

本文主要介绍redis的哨兵模式(redis sentinel)的相关内容。哨兵模式是使用一个或者多个哨兵实例组成的系统,该系统用于监控redis集群中master服务器的工作状态,当master发生故障,可以实现master和slave服务器切换,保证系统的高可用。redis2.6+版本已经集成sentinel。 redis哨兵模式结构图:
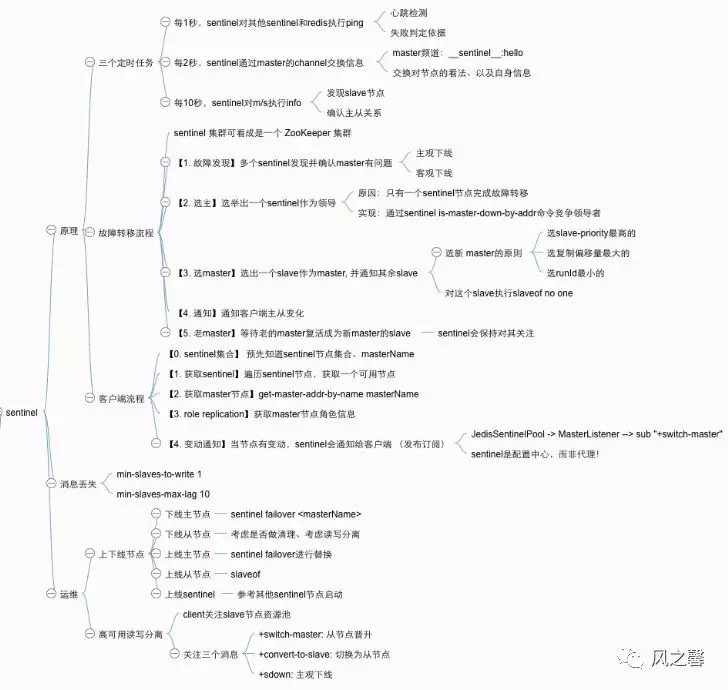
redis sentinel的工作机制: 监控(monitoring):哨兵(sentinel)通过流言协议(gossip protocols)会不断地检查你的master和slave是否运作正常。
提醒(notification):当被监控的某个redis节点出现问题时,sentinel可以通过邮件向管理员或者其它应用程序发送通知。
自动故障迁移(automatic failover):当一个master不能正常工作时,哨兵通过投票协议(agreement protocols)会开始一次自动故障迁移操作,它会将某一个slave升级为新的master,当客户端试图连接故障的master时,集群会向客户端返回新的master地址,集群可以使用现在的master替换失效master。master和slave服务器切换后,master的redis.conf、slave的redis.conf和sentinel.conf的监控目标会随之调换。
过程图解:
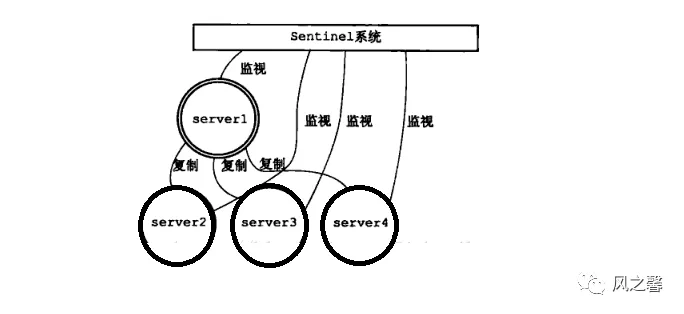
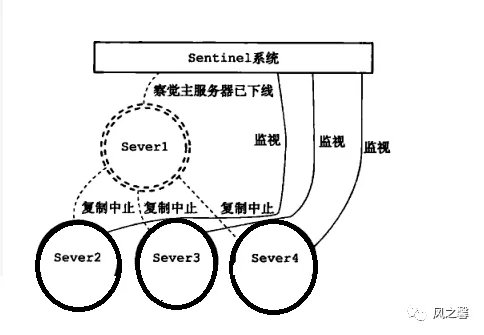
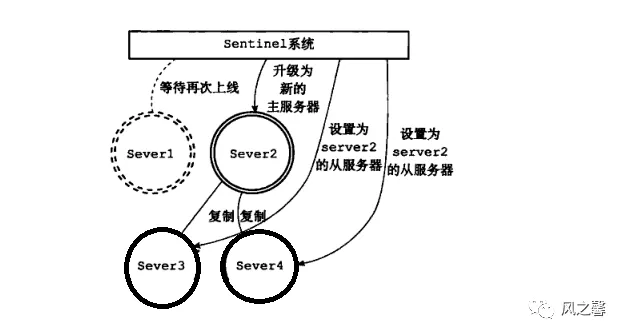
哨兵的作用
为了解决主从复制机构中出现宕机的情况。
master宕机
在slave端执行slaveof no one命令,断开主从关系并把slave角色切换为master继续提供服务。
