

事务 Transaction
事务 是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列组成
————百度百科
ACID 事务特性
-
Atomicity原子性事务里面的所有操作要么全部成功,要么全部失败
-
Consistency一致性数据从状态A,通过事务操作,转为状态B,要求数据在状态A满足的约束对于状态B的数据一样试用
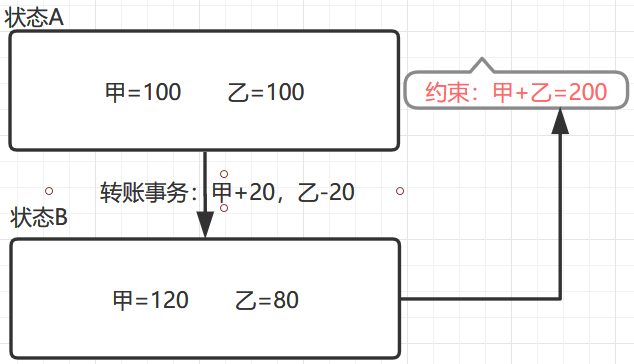
-
Durability持久性已经提交的事务对数据的修改,应该是永久保存在数据库中的,在数据库层面已经提交的事务不可回滚
-
Isolation隔离性多个事务并发执行的时候,根据某些规则,确保互不影响
隔离级别&常见问题
针对MySQL数据库而言,存在可设置的四种隔离级别(由高到低):
- 串行化
serializable:一个事务一个事务的执行 - 可重复度
repeatable-read:(MySQL默认)无论其他事务是否修改并提交了数据,在这个事务中的数据不受其他事务的影响 - 读已提交
read-commited:其他事务提交的数据,对于当前事务是可读的(其他很多数据的默认隔离级别) - 读未提交
read-uncommited:其他事务未提交的数据,对当前事务是刻度的
串行化
serializable理论(注意理论上,可能受其他未知因数影响)上可以保证数据的就绝对一致隔离级别越高,数据库并发性能越差,数据一致性越好;隔离级越低,并发性能越好,一致性越差
本质上这是一个并发场景的共享数据问题:竞态问题(操作者数量>操作物数量)
MySQL数据库其他三个隔离可能导致的常见问题:
脏读
通俗的讲,一个事务在处理过程中读取了另外一个事务未提交的数据
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | transaction begin | |
| 2 | transaction begin | |
| 3 | select balance from account where id = 1(结果为0) |
|
| 4 | update account set balance = 2 where id = 1 |
|
| 5 | select balance from account where id = 1(结果为2) |
事务A的【5】操作读取了事务B未提交的数据,导致这个数据是不一定正确的,称为
脏读隔离级别:
read-uncommited会导致这个问题
不可重复度
通俗的讲,一个事务范围内,多次查询某个数据,却得到不同的结果
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | transaction begin | |
| 2 | transaction begin | |
| 3 | select balance from account where id = 1(结果为0) |
|
| 4 | update account set balance = 2 where id = 1 |
|
| 5 | select balance from account where id = 1(结果为0) |
|
| 6 | transaction commit | |
| 7 | select balance from account where id = 1(结果为2) |
事务A的【3】、【5】、【7】三个步骤读取的结果不一样,这种称为
不可重复读隔离级别:
read-commited会导致这个问题
幻读
事务A查询的记录条数,由于事务B的增删导致,事务A某两次读取匹配的记录数不一样
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | transaction begin | |
| 2 | transaction begin | |
| 3 | select count(*) from account where salary > 5000(结果为10) |
|
| 4 | insert into account values(5000) |
|
| 6 | transaction commit | |
| 7 | select count(*) from account where salary > 5000(结果为11) |
事务A的【3】、【7】同样的sql匹配到不同数量的记录,称为
幻读隔离级别:
repeatable-read会导致这个问题
不可重复读&幻读区别
不可重复读的重点是修改: 同样的条件,你读取过的数据,再次读取出来发现值不一样了 幻读的重点在于新增或者删除: 同样的条件,第 1 次和第 2 次读出来的记录数不一样
第一类丢失更新
事务A回滚,导致事务B的提交修改失效
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | transaction begin | |
| 2 | transaction begin | |
| 3 | 查询余额1000 | |
| 4 | 查询余额1000 | |
| 5 | 汇入100,余额修改为1100 | |
| 6 | transaction commit | |
| 7 | rollback |
事务A的回滚导致,余额恢复为1000,事务B提交的数据更新失效
第二类丢失更新
事务A的提交,导致事务B的提交失效
| 操作顺序 | 事务A | 事务B |
|---|---|---|
| 1 | transaction begin | |
| 2 | transaction begin | |
| 3 | 查询余额1000 | |
| 4 | 查询余额1000 | |
| 5 | 汇入100,余额修改为1100 | |
| 6 | transaction commit | |
| 7 | 去除100,余额修改i为900 | |
| 8 | transaction commit |
事务A的提交,将余额修改为900,导致事务B的提交数据更新失效
数据库并发问题的不完全解决
为了解决上述问题,数据库通过锁机制解决并发访问的问题。根据锁定对象不同:分为行级锁和表级锁;根据并发事务锁定的关系上看:分为共享锁定和独占锁定,共享锁定会防止独占锁定但允许其他的共享锁定。而独占锁定既防止共享锁定也防止其他独占锁定。为了更改数据,数据库必须在进行更改的行上施加行独占锁定,insert、update、delete和select for update语句都会隐式采用必要的行锁定。
但是直接使用锁机制管理是很复杂的,基于锁机制,数据库给用户提供了不同的事务隔离级别,只要设置了事务隔离级别,数据库就会分析事务中的sql语句然后自动选择合适的锁。 不同的隔离级别对并发问题的解决情况如图:
| 隔离级别 | 脏读 | 不可重复度 | 幻读 | 第一类丢失 | 第二类丢失 |
|---|---|---|---|---|---|
read_uncommited |
√ | √ | √ | √ | |
read_commited |
√ | √ | √ | ||
repeatable_read |
√ | ||||
serializable |
√表示当前隔离级别,这种问题可能发生
金三银四
参看文章:
