

Introduction
在开始之前, 我想说一下, 分析GMP的定位, 以及工作流程是一个非常冗长的行为. 这跟reflct分析不一样, 即使花去了两周时间看各种文章, 代码阅读. 我也只能说, 只敢说我刚刚摸到了调度的门, 只看调度就已经不容易, 有时候你需要结合GC一起考虑进去, 在这篇文章里我没提到GC下我们应该怎么处理一些问题, 也许是我对GC没有很深的理解, 如果我有, 我会及时更新我对于调度的理解
我希望看这个文章的人能先看看Introduction部分, 大概的去了解各种名词, 各种组件的定义, runtime源码编写的风格跟别的内置包不同, 如果直接跳进源码很有可能一头雾水.
为什么Go需要设计goroutine
在我们开始介绍goroutine(后面称gr)之前, 我们需要了解为什么, Go需要自己设计一套自己的"routine", 为什么还需要自己实现调度.
我们知道, 线程(thread), 是操作系统调度的最小单位, 并且操作系统会有自己的一套逻辑来调度管理这些Thread. 这些资源以及管理模式全都是现成可用的. 事实上, C/C++, Java中的确也是这么做的, 他们的pthread也就是用于做这些事的. 那这现成的一套有什么不好呢?
Thread太重: Thread相比较于process已经非常轻量了, 但也不是我们想要的"那么轻量". thread作为一支完整的线程具备信号掩码,上下文环境以及各种控制信息等, 这其中已经出现了很多多余的Go并不需要的数据了. 此外一个thread默认占用栈空间1M, 这样的大小使得你无法大量去创建线程
Thread切换开销大: 要知道既然你创建的是thread, 那么在操作系统看来, 主函数还是一个简单的线程, 就没什么区别了, thread切换是要经过穿过用户态到达内核态的, 因此上下文切换开销很大
Thread间通信困难: thread间通信虽然有很多机制可选, 但实际使用起来复杂, 一旦涉及到shared memory, 各种锁的问题立刻就来了, 死锁的问题就变成家常便饭.
程序不好写: 创建一个线程如果还好, 那么回收一个线程就十分麻烦了, 需要去判断是不是detached还是需要去Join. 逻辑十分复杂. 此外, 考虑到我们无法大量创建线程, 那么我们就需要在有限的线程里做多路复用, epoll就是为了解决这个问题而出现的. 就算是这样, 程序也非常不好写, 不好维护, 也不好看
无法满足GC的需求: 最主要的问题还是无法满足GC, GC需要STW, 要求内存保持一种一致的状态, 在使用thread的情况下, 假设我们有10个线程, 我们现在需要等10个线程全部停下来. 但是假设我们是有10个gr/一个线程, 一个线程内只会有一个gr在运行. 因此我们只需要等这一个gr停下即可, 相比于等10个线程停下可以说是拉了一个总闸, 方便很多
在这里引用一段英文, 我认为总结非常到位
Threads have their own signal mask, can be assigned CPU affinity, can be put into cgroups and can be queried for which resources they use. All these controls add overhead for features that are simply not needed for how Go programs use goroutines and they quickly add up when you have 100,000 threads in your program
线程并不是不好, 设计理念也并没有出问题. 只是在Go语言中我们针对并发的需求, 并没有这么庞大且全面, 我们也许只是并发的去发一个request, 也许只是并行的计算个什么东西, 很多时候并不是一些很难的东西, 我们也不需要去内核态中切换, 也不需要进程掩码. 在Go语言中我们希望它写起来很简单, 不要复杂, 很小, 我能在我的机器上创建一大堆出来最好, 也别搞多路复用.
那么Go实际是怎么设计的
从整体上来看: 为了解决上面的问题, 首先Go创造了一种叫做goroutine的东西(类似于coroutine), gr占用的资源非常少, 相比较于thread的1M栈, gr只需要2K. 因为是用户级, 因此调度过程也不需要进入操作系统内核, 最后非常容易能创建出成千上万个(一大堆).
将这些gr按照一定策略放到"CPU"上去运行, 这其中的"策略"就是go的调度策略, 负责执行这些策略的就叫go的调度器.
简单介绍一下GMP分别指什么
在runtime的眼中, 它将所有需要管辖的内容划分成G/M/P三个部分, 将这个三个部分统合协调好, 成为调度器的所有工作:
G(代表一个gr) : 存储有gr的栈信息, gr的状态, 以及gr需要执行的函数
P(逻辑Processor/局部调度器): 为什么是"逻辑"以及为什么是"局部调度", 后面会介绍 ,P是在Go1.2以后为了处理一些问题加入进来的组件. 起着"胶水/缓冲"一样的作用. 每个P受M线程管辖, 同时自己手持一个G队列, 他局部调度因为他只调度自己手下的G队列, 相比于"局部调度", 我们还存在一个"全局"调度schedt, 全局调度负责什么, 什么时候出现我们也会在后面说
M(代表一个线程): M就是一个真正的线程了. 操作系统直接管辖M, 在M绑定了一个有效的P以后, P的调度逻辑开始发挥作用, 内容包含: 从各种队列中获得G, 切换到G的栈上去执行G的函数, 执行完成了以后开始清理. 值得注意的是, M本身不保留任何跟P或者G的相关信息, 这么做是为了能将M独立出来, 让G能够跨M工作.
