

写在前面
如在iOS的类结构中定义了很多数据成员变量,那么根据源码里面的类8字节对齐(操作系统64位)的原则;如果一个成员变量是一个int类型,那么它所占用的内存为4个字节(对齐需要补4个字节);另外一个成员变量是一个char类型,占用的内存为1个字节(对齐需要补7个字节);相对占用内存不足8字节的结构这种盲目的字节对齐就是一种内存资源的严重浪费;所以就引出了=>内存优化,例如几个成员变量共同存储在一个段的内存中,共占8个字节。
对齐原则
- 数据成员对齐原则:结构体(struct)或联合体(union)的数据成员,第一个数据成成放在
offset = 0的地方, 以后每个数据成员存储的起始位置都要从该成员大小或者成员的子成员大小的(只要该成员有子成员,比如说数组、结构体等)的整数倍开始(比如int为4字节,则要从4字节的整数倍地址位置开始存储)。 - 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(结构体
a里面存有结构体b,b里有char1个字节,int4个字节,double8个字节,最大为8个字节;那么b有应该从8个字节的整数倍开始存储)。 - 收尾工作:结构体的总大小,也就是
sizeof方法函数的结果,必须是其内部最大内存元素的整数倍,不足的需要补齐。
内存对齐优化
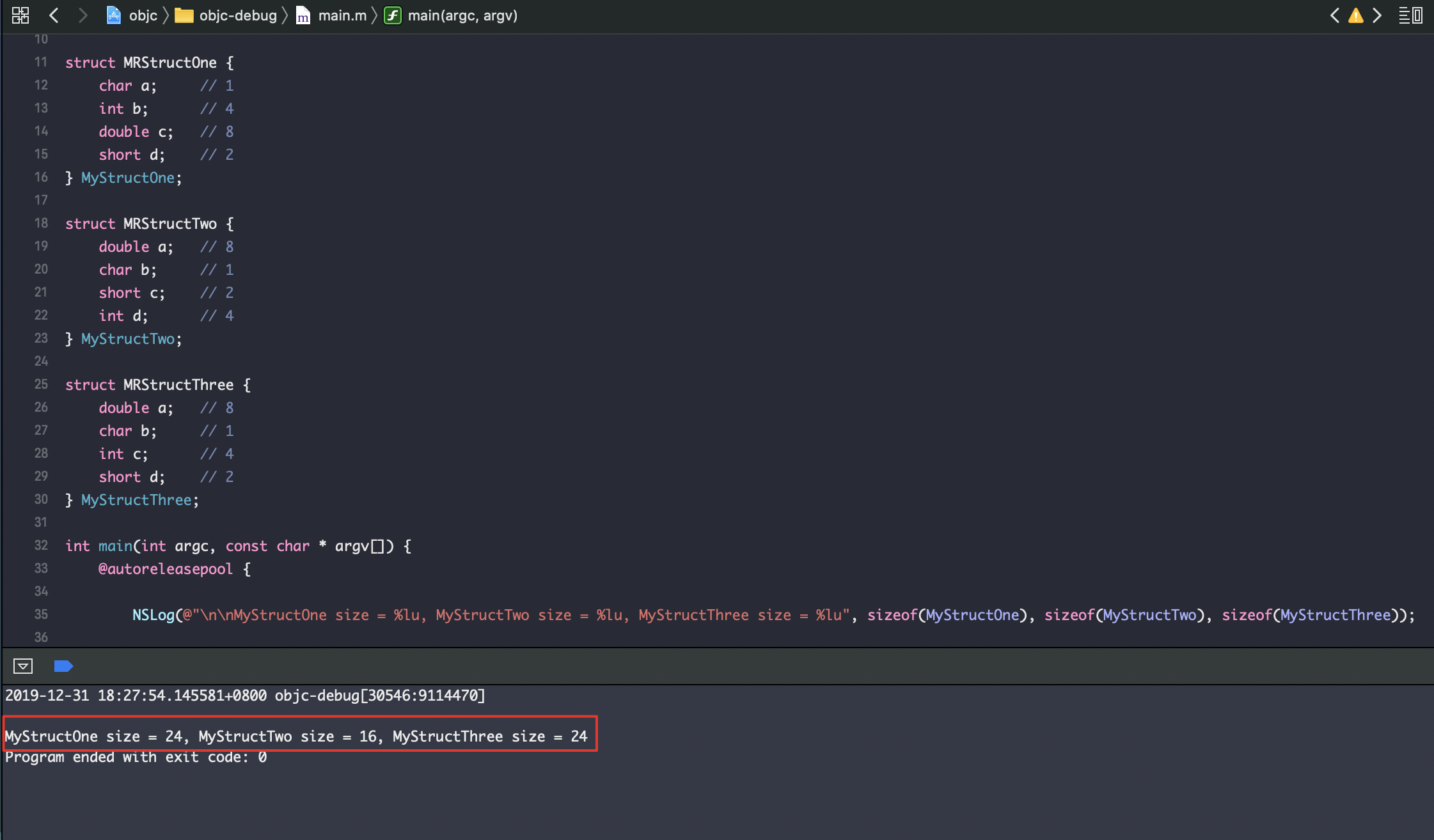
其中结构体的占用内存字节大小
sizeof计算出来是 24 - 16 - 24.
