前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现,跳表在Redis、LevelDB、ES中都有应用,本文以Redis为工程蓝本,分析跳表在Redis中的工程实现。
通过本文你将了解到以下内容:
前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现,跳表在Redis、LevelDB、ES中都有应用,本文以Redis为工程蓝本,分析跳表在Redis中的工程实现。
通过本文你将了解到以下内容:
-
Redis基本的数据类型和底层数据结构
-
Redis的有序集合的实现方法
-
Redis的跳表实现细节
1.Redis的数据结构
Redis对外共有约五种类型的对象:-
字符串(String)
-
列表(List)
-
哈希(Hash)
-
集合(Set)
-
有序集合(SortedSet)
/* The actual Redis Object */#define OBJ_STRING 0 /* String object. */#define OBJ_LIST 1 /* List object. */#define OBJ_SET 2 /* Set object. */#define OBJ_ZSET 3 /* Sorted set object. */#define OBJ_HASH 4 /* Hash object. */typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; int refcount; void *ptr;} robj;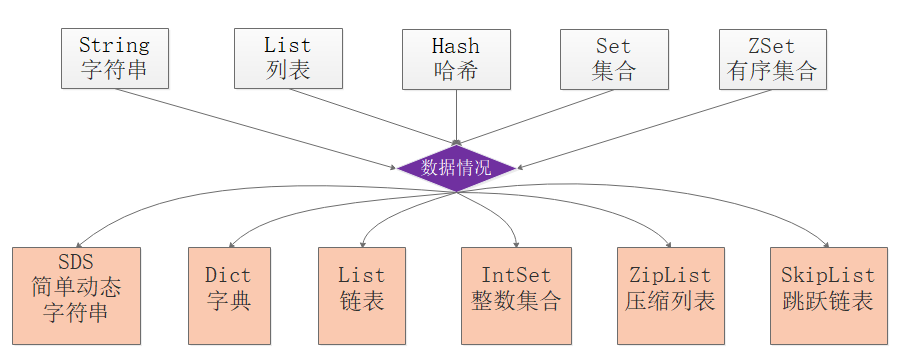
2.Redis的ZSet
ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存。typedef struct zset { dict *dict; zskiplist *zsl;} zset;ZSet中的字典和跳表布局:
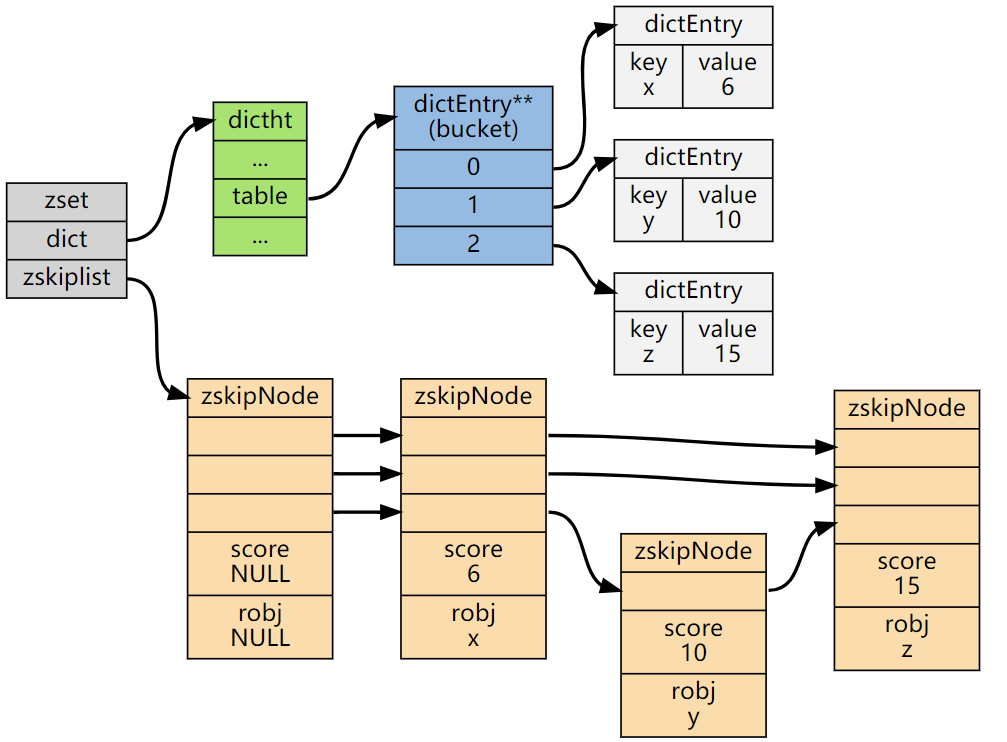
