

字典有称为符号表(symbol table)、关联数组(associative array)或者映射表(map table)、哈希表(hash table),是一种用于保存键值对的抽象数据结构。
本篇主要对哈希表的实现及内部结构总结介绍、以及哈希算法的选择、Redis采用哪种方式解决键冲突、以及rehash的实现等。
1、字典的实现
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
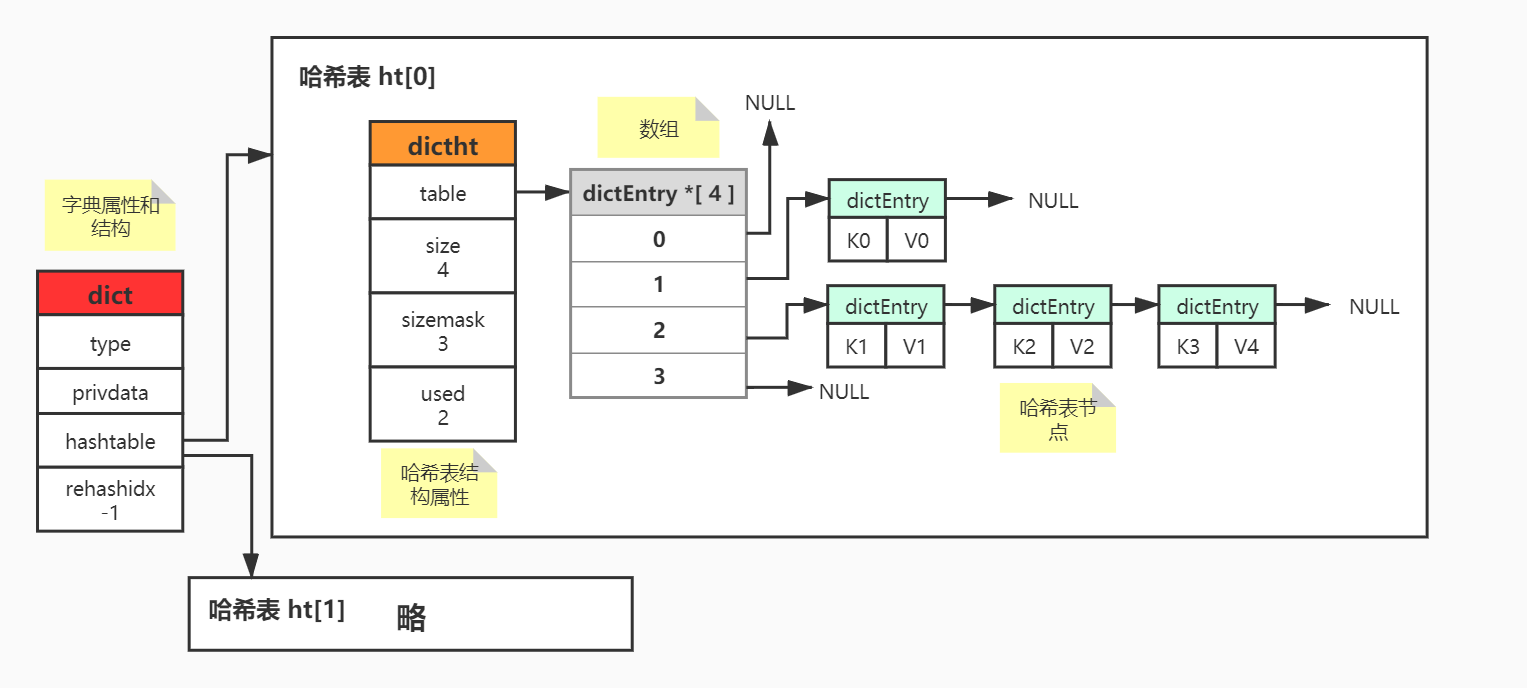
接下来我们就上图,来针对几个名称来进行归纳介绍:
a.哈希表
其结构如下:
typedef struct dictht{
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码、用于计算索引值,总是 = size-1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used
}
属性:
- table属性:是一个数组dictEntry *[4],每一个dictEntry值存放key_value节点,当发生哈希冲突是,则存放由哈希节点组成的单链表结构。
- size属性:记录着哈希表的大小,可以通过该属性O(1)获取哈希表的大小。
- sizemask属性:总是=size-1,该属性和哈希值(由哈希算法计算key而得,与sizemask取模)决定一个键应该被放入到 table数组的哪个索引上面。
- used属性:记录已有节点(键值对节点)的数量。
b.哈希表节点
每一个哈希表节点保存着一个键值对,其结构如下:
typedef struct dictEntry{
// 键
void *key;
// 值
union{
void *val;
uint64_t u64;
int 64_t s64;
};
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
主要next属性:指向另外一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起 (可以知道当通过哈希算法计算key得到的哈希值相同或者通过不同的哈希值对sizemask取模得到的值相同则被放入到相同的dictEntry索引位置中 -- 哈希冲突),以此解决哈希冲突。
c.字典
其结构如下:
typedef struct dict{
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash索引 -- 当rehash不在进行是,值为-1
int trehashidx;
} dict;
属性:type属性和privdata属性是针对不同类型的键值对,为创建多态字典而设置的。
- type属性:指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定键值对的函数,Redis根据用途不同的字典设置不同的类型特定函数(计算哈希值的函数、复杂键、对比键、销毁键等函数)。
- privdata属性:保存了需要传给上述那些特定函数的可选参数。
- ht属性:是一个包含两个项的数组,这两个项都是一个dictht的哈希表,一般情况下,字典只是有ht[0]哈希表,ht[1]哈希表只会对ht[0]哈希表进行rehash时使用。
- trehashidx属性:它记录了rehash目前的记录。
备注:这也是为什么Redis不直接使用哈希表结构的原因,通过再构建字典数据结构,type和privdata属性可以更加方便创建多态的字典,同时针对用户不同的字典调用不同的函数进行操作。并且通过构建存储两个哈希表的数组及trehashidx更加便捷的进行rehash操作。
2、哈希算法
