

在上一篇文章中我们可以看到对象是由calloc()方法开辟内存空间的,那这个方法底层都干了什么,这时我们就需要查看源码。
1.calloc源码分析
我们先来看一段代码:

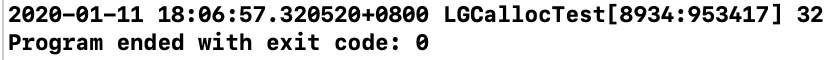
通过代码和输出结果可以得知我们申请了24字节的内存,但是系统实际开辟了32字节的内存,到底是为什么要这么做呢?点进去查看源码实现: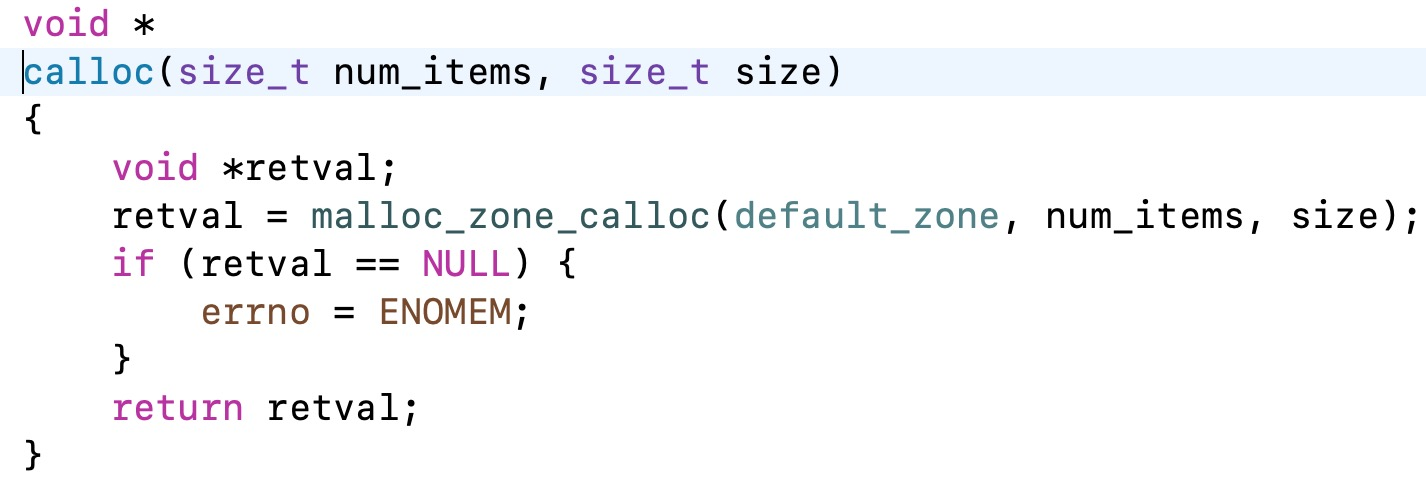
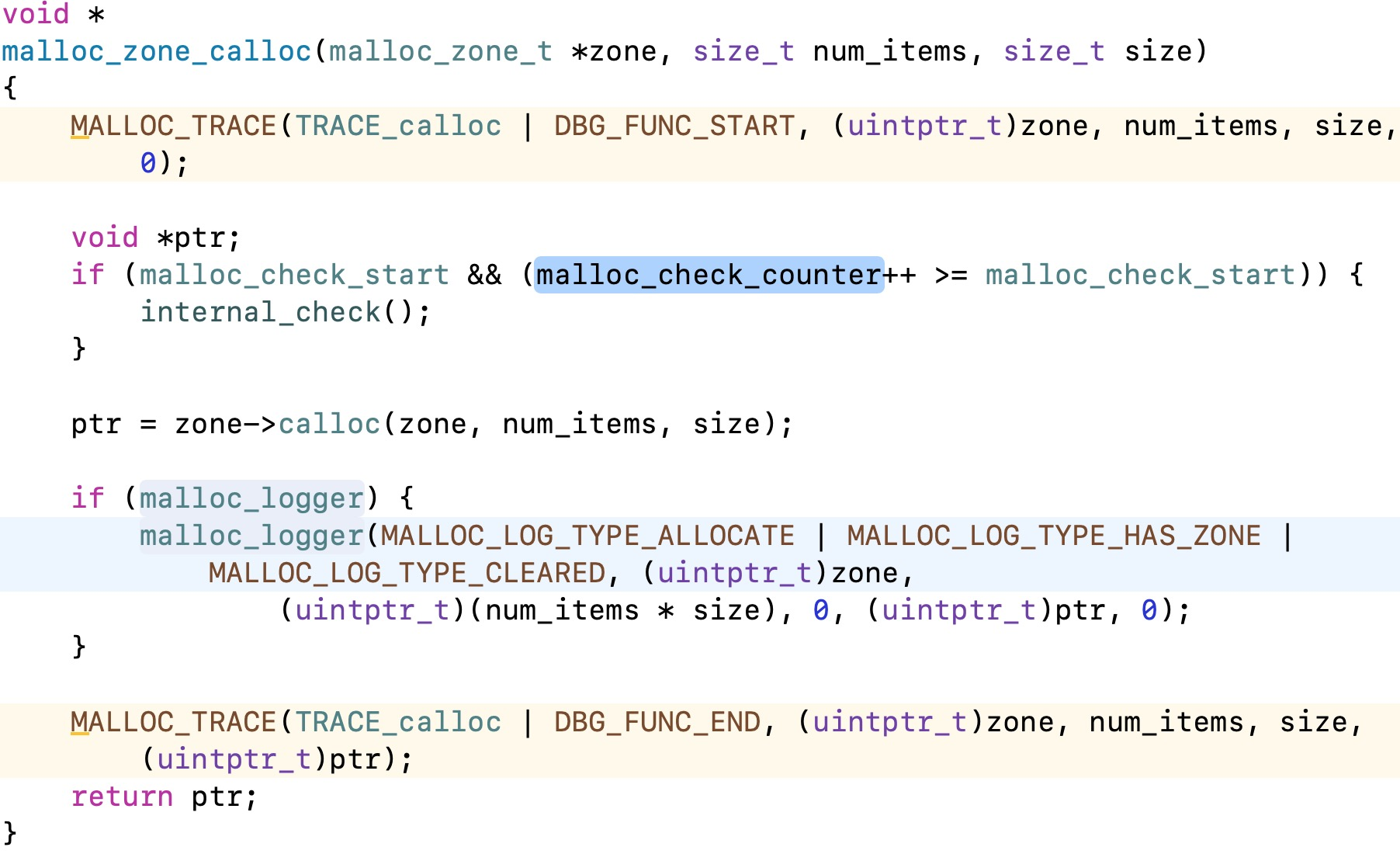
接下来通过lldb可以找到nano_malloc()方法,直接去搜索可以看到源码: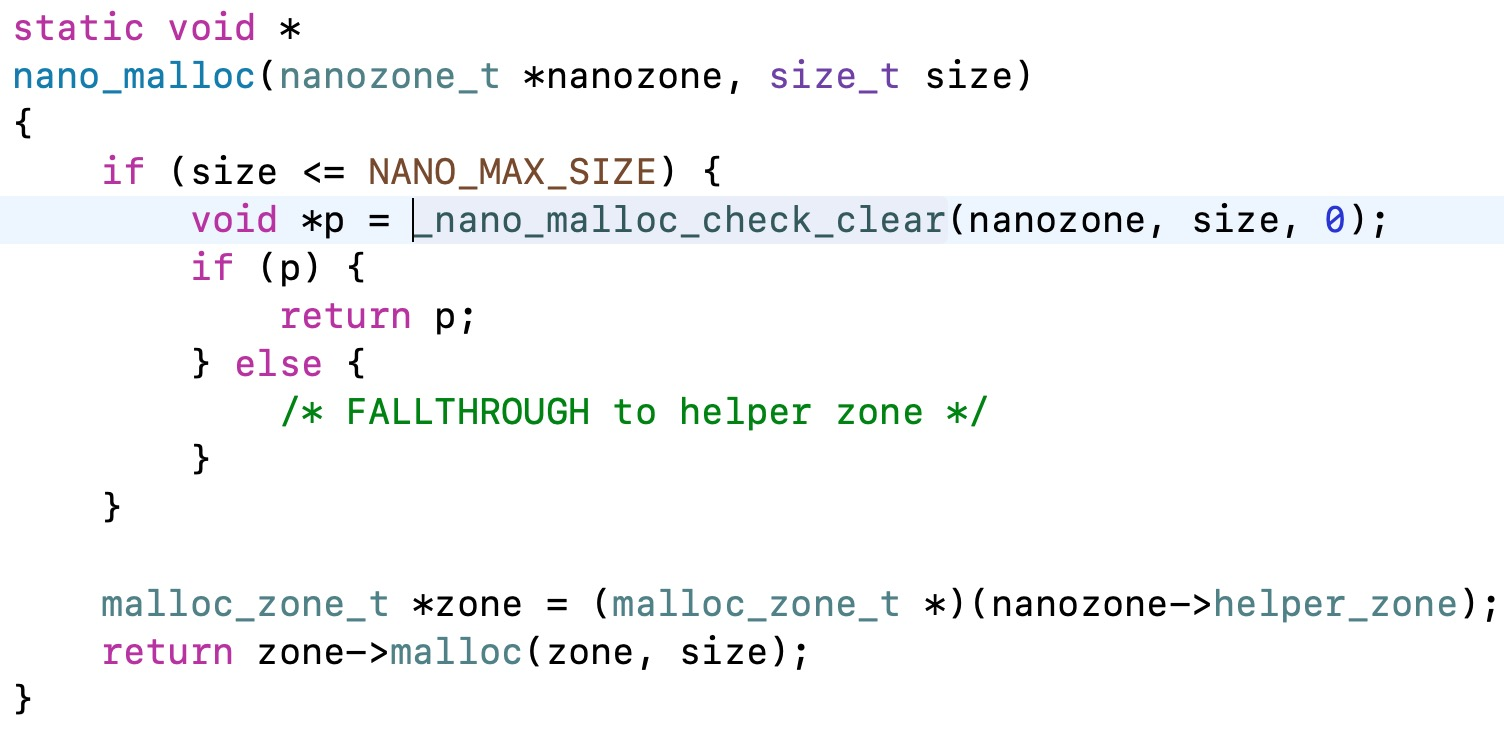