🌰sizeof = 24
struct MRStructOne {
char a; // 1 字节,补齐 + 7
int b; // 4 字节,根据对齐原则第一条,储存的起始位置是4字节的整数倍;
// 因为前面内存是1个字节的 char 类型,所以还不够填满整个8字节,
// 所以这里偏移到4字节处开始存储,
// int 存储占4字节,填满8字节
double c; // 8 字节,不需补齐,直接填满8字节
short d; // 2 字节,补齐 + 6
} MyStructOne;
sizeof = 8(4(1+3) + 4) + 8 + 8(2+6) = 24 字节
🌰🌰sizeof = 16
struct MRStructTwo {
double a; // 8 字节,不需补齐,直接填满
char b; // 1 字节,补齐 + 7
short c; // 2 字节,起始位置需要2的整数倍,前面占用一个字节,
// 能够存储的位置为246字节处,所以偏移到char后面2个字节的位置开始存储
int d; // 4 字节,该段的8字节还剩余4字节,刚好能填充d,直接填满8
} MyStructTwo;
sizeof = 8 + 8(2(1+1) + 2 + 4) = 16
🌰🌰🌰sizeof = 24
struct MRStructThree {
double a; // 8 字节,直接填满该段
char b; // 1 字节,补齐 + 7
int c; // 4 字节,起始位置需要4的整数倍,0被char占用,只能偏移4存储
// 那么前三个字节都存储 char b
short d; // 2 字节,前面8字节已经被填满,需要重新开辟8字节,补齐 + 6
} MyStructThree;
sizeof = 8 + 8(4(1+3) + 4) + 8(2+6) = 24
🌰🌰🌰🌰sizeof = 40
struct MRStructFour {
char a; // 8 字节, 不需要补齐,填满8字节
struct MRStructTwo b; // 16 字节, 前面定义的结构体2,size = 16字节
// 该结构体成员的子成员内部最大的是8字节,
// 所以存储起始位置偏移到a末尾的8字节处开始存储
// 需要2个8字节填充
long c; // 8 字节,不需要补齐,填满8字节
short d; // 2 字节,补齐 + 6
} MyStructFour;
sizeof = 8 + 16(2*8) + 8 + 8(2+6) = 40
对象属性内存优化
// 声明属性
@property (nonatomic, copy) NSString *name; // 8个字节
@property (nonatomic, assign) int age; // 4个字节
@property (nonatomic, assign) long height; // 8个字节
@property (nonatomic, copy) NSString *hobby; // 8个字节
@property (nonatomic, assign) int sex; // 4个字节
@property (nonatomic) char ch1; // 1个字节
@property (nonatomic) char ch2; // 1个字节
// 对象创建赋值
MRObject *obj = [MRObject alloc];
obj.name = @"testAlign";
obj.age = 18;
obj.height = 185;
obj.hobby = @"money";
obj.sex = 2;
obj.ch1 = 'a';
obj.ch2 = 'b';
然后打印对象的内存结构,查看对应属性的内存分配
(lldb) x obj 对象的指针内存情况
0x1019038d0: e9 25 00 00 01 80 1d 00 61 62 00 00 12 00 00 00 .%......ab......
0x1019038e0: 02 00 00 00 00 00 00 00 48 20 00 00 01 00 00 00 ........H ......
