

1、什么是深浅拷贝
深浅拷贝在JavaScript中只是对于引用类型数据的一系列操作。
在定义一个对象或数组时,变量存放的往往只是一个地址。当我们使用对象拷贝时,如果属性是对象或数组时,这时候我们传递的也只是一个地址。因此子对象在访问该属性时,会根据地址回溯到父对象指向的堆内存中,即父子对象发生了关联,两者的属性值会指向同一内存空间。
2、深浅拷贝的区别
- 对象的深拷贝:复制对象存在堆内存中的实际值并且重新在栈内存中生成一份指向新堆内存中的地址值。
- 对象的浅拷贝:即只复制对象在栈内存中的保存的地址值,例如我们直接用赋值符号拷贝另一个对象的值。
- JavaScript中的引用类型的数据是被存放在堆内存中的,他们在栈内存中的变量只是保存了一个指向对堆内存中值的指针(类似与c中的指针),因此我们在访问引用类型的数据时只能先从栈中取出对象的指针地址,然后才会从堆内存中取得对象的数据。这也是JavaScript对象用赋值符号只能复制指针地址的原因。
3、堆栈图解
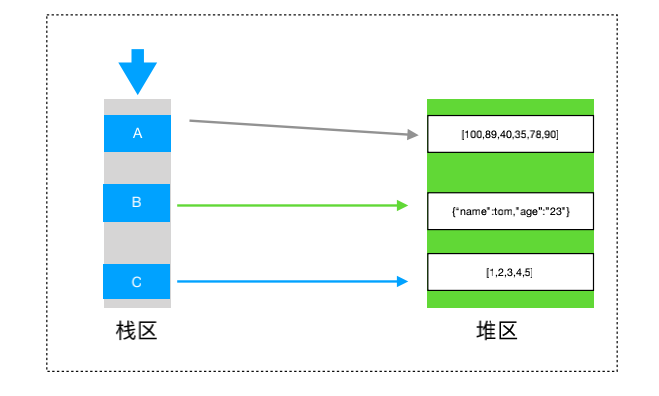
-
栈区:是由编译器自动分配释放,存放函数的参数值,局部变量的值等。遵从先进后出原则。
-
堆区:一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。
-
堆(数据结构):堆可以被看成是一棵树,如:堆排序; 栈(数据结构):一种先进后出的数据结构。相反的队列就是一种先进先出的数据结构.(关于数据结构、队列暂时不讲,说太多容易迷糊)
4、数据访问
1、基本数据类型:指保存在栈内存中的简单数据段。访问方式是按值访问。 undefined,null,布尔值(Boolean),字符串(String),数值(Number)
以一段代码为例:
var a = 1
var b = a
console.log(a) // 1
console.log(b) // 1
a = 3
console.log(a) // 3
console.log(b) // 1
用汉语解释一遍:
- (1)第一步:在栈区创建一个值a;(a被赋的值存在堆区,值为1)
- (2)第二步:把一个变量(b),向一个变量(a)复制时,会在栈中创建一个新值,然后把值(b)复制到为新变量分配的位置上。
5、没错长边的就是浅拷贝
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。即默认拷贝构造函数只是对对象进行浅拷贝复制(逐个成员依次拷贝),即只复制对象空间而不复制资源。
浅拷贝特点:
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个。
(2) 对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响。
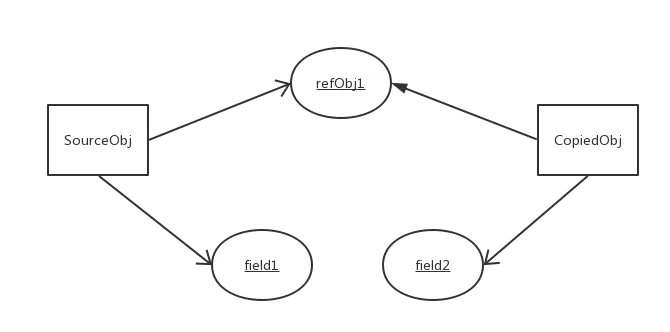
如果我们开发过程中,多个小伙伴处理同一条数据,很显然就乱套了!!!
6、深拷贝
在拷贝引用类型成员变量时,为引用类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝。
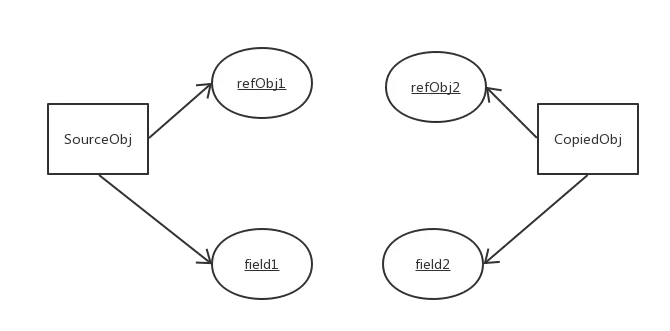
- 先JSON.stringfy() 再=> JSON.parse() ,即将一个对象先解析为json 字符串然后再解析。
let a={
val:'tom'
}
let b=JSON.parse(JSON.stringfy(a))
深拷贝特点: (1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)。
(2) 对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
(3) 对于有多层对象的,每个对象都需要实现 Cloneable 并重写 clone() 方法,进而实现了对象的串行层层拷贝。
(4) 深拷贝相比于浅拷贝速度较慢并且花销较大。
有一次我面试被问到深浅拷贝,我去,老子都没听过这个词!!!
在此告诫某些面试官不要太装X
本来一个很简单的问题,JSON.stringfy() 再=> JSON.parse() ,就搞定了,起一个高大上的名字,吓唬谁呢
另外,也不要拿节流防抖 糊弄人了 无非就是封装一个函数减少请求,减少服务器压力,都被你们吹上天了 负责的两个行内项目都是万级或十万级并发请求,不做压力测试,性能优化机房早崩了
