第2章-java内存区域和内存溢出异常
第一节:内存概述
- 概要:通常情况,jvm规范把内存分成了,
- 堆栈、堆、方法区。
前置知识
- 在单核单线程cpu的情况下:
- 1、cpu调度,最小执行单元是线程, 进程是资源分配的最小单元。
- 2、cpu把一小段时间,分成N个时间片段,然后调度线程,也就造成了在瞬时情况下,只有一个线程执行。
- 多核cpu
- 2、所以对于线程而已,只有cpu指令集,栈,程序计数器是私有的。
jvm运行时数据区示意图
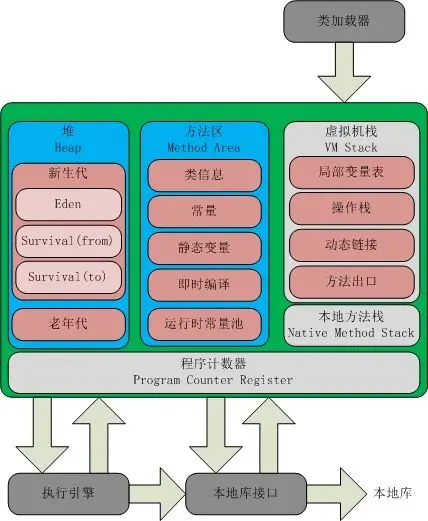
一、程序计数器:
- 1、cpu核心在同一时间只能调度一条线程,线程来回切换,尤其是在多核的情况下,所以就有了程序计数器来记录当前线程执行到了哪里
- 2、 程序计数器是一块较小的内存空间,记录执行行号,执行分支等等
- 3、线程恢复等等
- 4、执行navtive方法的话,那么就是undefined
- 5、在jvm规范中,唯一一个没有规定
outofmonery的地方
二、虚拟机堆栈
- 1、栈是线程独有,当线程结束的时候,栈也会随之销毁
- 2、每次执行一个方法的时候就会创建一个栈帧(
stack Frame),并且把这个栈帧压栈
- 3、栈帧中包含:局部变量表,操作数栈,动态链接,方法出口等等
- 局部变量表(也是常说的局部变量,对象引用):局部变量,对象引用,引用地址
- 4、本地方法栈,hotspot把本地方法栈和虚拟机栈合并在了一起
三、堆
- 1、不一定是物理上的连续空间,逻辑上的即可和硬盘是一个道理
- 2、存储java生成的对象,也是gc处理的主要区域
- 3、运行时方法区(规范中逻辑上划给了堆)
四、运行时方法区
- 1、hotspot中,将运行时,方法区放入到了堆中,认为是永生代,这样就造成了,在方法区中卸载类信息,容易
maxPerSize。
- 2、类加载信息,常量,静态变量,及时编译器编译后的代码。
- 3、运行时常量池
五、本机直接内存(并不属于运行时数据区)
- 1、基于管道和缓冲区的i/o方式,可以直接native函数库直接分配堆外内存,通过一个存储在堆内的DirectByteBuffer对象,作为这块内存的引用进行操作,即为NIO(
New input/output)
- 2、本机直接内存不会受到java堆大小的限制,但是会受到操作系统的限制
第二节:hotspot虚拟机对象
一、对象的创建
- 概要:主要讨论堆中对象的创建,但是不包括数组和类对象。
1、New指令发生了什么?
