

实际会遇到的问题
1.需要停止服务,在重新启动服务
2.需要修改代码(业务变更),从新上传服务
3. 程序报错重新启动(内存溢出)
目标就是下一次重新启动服务时,程序会从上一次的offset继续消费,保证不丢数据
0.8和0.10俩钟版本处理方式不一样
offset怎么去管理?
可以容忍重复消费数据,但是不允许丢数据
给kafka管理
0.8 版本offset管理
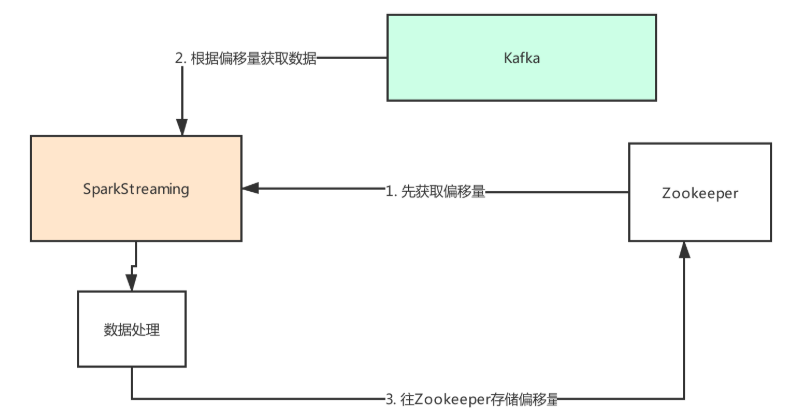
SparkStreaming程序启动后,先去zk上获取偏移量,如果没有获取到就是第一次启动,反之拿到偏移量再去kafka中获取数据,然后再进行消费数据,处理完数据后在去zk上存储消费的偏移量,这种方法来处理存储消费的偏移量
同理 存储到mysql redis也可以
为什么存到zk上?
SparkStreaming提供api,帮助我们将offset提交到zk中进行管理
因为有成熟的软件可以监控zk中offset数据,方便管理,不用开发专门的软件
另外 sparkstreaming天然提供了API可以提交到zk上
但是zk不太适合高并发,数据量不是非常大 就可以,实时任务30--60 左右 是没有太大压力的
代码中kafkaOffset08这个包下的代码是0.8版本管理offset
zk管理偏移量,主要目的是恢复数据确保下一次正常消费
checkpoint也可以帮我们存储元数据
offset,100 => checkpint => offset,100
这种方式很简单,线上为什么不采取呢?
ssc.checkpoint("hdfs://node01:8020/xxx/xxx/xxxx/wordcount/k-v(jar包的元数据信息))
因为重新打包编译更新了 程序,元数据信息就消失了
k的值是根据jar的信息进行计算出来的,所以更新了jar包这个值就丢失了
所以会采取存储到zk上
这个就是streaming提供的api
/**
* :: DeveloperApi ::
* Convenience methods for interacting with a Kafka cluster.
* See <a href="https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol">
* A Guide To The Kafka Protocol</a> for more details on individual api calls.
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>.
