

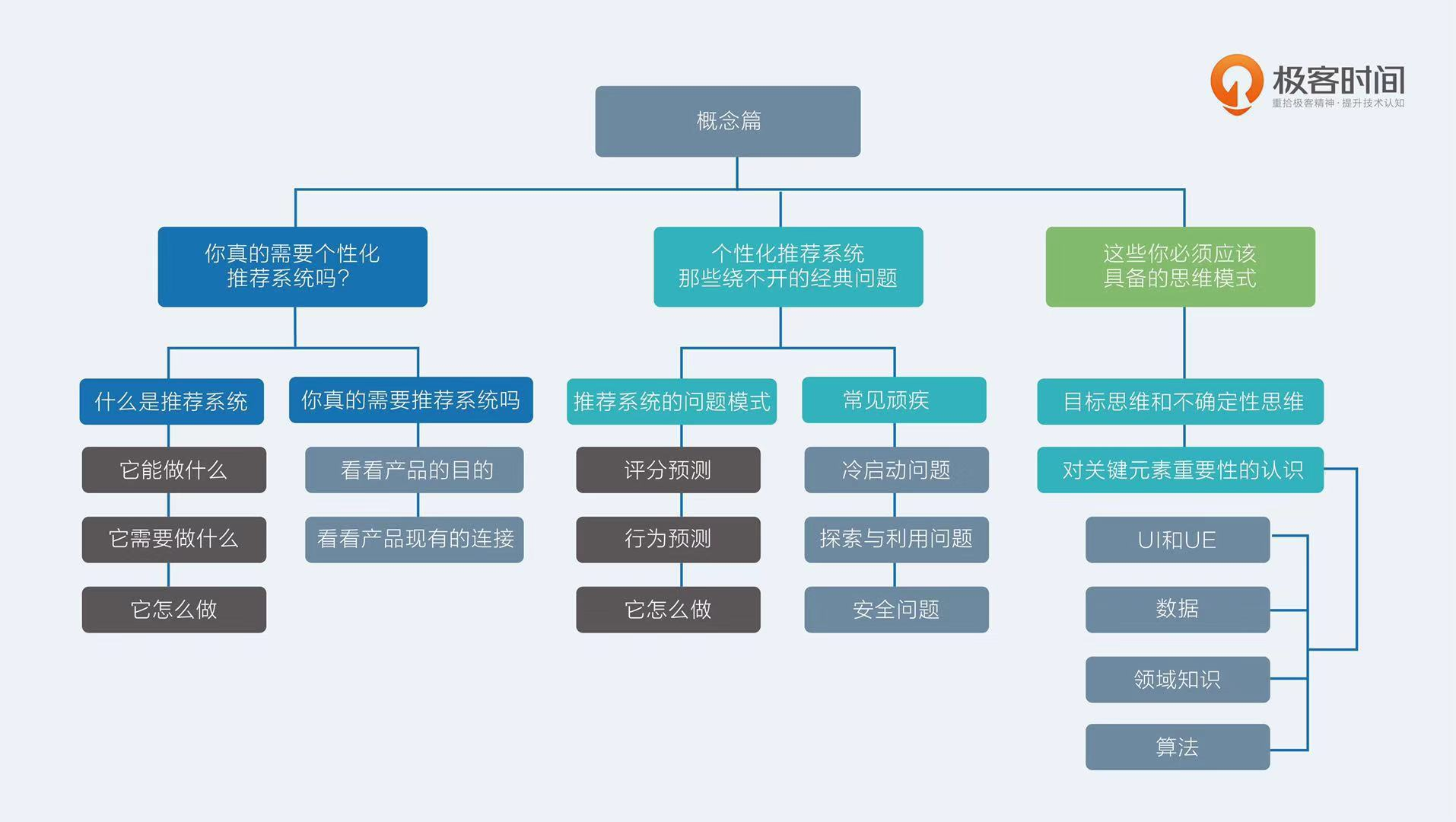
推荐系统的问题模式
- 评分预测
- 行为预测
推荐系统隐藏顽疾
- 冷启动问题
- 探索与利用问题(EE)
- 安全问题(不靠谱的推荐结果,脏数据问题)
推荐系统的4个关键元素(重要性由高至低)
- UI和UE
- 数据
- 领域知识
- 算法
构建推荐系统时的思维模式
- 目标思维(量化目标并增长目标)
- 不确定性思维(大多数推荐算法都是概率算法,不纠结一城一池的得失)
用户画像的用途(用户向量化的结果就是用户画像)
- 召回阶段
- 匹配评分
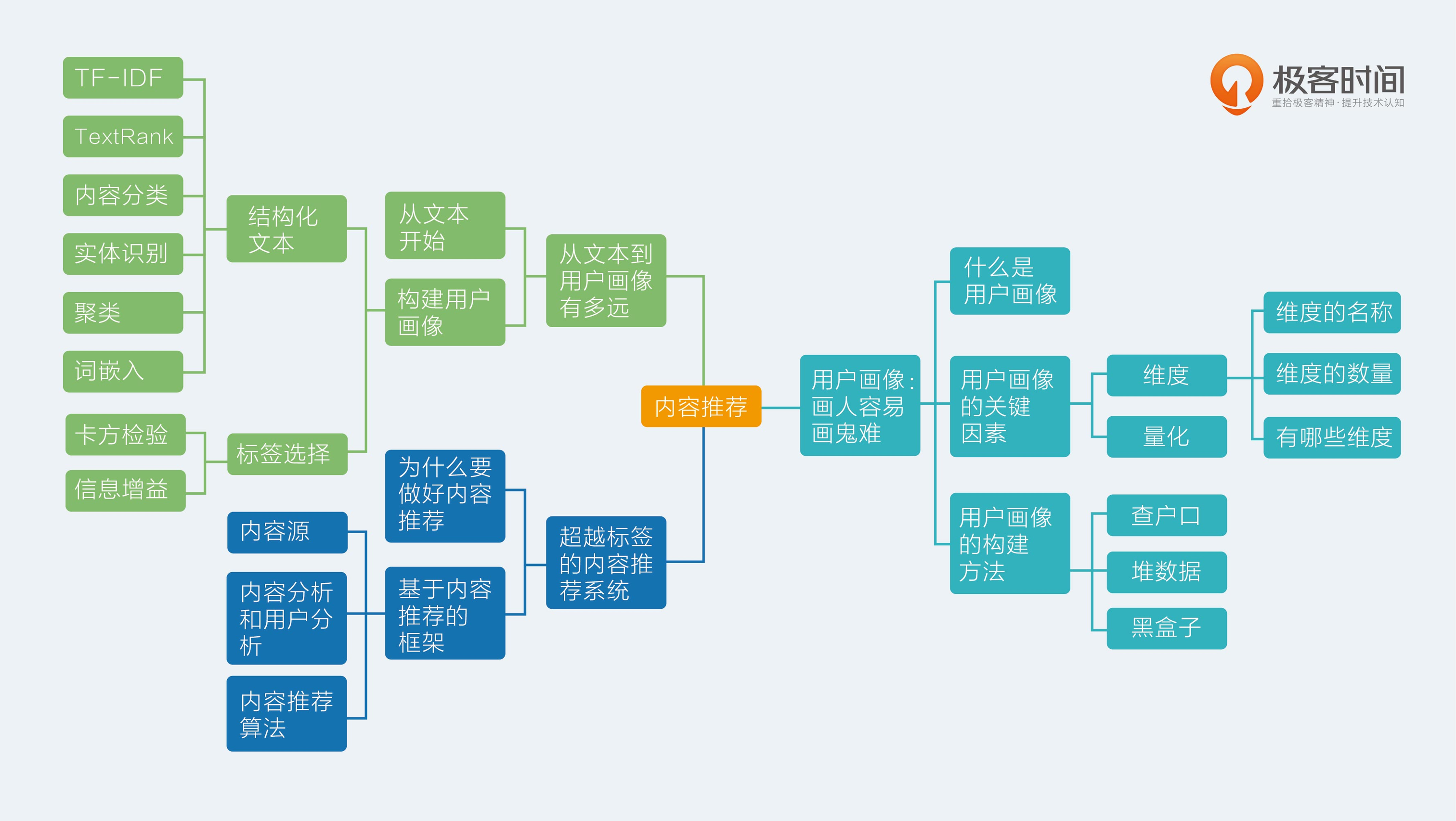
用户画像的关键因素
- 维度(维度和标签不同,不需要人理解)
- 量化:机器来量化并以目标为导向,以推荐效果反向优化用户画像,不要为了用户画像二用户画像,用户画像只是推荐系统的一个副产品
如何构建用户画像
- 文本结构化
- 结构化算法
- 关键词提取(TF-IDF,TextRank)
- 实体识别:对于序列标注问题,通常的算法就是隐马尔科夫模型(HMM)或者条件随机场(CRF),以实体识别为代表的序列标注问题上,工业级别的工具上 spaCy 比 NLTK 在效率上优秀一些
- 内容分类:短文本分类方面经典的算法是 SVM ,在工具上现在最常用的是 Facebook 开源的 FastText
- 主题模型:从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况,LDA 模型,开源的 LDA 训练工具有 Gensim,PLDA 等可供选择