旧master重新启动后,执行slaveof命令角色切换为slave继续为系统提供服务。
slave宕机
slave重新启动就会自动加入到当前的主从架构,自动完成同步数据。redis2.8之后,主从先断开后恢复连接的情况会实现增量复制。
哨兵的定时监控
任务1:每个哨兵节点每10秒会向主从节点发送info命令获取最新拓扑结构图,哨兵只需配置对主节点的监控,通过向主节点发送info,就可以获取从节点的信息,当有新节点加入可以马上感知到。
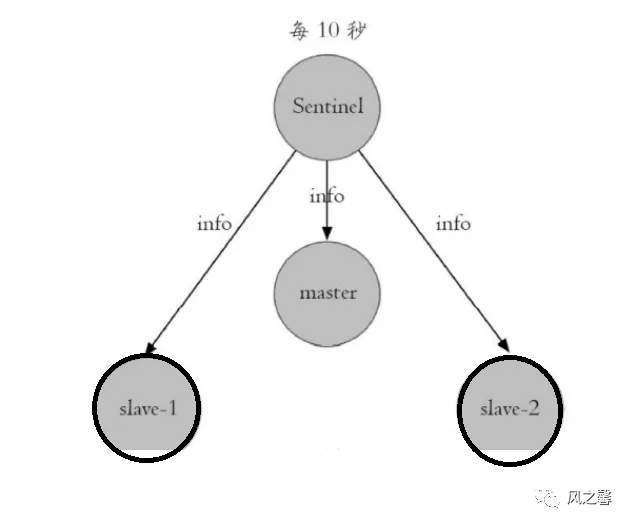
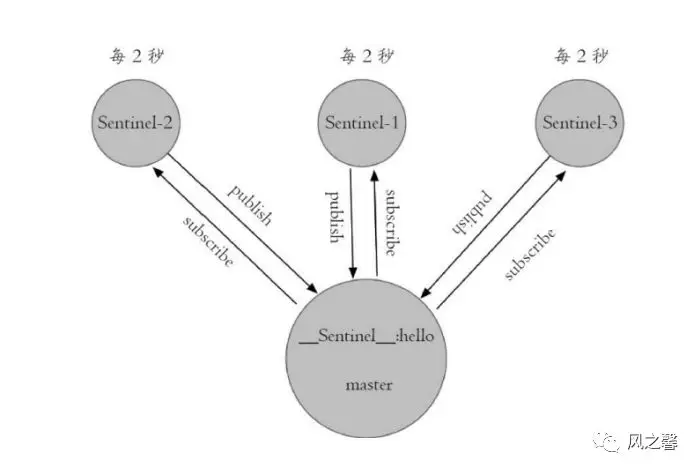
任务二:每个哨兵每隔2秒会向redis数据节点的指定频道发送该哨兵对于主节点判断和哨兵信息,同时每个哨兵节点也会订阅该频道,来了解其它哨兵节点的信息和对主节点的判断,通过消息的publish和subscribe来实现。
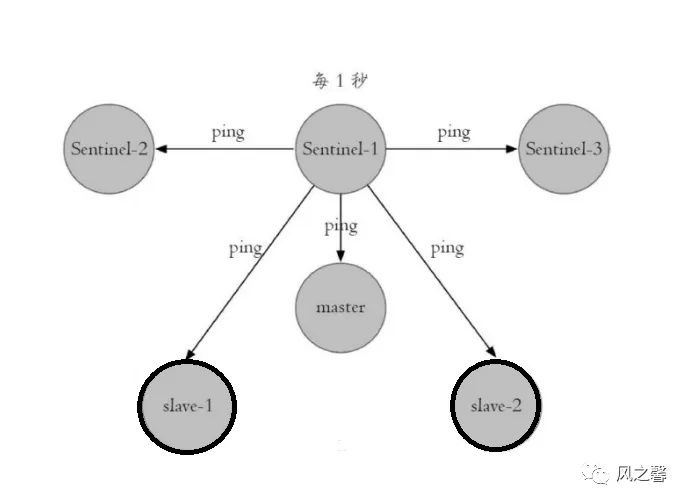
任务三:每隔一秒每个哨兵会向主从节点和其它哨兵节点发送一次ping命令做心跳检测,借此来判断节点是否正常。
哨兵实战部分
架构:1master2slave 1sentinel 实战
如果不知道主从怎么配置的可以查看redis 知识梳理(六),这里主要是针对sentinel进行配置。 1.从源码里把sentinel.conf复制到我们主从复制目录下

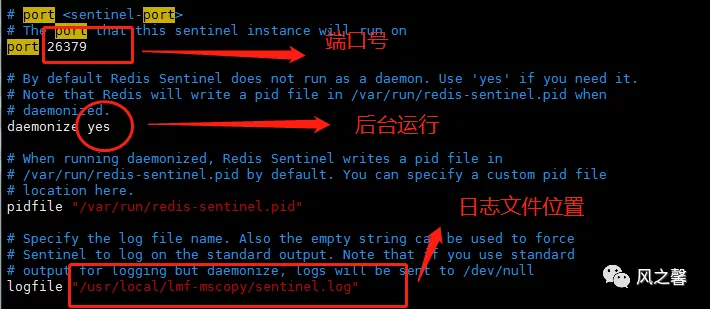
2.在sentinel.conf进行如下配置
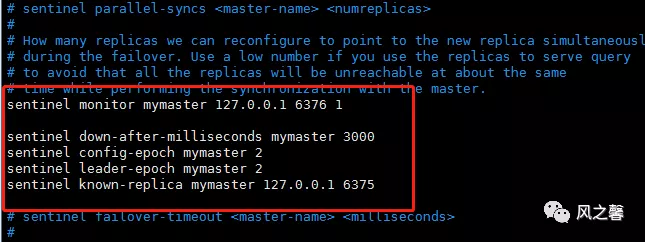
3.启动1master2从和sentinel
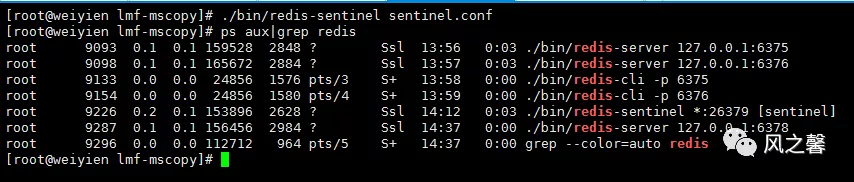
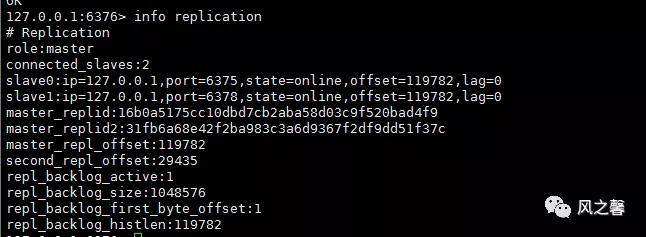
4.查看sentinel.log对6376进行监控。查看redis的从节点信息。