简单说说G/M/P三者之间的关系
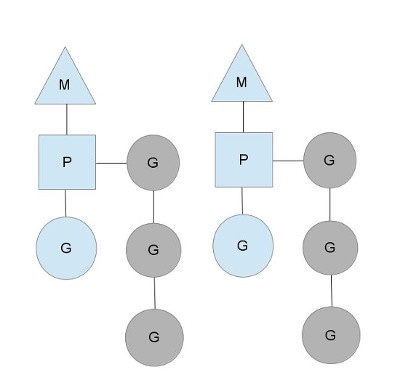
上图中包含了两个线程(M),每一个都持有自己的局部调度器(P), 运行着一个G(蓝色). 同时还有一个等待运行的本地G队列(灰色). 下面换一张更详细的图, 说明白GMP三者的关系:
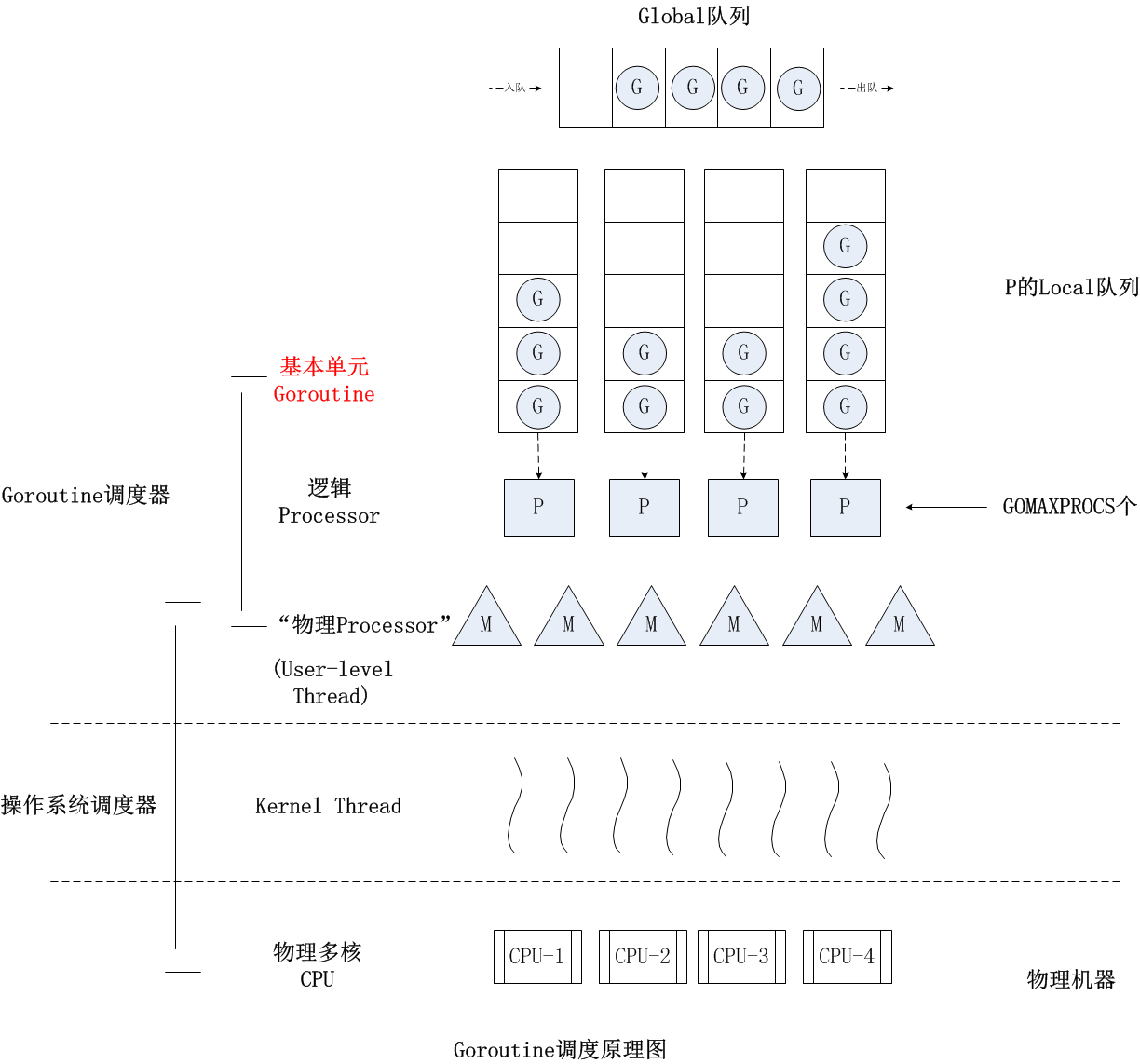
我们解释一下为什么P被称作 "逻辑Processor", 而不是一个真正的CPU. 每个G想要运行起来, 就需要先被分配一个P. 对于G来说, P就是它的CPU, 可以说: G的眼里只有P, G认为是P在执行他. 而从Go scheduler视角来看,真正的“CPU”是M. 真正负责接收操作系统调度, 放在CPU上跑的是M. 只有将P与M绑定了, 才能让G队列中的G运行起来.
