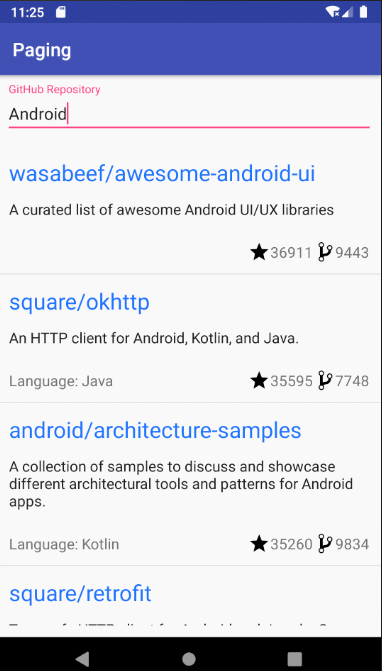
本文实现效果:
前言
一些资源
本文前置资源:
纯Database使用Paging(推荐):www.bilibili.com/video/av742…
纯Network使用Paging:(需翻墙,依然推荐):https://www.youtube.com/watch?v=eh4Wq7UrTok&list=PLk7v1Z2rk4hjCQw1RVoYPRdeIzwdz5_Fi
上面这个需要翻墙的视频我放到网盘里了:pan.baidu.com/s/1itD9eOm5…
本文源码地址(Java):gitee.com/littlecurl/…
本文参考源码地址(Kotlin):github.com/cerodriguez…
本文视频教程(我自己录的,没错,我自己录的):还没录,一定会录的 : )
Paging Library视频教程(Google官方, 需要梯子):https://www.youtube.com/watch?v=QVMqCRs0BNA
Paging Library视频教程(Google中国官方,和上面的内容一模一样):www.bilibili.com/video/av350…
Paging Library的Google Code Labs(需要梯子) :https://codelabs.developers.google.com/codelabs/android-paging/index.html
简要说明
纯Database作为数据源和纯Network作为数据源进行分页都非常容易理解,上面也给出了对应的资源地址。
但是,Database + Network 结合使用,就有点让人摸不着头脑了。而且,网上截止2020-01-12,这类的教程还很少,有些都是瞎扯,有些是讲半天废话不知道说的啥,这次,就让我来个终结版吧。
这些技术都不是我创造的,我只是学会之后将之传播,从中收获助人之乐,大家加油!
注:全文代码不完整,不要一步一步copy,完整源代码还是自行Github下载。
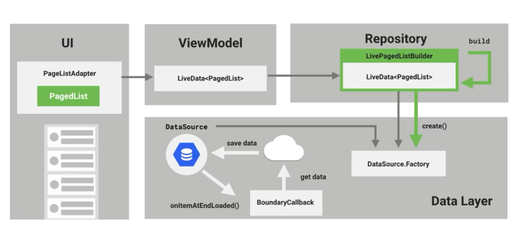
先看一下官方给出的数据流的鸟瞰图:
上图箭头顺序是我们根据UI上显示的数据,逐层深入得到的。
但是我们开发的时候,应该是倒叙开发的。
也就是以下 6 步:
-
编写
JavaBean,为获取网络数据Json反序列化做准备(Json 转成 JavaBean 叫反序列化) -
获取网络数据
Json并反序列化成JavaBean -
把
JavaBean数据插入本地数据库 -
从本地数据库中查询数据
-
在
ViewModel中将查询到的数据赋值给LiveData<PagedList<Repo>> -
UI(Activity或Fragment)中获得ViewModel来观察LiveData<PagedList<Repo>>当PagedList发生变化时,把观察到的数据送到RecyclerView的Adapter中,即adapter.submitList(repos);
以上 5 步可以分为两段内容:
一、 想办法得到LiveData<PagedList<Repo>>即PagedList
二、将PagedList中的数据送给RecyclerView的Adapter进行数据绑定
可以看到,PagedList在这之间起到了承上启下、起承转合、中流砥柱、一夫当关万夫莫开,啥啥啥啥 啥啥啥的作用! : )
接下来就开始吧!
