

总述
本文第一部分主要以一个超简化的编译器实现来理解编译的基本原理。 第二部分我们会对早期的5to6以及Babel、PostCSS的工作流程进行分析,来观察编译原理是如何运用在其上的。
本文3400余字 阅读大概需要15分钟,阅读收益:
- 理解基本的编译原理
- 理解Babel的工作流程,通过分析5to6和Babel v7 理解Babel本质
- PostCss 工作流程
- 结尾参考了很多文章,多点一点会有更多收获
先来看一个简化编译器实现的例子
lisp 是一门比较古老的语言,因为语法相对比较简单,很多国外的编译教程都是以lisp作为学习语言。这里我们也使用lisp作为一个例子。common lisp 了解
比如我要实现 100 + 100
lisp下 类JS
(add 100 100) add(100,100)
要把左边的lisp 编译成 类JS 一般需要经过以下几个步骤
- 解析,通过词法分析和语法分析 将代码生成为一个更抽象的形式 AST。
- 转换,传入解析过程得到的抽象形式, 通过访问器访问AST的节点,对节点进行操作,得到新的AST结构。(比如 ES6转ES5。先通过 esprima 解析器得到标准ES6 AST,在手动转成标准ES5 的AST)
- 生成代码,基于转换后的AST 生成代码。
解析
其实关于这三个步骤的实现相关,网上找到很多例子,毕竟是编译原理入门。
词法分析
代码首先是以文本形式被读取的,中间需要通过词法分析器对代码进行处理,生成一个一个的词素。
如
输入:
(add 100 100)
tokenizer 输出:
{"token":[{"type":"paren","value":"("},{"type":"name","value":"add"},{"type":"number","value":"100"},{"type":"number","value":"100"},{"type":"paren","value":")"}]}
伪代码实现
const tokenizer = (input) => {
let current = 0;
let tokens = [];
while (current < input.length) {
let char = input[current]
if (char === '(') {
tokens.push({ type: 'paren', value: '(' })
current++;
continue;
}
if (char === ')') {
tokens.push({ type: 'paren', value: ')' });
current++;
continue;
}
// 排除空格
let WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 解析数字
let NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'number', value });
continue;
}
...
// 如果if都不能捕获,则抛出异常
throw new TypeError(`char cannot be recognized , char is ${char} `);
}
return tokens
}
语法分析
语法分析阶段传入 上阶段生成的词素集合 将其按照语言对应的标准 生成对应的AST语法树。
如
输入词素:
{"token":[{"type":"paren","value":"("},{"type":"name","value":"add"},{"type":"number","value":"100"},{"type":"number","value":"100"},{"type":"paren","value":")"}]}
输出伪lisp 语法树:
{"type":"Program","body":[{"type":"CallExpression","name":"add","params":[{"type":"NumberLiteral","value":"100"},{"type":"NumberLiteral","value":"100"}]}]}
伪代码实现
const parser = (tokens) => {
let current = 0;
// walk函数 解析一个“()” 括号内的词素
let __walk = () => {
let token = tokens[current];
if (token.type === 'number') {
current++;
return { type: 'NumberLiteral', value: token.value };
}
if (token.type === 'string') {
current++;
return { type: 'StringLiteral', value: token.value };
}
// 遇到 CallExpression 类型
if (token.type === 'paren' && token.value === '(') {
// '('无意义 更新current 和 token
token = tokens[++current];
// 当前 CallExpression 的树结构, 内部的词素 都将放入params中
let node = {
type: 'CallExpression',
name: token.value,
params: []
};
token = tokens[++current]; //跳过函数名 因为lisp 执行到( 就表示函数,(对应的node 包含了 name 所以需要跳过函数名,
while (token.type !== 'paren' || (token.type === 'paren' && token.value !== ')')) {
let innerItem = __walk()
node
.params
.push(innerItem); //递归执行当前 CallExpression 内部的结构
token = tokens[current];
}
current++; //
return node
}
throw new TypeError(token.type); // 没有匹配的token.type 抛出异常
}
let AST = {
type: 'Program',
body: []
}
while (current < tokens.length) {
AST
.body
.push(__walk());
}
return AST
}
转换
