

一、软件安装
1.安装VMware
2.在VMware中安装centos7虚拟机

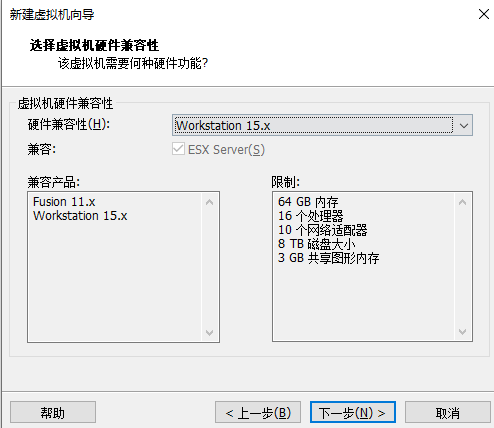
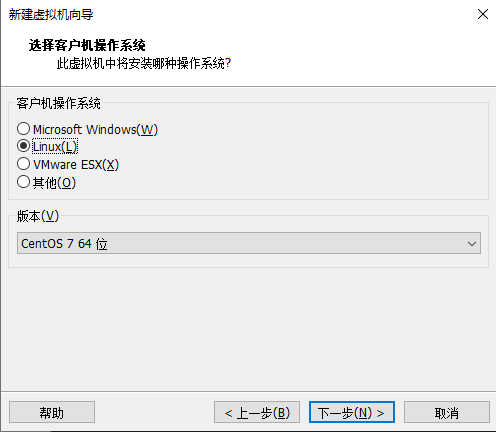
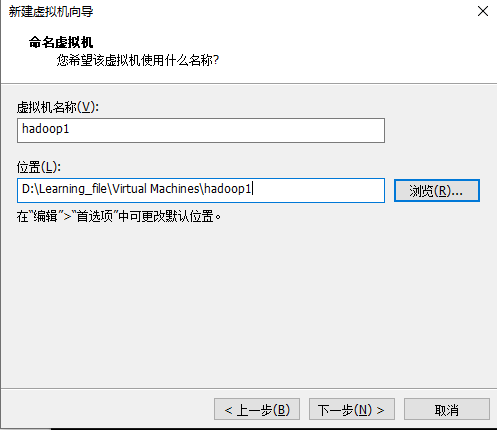
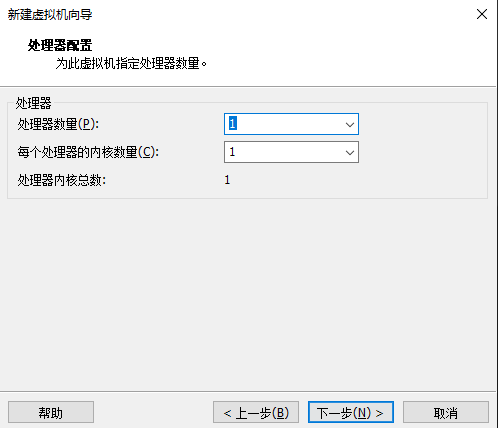
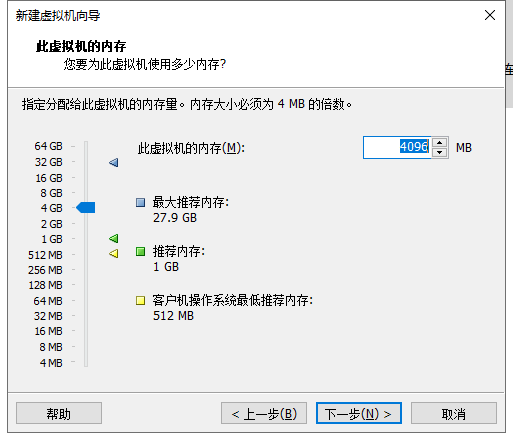
开机选择第一个
然后选中文进入安装
软件选择中选择图形界面gnome和Java环境,其他自愿
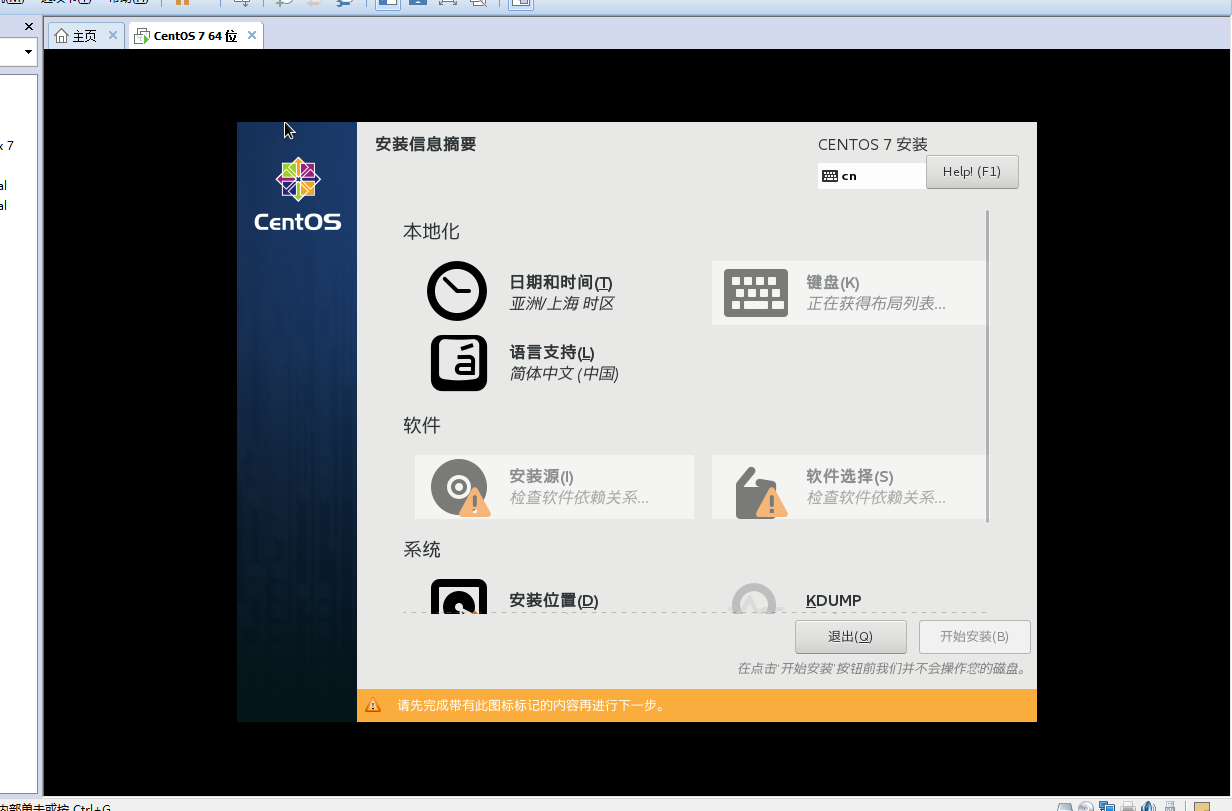