稍等,在开始之前,先引入以下依赖(Java版):
// architecture components:lifecycle、room、paging
implementation "android.arch.lifecycle:extensions:1.1.1"
implementation "android.arch.lifecycle:runtime:1.1.1"
implementation 'androidx.room:room-runtime:2.2.3'
annotationProcessor 'androidx.room:room-compiler:2.2.3'
implementation 'androidx.paging:paging-runtime:2.1.1'
// retrofit、OKhttp
implementation "com.squareup.retrofit2:retrofit:2.4.0"
implementation"com.squareup.retrofit2:converter-gson:2.4.0"
implementation "com.squareup.retrofit2:retrofit-mock:2.4.0"
//noinspection GradleDependency
implementation "com.squareup.okhttp3:logging-interceptor:3.9.0"
// 注解
implementation 'org.jetbrains:annotations-java5:15.0'
// ui
implementation "androidx.recyclerview:recyclerview:1.1.0"
implementation "com.google.android.material:material:1.0.0"
友情提醒:
如果加上阿里云的下载源,下载依赖的速度会起飞🛫
maven { url 'http://maven.aliyun.com/nexus/content/groups/public/' }
maven { url 'http://maven.aliyun.com/nexus/content/repositories/jcenter' }
google()
jcenter()
maven { url "https://jitpack.io" }
mavenCentral()
jcenter{url "http://jcenter.bintray.com/"}
接下来正式开始!
正文
一、编写JavaBean
Android作为前端,JavaBean的格式是参照着后端返回的Json格式来编写的。
如果自己练手,可以从网上搜一些提供Json数据的接口。
比如:
1、本文访问的Github查询仓库的接口:api.github.com/search/repo… 2、WanAndroid首页查询接口:www.wanandroid.com/article/lis…
3、StackOverflow问题查询接口:api.stackexchange.com/2.2/answers…
Tip: 仅用于练手,Do not be evil。
访问第一个接口返回的数据如下
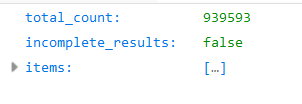
这是第一层,对应的我们可以写出下面这样的JavaBean

上面这段代码有三点需要注意:
-
这段我并没有直接给代码,而是一张截图,就证明这段其实可以不写。
摆在这里只是为了一层一层解析,思路不跳步。
-
所有属性都用
public修饰,这样可以省去Getter、Setter -
Item 是爆红的,所以我们接下来要去写Item的JavaBean
接下来我们展开items,来编写具体的item,不过,Item的属性实在是太多了

我们只需要写一些我们关心的数据即可
public class Repo {
public long id;
public String name;
public String full_name;
public String description;
public String html_url;
public int stargazers_count;
public int forks_count;
public String language;
}
如果你只需要从网络上获取数据,那么写成上面这样就可以了。
但是,我们是拿到数据之后,还要往本地数据库(Room)中插入的,所以我们要加上对应的注解:
@Entity(tableName = "repos")
public class Repo {
@PrimaryKey
@ColumnInfo(name = "id")
public long id;
@ColumnInfo(name = "name")
public String name;
@ColumnInfo(name = "full_name")
public String full_name;
@ColumnInfo(name = "description")
public String description;
@ColumnInfo(name = "html_url")
public String html_url;
@ColumnInfo(name = "stargazers_count")
public int stargazers_count;
@ColumnInfo(name = "forks_count")
public int forks_count;