我们要得到新的类JS语法树,需要对生成的伪Lisp语法树进行转换。 这里我们会访问旧语法树的节点,在每个节点上执行操作,生成新的语法树。 我们在访问器中传入enter方法生成新的节点。在enter方法中执行对应的操作。
traverser(ast, visitor)
伪代码
const visitor = {
NumberLiteral: {
enter (node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
})
}
},
StringLiteral: {
enter (node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value,
});
}
},
CallExpression: {
enter (node, parent) {
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
}
node._context = expression.arguments // 子项遍历, 内容挂载到 arguments 上
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression: expression,
}
}
parent._context.push(expression); // 将当前 CallExpression 所有子集遍历项 挂载在父级上下文
}
}
}
通过传入伪Lisp AST 对其节点进行操作 我们得到了新的JS AST
输入:
{"type":"Program","body":[{"type":"CallExpression","name":"add","params":[{"type":"NumberLiteral","value":"100"},{"type":"NumberLiteral","value":"100"}]}]}
输出:
{"type":"Program","body":[{"type":"ExpressionStatement","expression":{"type":"CallExpression","callee":{"type":"Identifier","name":"add"},"arguments":[{"type":"NumberLiteral","value":"100"},{"type":"NumberLiteral","value":"100"}]}}]}
生成代码
最后通过对新的AST 进行递归操作 生成代码
伪代码:
const codeGenerator = (node) => {
switch (node.type) {
case 'Program':
return node.body.map(codeGenerator).join('\n');
case 'ExpressionStatement':
return codeGenerator(node.expression) + ';';
case 'CallExpression':
return (
codeGenerator(node.callee) +
'(' +
node.arguments.map(codeGenerator).join(', ') +
')'
);
case 'Identifier':
return node.name;
case 'NumberLiteral':
return node.value;
case 'StringLiteral':
return '"' + node.value + '"';
default:
throw new TypeError(node.type);
}
}
完整例子可以参考the-super-tiny-compiler
通过这个例子我们能理解到最基本的解释器的工作原理。
前端应用场景分析
1、Babel
Babel 就是是现代前端的地基,无处不在。我们分析Babel通过两个点去切入
- 早期的babel --- 即6to5, 通过早期版本的分析,了解babel基本原理
- 现代Bale 分析现代Babel的主要工作流程
6to5
babel 的前身叫6to5,第一版。第一版提交是在14年,当时作者Sebastian McKenzie还是一个17岁的高中生。我们要学习babel,可以把代码回退到第一版first commit c97696c224d718d96848df9e1577f337b45464be,来了解其脉络。
在第一版中我们可以 transform 方法转换代码
var to5 = require("6to5");
to5.transform("code();");
进入transform 文件
var escodegen = require("escodegen");
var traverse = require("./traverse");
var assert = require("assert");
var util = require("./util"); //
var _ = require("lodash");
var transform = module.exports = function (code, opts) {
opts = opts || {};
// 生成tree
...
var tree = util.parse(code); // 调 esprima 生成标准 AST
...
//
_.each(transform.transformers, function (transformer, name) {
// transform 黑名单
var blacklist = opts.blacklist;
if (blacklist.length && _.contains(blacklist, name)) return;
// transform 白名单
var whitelist = opts.whitelist;
if (whitelist.length && !_.contains(whitelist, name)) return;
transform._runTransformer(transformer, tree, opts);
});
var result = escodegen.generate(tree, genOpts);
// 返回生成代码
if (genOpts.sourceMapWithCode) {
return result.code + "\n" + util.sourceMapToComment(result.map) + "\n";
} else {
return result + "\n";
}
};
...