继续跟进去: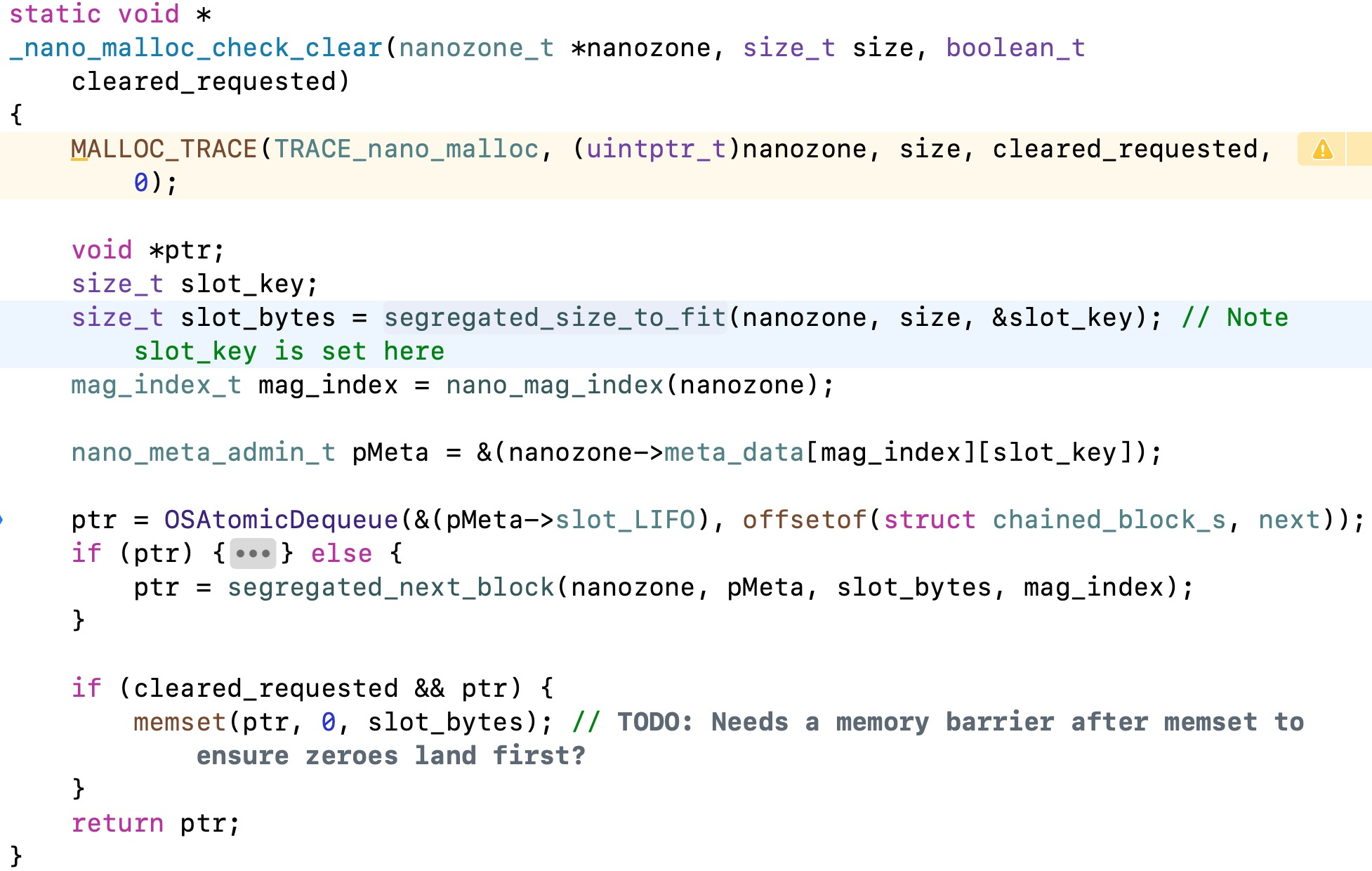
通过查看这段源码可以发现,slot_bytes就是系统最终开辟的内存空间,所以我们需要查看一下segregated_size_to_fit()方法: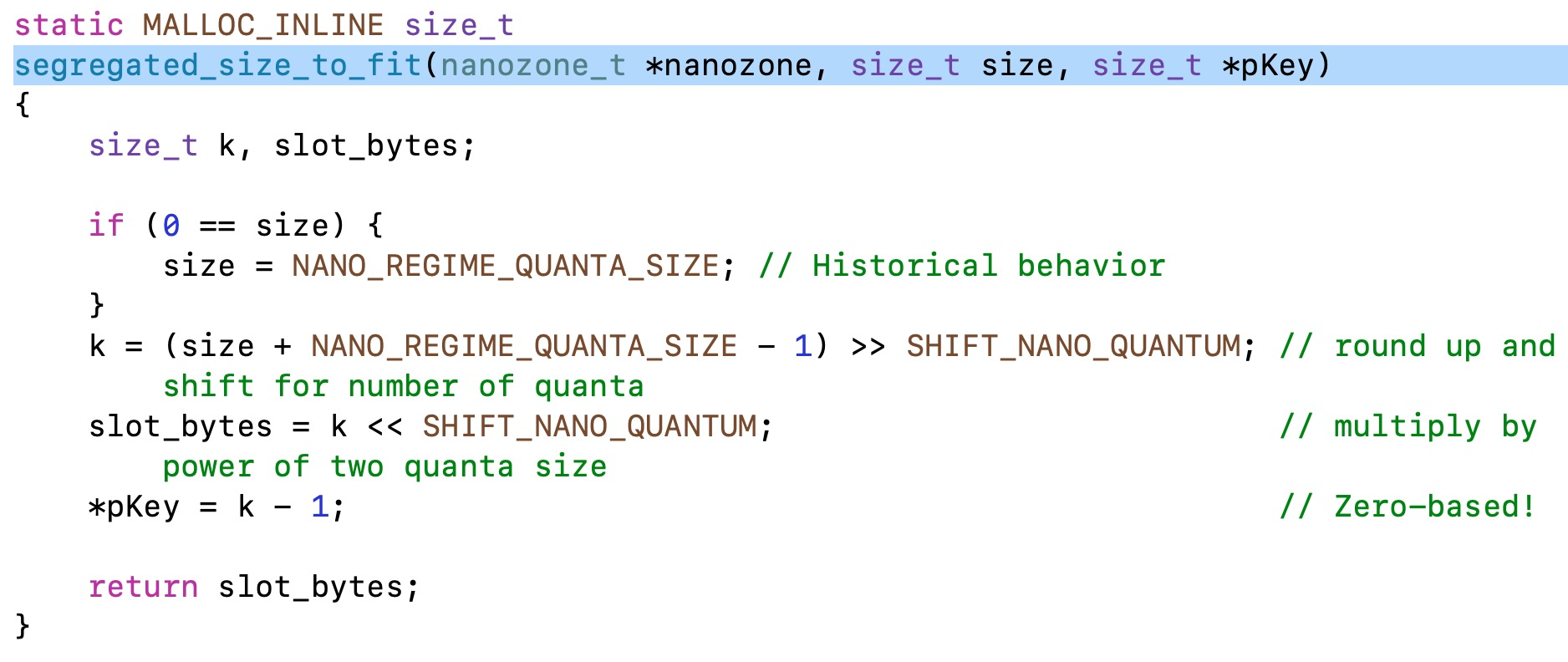
再去查看一下宏定义:
这个方法的功能是通过算法进行16字节对齐,这也就能解释开篇时为何申请24字节系统却开辟32字节的问题。
结合上一篇文章中对象的属性8字节对齐可以总结出:
- 对象的属性是进行的8字节对齐
- 对象本身是进行的16字节对齐