二、安装准备
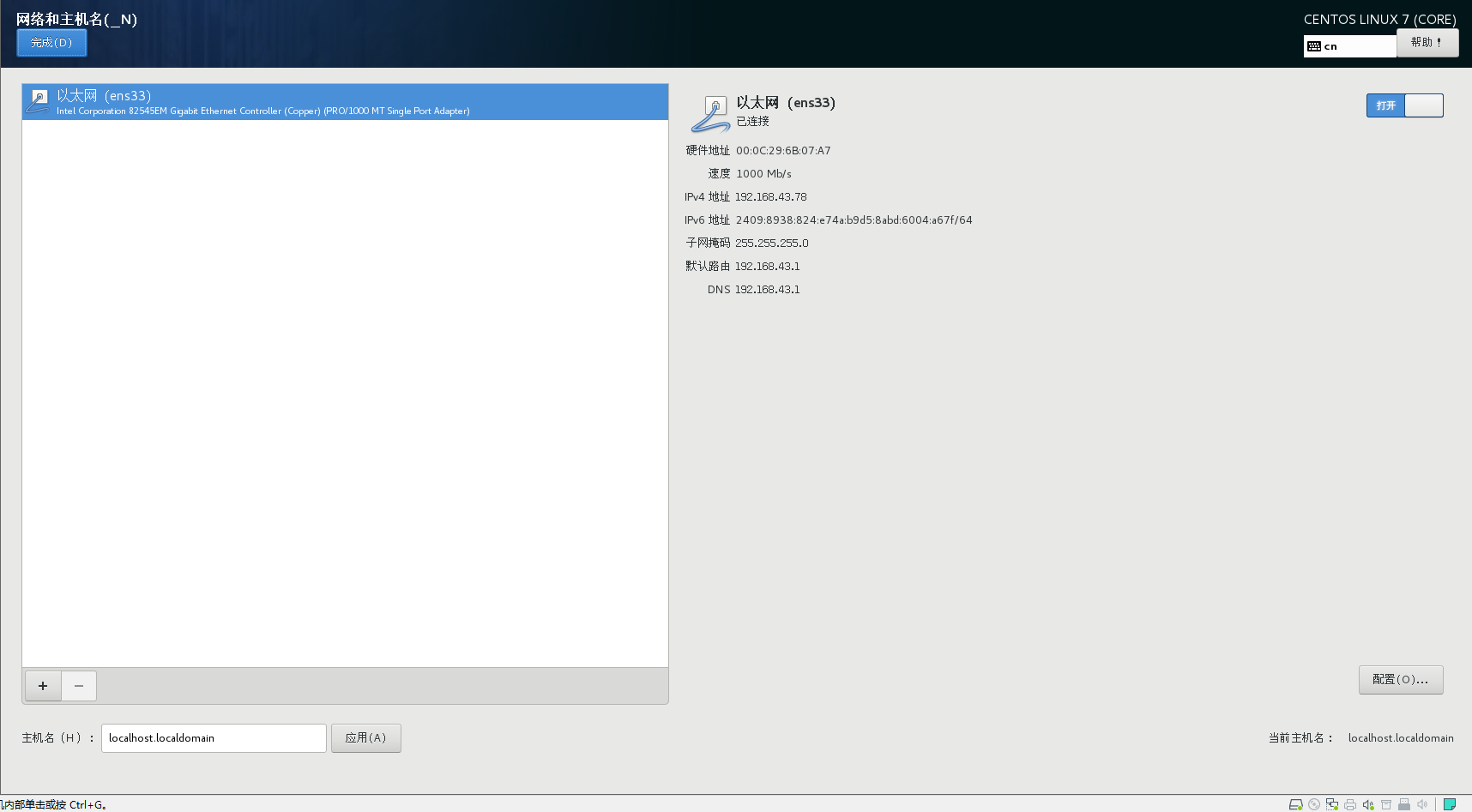
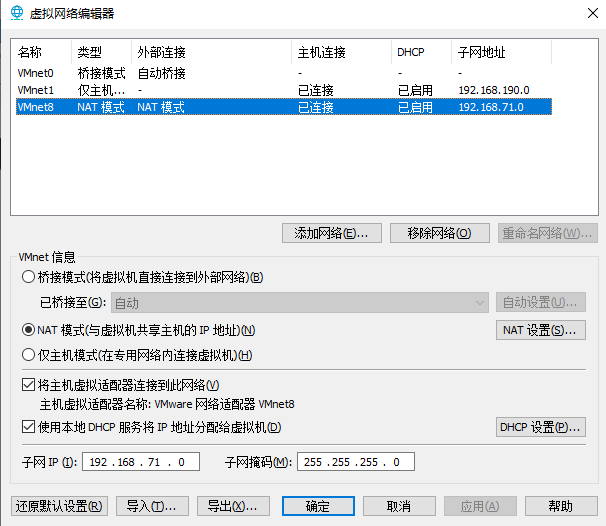
1.ip配置
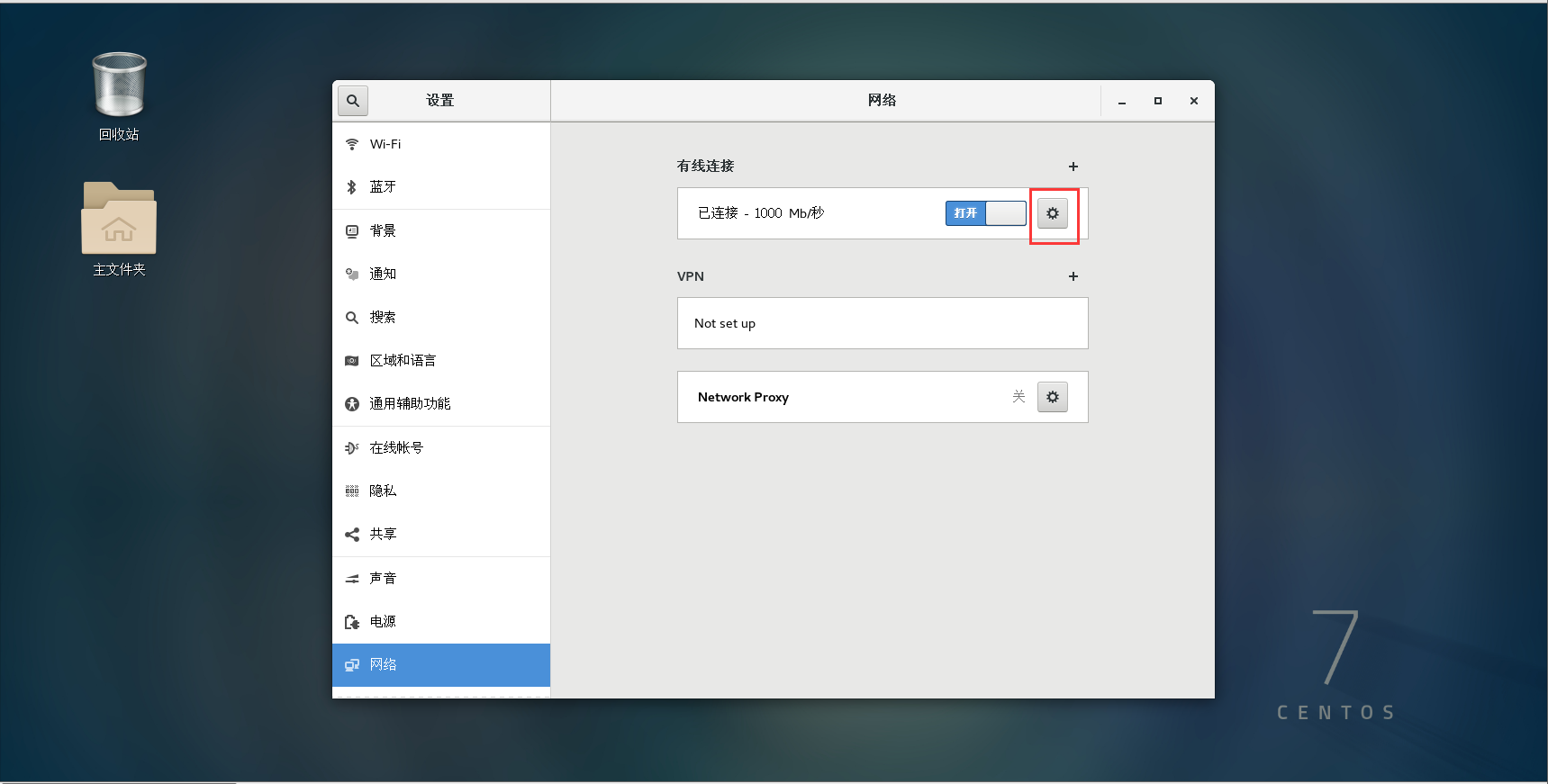
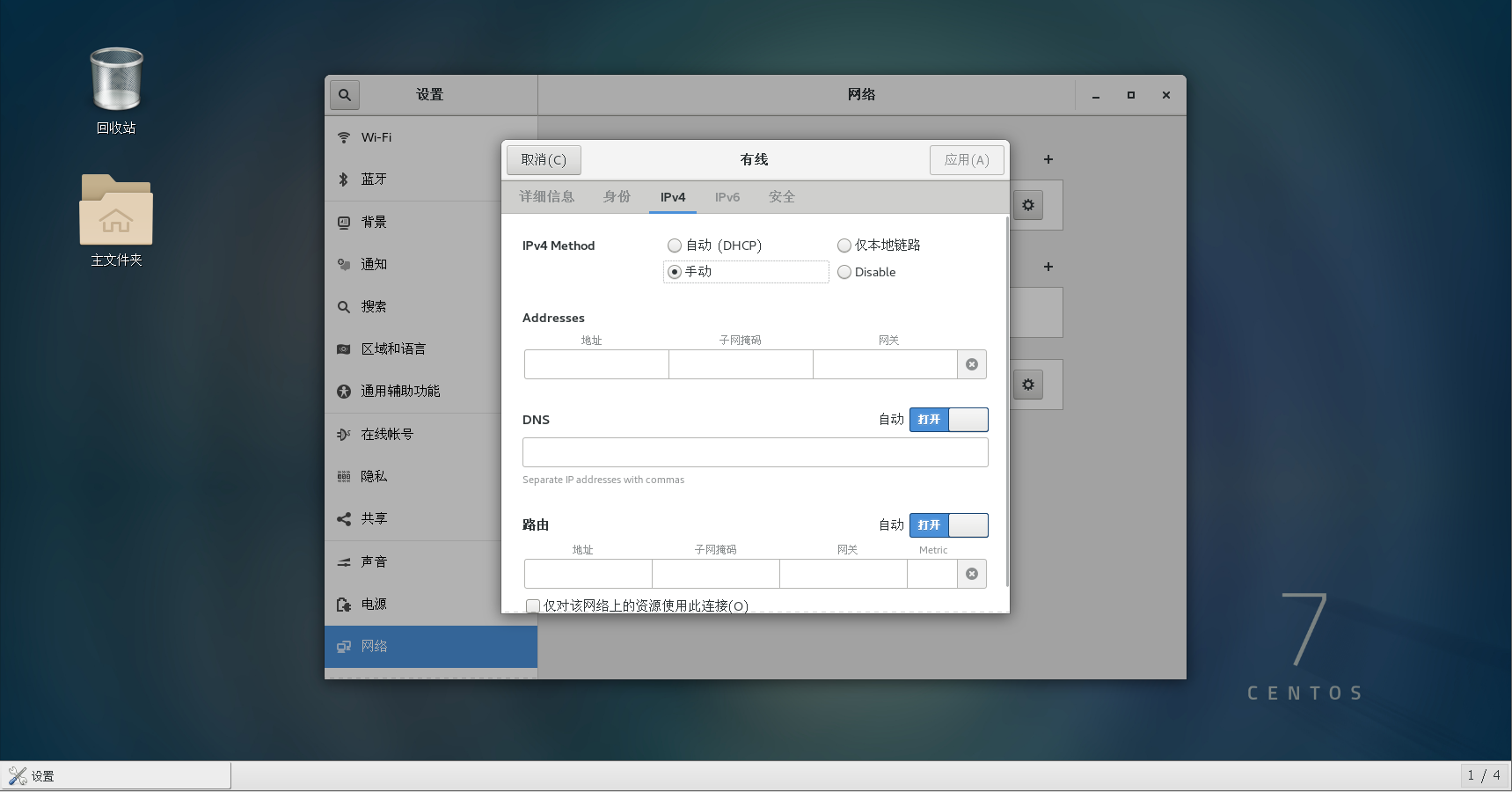
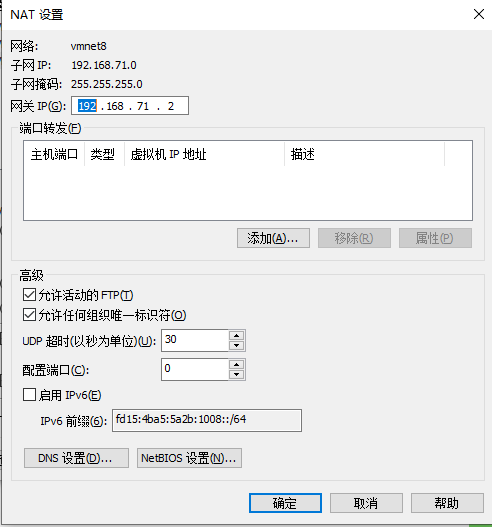
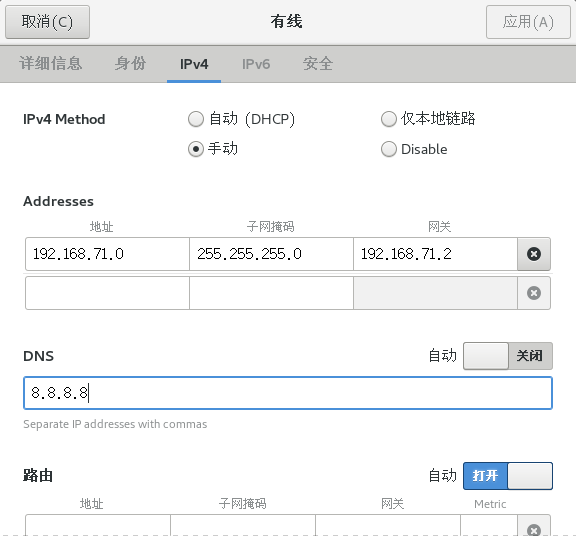
将各节点的ip设为静态。 点电源键打开设置。