@ColumnInfo(name = "language")
public String language;
}
以上需要注意三点:
-
列名称可以任意,比如驼峰命名、下划线分隔
-
属性名称必须和返回的Json格式一致,否则无法反序列化,也就得不到对应的数据
-
如果有属性名和Java关键字冲突,比如
private,可以用以下方法解决@SerializedName("private") @ColumnInfo(name = "private") public boolean privatee;不过,这次我这里并没有用到这个字段。
如果你想要的是更深层的数据,比如ower对象
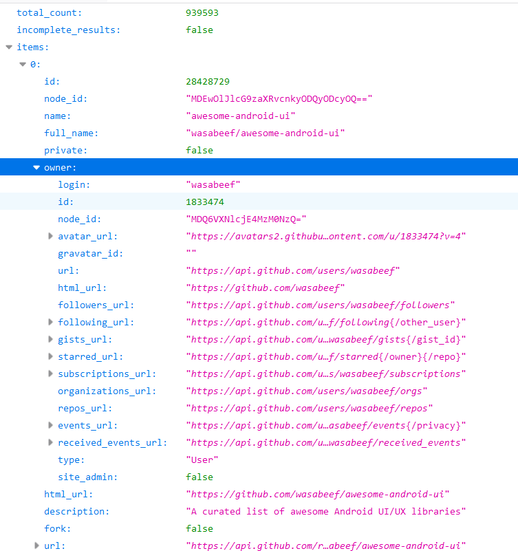
那么你需要写的是Owner对象的JavaBean,这里不再做演示了。
二、获取网络数据并反序列化成JavaBean
这里介绍Retrofit的使用方法。
官网有一个相对简单的介绍,就是三步走:
- 引入依赖
- 编写接口Api,指定部分Url
- 编写请求类,指定BaseUrl,创建Retrofit对象并调用接口中的请求,然后就可以用它来请求网络了。
0.依赖在前言中我已经给出。
1.接口如下:
public interface GitHubApi {
@GET("search/repositories?sort=stars")
Call<RepoSearchResponse> searchRepos(
@Query("q") String query,
@Query("page") int page,
@Query("per_page") int itemsPerPage
);
}
上面的代码应该可以直接理解,这是Retrofit的固定语法。
值得注意的一点就是,@GET() 里面部分Url不可以/开头,对应下面请求类中的基地址必须以/结尾,否则报错。
2.请求类如下:
public class GitHubClient {
private static final String TAG = "GitHubClient";
private static GitHubClient mInstance;
private Retrofit retrofit;
// 构造方法
public GitHubClient() {
retrofit = new Retrofit.Builder()
.client(getOkhttpClientBuilder().build())
.baseUrl(BASE_URL)
.addConverterFactory(GsonConverterFactory.create())
.build();
}
// 单例模式
public static synchronized GitHubClient getInstance() {
if (mInstance == null) {
mInstance = new GitHubClient();
}
return mInstance;
}
// 实例化接口
public GitHubApi getApi() {
return retrofit.create(GitHubApi.class);
}
// 请求网络数据
public void searchRepos(
GithubLocalCache cache,
String query,
int page,
int itemsPerPage) {
Log.d(TAG, "query: " + query + ", page: " + page + ", itemsPerPage: " + itemsPerPage);
String apiQuery = query + IN_QUALIFIER;
GitHubClient.getInstance()
.getApi()
.searchRepos(apiQuery, page, itemsPerPage)
.enqueue(new Callback<RepoSearchResponse>() {
@Override
public void onResponse(Call<RepoSearchResponse> call, Response<RepoSearchResponse> response) {
Log.d(TAG, "got a response " + response);
if (response.isSuccessful()) {
List<Repo> repos = response.body().items;
// 成功回调,数据入库
OnResponse onSuccess = new OnResponseImpl(cache);
onSuccess.onSuccess(repos);
} else {
// 失败回调,保存异常信息
OnResponse onError = new OnResponseImpl();
String errorMsg = response.errorBody().toString();
onError.onError(errorMsg == null ? "Unknown error" : errorMsg);
}
}
@Override
public void onFailure(Call<RepoSearchResponse> call, Throwable t) {
Log.d(TAG, "fail to get data");
}
});
}
}
上面代码做了三件事:
-
构造方法初始化retrofit对象 ===> 单例模式,确保运行时全局唯一,避免浪费内存。
