Drools是一款基于Java的开源规则引擎,实现了将业务决策从应用程序中分离出来。本文是作为一个技术角度进行编写,文采有限,仅供对drools有一定了解,并且想搞清楚drools内部实现原理,并想提升编程技巧的同行学习和指正。
1、案例
一个学校把学生的信息录入系统中,想找一批篮球苗子进行培养,为中国体育事业输送人才。
(1)事实:StudentFact对象
该对象中存放了学生的基本信息。年级,性别,年龄,身高,身体素质的信息。
(2)筛选规则:SelectStudentRule描述。
2、rete算法包含的部分
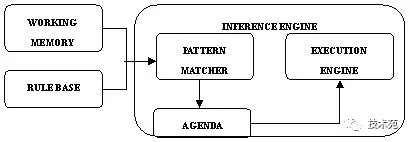
Working-Memory:存放要匹配规则的事实,也就说,存放的是业务对象,即StudentFact对象。
RuleBase:存放的是业务人员制定的形形色色的规则SelectStudentRule。
Pattern-Matcher:业务对象匹配规则的重要部分,也就是业务对象在规则网络中流动的过程的执行器。即StudentFact匹配SelectStudentRule的过程。
Agenda:一旦一个业务对象匹配了一个规则,会形成该规则和该业务对象的一个议程。即StudentFact要把该学生信息存入篮球苗子表中的事件。
Execution-Engine:业务对象匹配上一个规则后,业务对象执行规则结果的执行器。即将StudentFact信息存放如篮球苗子表中事件的执行器。
3、rete算法的网络图
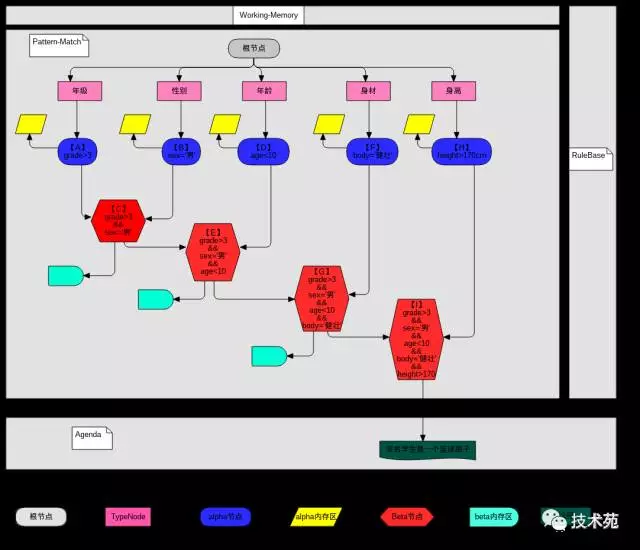
匹配过程:
(1)、匹配过程中事实在网络节点中的流转顺序为A-->B-->C-->D-->E-->F-->G-->H-->I--->规则匹配通过
(2)、从working-Memory中拿出一个待匹配的StudentFact对象,进入根节点然后进行匹配,以下是fact在各个节点中的活动图:
A节点:拿StudentFact的年级数值进行年级匹配,如果年级符合条件,则把该StudentFact的引用记录到A节点的alpha内存区中,退出年级匹配。
B节点:拿StudentFact的性别内容进行性别匹配,如果性别符合条件,则把该StudentFact的引用记录到B节点的alpha内存区中,然后找到B节点左引用的Beta节点,也就是C节点。
C节点:C节点找到自己的左引用也就是A节点,看看A节点的alpha内存区中是否存放了StudentFact的引用,如果存放,说明年级和性别两个条件都符合,则在C节点的Beta内存区中存放StudentFact的引用,退出性别匹配。
D节点:拿StudentFact的年龄数值进行年龄条件匹配,如果年龄符合条件,则把该StudentFact的引用记录到D节点的alpha的内存区中,然后找到D节点的左引用的Beta节点,也就是E节点。
E节点:E节点找到自己的左引用也就是C节点,看看C节点的Beta内存区中是否存放了StudentFact的引用,如果存放,说明年级,性别,年龄三个条件符合,则在E节点的Beta内存区中存放StudentFact的引用,退出年龄匹配。
