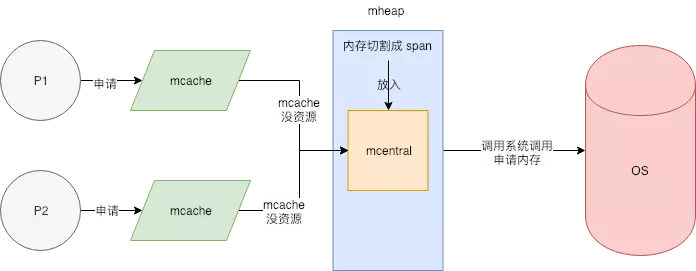
内存池 mheap
go语言再启动之初 ,就想操作系统那里申请一大块内存用来当做内存池,放入mheap中,
mheap 有以下几个结构
spans(512Mb) -> bitmap(16Gb) -> arena(512GB)
各个span 通过链表的方式连接在一起 形成各个功能的spans 用sizeclass 作为标识
针对不同的大小的对象申请内存 使用不同的sizeclass 做申请 一共有67种
这种链表形式 叫做 mcentral
至于mcache 则是 mcentral 的cache
什么叫做逃逸分析
c语言中 使用malloc在堆上分配内存 使用free 释放内存
go语言中,编译器自动帮你找到malloc的变量,使用堆内存 这个分析过程就是 逃逸分析
如图所示
7 go垃圾回收
go 1.3 之前是采用 mark sweep
后面采用三色标记法
三色标记法的过程 类似二叉树的层次遍历
1. 将所有待处理的变量表尾白色
2. 从根节点触发 BFS 将可达的 变量放入待处理区, 标记为灰色
3. 将待处理区的节点取出 将其标记为黑色 将其子节点放入待处理区
4. 直到待处理区为空 则所有不可达的变量就是垃圾变量 对其进行清除
在2,3步骤中 程序此时仍然在运行,所以会有新的变量产生,或者旧变量被引用,为了对这块加控制,所以有 write barrier 写屏障的概念 此时会触发stw
何时GC 堆上分配32Kb 内存时就要进行回收检查 主动gc 是阻塞的
8 Golang 的网络io模型
网络io模型
阻塞io blocking io
非阻塞io non-blocking io
多路复用io multiplexing io
信号驱动io signal-driven io
异步io asynchronous io
io模型 需要了解的点有以下
用户态 和内核态
用户进程需要进行系统调用的时候 ,必须将其切换成内核态,才能执行包括操作cpu,操作io,外设,网络通信等等操作
等操作完毕之后,才会切换回用户态,其中包括了建立的大量上下文,这是非常消耗性能的
所以在 用户进程 以及 系统进程之间 会有2个 缓冲区
用户缓冲区 以及 内核缓冲区
而阻塞io 的 核心在于 只有从 内核缓冲区拷贝到用户缓冲区时,才通知用户进程 这就是 阻塞io
而 非阻塞io 是在于 当数据还处于内核缓冲区的时候 就通知用户进程,这就是非阻塞io
非阻塞io 如何通知用户进程呢? 就需要不断的轮询 坏处就是 cpu使用率很低
多路复用io 本质在于 轮询多个非阻塞io,只要有一个任务完成,就发起通知
多路复用io 的实现有以下几个 select poll 和epoll
纵观全局 每一个socket 其实是non-blocking io的 但是整体用户进程是 blocking 的,使用select 函数进行blocking
信号驱动io 使用sigaction 系统调用,其等待过程是non-blocking 的 这样的cpu利用率高
异步io 与其余4中 同步io 的区别 同步io 是指总有某个步骤会阻塞,而 异步io 永远不会阻塞 再内核准备数据的时候就进行返回
go语言对网络io 的优化
1. 网络库所有都封装成非阻塞方式,减少上下文切换的开销
2. 运行时加入epoll 机制,当goroutine 进行网络io 请求但是 并未就绪时,则挂起G,根据GPM 模型,此时P 会运行其他G,等刚刚的G就绪了,会会重新从就绪队列中取出,再由调度器将他们重新分配M执行
- 大量对象初始化如何优化,比如在http 接收数据时bufio的创建
优化的方式就是:创建临时对象池
灵感来自于GO的内存模型,基于tcmalloc,在程序开始阶段创建一大块内存来充当对象池
至于创建的内存空间 是来自于 栈 还是堆 则由go 专门的编译器进行逃逸分析得到的
好处在于
1. 减少用户态以及内核态之间的上下文切换
2. 减少内存碎片的产生
3. 局部良好性,相当于访问同一个内存空间