(lldb) x/4gx obj 按照每段8字节打印内存情况,4gx 代表4段
0x1019038d0: 0x001d8001000025e9 0x0000001200006261
0x1019038e0: 0x0000000000000002 0x0000000100002048
(lldb) x/6gx obj 按照每段8字节打印内存情况,6gx 代表6段
0x1019038d0: 0x001d8001000025e9 0x0000001200006261
0x1019038e0: 0x0000000000000002 0x0000000100002048
0x1019038f0: 0x00000000000000b9 0x0000000100002068
(lldb) po 0x1019038d0 对象的首地址就是对象地址
<MRObject: 0x1019038d0>
(lldb) po 0x001d8001000025e9 打印第一个段的值,打印不出来,因为这里是 isa,但是 isa 指针要通过 mask 处理之后才能对应到具体的值
8303516107941353
(lldb) po 0x0000000000000002 对应 int sex 成员的值,占4字节;如果不对 sex 赋值,这里会是0x0000000000000000 代表默认的野地址,还没有赋值,但是也会有内存开辟
2
(lldb) po 0x0000000100002048 对应 NSString *hobby 的值,8字节
testAlign
(lldb) po 0x00000000000000b9 对应十进制的 long height 185,因为浮点型会系统底层优化成十进制存储
185
(lldb) po 0x0000000100002068 对应 NSString *nanme 的值,8字节
money
// 😳那么 age 和 18 到底存在哪儿呢??
// 仔细一看还有一段内存 0x0000001200006261 没有读取,但是直接读取读不出来;
(lldb) po 0x0000001200006261
77309436513
// 看这个内存的结构如果直接拆成两部分,4字节 + 4字节呢,我们单独打印尝试一下
(lldb) po 0x00000012
18
// 直接打印出来了赋值的年纪 => 18 4个字节
// 那么剩余的四个字节是否就是 ch1 和 ch2 呢
(lldb) po 0x00006261
25185
// 打印不出来,这个时候我们想到 char 是占用一个字节,单独打印一半呢??
(lldb) po 0x0062
98
(lldb) po 0x0061
97
// 这个就很眼熟,我们恍然大悟,这不是 a 和 b 对应的 ASCII 码值么!a == 97, b = 98