// es6 新特性
transform.transformers = {
arrowFunctions: require("./transformers/arrow-functions"),
classes: require("./transformers/classes"),
spread: require("./transformers/spread"),
templateLiterals: require("./transformers/template-literals"),
propertyMethodAssignment: require("./transformers/property-method-assignment"),
defaultParameters: require("./transformers/default-parameters"),
destructuringAssignment: require("./transformers/destructuring-assignment"),
generators: require("./transformers/generators"),
blockBinding: require("./transformers/block-binding"),
modules: require("./transformers/modules"),
restParameters: require("./transformers/rest-parameters")
};
我们从 解析 -> 转换 ->生成代码这个逻辑来看 6to5
Step1 解析
其中util.parse 引用的是 esprima 编译器,通过esprima进行解析生成标准AST. 我们可以看到 babel 通过 esprima 对代码进行转换
Esprima 是一个高性能、符合ECMAScript 标准的编译器。
回顾上面编译lisp例子的步骤。
- 解析 (词法分析、语法分析)
- 转换
- 生成代码
通过 esprima 实际上我们完成的是第一步 (词法分析和语法分析),esprima内部包含了词法、预发分析的接口,我们可以直接调用。
var esprima = require('esprima');
var program = 'const answer = 42';
esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
esprima.parse(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
Step2 转换
6to5 针对ES6所有的新属性写好了对应的转换规则
transform.transformers = {
arrowFunctions: require("./transformers/arrow-functions"),
classes: require("./transformers/classes"),
spread: require("./transformers/spread"),
templateLiterals: require("./transformers/template-literals"),
...
例子 箭头函数 transformer方法:
exports.ArrowFunctionExpression = function (node) {
var body = node.body;
if (body.type !== "BlockStatement") {
body = {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: body
}]
};
}
node.expression = false;
node.body = body;
node.type = "FunctionExpression";
if (traverse.hasType(node, "ThisExpression")) {
return util.template("function-bind-this", {
FUNCTION: node
});
} else {
return node;
}
};
在得到了ES6 AST以后 对每一个ES6规则进行遍历。发现对应的节点就调用 transformer 方法对齐进行ES5转换,最后得到一个标准ES5 AST
traverse.replace = function (node, callback) {
traverse(node, function (node, parent, obj, key) {
var result = callback(node, parent);
if (result != null) obj[key] = result;
});
};
Step3 生产代码
调用的第三方库escodegen进行代码生成
现代babel
随着前端技术的发展。现在的babel相比最早的6to5做了彻底的重构,成为了现代前端技术的基石,并且有专门的团队在维护。
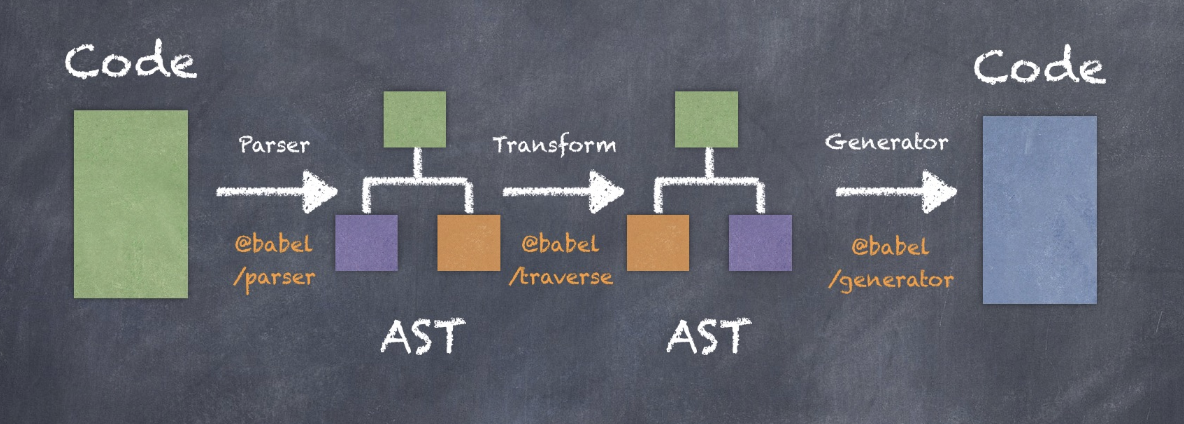