稍微了解哈希表数据结构的小伙伴们都知道,要将一个新的键值对添加到字典的ht属性中,程序需要先根据键值对的key计算出哈希值和索引值,根据索引值,将包含新键值对的哈希表节点放入哈希表数组的指定索引上面。
通过哈希算法计算方法如下:
- hashValue = dict.type.hashFunction(key) --> 得出哈希值
- index = hash % dict.ht[x].sizemask -- >通过hashvalue对哈希表(0 or 1)进行取模,得出索引值
备注:字典被用作数据库底层实现、或者哈希键的底层实现时,Redis使用MurmurHash2算法来计算键的哈希值。
3、解决键的冲突
当有两个或者以上数量的键被分配到了哈希表数组的同一个索引上面时 -- 哈希冲突。
Redis使用 链地址法 (separate chainning)来解决冲突,即每个哈希表节点都有一个next指针,存入哈希表数组的同一个索引上的多个节点可以使用这个单向链表连接起来。同时,为了速度考虑,总数将新节点添加到链表的表头位置。
4、rehash
问题:随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。
rehash的步骤如下:
1)、为字典的ht[1]哈希表分配空间 (空间大小取决于 --要执行的操作 + ht[0].used值)
- 扩展:ht[1] = 第一个>= ht[0].used * 2 * 2^n
- 收缩:ht[1] = 第一个>= ht[0].used * 2^n
2)、将保存在ht[0]中的所有key-value rehash(重新计算键的哈希值和索引值,放到指定位置上)到ht[1]上面。
3)、迁移到ht[1],ht[0]变为空表,释放ht[0],将ht[1]设置为ht[0],并在ht[1]上新建一个空白哈希表,为下次rehash做准备。
那什么时候进行rehash呢?
- 服务器目前没有执行BGSAVE或者BGREWRITEAOF命,并且负载因子 >= 1。
- 若正在执行上述命令,并且负载因子 >= 5
- 当哈希表的负载因子 < 0.1时,进行收缩操作。
其中负载因子通过如下公式计算:
上述两种不同的方式也是为了尽可能避免在子程序存在期间进行哈希表扩展操作,避免不必要的内存写入操作,最大限度地节约内存。
5、渐进式rehash
上述的扩展或者收缩哈希表需要将ht[0]里面的所有键值对rehash到ht[1]里面,但是这个动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
原因:若哈希表中存储的键值对数量十分庞大,例如:十万个、百万个等,要一次性将这些键值对全部rehash到ht[1]的话,庞大的计算量可能会导致服务器在一段时间内停止服务(与一次性过期处理同样的道理)。
详细步骤:
- 为ht[1]分配空间。
- 字典中维持一个索引计数器变量 rehashidx,并设置为0,表示rehash正式开始。
- 在rehash期间,对字典进行增删改查操作时,除了指定操作外,还顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成后, rehashidx +1。
- 随着字典操作的不断执行,最终 ht[0]中所有键值对都会rehash到ht[1],最后将 rehashidx设置为-1。
渐进式rehash的好处:采用分而治之的方式,将rehash键值对所需计算工作均摊到堆字典的每次执行操作上,从而避免集中式rehash带来的庞大计算量。
备注:在渐进式rehash的过程中,字典会同事使用ht[0]和ht[1]两个哈希表,增删改查等操作会在两个哈希上进行,例如:在ht[0]没找到,会在ht[1]再次查找。另外,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不会进行任何添加操作,这措施保证了ht[0]包含的键值对数量会只减不增,最终变成空表。
over~~~~~~~~~~~