最后总结一下P, 这个"逻辑CPU"的工作, 负责管理gr, 按照一定策略将gr推到thread(M)上工作. 现在我们能理解"逻辑" 这个词的含义了.
说完了P&G之间的关系, 再理一理P&M之间的关系, 从上图可以看到, 每个M绑定一个P, 而P负责选出一个gr来运行, 因此M能来执行G. 假设我们现在有3个go线程(M)并行在CPU的3个核上, 每个M绑定了一个P, 运行一个G, 那么实际上就是有3个gr并行, 把P的数量提升到4呢?
4P --绑定--> 4M --就会有--> 4G并行. 因此我们可以发现真正决定并行度(不是并发,是并行)的, 是P的数量, 一个Go程序开始运行的时候, 具体会有多少个调度器(P), 取决于你设置的GOMAXPROCS(), 把上面这句话换个说法, 你可以认为说: 在任意时间点下, 只有GOMAXPROCS()个gr在同时运行着.
简单说说一个调度的过程
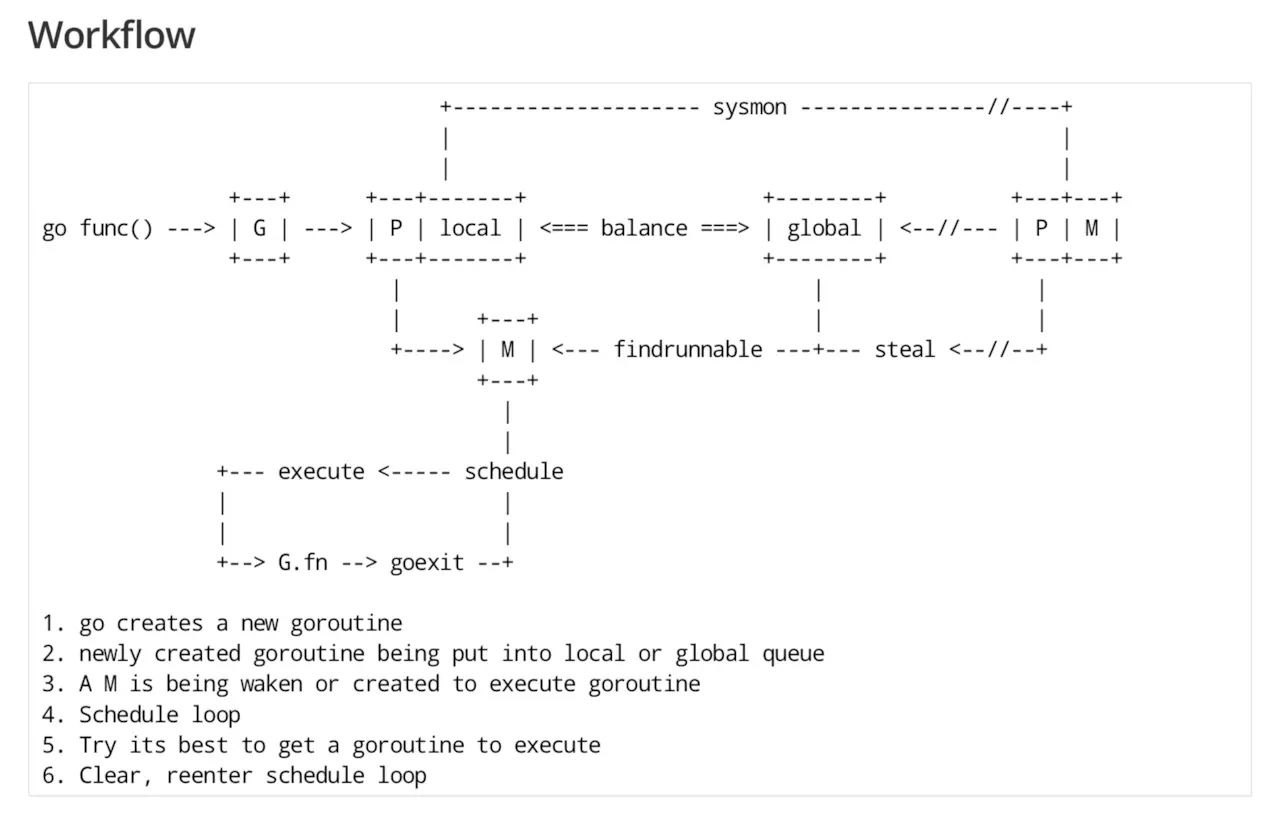
某个线程尝试创建一个新的gr, 这个新G会被安排到这个线程下的G队列中, 如果满了就或者全局G队列中
需要一个M来执行这个G, 首先尝试获得当前线程的M, 如果无法获取, 就从全局空闲的M列表中找一个M, 如果还是没有, 就新建一个M 然后绑定P与G运行. (M是按需分配的,但是也会有上限值)<对应后文的G创建过程>
进入调度循环, 我们所谓的调度过程就是发生在这里的 <对应调度逻辑>
找出一个合适的G
执行G, 执行完成以后goexit
再尝试找一个G
详细说说G的创建过程
从这里开始我们会尝试附带上一些代码, 以及一些从代码里整理出来的, 较为详细的流程总结. 在程序中写出go func()就能产生一个gr并发, 这并不是魔法, 分析一下gr的诞生: proc.go#newproc