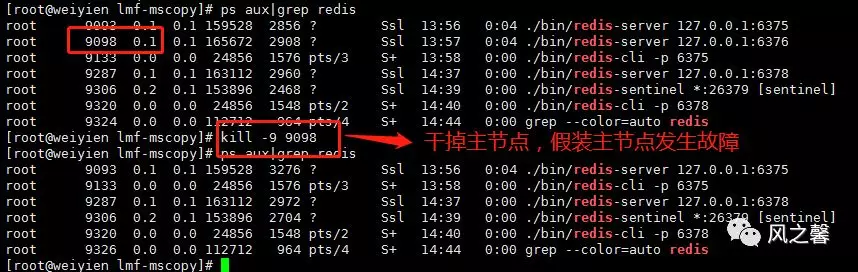
5.模拟6376出现故障,再查看sentinel.log,发现6375role角色在切为master。
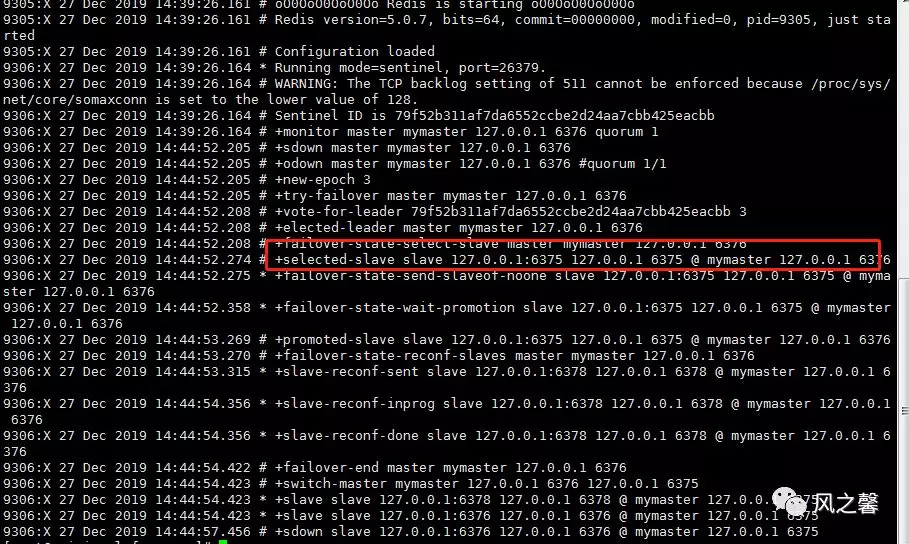
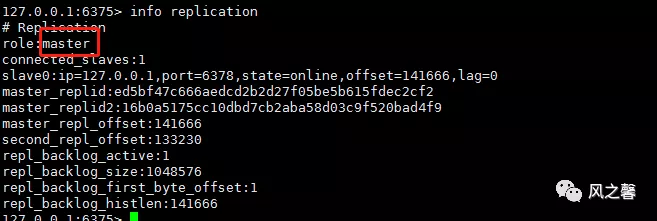
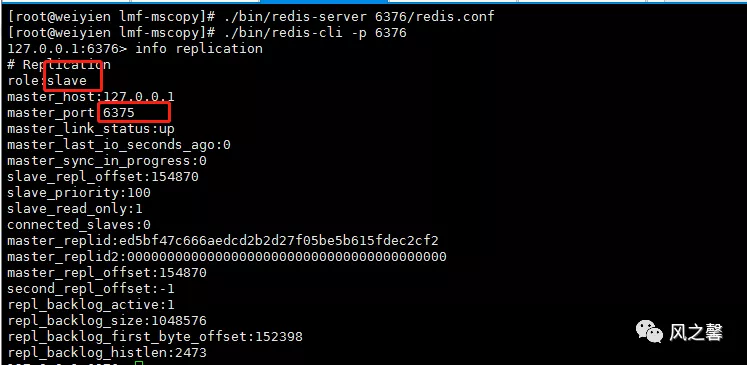
6.主服务器出现故障,故障修复后,会加入到原来的集群中,但此时角色已经切换为slave。
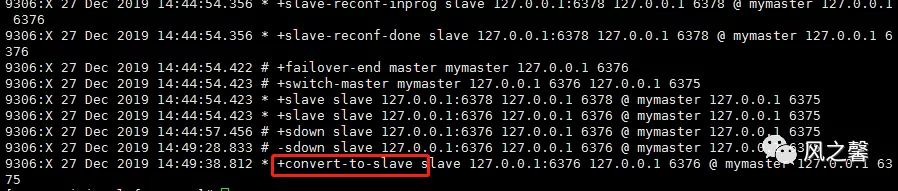
7.查看sentinel.log
复制俩份sentinel.conf,然后修改端口号和日志文件位置

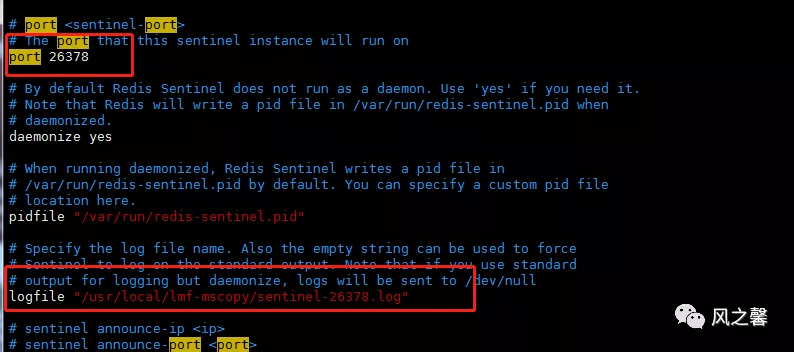
2.启动三个哨兵
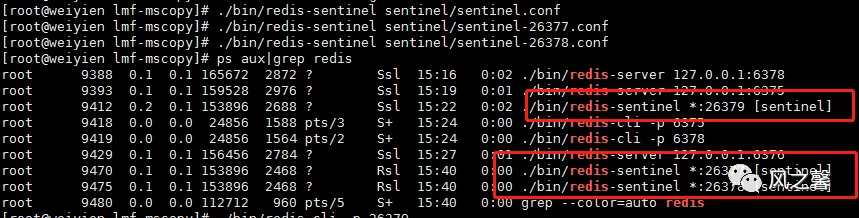

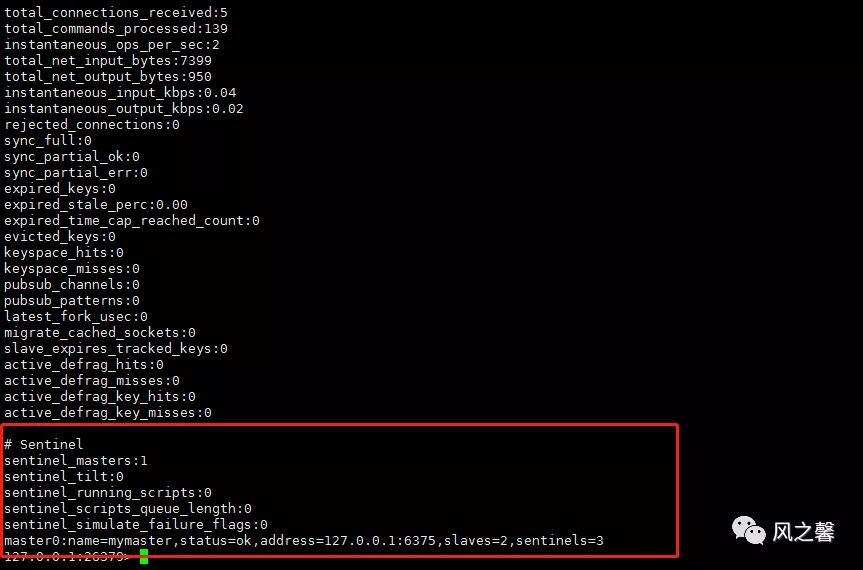
红框的圈出来代表集群节点的基本信息,master的ip、端口号,从节点的数量,哨兵的个数。 4.查看sentinel日志,我们看到哨兵正在监控redis集群

5.模拟master出现故障,再查看sentinel日志信息。
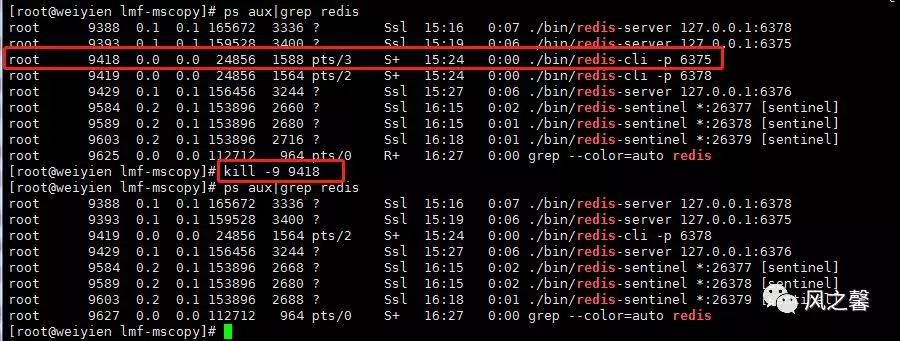
7.当master故障解决后,会发现角色变为slave服务器了。
sentinel.conf 配置文件详解

哨兵节点定期监控 名称为master-name可自定义 ip为监控节点ip(生产环境ip不要设置127.0.0.1或localhost) redis-port节点的端口号 quorum代表多少个哨兵认为节点故障了,才算主节点是客观下线。 port:哨兵实例运行的端口号 默认26379 dir:哨兵的工作目录 sentinel auth-pass
