

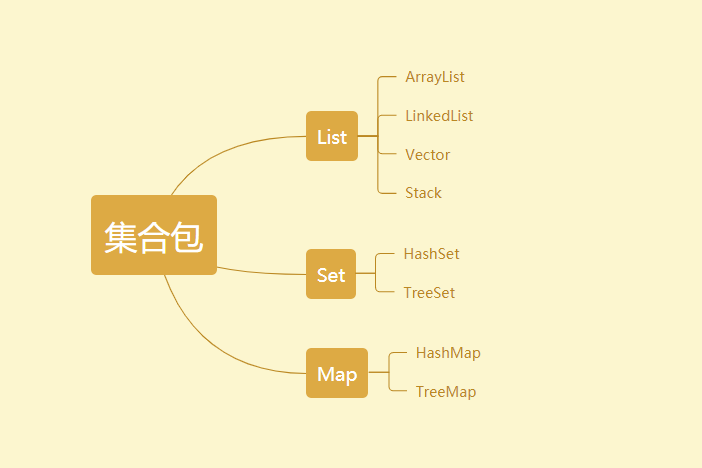
体系结构(将一般较多使用的划分出来)
1.为什么要需要Collection?
java是一种面向对象的语言,为了方便处理多个对象,把多个对象储存起来,需要一个容器-----集合。
2.数组和集合的区别?
- 长度: 数组的长度固定,集合的长度可变。
- 内容: 数组储存的同一类型的元素,集合可以储存不同的元素,但是我们通常不那样做。
- 元素的数据类型: 数组可以储存基本数据类型和引用类型,集合只能储存引用类型。
3.集合类简介
Java集合大致可以分为Set、List、Queue和Map四种体系,其中Set代表无序、不可重复的集合;List代表有序、重复的集合;而Map则代表具有映射关系的集合,Java 5 又增加了Queue体系集合,代表一种队列集合实现。 Java集合就像一种容器,可以把多个对象(实际上是对象的引用,但习惯上都称对象)“丢进”该容器中。从Java 5 增加了泛型以后,Java集合可以记住容器中对象的数据类型,使得编码更加简洁、健壮。
4.Collection接口
4.1简介:
collection接口是set,Queue,List的父接口
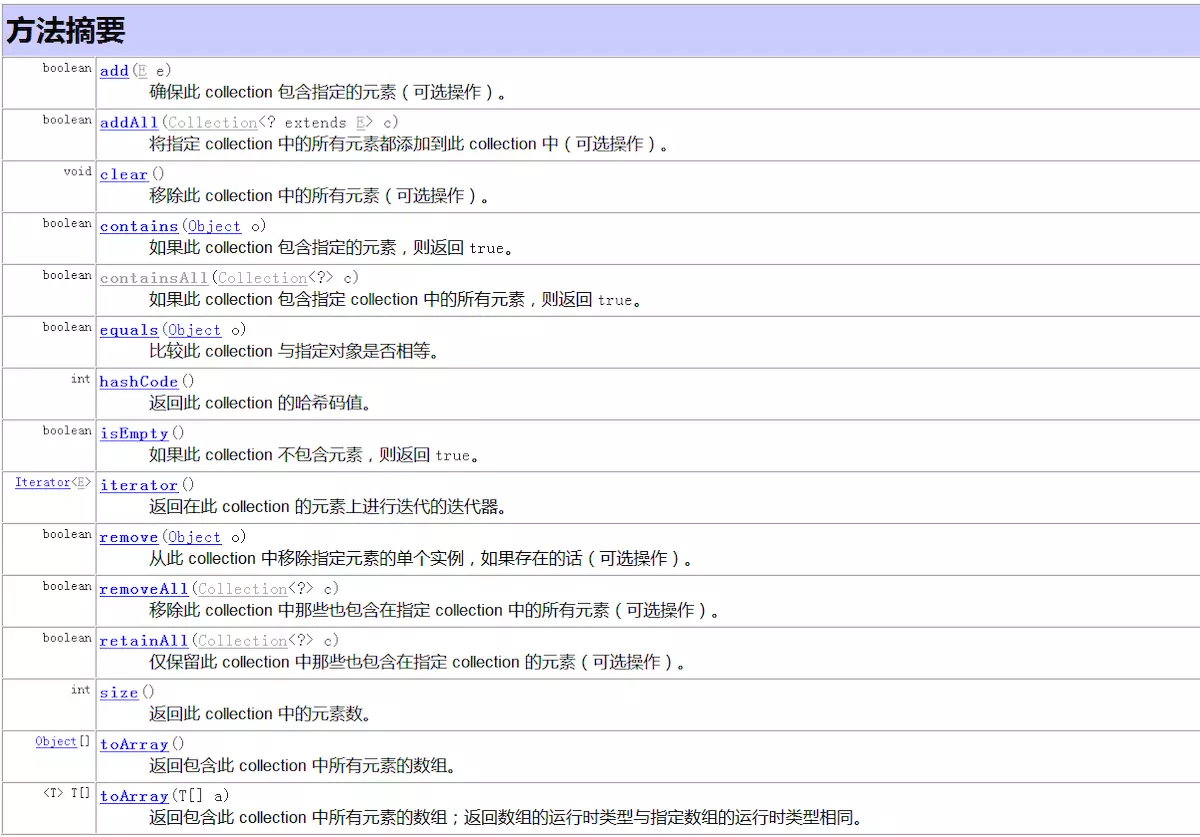
4.2使用Iterator遍历集合元素
Iterator接口是Collection的父接口,主要用于遍历Collection中的元素,其中定义了两个方法

public class IteratorExample {
public static void main(String[] args){
//创建集合,添加元素
Collection<Day> days = new ArrayList<Day>();
for(int i =0;i<10;i++){
Day day = new Day(i,i*60,i*3600);
days.add(day);
}
//获取days集合的迭代器
Iterator<Day> iterator = days.iterator();
while(iterator.hasNext()){//判断是否有下一个元素
Day next = iterator.next();//取出该元素
//逐个遍历,取得元素后进行后续操作
.....
}
}
}
注意: 使用Iterator对集合元素进行遍历时,Iterator并不是把集合元素本身传递给迭代变量,而是把集合元素的值传递给了迭代变量。
4.3ArrayList和Vector
ArrayList和Vector都是动态扩展的数组,如果开始的时候知道集合容纳元素的数量,可以指定initialCapacity的大小,这样可以提到性能。
**区别:**ArrayList线程不安全,Vector线程是安全的。Vector性能比ArrayList差。
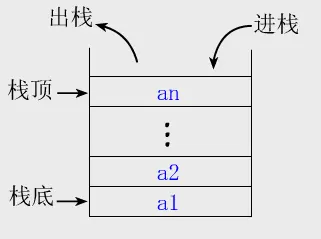
Stack 是Vector的子类,先进后出,线程是安全的,但是性能较差,
- 使用迭代器遍历
Integer value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
- 随机访问通过索引值去访问
Integer value = null;
int size = list.size();
for (int i=0; i<size; i++) {
value = (Integer)list.get(i);
}
- for循环访问
Integer value = null;
for (Integer integ:list) {
value = integ;
}
4.4LinkedList
LinkedList是List是实现类,说明其可以通过索引来随机访问集合中的元素,除此之外,LinkedList还实现了Deque接口,还可以被当做双端队列来使用。 LinkedList与ArrayList完全不同,ArrayList以数组的形式来保存集合中的元素;而LinkedList内部以链表的形式保存集合的元素,因此随机访问的性能较差,但是插入和删除元素时的性能较出色。
##4.41LinkedList方法
void addFirst(E e):将指定元素插入此列表的开头。