F节点:拿StudentFact的身体数值进行身体条件匹配,如果身体条件符合,则把该StudentFact的引用记录到D节点的alpha的内存区中,然后找到F节点的左引用的Beta节点,也就是G节点。
G节点:G节点找到自己的左引用也就是E节点,看看E节点的Beta内存区中是否存放了StudentFact的引用,如果存放,说明年级,性别,年龄,身体四个条件符合,则在G节点的Beta内存区中存放StudentFact的引用,退出身体匹配。
H节点:拿StudentFact的身高数值进行身高条件匹配,如果身高条件符合,则把该StudentFact的引用记录到H节点的alpha的内存区中,然后找到H节点的左引用的Beta节点,也就是I节点。
I节点:I节点找到自己的左引用也就是G节点,看看G节点的Beta内存区中是否存放了StudentFact的引用,如果存放了,说明年级,性 别,年龄,身体,身高五个条件都符合,则在I节点的Beta内存区中存放StudentFact引用。同时说明该StudentFact对象匹配了该规 则,形成一个议程,加入到冲突区,执行该条件的结果部分:该学生是一个篮球苗子。
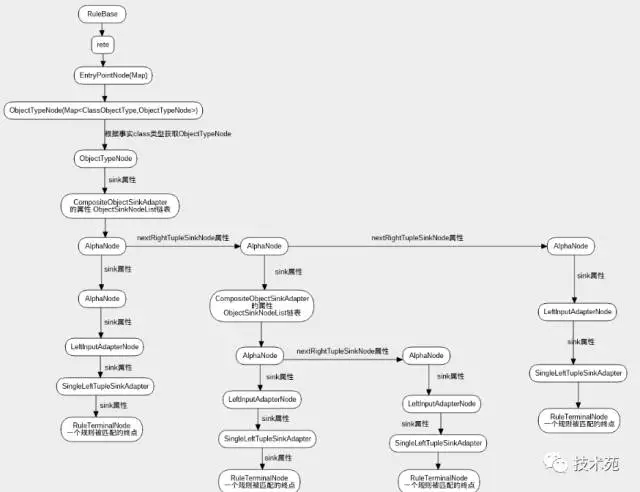
4、drools源码,一个事实匹配规则过程的原理介绍
一个Fact通过Session添加到规则网络中,如何进行规则匹配的大致过程如下:
(1)、通过根结点对象从EntryPointNode的Map集合中找到相应的EntryPointNode对象;
(2)、EntryPointNode对象有一个ObjectTypeNode的Map集合,把fact的class转化成ClassObjectType,从该集合中找到ObjectTypeNode;
(3)、OjectTypeNode对象的sink属性引用着这个fact事实的规则网络;
(4)、从sink属性中的链表中拿出一个alphaNode进行匹配,递归遍历所有alphaNode的子节点(sink属性),根据alphaNode中的条件对Fact数据进行比较。
==>(向下(子节点)是试图完整匹配一条规则),如果向下有不匹配的,表示该规则不符合当前fact,退出递归,开始向右匹配。
==>(向右(nextRightTupleSinkNode属性)开始试图匹配另一条规则)。
===>向下(当前AlphaNode子节点代表的规则的所有条件模式)匹配,如果所有的子节点alphaNode中隐藏的条件都符合, 则完全匹配一条规则,形成议程加入冲突集合,待匹配完所有的规则,再根据规则的优先级执行匹配上的规则的结果部分,更改Fact的数据。
===>向右(进行另一个规则的匹配),如果所有的子节点alphaNode中隐藏的条件都符合,则完全匹配一条规则,形成议程加入冲突集合,待匹配完所有的规则,再根据规则的优先级执行匹配上的规则的结果部分,更改Fact的数据。