设置哨兵主从连接的密码,主从设置的密码必须一致
sentinel down-after-milliseconds
每个哨兵节点会定期发送ping命令来判断redis节点和哨兵节点是否可达的的,如果超过milliseconds没有收到pong回复,哨兵主观上认为主节点下线,默认30秒
sentinel parallel-syncs
当哨兵节点都认为主节点故障时,哨兵投票选出的leader会进行故障转移,选出新的主节点,原来的从节点们会向新的主节点发起复制,这个配置就是控制在故障转移之后,每次可以向新的主节点发起复制的节点的个数,最多为个,numslaves越大,多的slave因为replication而不可用,越小完成failover所需的时间越长。因为如果不加控制会对主节点的网络和磁盘IO资源很大的开销。
sentinel failover-timeout
故障转移时间,用在如下几个方面:
1.同一个sentinel对同一个master俩次failover之间的间隔时间
2.当一个slave从一个错误的master那里同步数据开始计算时间,直到slave被纠正为向正确的master同步数据时间。
3.当想要取消一个正在进行的failover所需要的时间。
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。如果超时slaves依然会被正确指向master,但不会按到parallel-sync配置的规则。
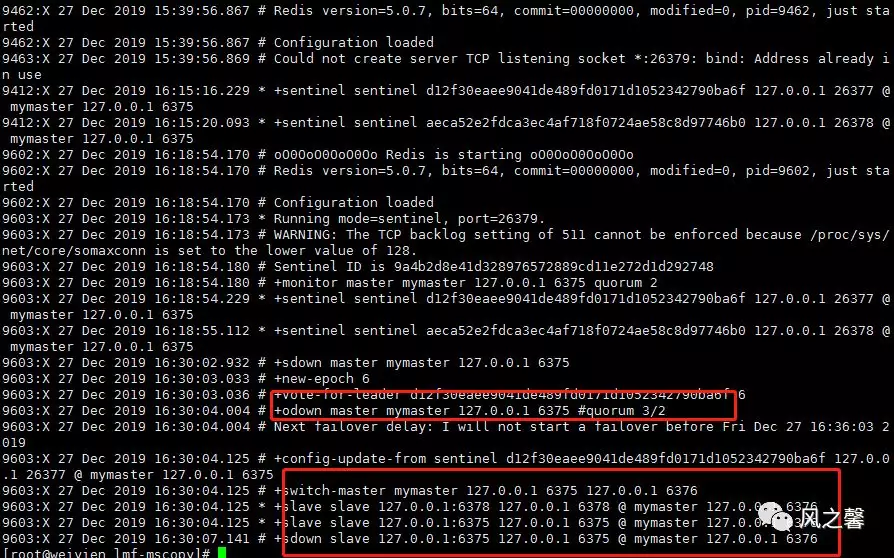
sentinel notification-script
配置当某时间发生时所需执行的脚本,可以通过脚本来通知管理员,例如当系统出现故障发送邮件通知相关人员。
对于脚本的运行结果以下规则。
1.若脚本执行后返回1,该脚本稍后将会被再次执行。
2.若脚本执行后返回>=2,脚本不会重复执行。
3.如果脚本在执行过程中由于系统中断信号被终止了,则同返回值为1一样的行为操作。