void addLast(E e): 将指定元素添加到此列表的结尾。
E getFirst(E e): 返回此列表的第一个元素。
E getLast(E e): 返回此列表的最后一个元素。
boolean offerFirst(E e): 在此列表的开头插入指定的元素。
boolean offerLast(E e): 在此列表末尾插入指定的元素。
E peekFirst(E e): 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
E peekLast(E e): 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
E pollFirst(E e): 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
E pollLast(E e): 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
E removeFirst(E e): 移除并返回此列表的第一个元素。
boolean removeFirstOccurrence(Objcet o): 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。
E removeLast(E e): 移除并返回此列表的最后一个元素。
boolean removeLastOccurrence(Objcet o): 从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。
4.42遍历方法
1.通过迭代器遍历LinkedList 2通过快速随机访问遍历LinkedList 3.通过for循环遍历LinkedList 4.通过pollFirst()遍历LinkedList 5.通过pollLast()遍历LinkedList 6通过removeFirst()遍历LinkedList 7.通过removeLast()遍历LinkedList 实现都比较简单,就不贴代码了。
5.set集合
set集合和Collection集合基本相同,没有提供额外的方法,set不允许包含相同的元素,试图把两个相同的元素放到一个集合中,add()方法会返回false。
5.1HashSet
##5.11 HashSet的特点
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化
- HashSet不是同步的,如果多线程访问需要保证其同步
- 集合元素可以是null
- 判断两个元素是否相等,判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值也相等。
equals()和hashCode()
equals() 比较两个对象是不是同一个对象
hashCode() 作用是获取哈希码,实践上是返回一个int整数,这个哈希码的作用是确定该对象在哈希表中的位置。Object类的默认的hashCode(),可以用来比较两个对象是否是同一个对象。 HashSet中元素的比较
- equals()返回false,hashCode()返回值不相等,HashSet会把他们保存在不同的位置。
- equals()返回true,hashCode()返回值不相等,,HashSet会把他们保存在不同的位置。
- equals()返回false,hashCode()返回值不相等,,HashSet会把他们保存在相同的位置。会在这个位置以链表结构保存多个对象,这是因为当向HashSet集合中存入一个元素时,HashSet会调用对象的hashCode()方法来得到对象的hashCode值,然后根据该hashCode值来决定该对象存储在HashSet中存储位置。
- 如果有两个元素通过equal()方法比较返回true,但它们的hashCode()方法返回true,HashSet将不予添加
5.2TreeSet
保证集合元素处于排序状态
5.21TreeSet的方法
comparator():返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回null。
first():返回此 set 中当前第一个(最低)元素。