newproc()
下面这张图是Go语言的执行函数时的堆栈图, 用于说明go func创建的过程中, 我们函数的定义在哪儿, 传递来的参数在哪儿, 会被怎么执行下去
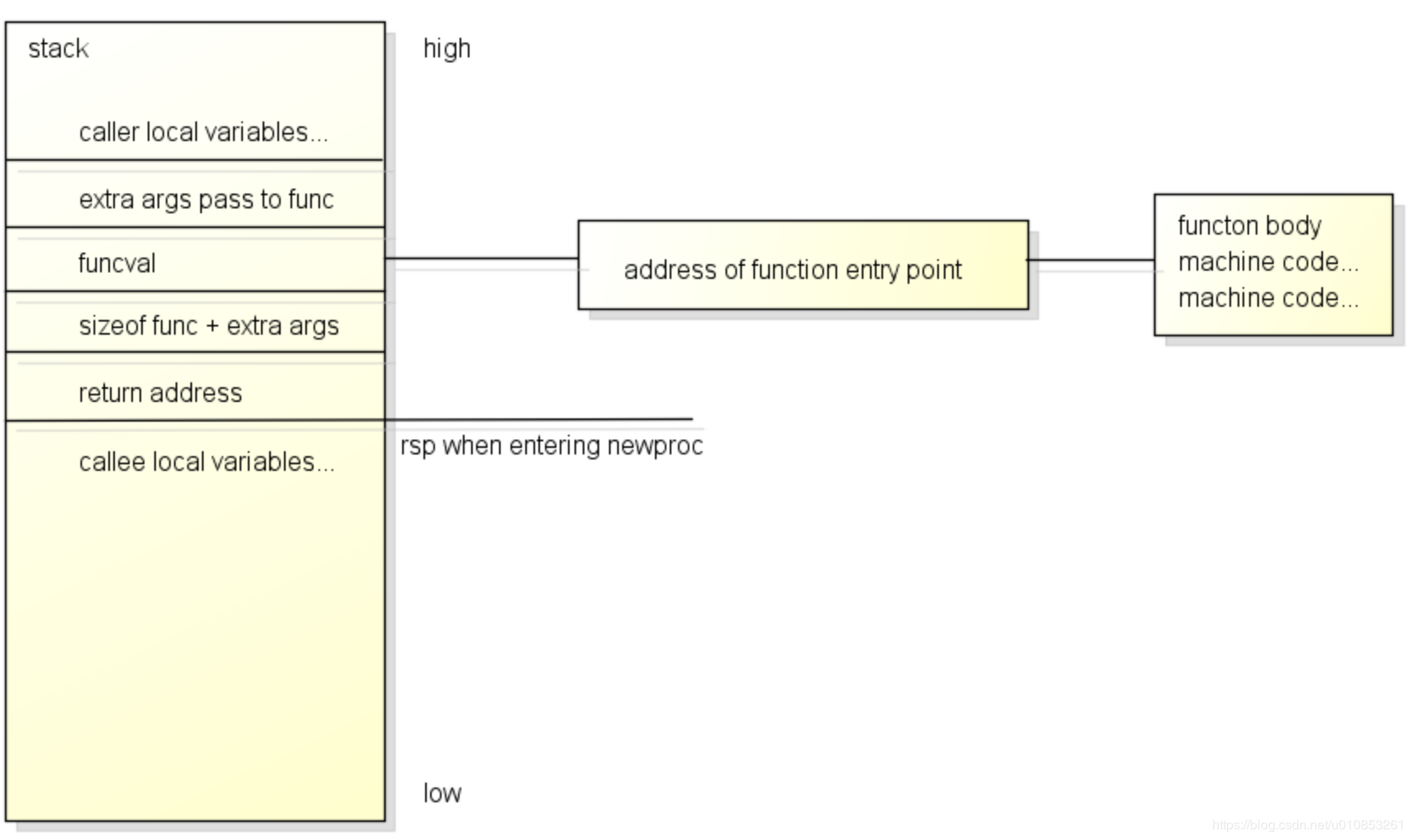
从这里开始我们尝试将你写的go func翻译成G, 本函数算是一个表层函数, 只做三件事:
尝试拿到参数的位置:
func是一个参数, 对应上图的funcval, 一个函数指针, 在图上我们同样能看到funcval有一根线牵出去, 我们需要跳到这个函数定义区, 去执行函数代码
在func指针上方是它的实际参数指针argp(argument passed), func指针加上一个指针的大小得到这个argp的位置
尝试获得pc(programme counter): 这个位置代表函数执行完成以后跳回来的位置
调用函数systemstack, 这个函数负责在上执行一个任务,随后返回
在这儿我们要它执行的任务, 也就是newproc的里函数newproc1
疑惑,为什么要这样, 为什么到多出这个逻辑, 切换到g0上执行并使用g0的栈, 因为调度, 创建G本身就是g0的职责范围
newproc1
newproc1是真正负责初始化G的, 其主要的工作流程包含:
获得g0:getg, g是用于获得当前g的, 既然我们已经切换到g0,这里返回g0
上锁: 下文中会引用到p, 为了避免p被双线操作, 这里必须上锁
检查函数本体是否为空, 空则直接panic(实际上在runtime里面我们不用panic关键字, 我们用
panic.go#throw函数)获取g0对应的p,并在当前p下获得一个空闲的g,或者说状态=GDEAD: gfget, 在尝试获得g的过程中可能会出现三种情况.