4.一个脚本最大执行时间为60s,如果超过这个时间,脚本将会被一个sigkill信号终止,之后重新执行。
查看配置文件关于该参数的解释:
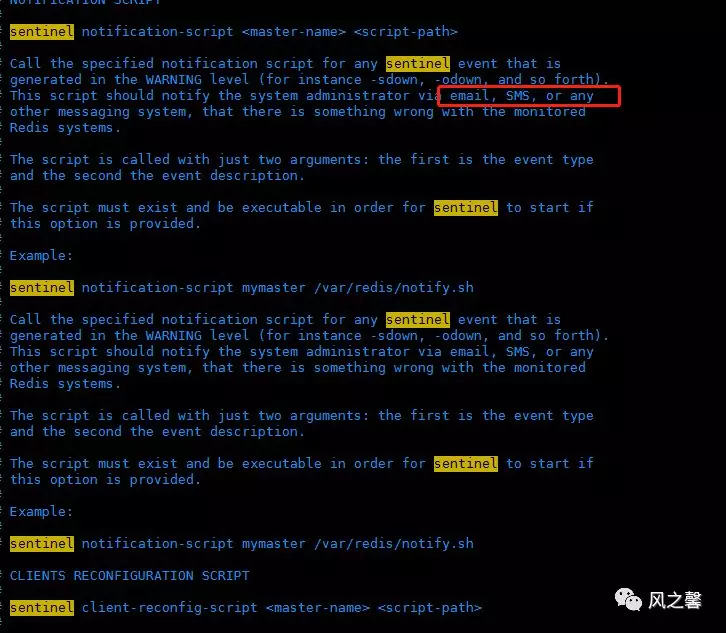
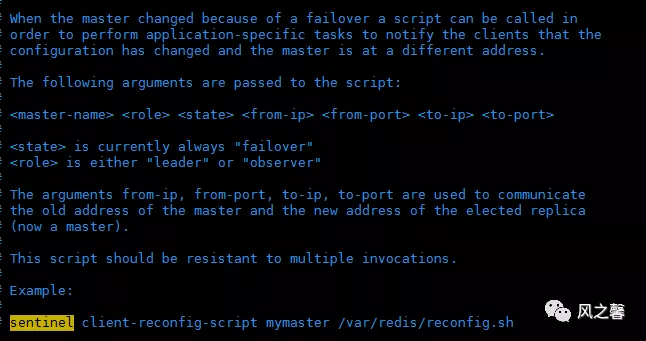
客户端重新配置主节点参数脚本 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。 以下参数将会在调用脚本时传给脚本: 目前总是“failover”, 是“leader”或者“observer”中的一个。 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的 这个脚本应该是通用的,能被多次调用,不是针对性的。
sentinel client-reconfig-script
具体配置文件解释:
三个定时任务 sentinel在内部有3个定时任务: 1.每10秒每个sentinel会对master和slave执行info命令,这个任务达到两个目的: a.发现slave节点 b.确认主从关系 2.每2秒每个sentinel通过master节点的channel交换信(pub/sub)。master节点上有一个发布订阅的频道(sentinel:hello)。sentinel节点通过__sentinel__:hello频道进行信息交换(对节点的"看法"和自身的信息),达成共识。 3.每1秒每个sentinel对其他sentinel和redis节点执行ping操作(相互监控),这个其实是一个心跳检测,是失败判定的依据。 主观下线与客观下线 主观下线:某个节点认为另一个节点不可用,"偏见"。
主观下线流程:
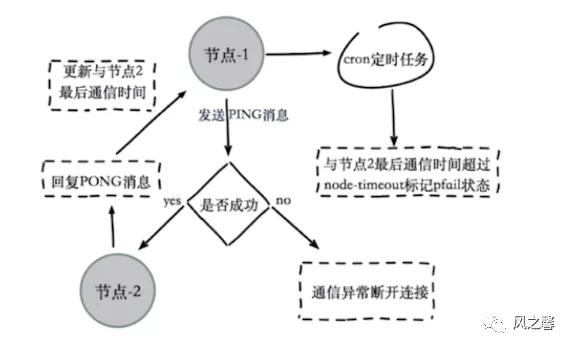
客观下线:当半数以上持有槽的主节点都标记某节点主观下线。
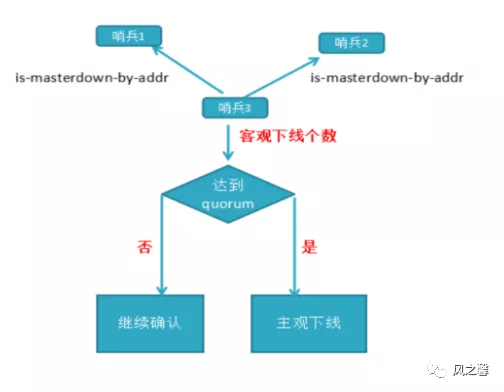