- 嵌入:为每个词学习到一个稠密的向量,工具有Word2Vec
- 结构化算法
- 根据用户的行为,把物品的结构化结果传递给用户,与用户自己的结构化信息合并
文本结构化NLP算法
- 基本思想
- 把物品的结构化内容看成文档;
- 把用户对物品的行为看成是类别;
- 每个用户看见过的物品就是一个文本集合;
- 在这个文本集合上使用特征选择算法选出每个用户关心的东西。
- 标签选择算法
- 卡方检验(CHI)
- 信息增益(IG)
- 基本思想
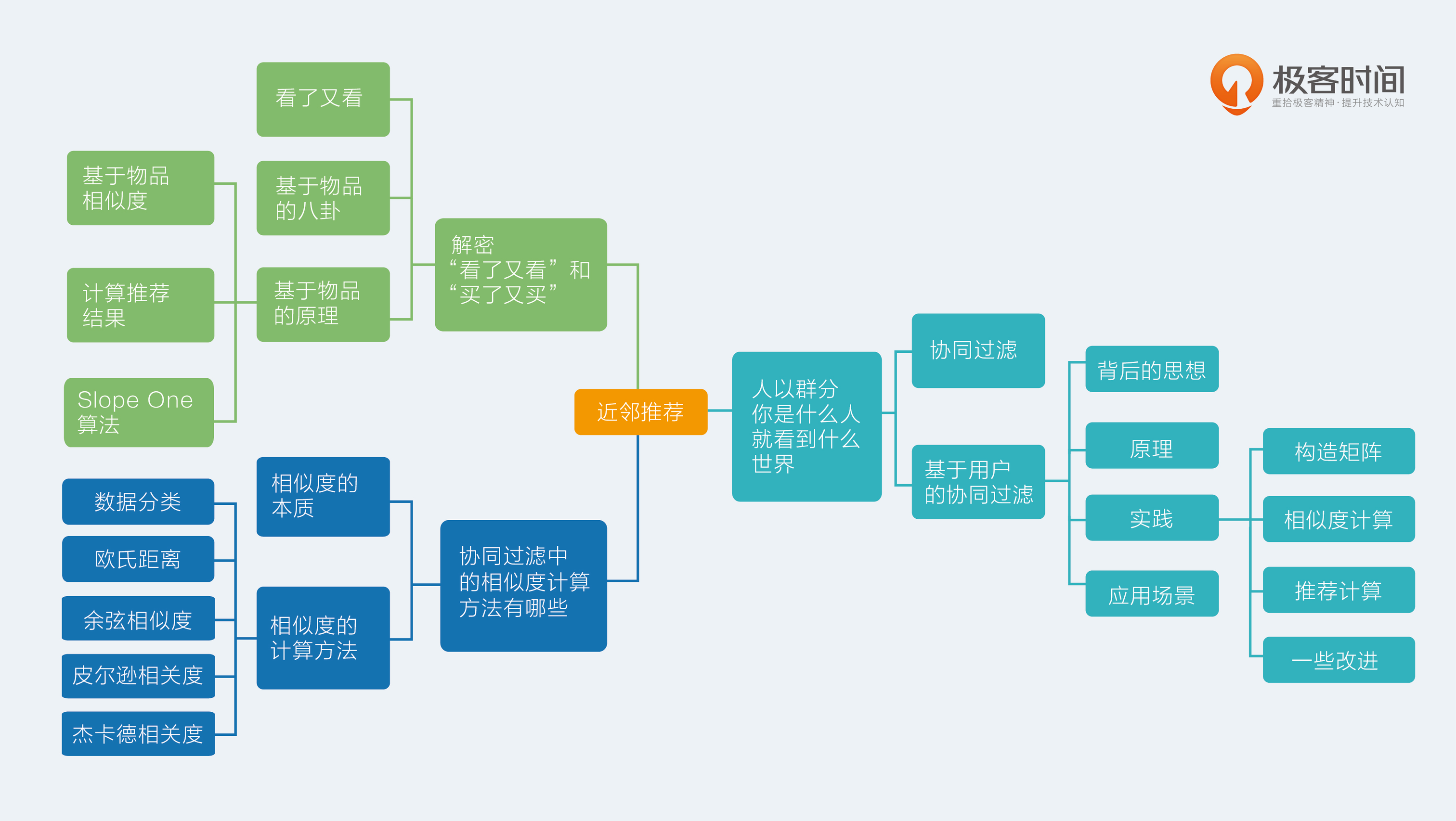
基于用户的协同过滤
-
步骤
-
准备用户向量,构造矩阵
- 稀疏矩阵存储格式:CSR,COO
- 把你的原始行为日志转换成上面的格式,就可以使用常用计算框架的标准输入了
-
每个用户之间两两计算相似度,为每个用户保留与其最相似的用户
- 向量很长怎么办
- 维度采样
- 向量化计算(将循环转换成向量化计算)
- 用户很多怎么办
- 使用批处理,入spark
- 不用基于用户的协同过滤
- 如果数据量不大,一般来说不超过百万个,然后矩阵又是稀疏的,那么有很多单机版本的工具其实更快,比如 KGraph、 GraphCHI 等
- 向量很长怎么办
-
将每个相似用户想换的物品列出来,去掉该用户喜欢过的物品,剩下的就是推荐的输出结果
- 物品数量很多,不可能为每个物品计算分数,怎么办