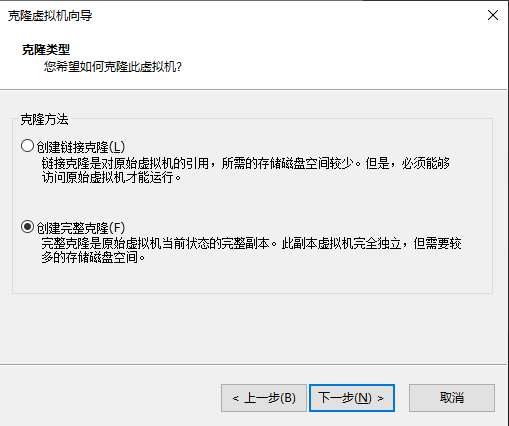
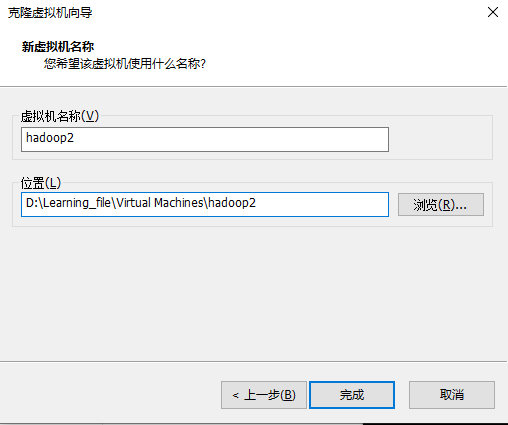
右键虚拟机-管理-克隆
下一步
选择创建完整克隆