哨兵3节点会通过指令sentinel is-masterdown-by-addr查询其它哨兵节点对主节点的判断,如果其他的哨兵认为主节点主观线个数超过了quorum,哨兵节点则认为该主节点确实有问题线客观下线。
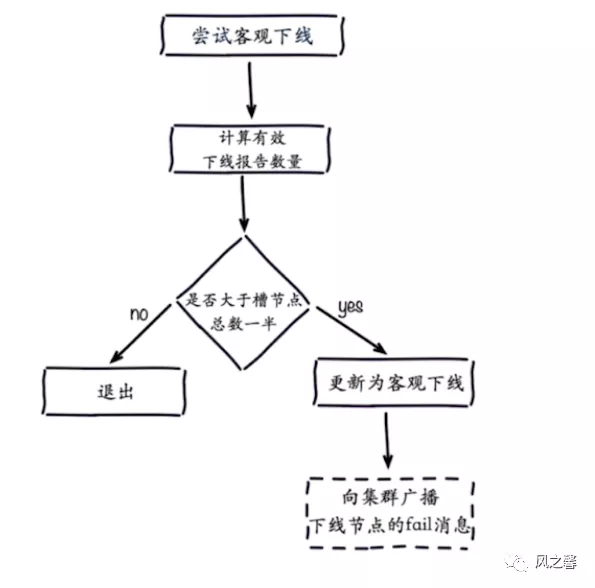
尝试客观下线:通知集群内所有节点标记故障节点为客观下线,通过故障节点的从节点触发故障转移流程。
哨兵leader推举
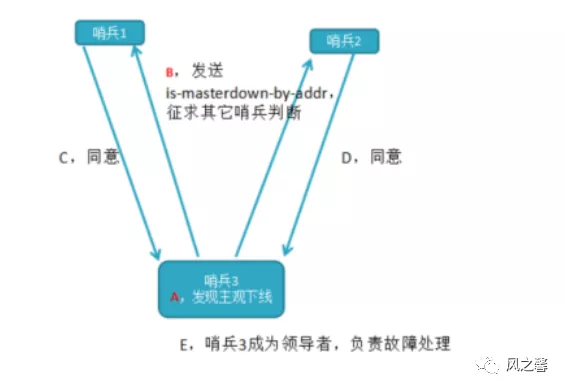
主节点客观下线后,任意哨兵都可以成为领导者,会向其它的哨兵节点发送is-master-down-by-addr命令,征求判断并推举为自已为领导者。如果其它哨兵同意票数大等于(哨兵总个数/2)+1就成为领导者并负责故障转移,没有继续选举。
自动故障转移机制
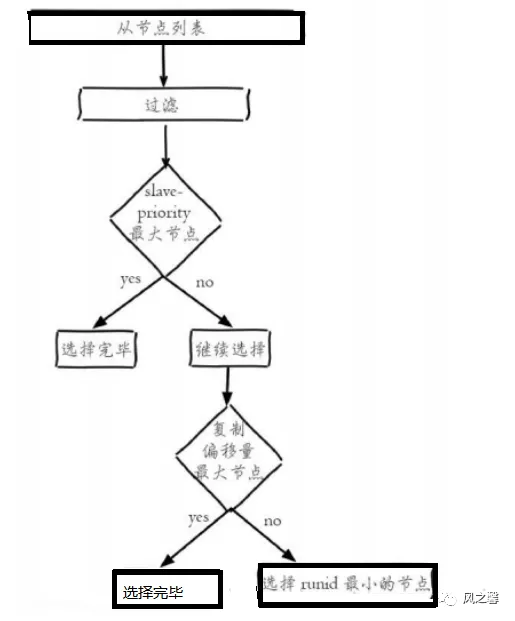
当哨兵leader选举完成后,会从现有的slave节点中挑出一个充当为主节点。
过程:
过滤中主观下线的节点,然后选择slave-priority最高的节点,有的话直接返回,没有继续选择。选择出复制偏移量最大的salve节点,因为复制偏移量越大则数据复制的越完整,如果有就返回了,没有就继续,选择run_id最小的节点,通过slaveof no one命令,把选择出来从节点更改为master,再通过slaveof命令让其它节点成为它的从节点。原来的主节点会设置成新从节点,等恢复正常以从节点角色加入。
sentinel命令查看主从服务器信息 PING :返回 PONG 。

SENTINEL masters :列出所有被监视的主服务器,以及这些主服务器的当前状态;
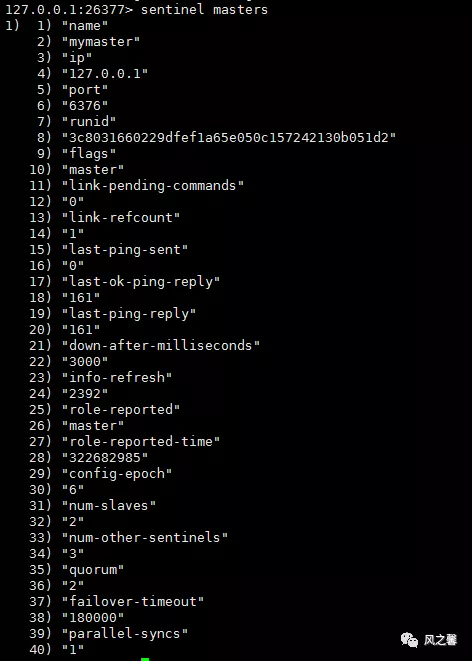
SENTINEL slaves :列出给定主服务器的所有从服务器,以及这些从服务器的当前状态;