从这里可以得出,在类的成员变量的内存大小分配的时候;系统会进行一次优化,将能进行对齐优化的成员编程放在一个段里面,节约内存空间,以空间换时间,加快 CPU 读取字节时候的偏移计算复杂度;而不是根据成员声明定义的顺序依次进行排布,这里就调整了顺序,然后直接最大化优化内存字节对齐。
malloc 源码
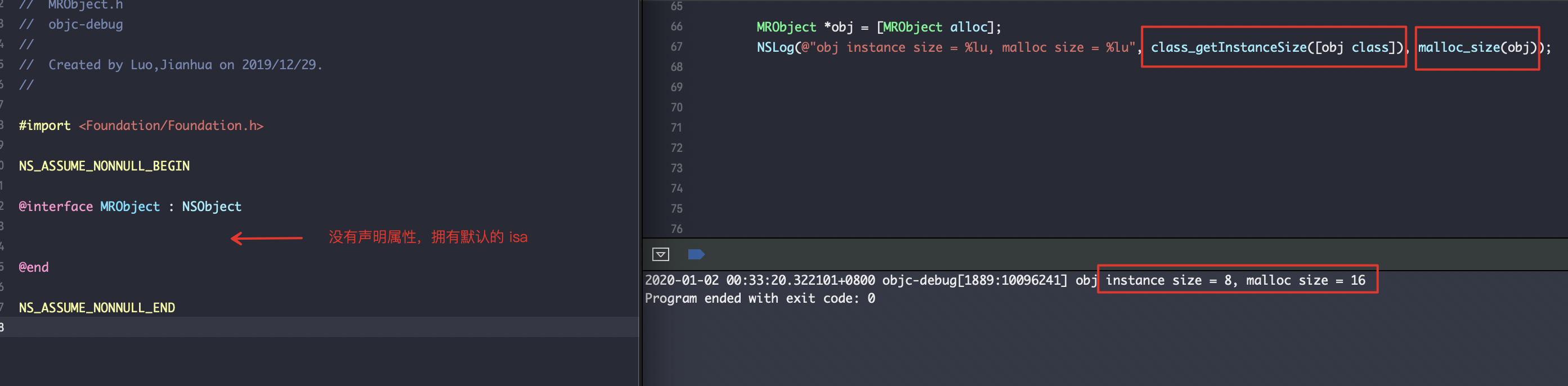
class_getInstanceSize获取的内存大小8(默认属性 isa 的内存大小);没有并没有按照之前alloc源码流程中的最少16的规则,这里是因为class_getInstanceSize方法没有走alloc流程中instanceSize方法的if (size < 16) size = 16条件,这里直接调用了直接对齐alignedInstanceSize() -> word_align(unalignedInstanceSize())返回的内存大小。
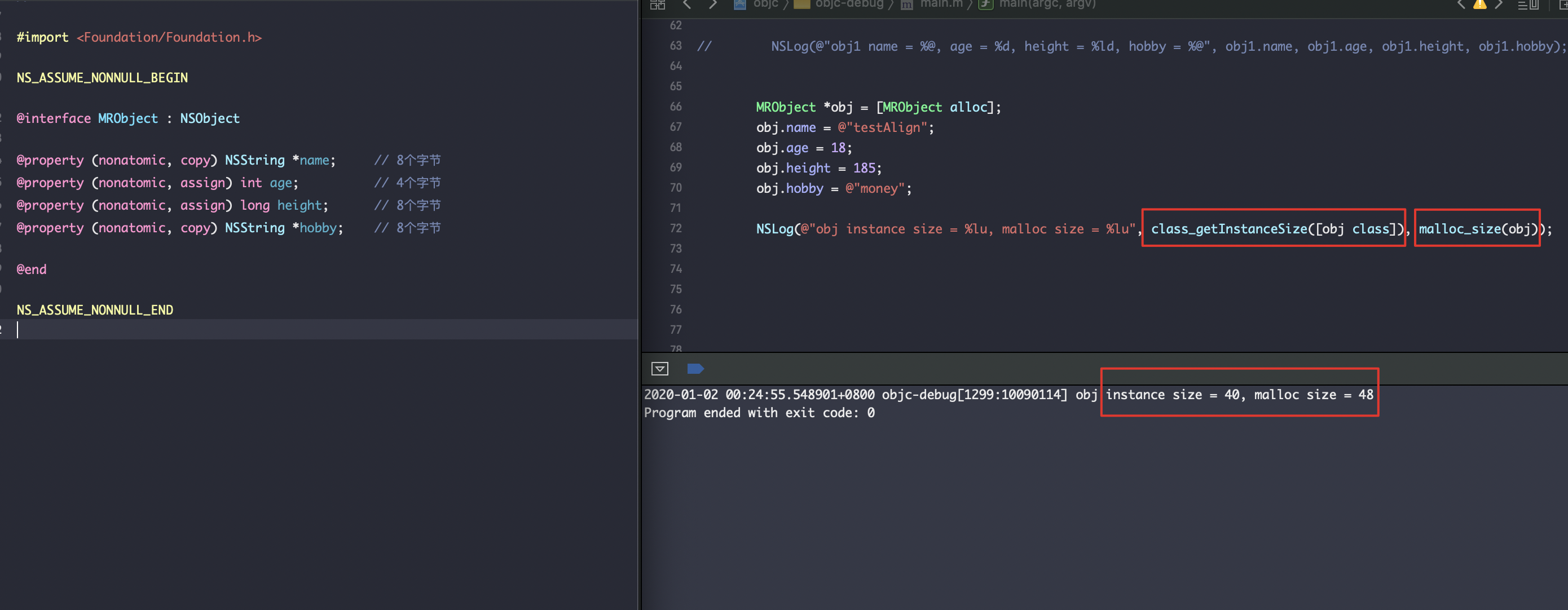
声明了几个属性之后发现就大于16了,因为 isa(8) + name(8) + age(4) + 补齐(4) + height(8) + hobby(8) = 5*8 = 40; 但是会发现 malloc_size 却不等于40,为48;这里就总结出 对象申请的内存大小 与 系统开辟的内存大小 不一致
系统开辟内存 - calloc
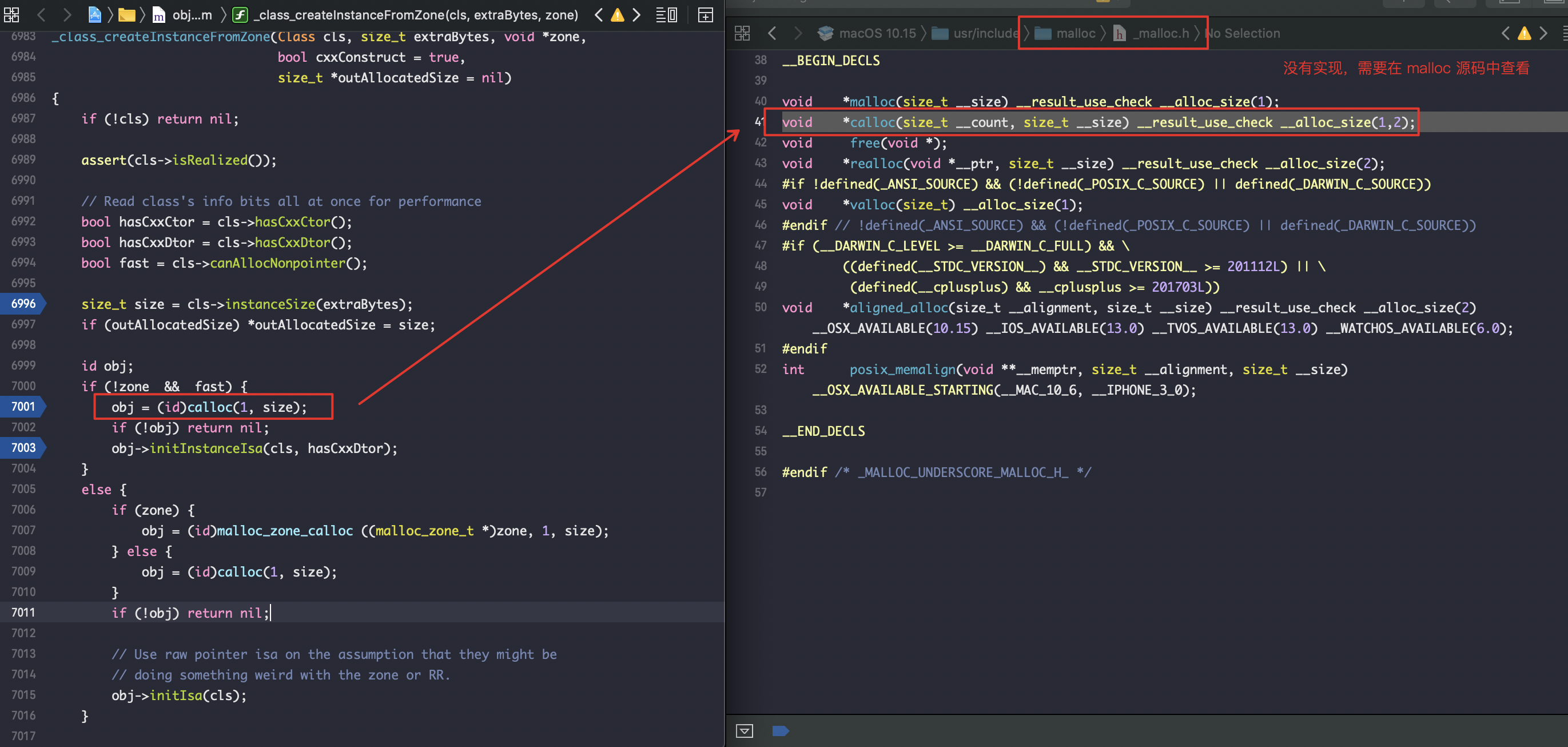
在objc源码中查看不了calloc源码的实现,需要在malloc源码中查看。