2.内存对齐
既然我们通过源码分析得出了系统会在开辟内存空间时进行内存对齐,那么内存对齐的规则是什么?以及内存对齐的原因和带来的好处有哪些?
2.1 内存对齐规则
1.数据成员对⻬规则:结构(struct)(或联合(union))的数据成员,第⼀个数据成员放在offset为0的地⽅,以后每个数据成员存储的起始位置要 从该成员⼤⼩或者成员的⼦成员⼤⼩(只要该成员有⼦成员,⽐如说是数组, 结构体等)的整数倍开始(⽐如int为4字节,则要从4的整数倍地址开始存储。
2.结构体作为成员:如果⼀个结构⾥有某些结构体成员,则结构体成员要从其内部最⼤元素⼤⼩的整数倍地址开始存储(struct a⾥存有struct b,b ⾥有char、int 、double等元素,那b应该从8的整数倍开始存储) 。
3.收尾⼯作:结构体的总⼤⼩,也就是sizeof的结果,必须是其内部最⼤成员的整数倍,不⾜的要补⻬。
2.2 内存对齐的原因及好处
a. 程序的执行效率提高
现代处理器一般都有多个级别的高速缓存,处理器访问这些高速缓存里的数据的效率要比访问内存里的数据效率高得多(就像处理器访问内存里的数据,比访问磁盘里的数据效率高得多一样)。
就像上面介绍以的一样,一般来说,CPU 总是以字大小(32 位处理器上常常为 4 个字节)访问数据,所以如果数据没有内存对齐,CPU 访问这些数据时,可能就需要执行更多次的读取操作才行。在这样的机器上,读取 2 个字节数据往往比读取 4 个字节数据慢得多。
b. 访问范围提高
对于任意给定的地址空间,如果体系架构可以确定 2 个 LSB 总是 0(例如 32 位机器),那么它可以访问 4 倍多的内存(2 个位能够表示 4 个不同状态)。从一个地址中去掉 2 个 LSB,将得到 4 字节的内存对齐,或者说“跨距”,因为地址每增加一,它就有效的增加 bit 2,而不是 bit 0。(鉴于低 2 位总是 00)这甚至会影响系统的物理设计:如果地址总线的需要少 2 位,CPU 上的管脚就可以少 2 个。
c. 原子性的保障
前面提到 CPU 每次访问数据的宽度是一个字,如果C语言程序中的数据总是内存对齐的,那么 CPU 访问数据总是原子性的,这对于许多无锁数据结构和其他并发需求的正确操作至关重要。