* Requires "metadata.broker.list" or "bootstrap.servers" to be set with Kafka broker(s),
* NOT zookeeper servers, specified in host1:port1,host2:port2 form
*/
@DeveloperApi
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
import KafkaCluster.{Err, LeaderOffset, SimpleConsumerConfig}010版本offset管理
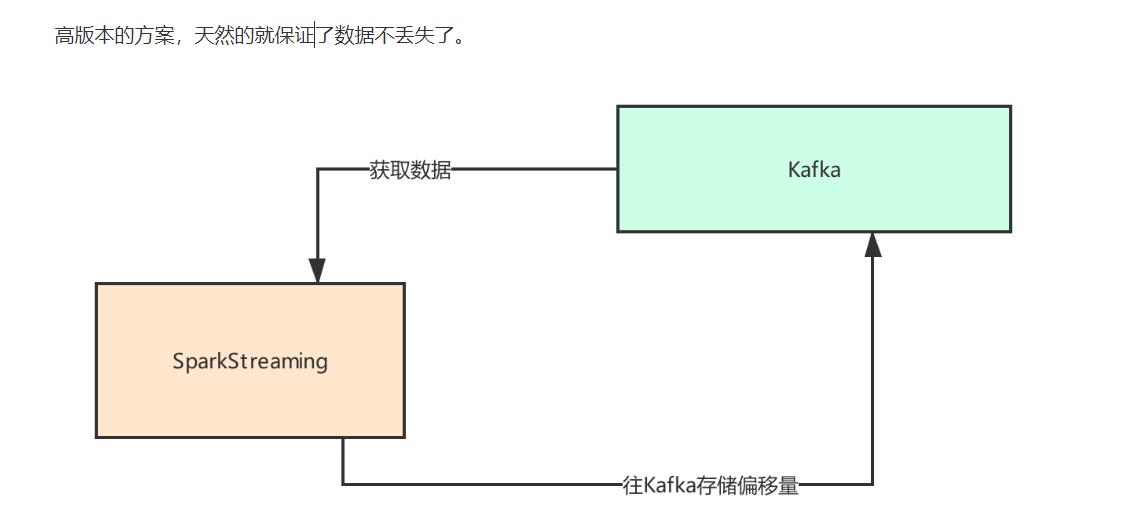
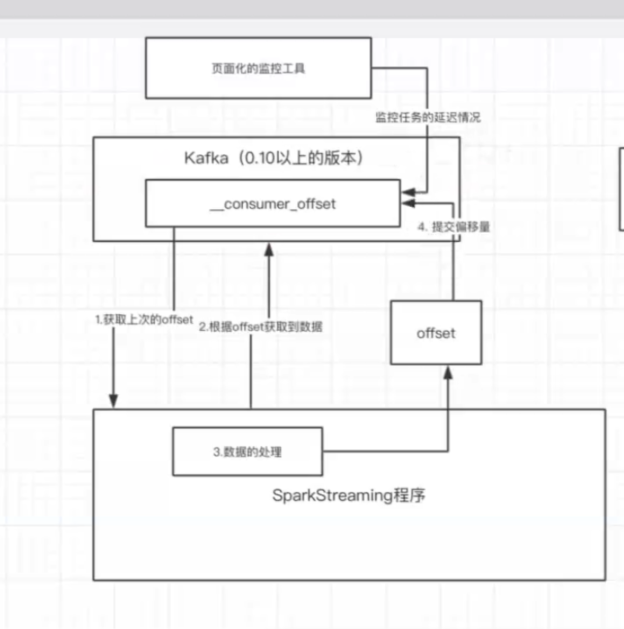
stremaing在kafka中获取到偏移量,通过偏移量获取数据进行处理,然后将offset存储在_consumer_offset中,进行offset管理
方案一
缺点 拿到stream就必须直接对stream进行foreachRDD 不能进行其他操作不然偏移量就会丢失
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition { iter =>
val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
//偏移量进行存储
}
}方案二
缺点 拿到stream就必须直接对stream进行foreachRDD 不能进行其他操作不然偏移量就会丢失
比第一种要好一点
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges// some time later, after outputs have completed
//一个批次运行完了,提交偏移量,偏移量会自动提交到 kafka的consumer_offset主题里面
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}方案三
还是用spark提供好的api,进行调用
同样 通过监听器的方式去提交偏移量
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)checkpoint
我们把偏移量存储在checkpoint上, 这样不可以 ,因为程序一升级,这个偏移量就没有了
因为修改代码重新打包编译,上线后,元数据信息就丢失了,因为获取数据的信息是根据jar的信息计算出来的,.jar包已经更改了 这个数据就获取不到了,就等于丢失了
kafka监控
KafkaOffsetMonitor-assembly-0.2.1.jar
启动命令
--offsetStorage kafka \ 监控zk下kafka目录下的偏移量的信息 看自己存到哪里去了
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--port 8088 \
--offsetStorage kafka \
--zk node01:2181,node02:2181,node03:2181 \
--refresh 60.seconds \
--retain 2.days