calloc => malloc_zone_calloc
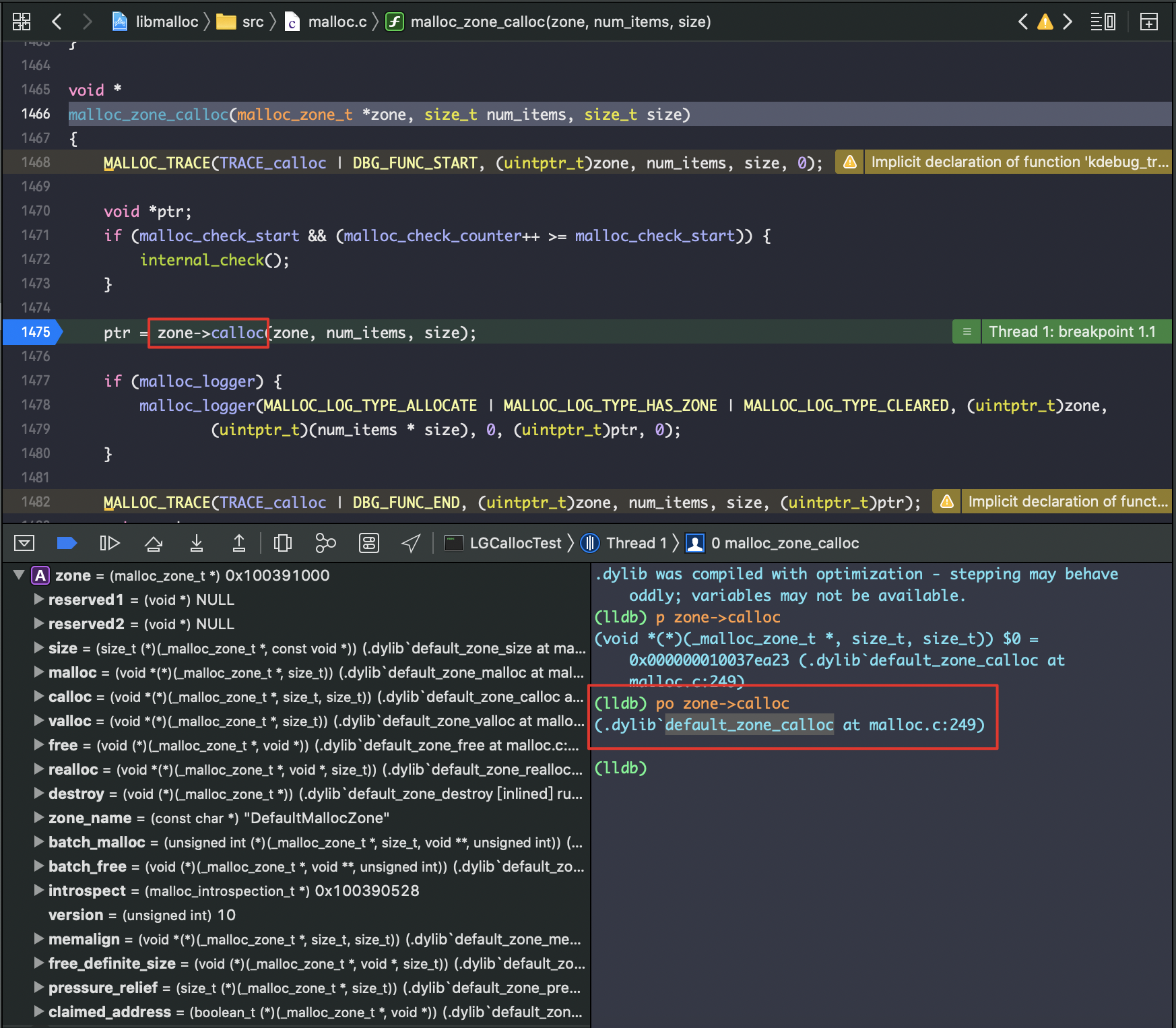
default_zone_calloc; 全局搜搜函数名得到定义。
static void *
default_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size)
{
zone = runtime_default_zone();
return zone->calloc(zone, num_items, size); // 递归调用
}
发现又是一个递归调用,断点打印zone的calloc成员属性;
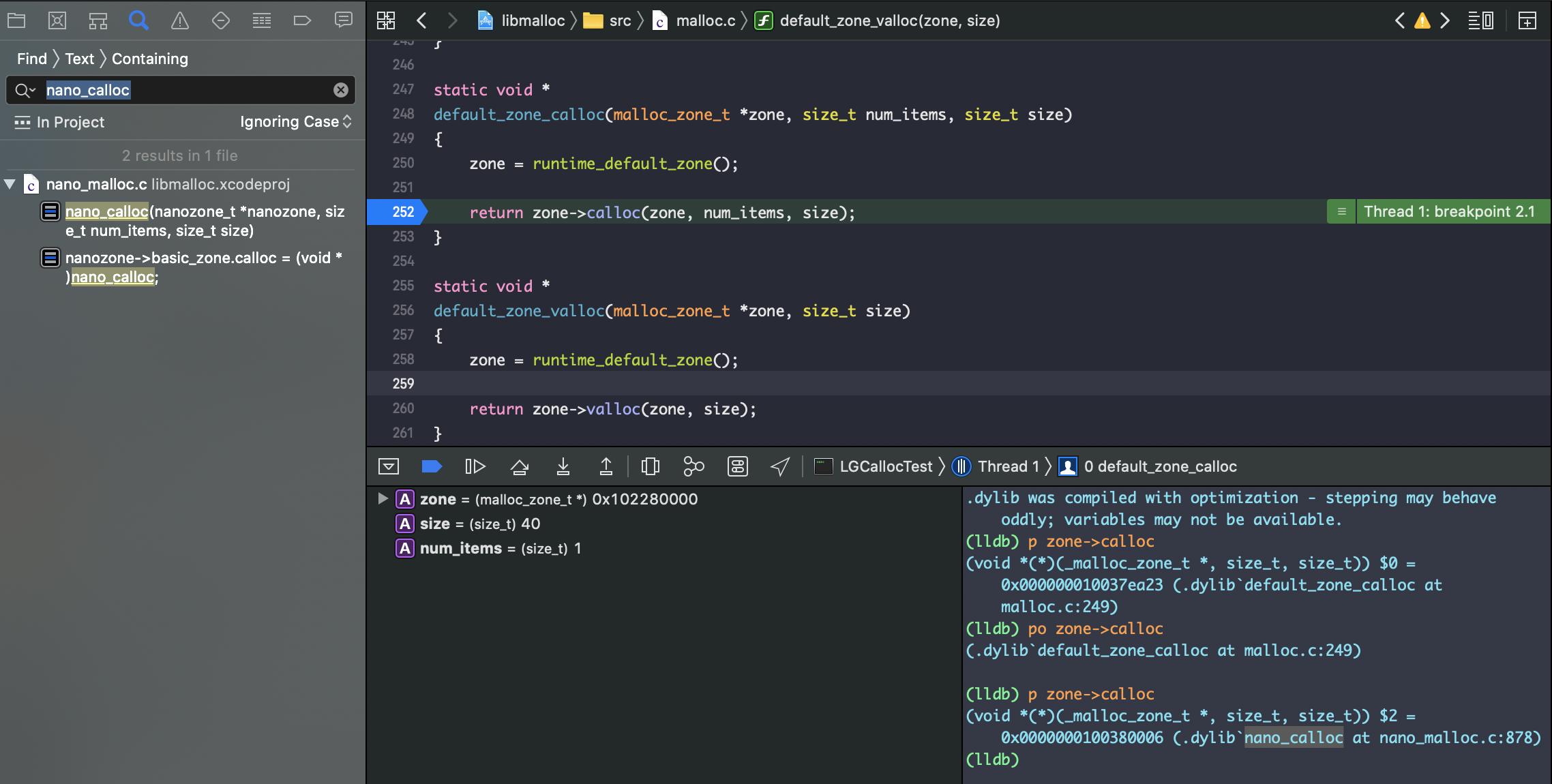
得到nano_calloc方法
static void *
nano_calloc(nanozone_t *nanozone, size_t num_items, size_t size)
{
size_t total_bytes;
if (calloc_get_size(num_items, size, 0, &total_bytes)) {
return NULL;
}
if (total_bytes <= NANO_MAX_SIZE) {
// 分析到走这个逻辑,才是内存开辟过程