-
调用retrofit对象的create()方法,传入接口类名,得到一个可以调用接口中方法的方法。
-
在 searchRepos() 方法中,
① 调用了上面的单例模式方法 getInstance()获得请求类的对象
② 继续调用接口类方法getApi()获得接口类实例化
③ 继续调用接口中的searchRepos()方法并传入请求参数
④ 使用enqueue() 进行异步请求
(1)如果请求成功,则将得到的response.body().items 传给成功回调方法,去插入数据库
(2)如过请求失败,则将得到的response.errorBody().toString() 传给失败回调方法,保存异常信息
三、把JavaBean数据插入本地数据库
其中成功回调方法实现如下:
@Override
public void onSuccess(List<Repo> repos) {
// 本地数据库插入返回值
cache.insert(repos);
// 设置当前页 +1,注意这里设置静态值需要使用 类名.静态值
// 否则使用new对象,然后调用对象的Setter方法是不管用的,
// 会导致无法加载下一页
RepoBoundaryCallback.lastRequestedPage = RepoBoundaryCallback.lastRequestedPage + 1;
RepoBoundaryCallback.isRequestInProgress = false;
Log.d(TAG, "设置当前页 +1---" + RepoBoundaryCallback.lastRequestedPage);
}
其中插入数据库的方法实现如下:
public void insert(final List<Repo> repos) {
// Executor
ioExecutor.execute(new Runnable() {
@Override
public void run() {
try {
// 插入数据库
repoDao.insert(repos);
} catch (Exception e) {
CRUDApi crudApi = new CRUDApiImpl();
crudApi.insertFinished("GithubLocalCache: Insert Error");
}
}
});
}
以上代码有两点需要注意
-
ioExecutor,这里使用到了Executors.newSingleThreadExecutor(),Java的四种线程池的一种---单例线程池。具体细节不再细究,简单一句话总结就是:该线程池会在并发执行时,确保按照任务提交顺序执行(即便是并发,也总会有个先来后到的),如果有线程中途执行失败了,有可能会调取其他线程来继续执行。
-
repoDao.insert(repos),这里使用到了Dao层的方法。
@Dao public interface RepoDao { @Insert(onConflict = OnConflictStrategy.REPLACE) public void insert(List<Repo> repos); }我们在写JavaBean时,指定了Repo为Entity,这里,insert()方法传入参数的泛型又是Repo,这样,Room就可以精准的识别表名,从而将数据插入进去。
失败回调方法如下:
@Override
public void onError(String errorMsg) {
RepoBoundaryCallback.networkErrors.postValue(errorMsg);
RepoBoundaryCallback.isRequestInProgress = false;
}
这里的networkErrors最终会被ViewModel拿到,在Activity中进行观察。如果内容改变,就会以Toast方式显示。
现在我们已经完成了获取网络数据,成功时将数据入库。
四、从本地数据库中查询数据
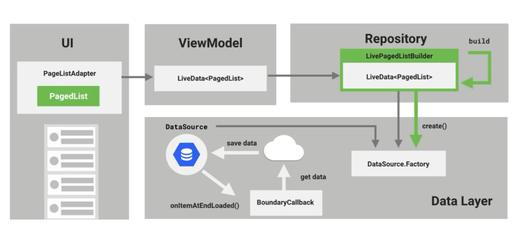
接下来我们就需要去数据库中获取数据了。
也就是实现下面箭头这一步
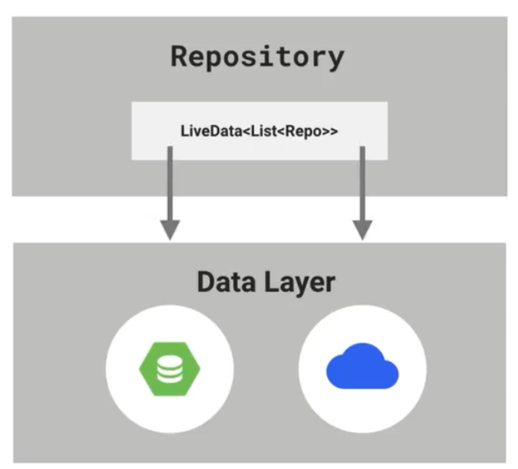
我们直接来看一下DataSource的源码
public class GithubDataSource {
private GithubLocalCache cache;
public LiveData<PagedList<Repo>> itemPagedList;
// 构造方法
public GithubDataSource(GithubLocalCache cache) {
this.cache = cache;
}
public RepoSearchResult search(String query) {
DataSource.Factory<Integer, Repo> dataSourceFactory = cache.reposByName(query);
// 每次查询都创建一个新的边界回调
RepoBoundaryCallback boundaryCallback = new RepoBoundaryCallback(cache, query);
LiveData<String> networkErrors = RepoBoundaryCallback.networkErrors;
PagedList.Config config = new PagedList.Config.Builder()