- 只有相似用户喜欢过的物品才计算
- 使用批处理
- 一些改进
- 惩罚对热门物品的喜欢程度
- 对喜欢程度增加时间衰减
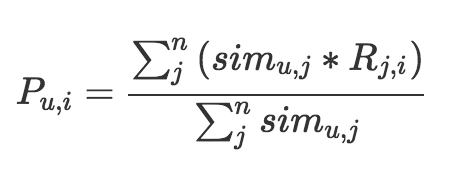
- 物品数量很多,不可能为每个物品计算分数,怎么办
-
-
应用场景
- 推荐相似的用户列表
- 基于用户的推荐
基于物品的协同过滤
-
相对于基于用户的协同过滤的好处
- 用户数量过大,计算成为瓶颈,物品数量有限,可计算
- 用户的口味会变化,物品之间的相似度比较静态,解耦了用户兴趣迁移的问题
- 数据稀疏,用户和用户之间共同的消费行为比较少,而且一般是热门的物品消费,对发现相同用户兴趣帮助不大
-
步骤
-
构建用户物品关系矩阵,矩阵元素可以为:消费行为,评分,也可以是对消费行为的某种量化,如时间,次数,费用等
-
行表示物品,列表示用户,两两计算行向量之间的相似度,得到物品相似度矩阵
- 用户消费过的才表示出来,所以是一个稀疏矩阵
- 计算相似度一般使用余弦相似度
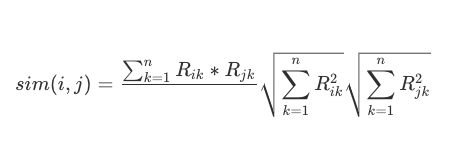
- 改进的地方
- 物品中心化:对脑残粉的刷分行为有一定抑制作用
- 用户中心化:严谨的用户可能评分都会偏低,中心化后只保留偏好部分
-
生成推荐结果,按照场景,有两种产生结果的形式,一种是“猜你喜欢”,得到预期用户评分最高的那些物品,一种是“看了又看,买了又买”,得到与刚购入物品相似度最高的那些物品
-
猜你喜欢,一般放在首页,计算方法是相似度加权汇总。根据各个物品和待计算分数物品的相似度,加权计算得到该物品的评分