情况-1: p内有空闲G
情况-2: p内没有空闲G,但是本地/全局Glist内有: 从全局调度器内偷出32个, 赋给p
情况-3: 都没有, 这种情况下会通过malg()创建一个新G, 默认大小2K
将参数复制到G的栈上
将返回地址复制到G的栈上, 程序中是
funcPC(goexit)等于说, 在G执行完成以后自动执行goexit将G状态从之前的GDEAD更新成RUNABLE
将G推入p的G队列中: runqput, 我们把这个G设置为下个就执行的, 接下来我们尝试把G推到P的G的队列中, 如果G的队列已经满了, 就尝试放到全局G队列中, 值得注意的是推到全局队列这件事, 需要加锁, 因此可能会比较慢
现在G的生成使命已经完成了, 现在是最后一步, 我们需要确保会有足够多的m能来运行G, 逻辑是这样的:
如果当前情况下有空闲的P, 但是自旋中的M却为零, 也就说发现了现在有P是没有M的, 这个P上的任务是无法执行的, 这种情况下, 我们需要唤醒或者新建一个M来 - wakep()
通过pidleget获得一个空闲的P
通过mget获得一个空闲的M
如果没有空闲的M, 则通过newm创建一个M
详细说说M的创建
type m struct {
g0 *g
mstartfn func()
curg *g
p puintptr
nextp puintptr
helpgc int32
spinning bool
alllink *m
lockedg guintptr
}以上是简略版的m定义, 以上各个字段的定义分别是:
g0: 每一个m在创建的时候都会连带生成一个g0,本质上也是一个gr, 只是与别的gr不同的是普通gr使用的是Heap分配的栈, 而这个gr则是使用的是M的栈, 除了栈不同以外, g0的工作可以被认为是"辅助调度小助手", 在M空闲的情况下, M一直是在g0上工作的, 等有gr了, g0负责恢复这个G的上下文, 等上下文切换完毕以后切换到这个G上工作
mstartfn: 表示M需要执行的函数, 也就是go关键字后面跟着的函数
curg: 存放着现在正在执行的g
p: 指向与当前M所绑定的P
netxp: 一个潜在可能的, 用于绑定的p
helpgc: 一个标志位, 说明这个线程是不是用于辅助gc的线程
spinning: 一个标志位, 如果是true, 就说明m正在寻找p中...
alllink: 一个连接, allm代表一个承载了所有m的列表, 这就是指向这个列表的链接
lockedg: 一个m在运行时会与一个g绑定在一起,这里指的就是绑定的这个g
详细说说P
P是一个抽象出的概念, 我们在之前也解释过为什么P也只是"逻辑CPU", P并不代表CPU的数量, 只是真正能决定并发度的是P . 现在看来, 它包装了G在运行时所需要的资源, 因此造成了"G的眼中只有P"这种情况的发生.
P的初始化
在程序开始之前, 也就是runtime初始化的时候, 我们需要去读取P的数量, 如果存在GOMAXPROCS就设置为这个值, 如果不存在就设置为默认值, 拿到这个数值以后就创建一个全局P列表, 也就是runtime.allp, 这里面包含了所有创建出的P, 随后runtime将调度器中(也就是runtime.schedt.runq)中所有需要运行的G,均匀的分布到P的本地G队列中, 到这里为止, 所有要用到的P都已经准备就绪了.
大家都是调度器???