last(): 返回此 set 中当前最后一个(最高)元素。
lower(E e):返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。
higher(E e):返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。
subSet(E fromElement, E toElement):返回此 set 的部分视图,其元素从 fromElement(包括)到 toElement(不包括)。
headSet(E toElement):返回此 set 的部分视图,其元素小于toElement。
tailSet(E fromElement):返回此 set 的部分视图,其元素大于等于 fromElement。
5.22TreeSet的排序方式
支持两种排序方式,自然排序(默认);定制排序
5.23TreeSet判断集合元素相等
唯一标准,两个对象通过compareTo(Object obj),通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等,不予添加入集合内;否则就认为它们不相等,添加到集合内。
6.List集合
List集合代表了一个元素有序可重复的集合,集合的每个元素都有其索引,List集合允许使用重复的元素。默认按添加元素的顺序设置元素的索引。相比Collection接口的全部方法,List中添加了一些根据索引操作集合的方法。
void add(int index, Object element): //在列表的指定位置插入指定元素(可选操作)。
boolean addAll(int index, Collection<? extends E> c) : 将集合c 中的所有元素都插入到列表中的指定位置index处。
Object get(index):返回列表中指定位置的元素。
int indexOf(Object o): 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
int lastIndexOf(Object o):返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
Object remove(int index); 移除列表中指定位置的元素。
Object set(int index, Object element):用指定元素替换列表中指定位置的元素。
List subList(int fromIndex, int toIndex): 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的所有集合元素组成的子集。
Object[] toArray(): 返回按适当顺序包含列表中的所有元素的数组(从第一个元素到最后一个元素)。
java8中还添加了两个默认方法
void replaceAll(UnaryOperator operator):根据operator指定的计算规则重新设置List集合的所有元素。
void sort(Comparator c):根据Comparator参数对List集合的元素排序。
7.Queue集合
Queue用户模拟队列这种数据结构,队列通常是指“先进先出”(FIFO,first-in-first-out)的容器。队列的头部是在队列中存放时间最长的元素,队列的尾部是保存在队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素。
8.Map集合
8.1简介
Map保存具有映射关系的数据,因此Map集合中保存着两组数,Key和Value都是可以支持任何数据类型的数据,Map中的key不允许重复,key和value存在一对一的对应关系。
8.2Map集合与Set和List的关系
- 和set集合的关系,把Map的所有Key放在一起,可以看成一个set集合
- 和List集合的关系,把Map的所有value放在一起看,可以看成一个List集合

8.3使用
public class MapTest {
public static void main(String[] args){