SENTINEL get-master-addr-by-name :返回给定名字的主服务器的 IP 地址和端口号。如果这个主服务器正在执行故障转移操作, 或者针对这个主服务器的故障转移操作已经完成, 那么这个命令返回新的主服务器的 IP 地址和端口号;

SENTINEL reset :重置所有名字和给定模式 pattern 相匹配的主服务器。pattern 参数是一个 Glob 风格的模式。重置操作清楚主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel;如:sentinel reset * SENTINEL failover :当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移。 (不过发起故障转移的 Sentinel 会向其他 Sentinel 发送一个新的配置,其他 Sentinel 会根据这个配置进行相应的更新),主从切换了。

SENTINEL MONITOR 这个命令告诉sentinel去监听一个新的master SENTINEL REMOVE 命令sentinel放弃对某个master的监听 SENTINEL SET 这个命令很像Redis的CONFIG SET命令,用来改变指定master的配置。支持多个。例如:SENTINEL SET objects-cache-master down-after-milliseconds 1000 只要是配置文件中存在的配置项,都可以用SENTINEL SET命令来设置。这个还可以用来设置master的属性,比如说quorum(票数),而不需要先删除master,再重新添加master。例如:SENTINEL SET objects-cache-master quorum 5
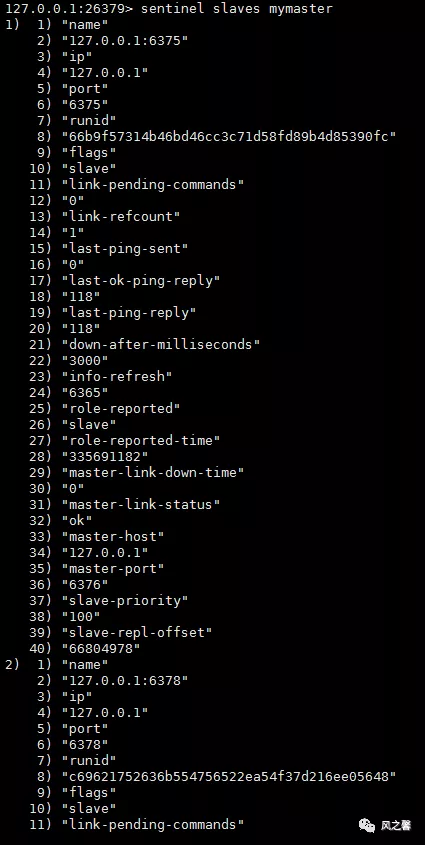
SENTINEL sentinels 查看其它sentinel信息
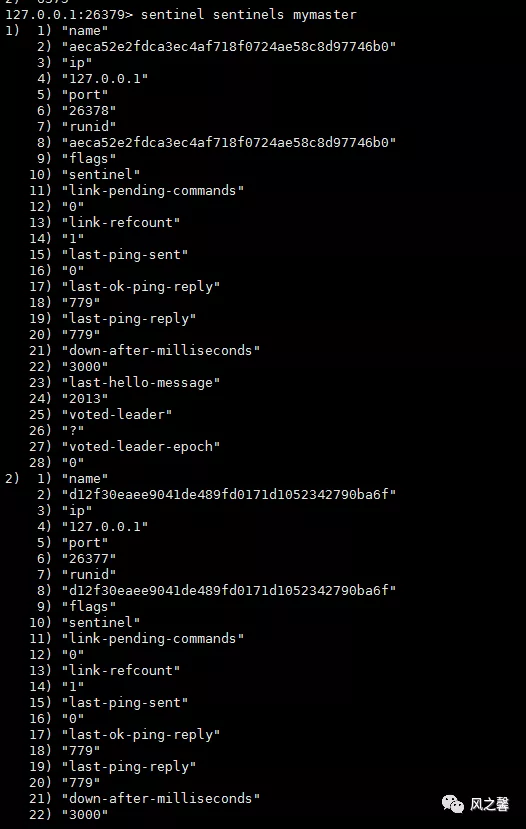