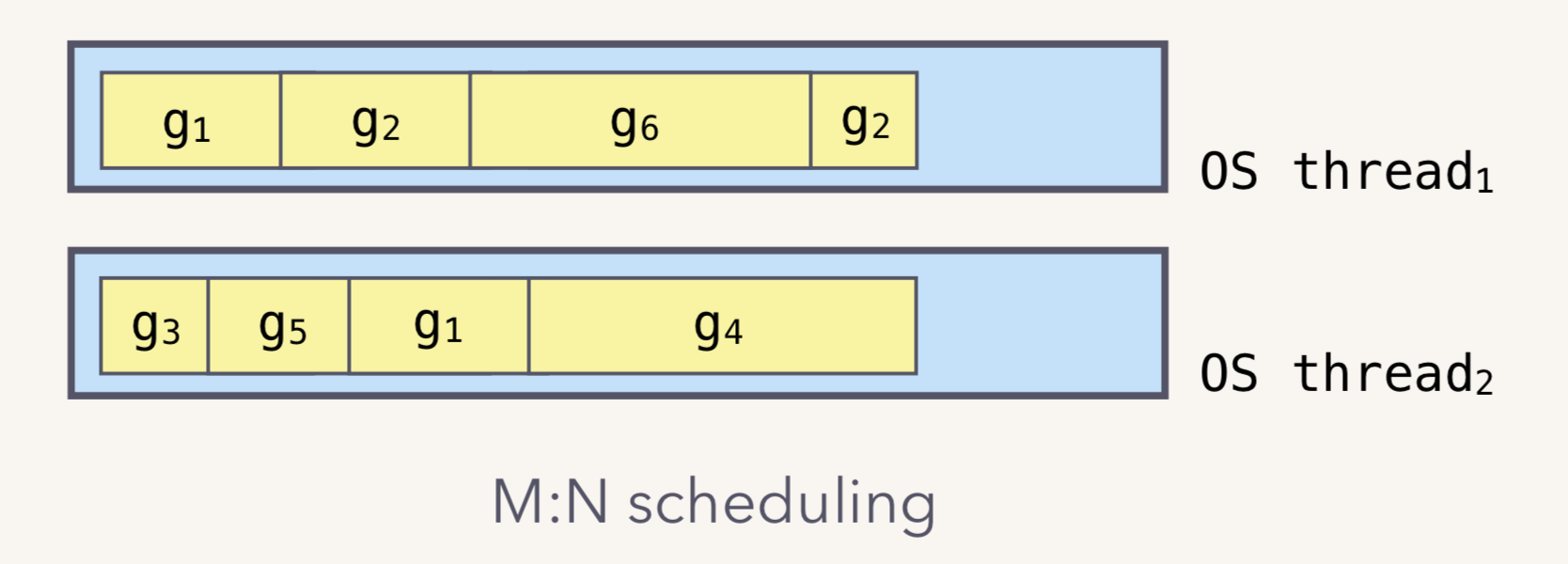
截止目前我们提到了两种调度器, 我们说schedt也是调度器, 同时P我们也说是调度器, 他们有什么区别?
局部调度P:上图中灰色框代表一个M, M中包裹着蓝色的P, P决定了此时把那个G推给M做, 换句话说P只能决定自己队列中下一个接受调度的是谁. 别的队列管不到
全局调度schedt: runtime全局调度时使用的数据结构, 里面主要有M的全局idle队列,P的全局idle队列,一个全局的就绪的G队列以及一个runtime全局调度器级别的锁。我们在搞全局调度的时候, 比如决定这个P现在空闲, 现在与M解绑, 这个过程是基于全局调度的.
为什么需要这个"P" - 及时解绑PM
为什么需要这个"逻辑Processor", 为什么要在中间加上这一层? 回答这个问题我们就回到了Go1.1, 那个时候叫GM模型, 没有P这一层, 结果出现很多问题, 其中最大的问题来自: "假设现在gr需要做系统调用, 阻塞会导致后面的G无法被执行"
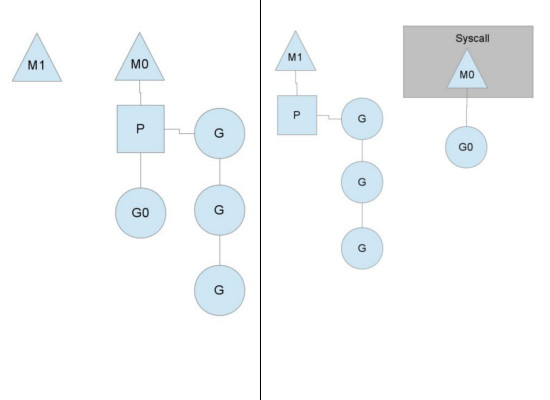 如上图, 在有了P以后, 我们能做到在一个G因为系统调用产生阻塞的时候,能做到解绑PM, 并将剩余的G+P转移到另一个M上继续执行. 而上图中的M1既可能是新创建的, 同时也可能是从线程缓存中取出来的. 在M0返回时, 它会尝试从别的线程哪里偷一个P过来, 如果没偷到, 那么这个G则会进入全局G队列. 什么是"偷"? 进入下一个问题, stealing work
如上图, 在有了P以后, 我们能做到在一个G因为系统调用产生阻塞的时候,能做到解绑PM, 并将剩余的G+P转移到另一个M上继续执行. 而上图中的M1既可能是新创建的, 同时也可能是从线程缓存中取出来的. 在M0返回时, 它会尝试从别的线程哪里偷一个P过来, 如果没偷到, 那么这个G则会进入全局G队列. 什么是"偷"? 进入下一个问题, stealing work
Syscall中, 在调度器在解绑后我们的选择立刻找到M1继续绑定. 也有的情况下, 如果P不在与任何M相关联了, Golang会在合适的时间点下断开P&M, 然后另寻其主的切换M, 使得P中的G能够在合适的时间点下更好的运行. 就会被直接投入调度器的空闲队列中, runtime.shcedt.pidle, 等待后续需要的时候再投入使用.