babel 采用了微内核的设计,核心部件都是以包的形式存在。通过上图我们可以看到babel在代码编译工作流上的几个流程。
babel 工作流程:
-
解析阶段 核心部件为 @babel/paeser 包
基于babylon www.babeljs.cn/docs/babel-… babylon 基于的是acorn 引擎。
-
转换阶段 核心部件为 @babel/traverse (babel插件也是在这个阶段进行处理的)
-
生成代码阶段 核心部件为 @babel/generator 作用:将通过各种规则转换后的AST生成代码
-
核心调度 @babel/core 负责整个流程的核心调度
packages 目录下的包 主要分为四类
- 核心流程包 @babel/paeser 、@babel/traverse 、 @babel/generator、@babel/core
- 9个preset包 babel-preset-env
- 辅助包
@babel/types 、@babel/template 、@babel/helpers、@babel/code-frames 在编译过程中用于对AST进行操作
@babel/polyfill Provides polyfills necessary for a full ES2015+ environment github.com/babel/babel…
- babel 插件
babel插件化
在6to5中转换规则是写到一个对象中的,对规则进行遍历匹配AST,如果发现有对应的ES6类型,调用对应的规则处理方法,将其AST节点修改为ES5对应的节点类型。
transform.transformers = {
arrowFunctions: require("./transformers/arrow-functions"),
classes: require("./transformers/classes"),
spread: require("./transformers/spread"),
templateLiterals: require("./transformers/template-literals"),
在Babel中 所有的规则都是以插件形式来引入的。在转换阶段,我们会通过visitor 对旧AST 的节点进行访问,并用对应插件中的方法对齐节点进行操作
流程: 解析生成AST-> Plugin 对AST进行操作得到新的AST ->生成代码
源码如下:
...
function parser(
pluginPasses: PluginPasses,
{ parserOpts, highlightCode = true, filename = "unknown" }: Object,
code: string,
) {
try {
const results = [];
for (const plugins of pluginPasses) {
for (const plugin of plugins) {
const { parserOverride } = plugin;
if (parserOverride) {
const ast = parserOverride(code, parserOpts, parse);
if (ast !== undefined) results.push(ast);
}
}
}
if (results.length === 0) {
return parse(code, parserOpts);
...
我们在6to5中举了箭头函数转换的例子,在Babel中我们同样举这个例子
import { declare } from "@babel/helper-plugin-utils";
import type NodePath from "@babel/traverse";
export default declare((api, options) => {
api.assertVersion(7);
const { spec } = options;
return {
name: "transform-arrow-functions",
visitor: {
ArrowFunctionExpression(
path: NodePath<BabelNodeArrowFunctionExpression>,
) {
// In some conversion cases, it may have already been converted to a function while this callback
// was queued up.
if (!path.isArrowFunctionExpression()) return;
path.arrowFunctionToExpression({
// While other utils may be fine inserting other arrows to make more transforms possible,
// the arrow transform itself absolutely cannot insert new arrow functions.