把三个虚拟机都打开,登录
在终端下:复制命令:Ctrl+Shift+C组合键,粘贴命令:Ctrl+Shift+V组合键。
先查看一下自己的ip
ifconfig -a
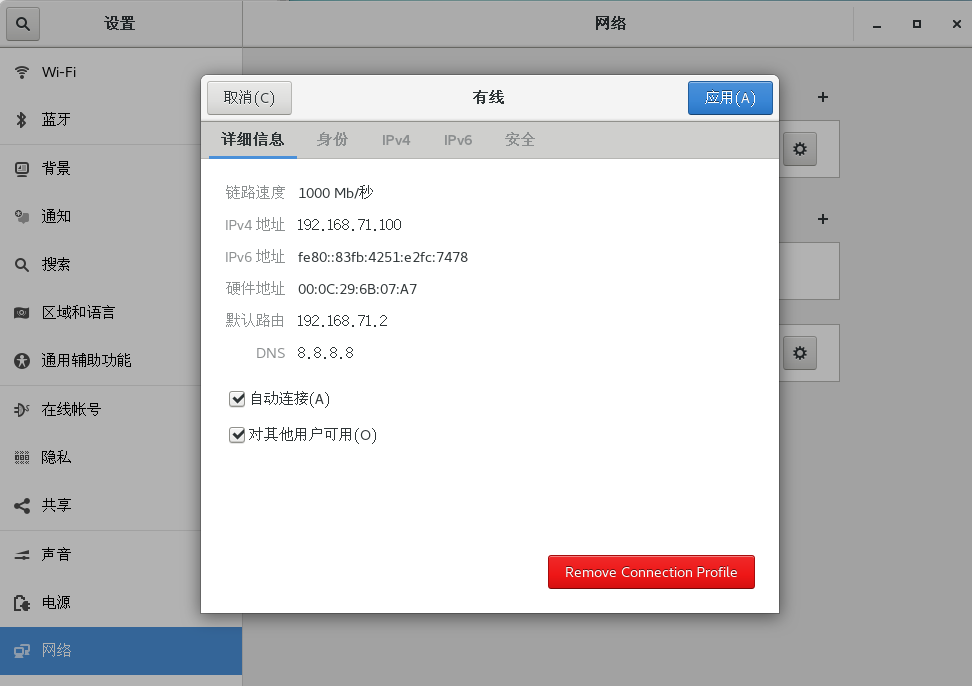
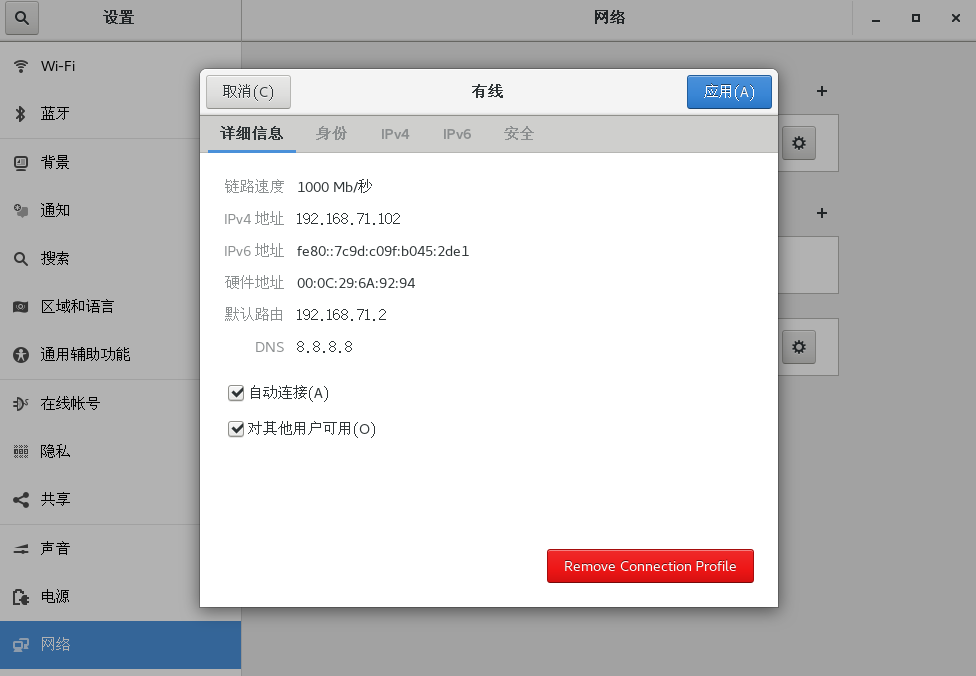
也可以直接打开设置查看自己的ip
2.配置主机名
vi /etc/sysconfig/network