P的Stealing work机制
你可能会好奇, 上面的这个全局G队列是什么? 我们在之前只提到过每个P会有一个自己的G队列, 顾名思义, P会有一个自己的"本地"G队列, 同时这么多个P之间还会有一个全局G队列.
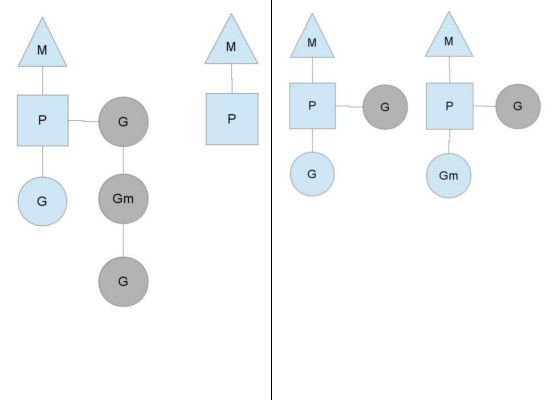
在左图中, 左边的M还有好几个任务要做, 而右边的M已经没活干了. 为了把CPU充分利用起来,右边的M会想办法找点活做. 首先它会去全局gr队列拿一些任务来做. 但如果全局队列也没什么gr, 这时候它会去别的M哪里偷一点任务过来, 通常是偷一半
P的状态流转图
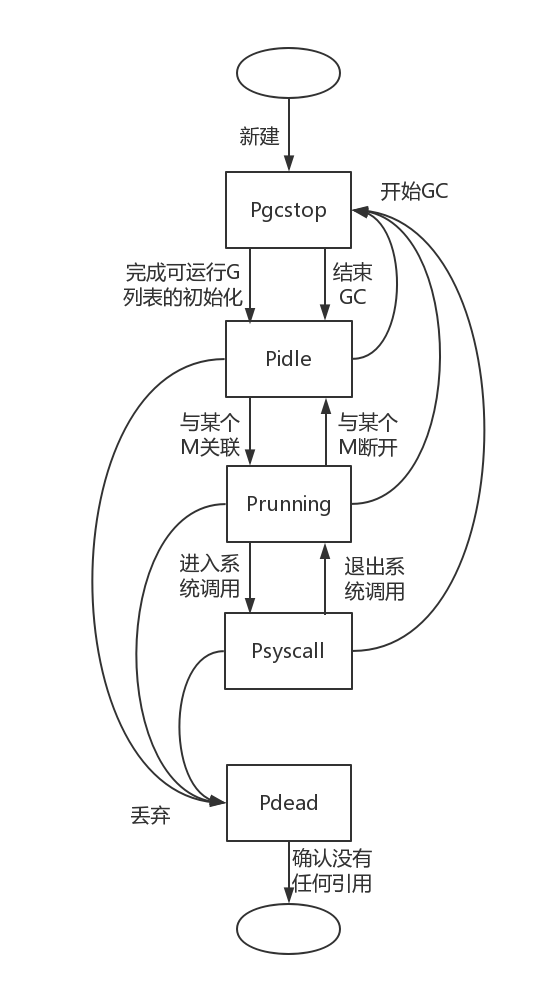
与M的无状态不同的是, P是存在状态的, 在P生成了, 但是还没填充P时, 它的状态Pgcstop状态, 尽管维持的时间很短. 随后在P填充完毕, P变成Pidle状态, 并加入调度器的空闲P列表runtime.schedt.pidle中
在图中可以看到, 只要P不是dead状态, 那么无论任何状态, 在GC开始的时候都会被调整为Pgcstop, 在GC结束以后又统一都变成了pidle. 因此pidle并不是真的闲下来了, 甚至可能P里面还有别的G的情况下, 就直接idle
循环调度
我们花了非常大的精力用于说明我们的调度模型下有哪些组件, 他们具备什么样的功能, 有哪些状态. 我们也曾经简单介绍了循环调度做了什么, 最后一定会回到一个问题: 是谁负责调用他们的? 或者说, 他们的状态是谁改变的? 工作流是什么样的, 这些内容都需要在大脑里有一个浮想.