.setInitialLoadSizeHint(2 * DATABASE_PAGE_SIZE) // 第一次加载多少数据,必须是分页加载数量的倍数
.setPageSize(DATABASE_PAGE_SIZE) // 每次加载多少数据
.setMaxSize(Integer.MAX_VALUE) // Maximum number of items to keep in memory
// MaxSize必须满足 MaxSize >= PageSize + 2 * PrefetchDistance
.setPrefetchDistance(5) // 距底部还有几条数据时,加载下一页数据
.setEnablePlaceholders(false) // 是否启用占位符,若为true,则视为固定数量的item,比如PositionalDataSource
.build();
// Get the paged list
itemPagedList = new LivePagedListBuilder(dataSourceFactory, config) // 从本地数据库中拿数据
.setBoundaryCallback(boundaryCallback) // 如果触发边界回调,再从网络中获取
.build();
// Get the network errors exposed by the boundary callback
return new RepoSearchResult(itemPagedList, networkErrors);
}
}
上面代码主要就两个方法:构造方法和查询数据方法
因为获取数据库需要Context参数,所以我们会在Activity中获取数据库对象,然后再将数据库对象传递给需要用到的类。
查询数据方法里面,先是去本地查询了一下 cache.reposByName(query); 返回一个DataSource工厂,然后根据工厂及每次从数据库中查询的数据量去创建一个PagedList,将PagedList和网络请求异常组装成一个对象进行统一返回。
另外,这里使用了建造者模式建造了一个PagedList.Config对象,用来配置分页加载的一些参数。
三种分页的区分
如果是纯从DataBase中获取数据,那么就没有前面的成功、失败回调了,这里也不需要RepoBoundaryCallback,直接返回一个PagedList即可
如果是纯从Network中获取数据,那么就没有前面的**@Dao**、@Entity了,这里也不需要RepoBoundaryCallback,Android提供了三种DataSource:PositionalDataSource、ItemKeyedDataSource、PageKeyedDataSource,直接继承它们中的一个去实现对应的方法即可。
但这是DataBase+Network,这里的DataSource不需要继承Android提供的三种DataSource,也就不需要重写它们的方法了。但是,这里需要一个PagedList的边界回调。当RecyclerView从PagedList中获取数据触发到List边界时,就会触发这个回调。
public abstract static class BoundaryCallback<T> {
public void onZeroItemsLoaded() {}
public void onItemAtFrontLoaded(@NonNull T itemAtFront) {}
public void onItemAtEndLoaded(@NonNull T itemAtEnd) {}
}
这个边界回调需要实现以上两个个方法,onItemAtFrontLoaded()在这里没有使用,具体实现如下:
public class RepoBoundaryCallback extends PagedList.BoundaryCallback<Repo> {
private String query;
private static final String TAG = "RepoBoundaryCallback";
// 保存最新的请求页数,当请求成功时,递增 1
public static int lastRequestedPage = 1;
// 避免同一时刻触发多次请求
public static boolean isRequestInProgress = false;
public static MutableLiveData<String> networkErrors = new MutableLiveData<String>();
private GithubLocalCache cache;
public RepoBoundaryCallback(GithubLocalCache cache, String query) {
this.cache = cache;
this.query = query;
}
/*
一开始,PagedList为空,RecyclerView想要渲染数据时,触发此方法
相当于初始化数据,获取第一页数据
*/
@Override
public void onZeroItemsLoaded() {
Log.d("RepoBoundaryCallback", "onZeroItemsLoaded");
requestAndSaveData(query);
}
/*
RecyclerView渲染PagedList中最后一项数据时(不算prefetch),触发此方法
相当于上拉加载
*/
@Override