【i】编辑文档,按下【Esc】即可退出编辑模式
【:w】 保存编辑的内容
【:w!】强制写入该文件,但跟你对该文件的权限有关
【:q】 离开vi
【:q!】 不想保存修改强制离开
【:wq】 保存后离开
【u】 恢复前一个操作
【Ctrl+r】重做上一个操作
【.】 是重复前一个操作
NETWORKING=yes
HOSTNAME=hadoop1

3.主机映射
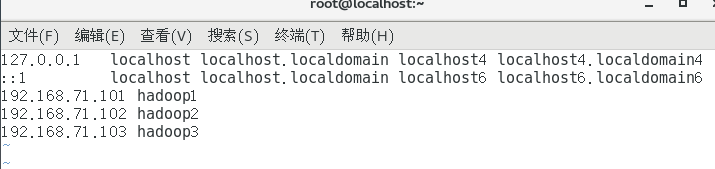
vi /etc/hosts
192.168.71.101 hadoop1
192.168.71.102 hadoop2
192.168.71.103 hadoop3
ip和之前保持一致
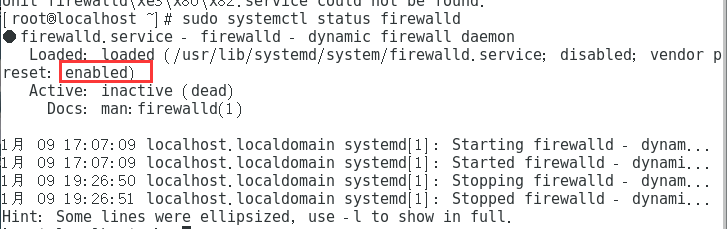
4.关闭防火墙 (centos7)
systemctl stop firewalld
systemctl disable firewalld

sudo systemctl status firewalld
5.为hadoop用户添加sudoers权限
每个节点的hadoop用户名必须相同
useradd 用户名 #添加用户命令
passwd 用户名 #设置用户密码
useradd hadoop
passwd hadoop

vi /etc/sudoers
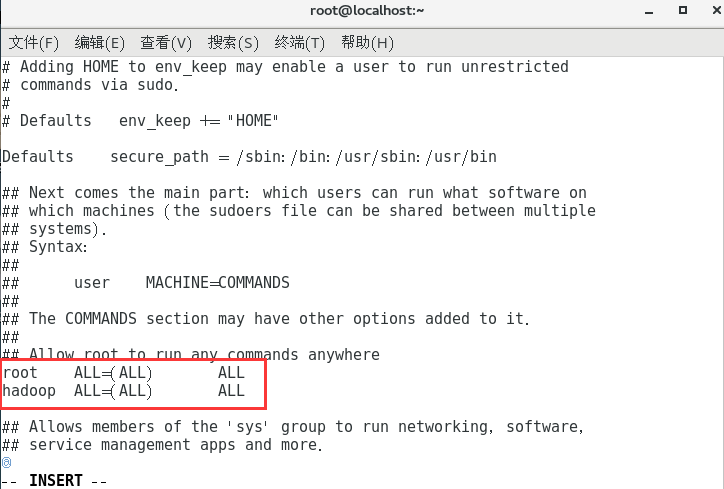
hadoop ALL=(ALL) ALL
6.配置免密登录(每台机器都要执行)
先切换到普通用户:
su hadoop
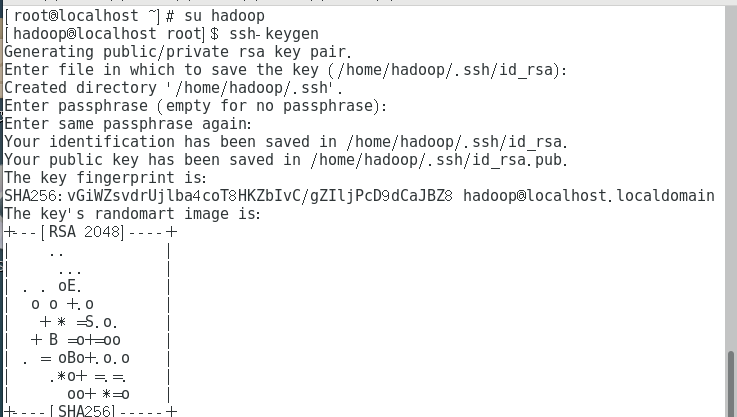
生成秘钥
ssh-keygen
一直按【Enter】
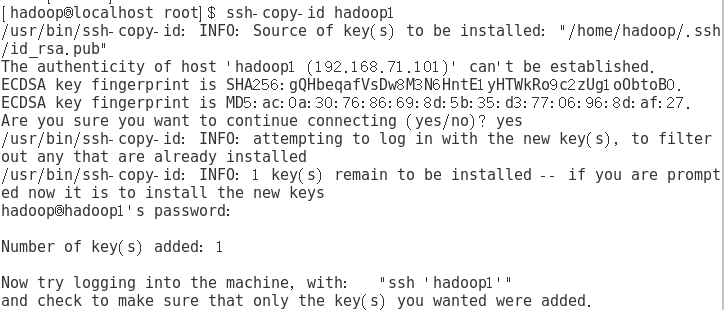
ssh-copy-id 主机名
ssh-copy-id hadoop1
输入密码
ssh hadoop1
7.安装jdk
如果图形界面安装了jdk,更新一下
需要安装openjdk-devel包,如果没网,更改一下网络的连接模式
yum install java-1.8.0-openjdk-devel.x86_64
每个节点都要安装一次
java -version