什么时候会执行调度逻辑
函数mstart用于创建一个M, 其处理流程的最后一步是调度函数schedule, 其作用是开始调度, 简单来说mstart的处理流程是下面这样的:
调用函数getg拿到g0
尝试使用系统栈,随后开始mstart1
调用gosave函数保存当前状态到g0的调度数据中
调用minit函数, 设置当前线程可以接收的信号
调用schedule函数
Schedule的执行过程
这儿就是调度核心, 执行的过程是这样的, 这其中一些步骤被省略了, 例如对于GC状态的检查, 以及安全点函数runSafePointFn, 这些我认为不重要, 我们需要快速了解流程
获取g0, 因为是g0执行的调度逻辑
想要获得一个G:
A:尝试快速获得一个G, 按照顺序依次去尝试:
如果在GC阶段, 尝试寻找GC Worker, 因为GCW也是一个G
为了公平, 每61次尝试从全局G队列中获得一个G
尝试从P的本地G队列中获取一个G, 调用
runqget函数
B:以上步骤没有成功的话, 就依次继续下面的步骤, 这次尝试会一直阻塞到成功获得G为止
从P的本地运行队列中获取G, 调用runqget函数,如果获取到就返回
从全局运行队列获取G, 调用globrunqget函数, 需要上锁,获取到就返回
从网络事件反应器获取G, 函数netpoll会获取哪些fd可读可写或已关闭, 然后返回等待fd相关事件的G
尝试一下WorkStealing: 调用runqsteal尝试从其他P的本地运行队列盗取一半的G
如果都走到这一步依旧无法获得G, 则M需要进入休眠状态, 主要包含:
释放P, P本身状态修改成_Pidle
将P放入全局空闲P列表schedt.pidle中
令M离开自旋状态,代表M不再尝试寻找G
减少表示当前自旋中的M的数量的全局变量nmspinning
休眠
休眠唤醒以后, 重新执行事件B
找到G了, execute函数开始执行G
获取当前g0, 因为执行函数需要恢复上下文栈, 这些都是要在g0中完成的
将G的状态从_Grunnable调整为_Grunning
设置G的stackguard, 栈空间不足时可以扩张
自增P的调度次数, 对应上面说的61次调度执行全局队列一次
令 g.m.curg = g, gp.m = g0.m
调用gogo函数, 这个函数能在M上执行G, 主要做的事情包含恢复上下文, 寄存器中的值, 随后开始运行
假设一个G现在任务已经完成了, 调用goexit执行退出步骤,包含:
将G的状态从GRunning更新成_Gdead
调用dropg函数解除M和G之间的关联
调用gfput函数把G放到P的自由列表中, 下次创建G时可以复用
调用schedule函数继续调度
疑问, 什么时候可以重新执行schedule逻辑? 只有M新创建的时候+G执行成功的时候吗 ? 不是的, 我们还有抢占调度, 抢占调度也决定了schedule什么时候运行. 初次之外network, syscall 等都会导致schedule的重新执行.
触发调度-抢占调度
Go语言支持抢占式调度策略, 设想一种情况, 假设一个g长时间占用CPU, 这种情况下我们会怎么做? 简单来说, 只要这个g一旦尝试函数调用, 立刻开始调度, 但是, 如果一个g就是占用, 并且也不调用函数, 在这种情况下就没办法了
runtime在开始运行的时候, 会创建一个监视线程sysmon(), 这个函数会在程序的生命周期中一直运行, 负责监视各个gr的运行状态, sysmon会调用retake函数, retake负责遍历所有的P, 如果出现一个P处于运行状态, 且执行一个G时间超过10ms, 就准备开始执行抢占:
retake()调用preemptone()将P的stackguard0设为stackPreempt,这将导致该P中正在执行的G进行下一次函数调用时, 导致栈空间检查失败,进而触发morestack(),在goschedImpl()函数中,会通过调用dropg()将G与M解除绑定;再调用globrunqput()将G加入全局runnable队列中;最后调用schedule() 来用为当前P设置新的可执行的G。
其他触发调度的情况
channel阻塞/networkIO: 如果G被阻塞在chan上, 或某次networkIO上, 这个G会被放到waitting队列中, 而M尝试运行下一个就绪的G, 如果没有了, M解绑P, 进入sleep状态. 一旦这个G工作完成了, 就会将自己的状态更新成runnable, 放到某个P的队列中等待执行
Syscall: Syscall造成的阻塞, 与上面不同, 在这里一旦遇到Sys阻塞, 直接造成M&P解绑, 这个M会与这个P一起进入sleep状态, 留下P带着剩下的G会想办法找个M继续执行. 如果有空闲的M就绑定这个M, 如果没有, 则尝试创建一个新M来执行, 跟我们上面介绍的GM模型时一样, 在G的系统调用返回时找一个P绑定或者G进入全局队列