sentinel ckquorum 查看sentinel监控是否正常

sentinel flushconfig 配置文件丢失,重写配置文件
增加或删除sentinel
增加sentinel直接配置好参数开启一个sentinel即可。每30秒添加一个sentinel,紧接的增加可以有效预防网络隔离带来的问题。
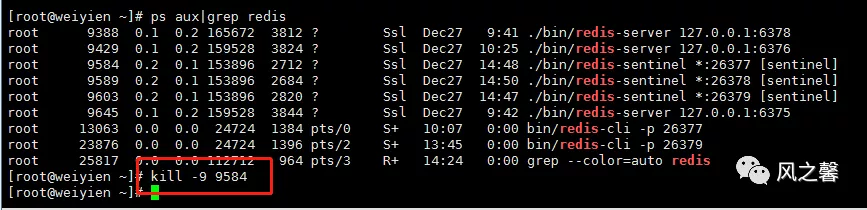
sentinel不会主动删除已经存在过的sentinel,即使它已经与组织失去联系。删除步骤:
找出进程号,kill掉。
发送一个sentinel reset * 命令给所有其它的sentinel实例,如果你想要重置指定master上面的sentinel,只需要把*号改为特定的名字,注意,需要一个接一个发,每次发送的间隔不低于30秒。
num-other-sentinels来查看是否成功添加或者删除sentinel。
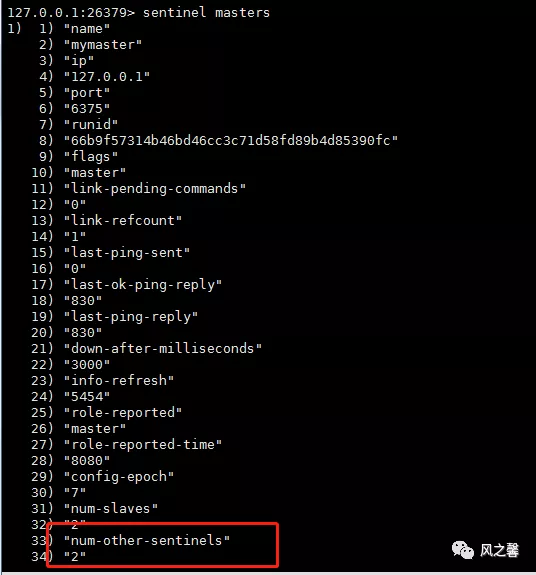

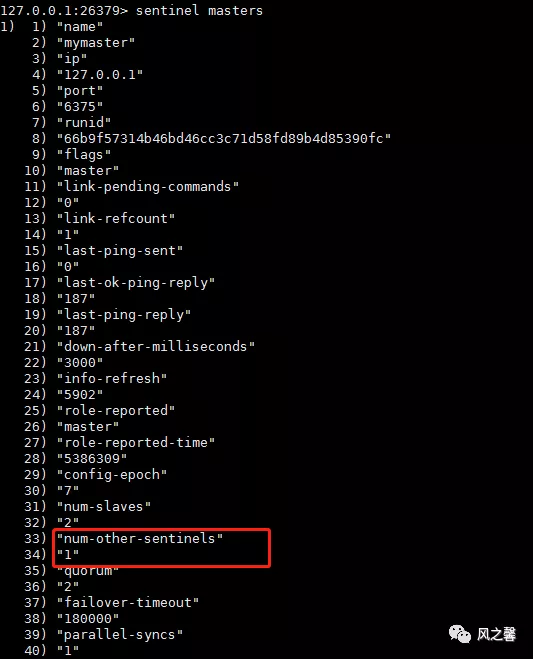
删除旧master或者不可达slave步骤如上。
发布与订阅
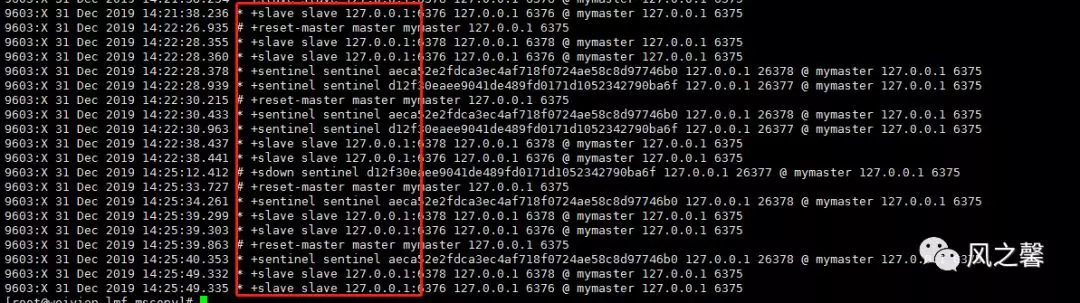
客户端可以将 sentinel看作是一个只提供了订阅功能的 Redis 服务器:你不可以使用 publish 命令向这个服务器发送信息,但你可以用 SUBSCRIBE 命令或者psubscribe命令,通过订阅给定的频道来获取相应的事件提醒。 一个频道能够接收和这个频道的名字相同的事件。比如:名为 +sdown 的频道就可以接收所有实例进入主观下线(sdown)状态的事件。
+switch-master :配置变更,主服务器的 IP 和地址已经改变。这是绝大多数外部用户都关心的信息。
本文详细介绍了哨兵模式的相关内容,如果您觉得还不错,关注我公众号,更多精彩好文等着你。