三.安装hadoop-2.7.7
集群规划(假设集群有3个节点,分别是hadoop1、hadoop2、hadoop3)
| hdfs | yarn | ||
|---|---|---|---|
| hadoop1 | namenode | datanode | nodemanager |
| hadoop2 | secondarynamenode | datanode | datanode |
| hadoop3 | datanode | resourcemanager |
注意:先在一个节点上操作,装好在远程发送到其他节点,先切换到普通用户(hadoop用户)。
1.上传安装包
ls

2.解压
tar -zvxf hadoop-2.7.7.tar.gz
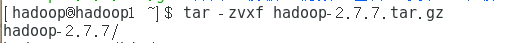
3.配置环境变量
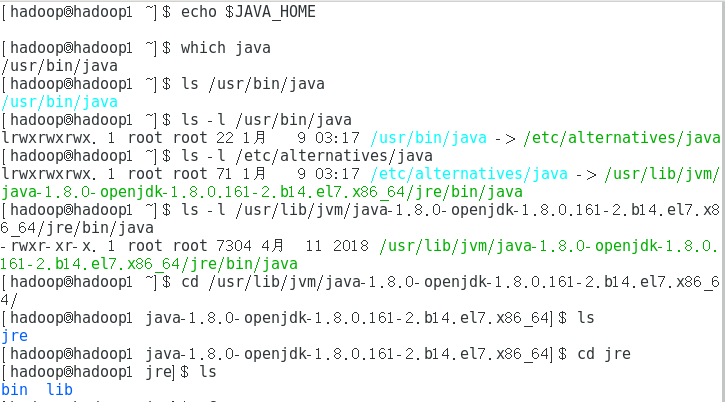
查看一下自带的java环境变量位置
[hadoop@hadoop1 ~]$ which java
/usr/bin/java
[hadoop@hadoop1 ~]$ ls /usr/bin/java
/usr/bin/java
[hadoop@hadoop1 ~]$ ls -l /usr/bin/java
lrwxrwxrwx. 1 root root 22 1月 9 03:17 /usr/bin/java -> /etc/alternatives/java
[hadoop@hadoop1 ~]$ ls -l /etc/alternatives/java
lrwxrwxrwx. 1 root root 71 1月 9 03:17 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
[hadoop@hadoop1 ~]$ ls -l /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
-rwxr-xr-x. 1 root root 7304 4月 11 2018 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
[hadoop@hadoop1 ~]$ cd /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/
[hadoop@hadoop1 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64]$ ls
jre
[hadoop@hadoop1 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64]$ cd jre
[hadoop@hadoop1 jre]$ ls
bin lib
如此来,可以暂时的断定是/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
字母“d”表示该文件是一个目录,字母”d”,是dirtectory(目录)的缩写
注意:目录或者是特殊文件,这个特殊文件存放其他文件或目录的相关信息
字母“l”表示该文件是一个链接文件。字母”l”是link(链接)的缩写,类似于windows下的快捷方式
字母“b”的表示块设备文件(block),一般置于/dev目录下,设备文件是普通文件和程序访问硬件设备的入口,是很特殊的文件。没有文件大小,只有一个主设备号和一个辅设备号。一次传输数据为一整块的被称为块设备,如硬盘、光盘等。最小数据传输单位为一个数据块(通常一个数据块的大小为512字节)
字母为“c”表示该文件是一个字符设备文件(character),一般置于/dev目录下,一次传输一个字节的设备被称为字符设备,如键盘、字符终端等,传输数据的最小单位为一个字节。 字母为“p”表示该文件为命令管道文件。与shell编程有关的文件。
字母“s”表示该文件为sock文件。与shell编程有关的文件。
sudo vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
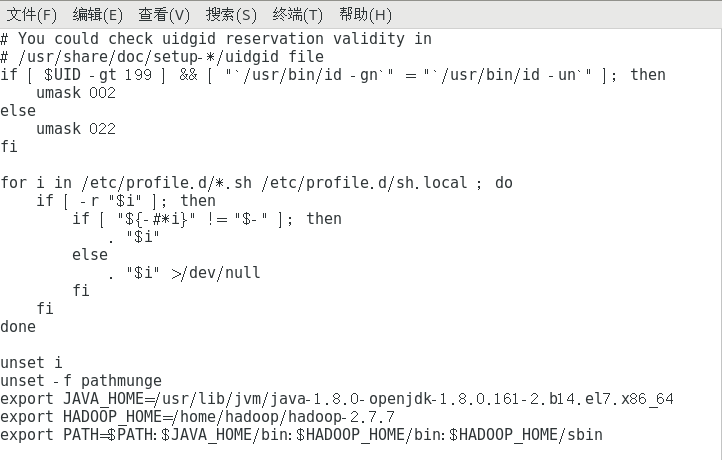
source /etc/profile
查看环境变量位置
echo $JAVA_HOME
echo $HADOOP_HOME
echo $PATH

sudo scp /etc/profile hadoop2:/etc/

4修改配置文件(6个配置文件)
进入hadoop配置文件所在目录
cd hadoop-2.7.7/etc/hadoop/

4.1.修改hadoop-env.sh文件
vi hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
4.2.修改core-site.xml文件
vi core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
<description>hdfs的主节点</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
<description>存放临时文件的目录</description>
</property>
</configuration>

4.3.修改hdfs-site.xml文件
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoopdata/name</value>
<description>namenode的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoopdata/data</value>
<description>datanode的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop2:50090</value>
<description>secondarynamenode的运行节点,和namenode不同节点</description>
</property>
</configuration>

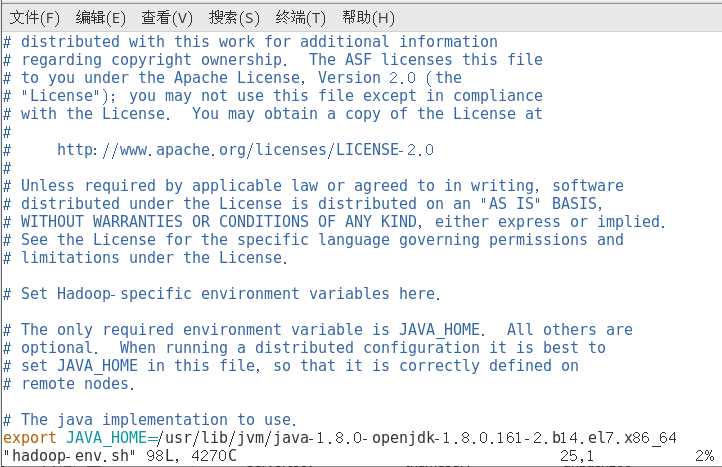
4.4.修改yarn-site.xml文件
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
<description>YARN集群的主节点</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN集群为MapReduce程序提供shuffle服务</description>
</property>
</configuration>
4.5.修改mapred-site.xml文件
先将mapred-site.xml.template文件拷贝得到mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml

vi mapred-site.xml
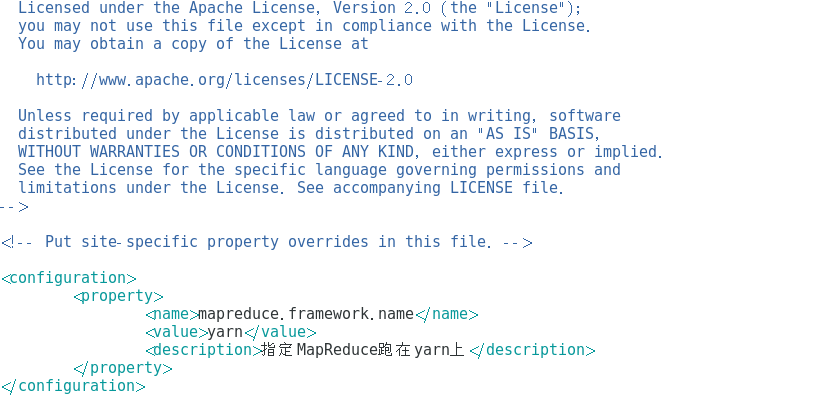
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MapReduce跑在yarn上</description>
</property>
</configuration>
4.6.修改slaves文件
vi slaves
将从节点的主机名填写在该文件中,注意不能有空格,一行一个主机名
hadoop1
hadoop2
hadoop3

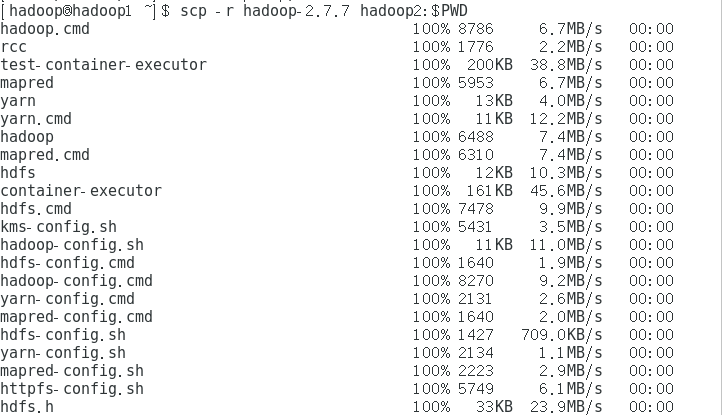
5.远程发送到其他节点
关闭重新打开终端
scp -r hadoop-2.7.7 hadoop2:$PWD
ssh hadoop2
source /etc/profile
对第三个节点也执行上述操作
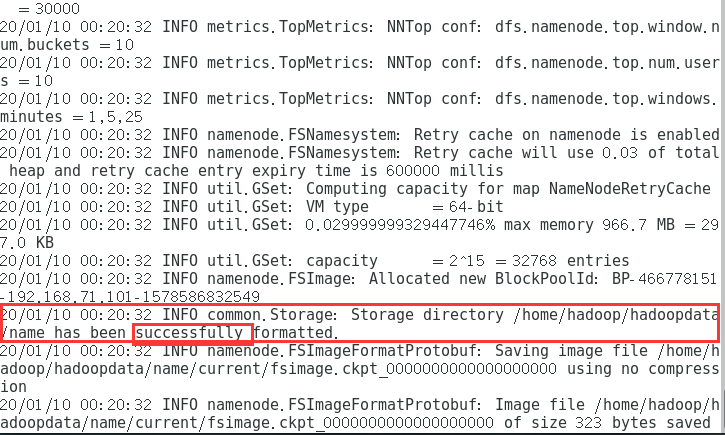
6.进行格式化
必须在namenode的节点,也就是配置的第一个节点操作
hadoop namenode -format
7、启动
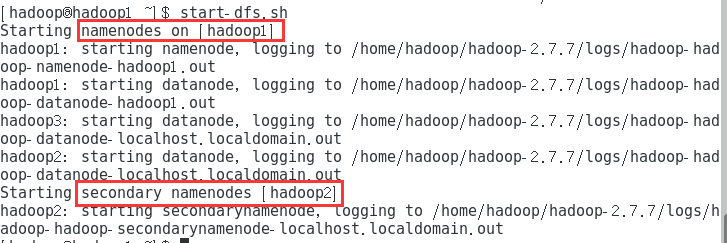
7.1启动hdfs
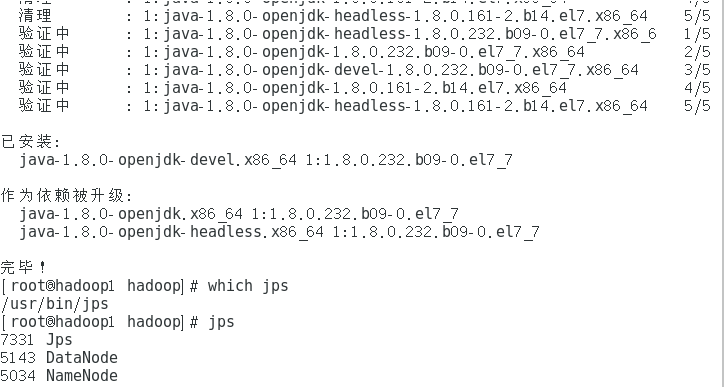
start-dfs.sh
可以在任意节点执行
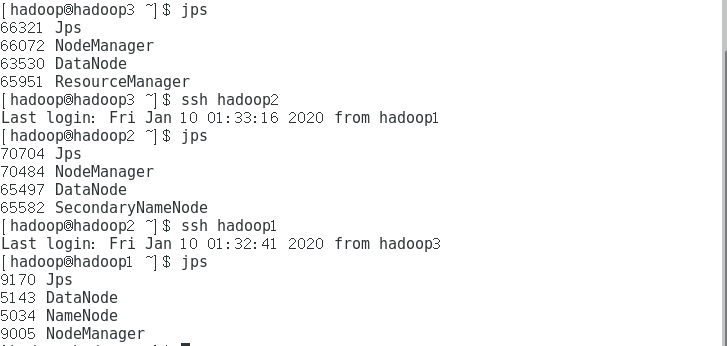
jps