- 首先检测方法区常量池中,有没有class相关的引用,该class有没有加载相关的信息(被加载、解析、初始化)。如果没有加载,那么就加载class相关信息。
2、分配内存
- class加载完成后,会为为对象在新生代中,分配内存,分配内存根据GC回收算法不同采用的分配方式也不相同。
- serial和parNew等compact过程算法:
- 指针碰撞,用过的内存放于一侧,没有用过的内存放于另一侧,中间放一个指针作为指示器。
- 因为这两种算法,都是基于标记--整理算法,会把堆内存空间整理成绝对规整的空间。
- 每次在创建对象的时候,只要把指针向空闲空间那边移动和对象大小相同的空间即可。
- CMS等Mark-sweep算法:
- 空闲列表,记录哪块空间是可用的,并记录大小,为新对象分配内存
- 对象在内存中并不是规整的空间,而是使用过的空间和未使用的空间相互交错
- cms采用的是吞吐最优,所以他没有整理空间。
3、多线程创建对象:
- A线程在创建对象时,移动指针,但是B对象同时也想拥有该空间,移动指针。那么这个指针本身本身不是线程安全的。两种方式:
- 1、对内存空间同步处理:虚拟机使用CAS+失败重试机制,保证原子性。
- 2、预先给每个线程预先分配好一小块内存,称为本地线程分配缓冲(TLAB),当使用完TLAB以后,才需同步锁定。
- 虚拟机设置对象:
- 设置Object Header:对象是哪个类的实例(类型指针),对象的hash code,如何才能找到类的元数据,GC分代年龄信息。
- 已完成虚拟机对类和对象信息内容处理。
- 执行init方法,根据构造器,创建对象
二、对象内存布局
- 概述:对象在堆中:对象头(Header),实体数据(Intence Data),还有对齐填充(Padding)
运行时对象结构示意
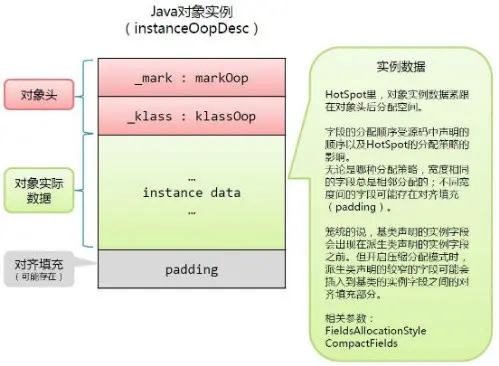
1、对象头(Header)
- 对象运行时数据(Mark World)
- HashCode,GC年龄分代,锁状态标志,线程持有的锁,偏向线程ID和偏向时间戳等。
- Mark World被设计成一个非固定的数据结构,不同的情况下,使用的内存大小是不同的,提高了内存利用率。
- class类型指针
- 虚拟机通过这个指针标识这个对象是方法区中的哪个类的实例。
- 并不是所有的虚拟机实现都保留了class类型指针(句柄池),换句话说查找对象不一定通过对象本身。(hotspot是保留了类型指针的)
- java为数组类型
- 对象头中必须保留数组长度的信息。
- 因为普通java对象可以通过元数据确定大小,但是数组不行。
2、实例数据(Instance Data)
- 保存对象的真正有用的信息,程序中定义的类型的字段信息(包括父类和自己的)。
- 字段的存储顺序会受到分配策略参数和字段在java源码中定义顺序影响
- hotspot默认参数分配策略:longs/doubles、ints、short/chars、bytes/booleans、oop(ordinary object Pinters) ,相同宽度的字段总是被分在一起。
3、对齐填充
- 并不是一定存在,对齐填充,仅仅是为了给对象占位。
- hotspot要求对象占位必须是8byte的整数倍,对象头是8byte的整数倍,所以当Instance Data不是8的倍数的时候,就要padding补齐
三、对象访问
- 概要:虚拟机规范只是规定了,栈帧中局部变量表中的reference类型指向堆中对象,没有规定,该以何种方式去定位、访问这个对象。目前有两种方式,一种是句柄访问、一种是直接指针。(牵扯reference类型,对象实例,class类型)
对象访问示意图
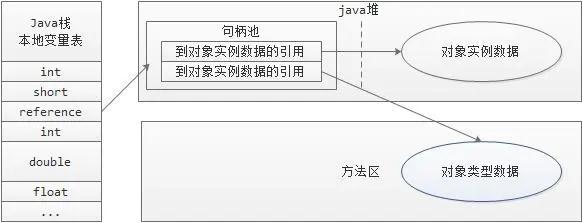
1、句柄访问(obj header中就没放class类型指针)
- 堆中划分出一块区域,作为句柄池。
- 栈帧局部变量表中reference保存的就是句柄池中对象的句柄地址。
- 句柄地址中,分别指向了obj实例数据和类型数据各自的具体地址。
2、直接指针(hotspot)
- 栈帧局部变量表中reference类型,保存的就是对象在堆中的具体地址
- obj Header中类型指针直接指向了方法区中class类型