Day day1 = new Day(1, 2, 3);
Day day2 = new Day(2, 3, 4);
Map<String,Day> map = new HashMap<String,Day>();
//成对放入key-value对
map.put("第一个", day1);
map.put("第二个", day2);
//判断是否包含指定的key
System.out.println(map.containsKey("第一个"));
//判断是否包含指定的value
System.out.println(map.containsValue(day1));
//循环遍历
//1.获得Map中所有key组成的set集合
Set<String> keySet = map.keySet();
//2.使用foreach进行遍历
for (String key : keySet) {
//根据key获得指定的value
System.out.println(map.get(key));
}
//根据key来移除key-value对
map.remove("第一个");
System.out.println(map);
}
}
8.4 HashMap
HashMap是一个散列表,它存储的内容是键值对(Key-value)映射 **与Hashtable的比较:**HashMap比Hashtable的性能要好一些,但是线程不安全。 Hashtable不允许null作为key或value,但是HashMap可以使用null作为key或者value。
8.41判断相等的标准
key和hashset比较像,hashCode()返回结果一直,equals()返回true。 value equals()返回结果为true。
8.42HashMap的本质
HashMap的构造函数
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)
有两个重要的元素:容量(capacity)和加载因子(loadFactor),加载因子是在其容量自动增加之前可以达到多满的程度(通常默认为0.75)
Node类型 HashMap是通过“拉链法”实现的哈希表,它包括几个重要的成员变量:table,size,threshold,loadFactor size 是HashMap的大小,它是HashMap保存的键值对的数量。threshold是阈值,用于判断是否需要调整HashMap的容量,threshold的值=size*loadFactor,当存储的数据达到数量时,就将HashMap的容量加倍。
**数据存储方式:**综合了数组和链表的优点-----哈希表,有较快的查询速度和增删速度,通过hash(key)获得key的哈希值,如果hash值相等,则都存入该hash值对应的链表中,其内部是通过一个node数组来实现的,每一个数组元素代表一个链表,其共同点就是hash(key)相等
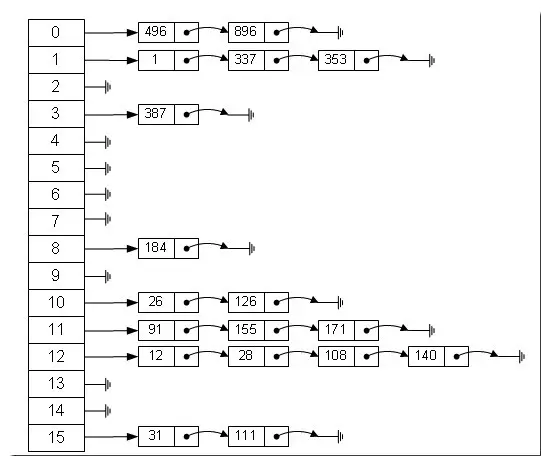
Node基本元素
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
// 指向下一个节点
Node<K,V> next;
//构造函数。
// 输入参数包括"哈希值(hash)", "键(key)", "值(value)", "下一节点(next)"
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Node是否相等
// 若两个Node的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
HashMap的遍历方式
-
1.遍历HashMap的键值对 第一步:根据entrySet()获取HashMap的“键值对”的Set集合。 第二步:通过Iterator迭代器遍历“第一步”得到的集合。
-
2.遍历HashMap的键 第一步:根据keySet()获取HashMap的“键”的Set集合。 第二步:通过Iterator迭代器遍历“第一步”得到的集合。
-
3.遍历HashMap的值 第一步:根据value()获取HashMap的“值”的集合。 第二步:通过Iterator迭代器遍历“第一步”得到的集合。
##8.5TreeMap