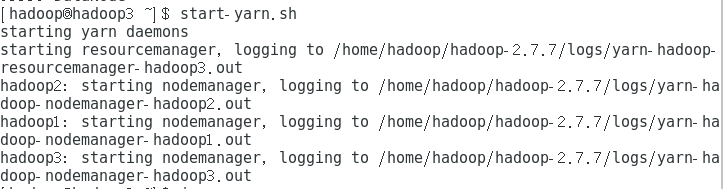
7.2启动yarn
在yarn的主节点执行,也就是第三个节点
start-yarn.sh
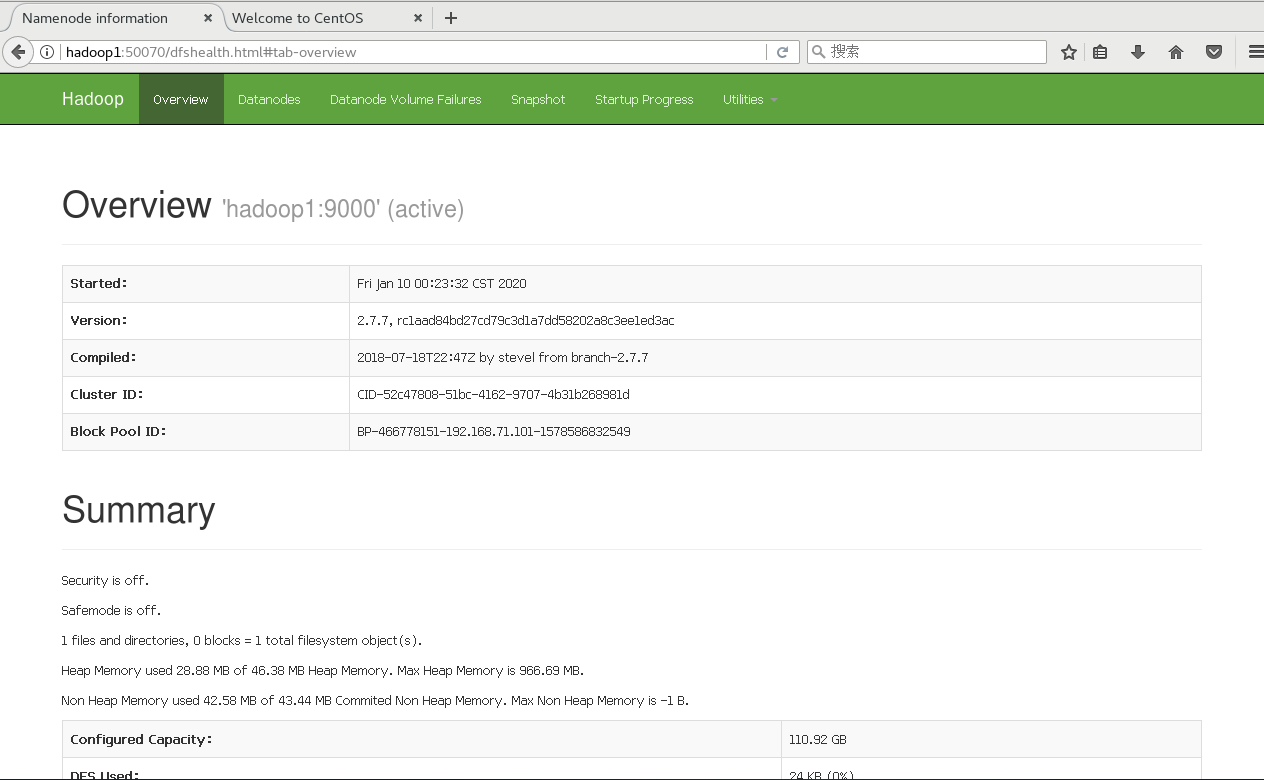
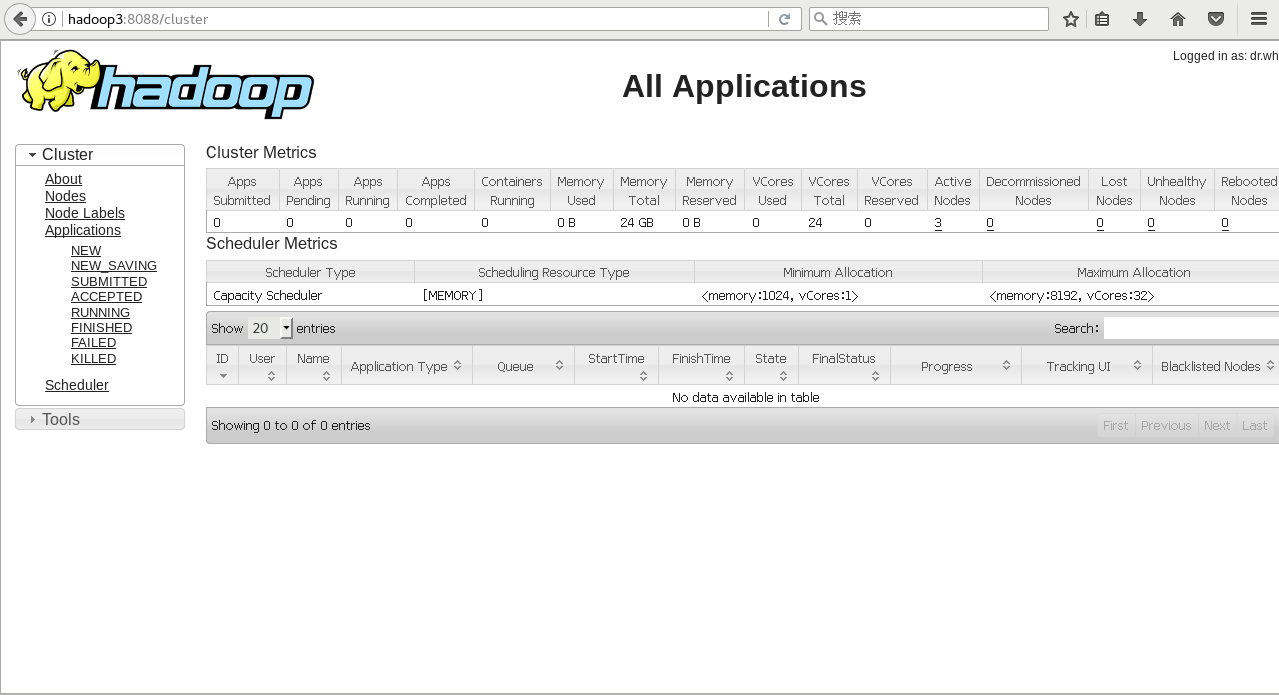
8.网页访问
打开浏览器
yarn:hadoop3:8088
9关闭
9.1关闭yarn
stop-yarn.sh
9.22关闭hdfs
stop-dfs.sh