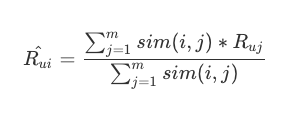
-
看了又看,买了又买的推荐,只需要推荐相似度最高的那些物品
-
Slope One算法:经典的基于物品推荐,无法实时更新,过程是离线计算的,而且没有考虑相似度的置信问题,即单个用户对单个物品的评分可能会对最后结果影响非常大。Slope One算法加入了置信度,例如如下物品评分
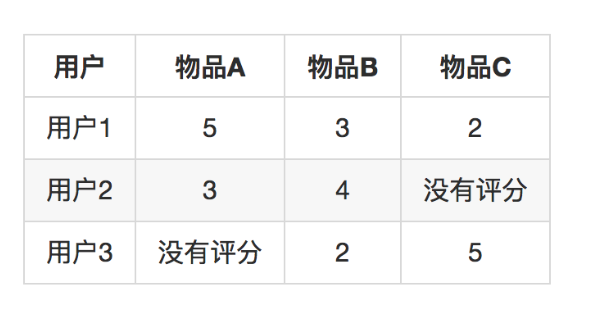
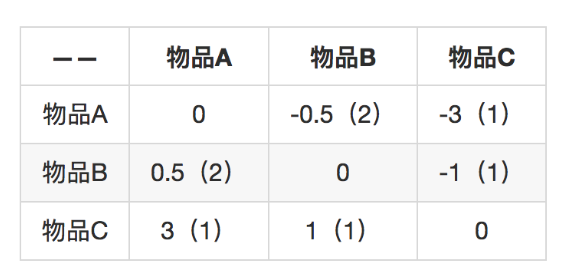
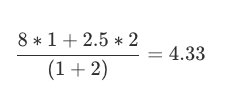
-
-
集中相似度的算法
-
数据分类,不同的数据类型适用于不同的相似度算法
- 实数值
- 布尔值
-
算法种类
-
欧氏距离
- 求两个向量的绝对距离,适用于分析用户能力模型之间的差异,如消费能力,贡献内容的能力
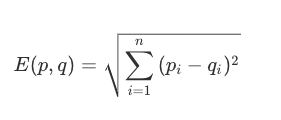
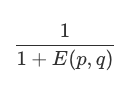
- 求两个向量的绝对距离,适用于分析用户能力模型之间的差异,如消费能力,贡献内容的能力
-
余弦相似度,适用于评分数据
-
使用两个向量之间的余弦夹角来度量两个向量间的相似度,特点是不管向量的长度,其思想是,只要方向一致,无论程度强弱,都认为是相似的。适用于某些场景,例如:我用140字摘要了一篇5000字的博文,两者的文本向量可以认为是方向一致的,只是词频不同,这种情况下余弦相似度认为他们是相似的。