public void onItemAtEndLoaded(Repo itemAtEnd) {
Log.d(TAG, "onItemAtEndLoaded");
Log.d(TAG, "query:" + query);
requestAndSaveData(query);
}
//
private void requestAndSaveData(String query) {
// 避免同一时刻多次请求
if (isRequestInProgress) return;
isRequestInProgress = true;
// retrofit对象实例化,请求数据并插入到数据库中
GitHubClient.getInstance().searchRepos(
cache,
query,
lastRequestedPage,
NETWORK_PAGE_SIZE
);
Log.d(TAG, "NETWORK_PAGE_SIZE: " + NETWORK_PAGE_SIZE);
}
}
上面代码主要就是两个方法
onZeroItemsLoaded() 初始化数据 和onItemAtEndLoaded() 加载更多数据
这里和DataSource是整个DB+Network代码流程中最关键的两环:分页的核心逻辑,因为俩之前,是网络请求和数据库插入,都是在准备数据,终于在DataSource这一环节通过与BoundaryCallback的配合,准备好了数据:PagedList,接下来,就要准备和UI打交道了。
五、在ViewModel中把查询到的数据赋值给LiveData<PagedList<Repo>>
我们前面通过网络请求 ===> 插入数据库 ===> 查询数据库 终于得到了PagedList,即,需要分页展示的数据集合。
众所周知,ViewModel是JetPack中用于管理数据的地方。
所以,我们要在ViewModel中获取一份PagedList的数据,也就是下图所示的虚线箭头--->。
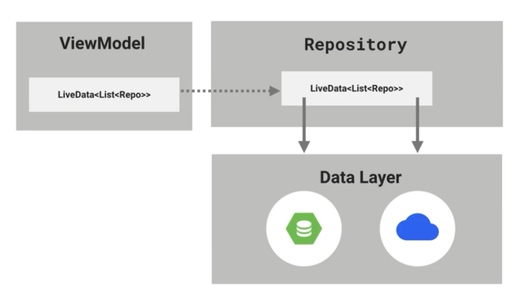
直接看ViewModel的代码
public class SearchRepositoriesViewModel extends AndroidViewModel {
private GithubDataSource githubDataSource;
private MutableLiveData<String> queryLiveData = new MutableLiveData<String>();
// 构造方法
public SearchRepositoriesViewModel(@NonNull Application application, GithubDataSource githubDataSource) {
super(application);
this.githubDataSource = githubDataSource;
}
// SearchRepositoriesActivity.onCreate()查询方法
public void searchRepo(String queryString) {
queryLiveData.postValue(queryString);
}
// 使用 queryLiveData
private LiveData<RepoSearchResult> repoResult = Transformations.map(
queryLiveData,
it -> githubDataSource.search(it) // 调用DataSource中的方法
);
// 构造 repoResult
public LiveData<PagedList<Repo>> repos = Transformations.switchMap(
repoResult,
it -> it.data
);
public LiveData<String> networkErrors = Transformations.switchMap(
repoResult,
it -> it.networkErrors
);
// SearchRepositoriesActivity.onSaveInstanceState()查询方法
public String lastQueryValue() {
return queryLiveData.getValue();
}
一个构造方法
因为继承自AndroidViewModel,所以必须传个Application参数
因为要调用DataSource中的search()方法,获取到RepoSearchResult,再将其映射为PagedList和networkErrors,所以需要传递一个githubDataSource参数。
一个初始查询方法
searchRepo(String queryString) 接收来自Actvity的查询参数,将推送到queryLiveData中。
三个map方法
第一个map,从queryLiveData中取出String,调用githubDataSource.search(it),返回查询数据。
其他两个switchMap,分别取出刚刚查询出来的数据的PagedList和networkErrors。
一个Activity恢复显示时调用的查询方法。
上面有两点迷惑行为我还没搞懂
1、query为啥要转为MutableLiveData,我现在还没看懂,明明普通字符串就可也啊,为啥要用MutableLiveData,就是为了装X?还是说,ViewModel的要求?