allowInsertArrow: false,
specCompliant: !!spec,
});
},
},
};
});
具体的插件开发及说明文档 可以直接查看文档,这里不做多言 babeljs.io/docs/en/plu…
2、postCSS
postCSS 介绍 查看
PostCSS 接收一个 CSS 文件并提供了一个 API 来分析、修改它的规则(通过把 CSS 规则转换成一个抽象语法树的方式)。在这之后,这个 API 便可被许多插件利用来做有用的事情,比如寻错或自动添加 CSS vendor 前缀。
首先我们 通过官方的直接在Node中使用PostCSS的例子来看postCss的使用方法
const autoprefixer = require('autoprefixer')
const postcss = require('postcss')
const precss = require('precss')
const fs = require('fs')
fs.readFile('src/app.css', (err, css) => {
postcss([precss, autoprefixer])
.process(css, { from: 'src/app.css', to: 'dest/app.css' })
.then(result => {
fs.writeFile('dest/app.css', result.css)
if ( result.map ) fs.writeFile('dest/app.css.map', result.map)
})
})
我们分析postCss的编译流程还是通过 解析 -> 转换 ->生产代码这个过程来分析
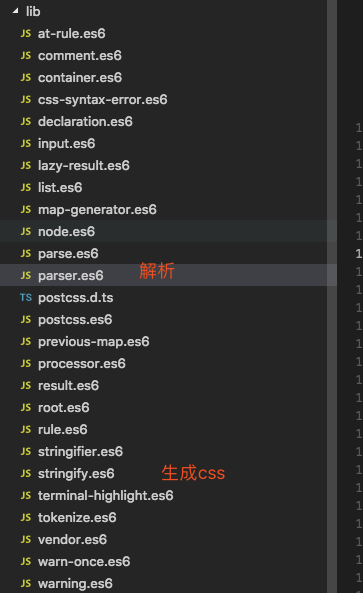
工作流程:
- Step1 解析 通过parser.es6 解析css 。parser 虽然是解析css文件,但是步骤和一般的解析流程是一样的,分为词法分析和语法分析 最后得到一颗CSS节点树,详细可看 parser.es6源码
通过 new Parser().parse() 进行调用
我们可以看到初始化阶段会先调用this.createTokenizer()进行词法分析,得到css token流。
parse 方法中会对token流 tokenizer 进行处理得到CSS Node Tree
export default class Parser {
constructor (input) {
this.input = input
this.root = new Root()
this.current = this.root
this.spaces = ''
this.semicolon = false
this.createTokenizer()
this.root.source = { input, start: { line: 1, column: 1 } }
}
createTokenizer () {
this.tokenizer = tokenizer(this.input)
}
parse () {
let token
while (!this.tokenizer.endOfFile()) {
token = this.tokenizer.nextToken()
switch (token[0]) {
...
}
this.endFile()
}
- Step2 转换 通过外部定制的插件 进行规则转换
通过源码来看插件机制 postCSS使用一定要注入插件,会返回一个囊括插件集合的处理器Processor。
process (css, opts = { }) {
if (this.plugins.length === 0 && opts.parser === opts.stringifier) {
if (process.env.NODE_ENV !== 'production') {
if (typeof console !== 'undefined' && console.warn) {
console.warn(
'You did not set any plugins, parser, or stringifier. ' +
'Right now, PostCSS does nothing. Pick plugins for your case ' +
'on https://www.postcss.parts/ and use them in postcss.config.js.'
)
}
}
}
return new LazyResult(this, css, opts)
}
Processor内部会聚合所有插件,当传入css文件时,会通过插件提供的方法进行处理。
then (onFulfilled, onRejected) {
...
return this.async().then(onFulfilled, onRejected)
}
// 为了清晰 我们用同步方法展示这是同步方法,可以看到通过插件遍历对css进行处理 (实际源码是异步 this.async)
sync () {
if (this.processed) return this.result
this.processed = true
...
for (let plugin of this.result.processor.plugins) {
let promise = this.run(plugin)
...
}
return this.result
}
- Step3 生成代码 通过stringify.es6 文件, 传入一颗css树,返回css代码
更多可以关注官方资料 官方资料
总结
首先我们通过一个超简化的编译器实现了解了编译器的基本工作步骤即:
解析(词法分析、语法分析) 得到AST -> 转换 (visitor 遍历器引入插件 得到新的AST) -> 生成代码
然后我们分析了6to5、Babel、PostCSS 等应用场景。阐述了以上步骤在这些应用场景中的运用。
本文主要参考的文章及仓库
alloyteam analysis-of-babel-babel-overview
It's Time for Everyone to Learn About PostCSS
以上。