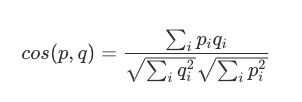
-
调整的余弦相似度,先计算各个维度上的均值,然后各维度减去各维度的均值,再做余弦相似度计算。适用于如下场景:用户A对两部电影的评分分别是1分和2分,用户B的评分是4分和5分,这样算出来的余弦相似度非常高,但是结论却是,A不喜欢那两部电影,而B喜欢。使用调整的余弦相似度计算之后,计算的记过是-1,相似度非常低
-
-
皮尔逊相关度
- 先计算向量的均值,然后各维度减去均值,再算余弦相似度。皮尔逊相关度其实度量的是两个随机变量是不是在同增同减。如果同时对两个随机变量采样,当其中一个得到较大的值另一也较大,其中一个较小时另一个也较小时,这就是正相关,计算出来的相关度就接近1,这种情况属于沆瀣一气,反之就接近 -1
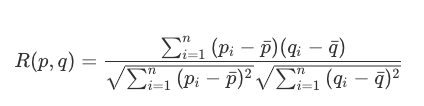
- 先计算向量的均值,然后各维度减去均值,再算余弦相似度。皮尔逊相关度其实度量的是两个随机变量是不是在同增同减。如果同时对两个随机变量采样,当其中一个得到较大的值另一也较大,其中一个较小时另一个也较小时,这就是正相关,计算出来的相关度就接近1,这种情况属于沆瀣一气,反之就接近 -1
-
杰卡德相似度,适用于隐式反馈的数据,例如用户收藏
- 分子是两个布尔向量的点积,得到交集元素个数
- 分母是两个布尔向量做或运算,再求元素和
-