2、map和switchMap,看来源码的注释,依然没看懂:)
虽然很迷惑,但大致上还是能看懂这些代码的。
继续往下看。
六、UI(Activity或Fragment)中获得ViewModel来观察LiveData<PagedList>当PagedList发生变化时,把观察到的数据送到RecyclerView的Adapter中,即adapter.submitList(repos);
我们来完成最后一部分UI拼图
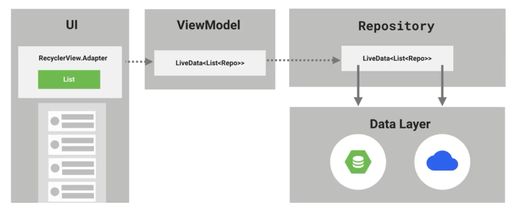
这一部分最主要的就是一个PagedListAdapter了。
Adapter代码其实都是固定套路,没啥看的,唯一有看头的就是ViewHolder绑定数据了。
我直接贴一下代码
public class RepoViewHolder extends RecyclerView.ViewHolder {
private TextView name;
private TextView description;
private TextView stars;
private TextView language;
private TextView forks;
private Repo repo;
public RepoViewHolder(@NonNull View view) {
super(view);
name = view.findViewById(R.id.repo_name);
description = view.findViewById(R.id.repo_description);
stars = view.findViewById(R.id.repo_stars);
language = view.findViewById(R.id.repo_language);
forks = view.findViewById(R.id.repo_forks);
view.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent(Intent.ACTION_VIEW, Uri.parse(repo.html_url));
view.getContext().startActivity(intent);
}
});
}
public void bind(Repo repo){
if (repo == null) {
Resources resources = itemView.getResources();
name.setText(resources.getString(R.string.loading));
description.setVisibility(View.GONE);
language.setVisibility(View.GONE);
stars.setText(resources.getString(R.string.unknown));
forks.setText(resources.getString(R.string.unknown));
} else {
showRepoData(repo);
}
}
private void showRepoData (Repo repo){
this.repo = repo;
name.setText(repo.full_name);
// if the description is missing, hide the TextView
int descriptionVisibility = View.GONE;
if (repo.description != null) {
description.setText(repo.description);
descriptionVisibility = View.VISIBLE;
}
description.setVisibility(descriptionVisibility);
stars.setText(String.valueOf(repo.stargazers_count));
forks.setText(String.valueOf(repo.forks_count));
// if the language is missing, hide the label and the value
int languageVisibility = View.GONE;
if (!TextUtils.isEmpty(repo.language)) {
Resources resources = this.itemView.getContext().getResources();
language.setText(resources.getString(R.string.language, repo.language));
languageVisibility = View.VISIBLE;
}
language.setVisibility(languageVisibility);
}
public static RepoViewHolder create (ViewGroup parent){
View view = LayoutInflater.from(parent.getContext())
.inflate(R.layout.repo_view_item, parent, false);
return new RepoViewHolder(view);
}
}
完结!
结尾
本文源码资源:gitee.com/littlecurl/…
我本以为这篇能写一万字呢,结果还不到4500
是不是写的有点着急了?
说一个Bug
其实这样尽管已经实现了分页查询,但还是有个Bug,就是当你第一次启动程序,查询了几页之后,比如查询了5页内容,这时候,你退出了程序。再次进入程序时,首先会去Database里面查询,当查询到最下方时,因为没有记录当前已经查到第多少页了,所以它会从第 1 页开始查询,直到查到第5页之后,你这里才能拿到更多数据。
关于这个问题,有人说:每次查询,都把最新页数记录下来,比如SharedPreference,或者记录到数据库中。等下次触发到边界时再查出来这个数。
这是目前大多数人的解决方案,但其实也不是很优雅,因为,在这期间,你中间的数据有可能增删,那样,你上次记录的那个页码有可能就不对了。
另一种不是很优雅的解决方案是可以通过LayoutManager获得当前所有Item的数量,然后除以你每页显示的数量,来判断该去查询第几页了。
我并没有在Demo中解决这个Bug!因为两个解决方案都不是很优雅,所以,优雅的解决这个问题的任务,留给你了,思考思考,或许能想出来类似 P = NP的问题,加油!
关于这个问题,网上讨论还是很多的,典型的两个如下:
StackOverflow:stackoverflow.com/questions/5…
Github Issue:github.com/android/arc…
其中**ChrisCraik**是Android Paging Library的官方维护人之一(竟然能看到活人说话:)
由于
再来个简短的总结吧。
总结:Paging Core elements
-
PagedList
- Collection
- Loads data in pages
- Asynchronous data loading
-
DataSource
-
Base Class for loading snapshots of data
-
Can be backed by:
① Network
② Database
③ File
④ Any other source
-