void *p = _nano_malloc_check_clear(nanozone, total_bytes, 1);
if (p) {
return p;
} else {
// 失败的情况,不是我们要找的内存开辟计算,跳过
/* FALLTHROUGH to helper zone */
}
}
// 失败的情况,不是我们要找的内存开辟计算,跳过
malloc_zone_t *zone = (malloc_zone_t *)(nanozone->helper_zone);
return zone->calloc(zone, 1, total_bytes);
}
定位_nano_malloc_check_clear方法
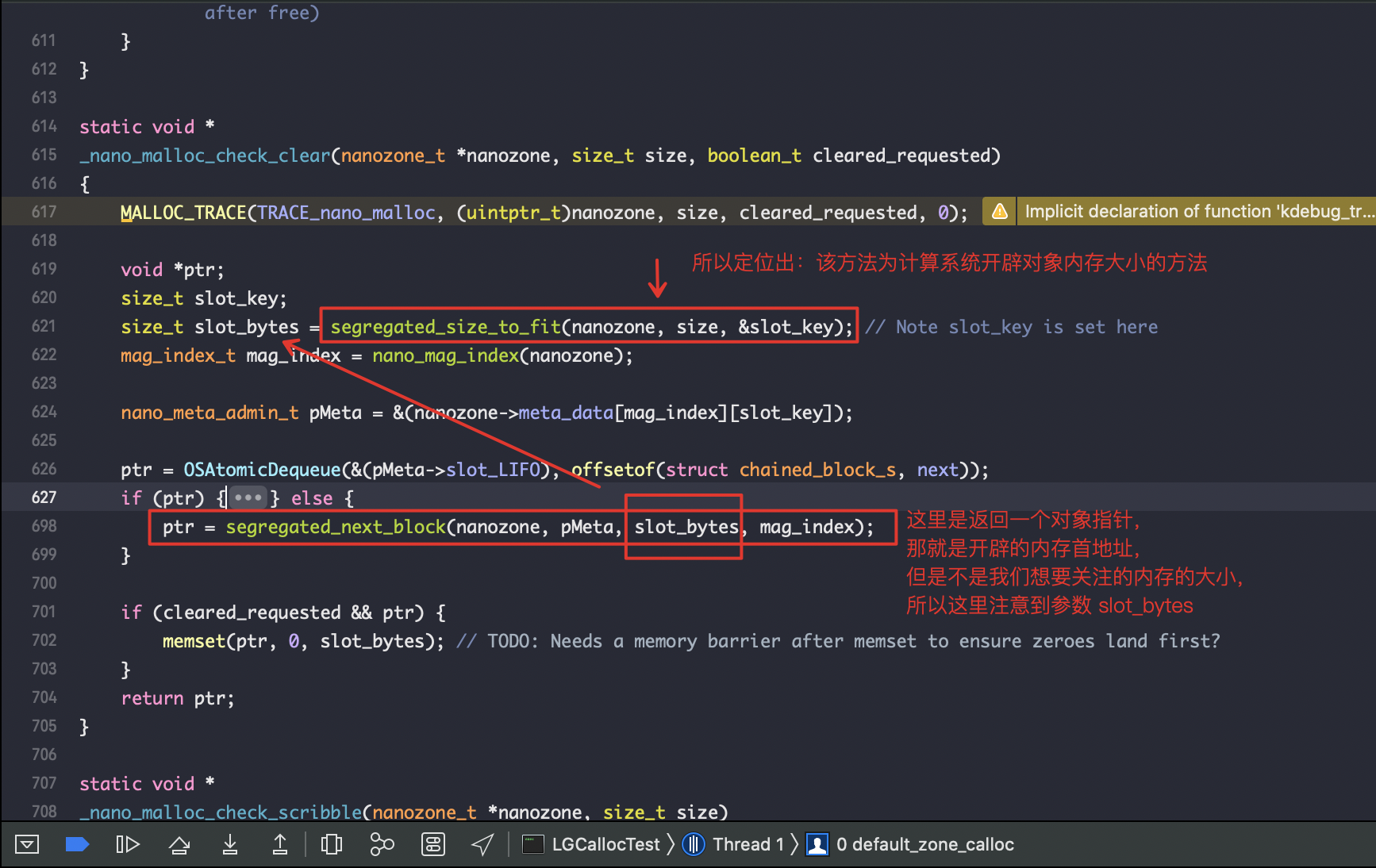
得到计算系统开辟对象内存大小的具体方法segregated,顾名思义:需要隔离填充的内存大小。
#define SHIFT_NANO_QUANTUM 4
#define NANO_REGIME_QUANTA_SIZE (1 << SHIFT_NANO_QUANTUM) // 16
static MALLOC_INLINE size_t
segregated_size_to_fit(nanozone_t *nanozone, size_t size, size_t *pKey)
{
size_t k, slot_bytes;
if (0 == size) {
size = NANO_REGIME_QUANTA_SIZE; // Historical behavior
}
k = (size + NANO_REGIME_QUANTA_SIZE - 1) >> SHIFT_NANO_QUANTUM; // round up and shift for number of quanta
slot_bytes = k << SHIFT_NANO_QUANTUM; // multiply by power of two quanta size
*pKey = k - 1; // Zero-based!
// 上面的定义翻译出来是: slot_bytes = (size + 2^4-1) >> 4 << 4;
// >> 4 << 4; 右移4位,然后左移4位,得到的就是16的倍数;
// 类似于之前介绍的8字节对齐; 所以这里是16字节对齐的算法;
return slot_bytes;
}
由这里16进制对齐的算法可以得出结论,40的类成员属性字节总数传递进来进行16字节对齐之后返回16*3 = 48字节。
总结
- 对象里面的属性 => 8 字节对齐;因为属性一般最大都为 8 字节!
- 对象 => 16 字节对齐;因为默认对象有一个
isa属性占用 8 字节,如果只给 8 字节那么就太紧凑,如果在多线程CPU进行读取的时候就容易造成溢出的风险;所以默认多 8 个字节进行16字节对齐!
结束语
以上为字节对齐及内存优化分析,有歧义欢迎指出,持续更新进阶之旅,未完待续。。。