注:图片源自网络
3.ZSet中跳表的实现细节
-
随机层数的实现原理
-
指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
-
生成一个0~1的随机数r,若r<p,且lvl<MaxLevel ,则lvl ++
-
重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
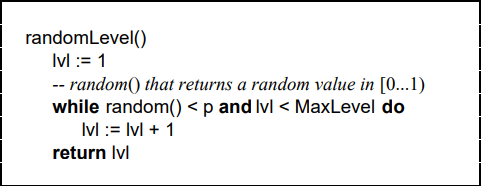
/* Returns a random level for the new skiplist node we are going to create. * The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL * (both inclusive), with a powerlaw-alike distribution where higher * levels are less likely to be returned. */int zslRandomLevel(void) { int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */(random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF) 最开始的猜测是random()返回的是浮点数[0-1],于是乎在线找了个浮点数转二进制的工具,输入0.25看了下结果:
最开始的猜测是random()返回的是浮点数[0-1],于是乎在线找了个浮点数转二进制的工具,输入0.25看了下结果:
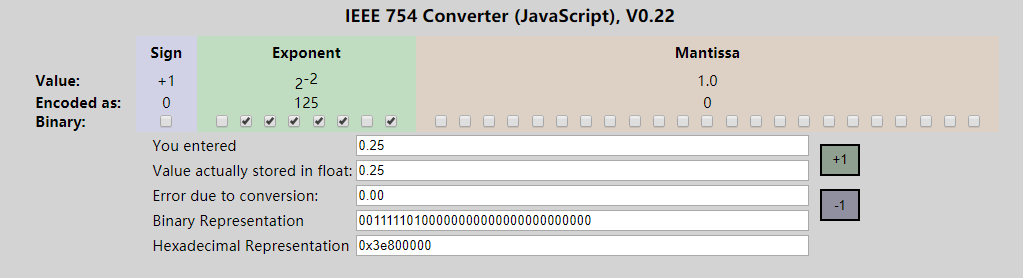
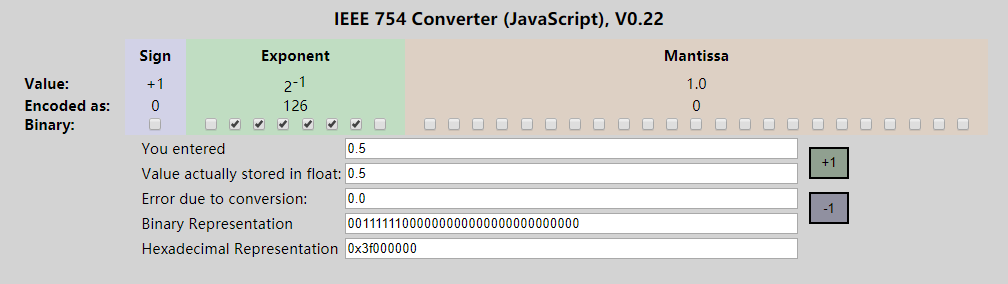
-
random()在dict.c中的使用:
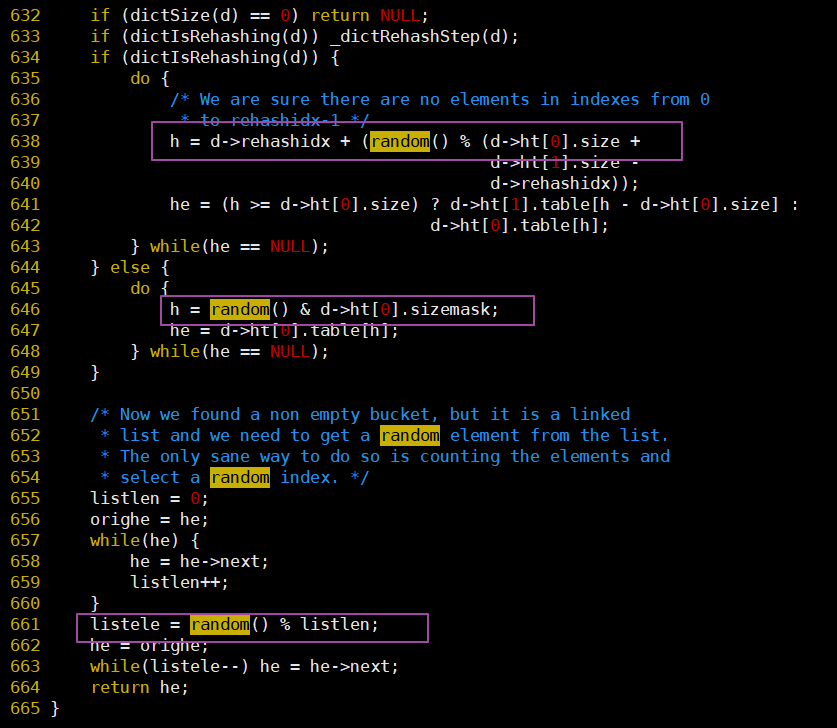
-
random()在cluster.c中的使用:
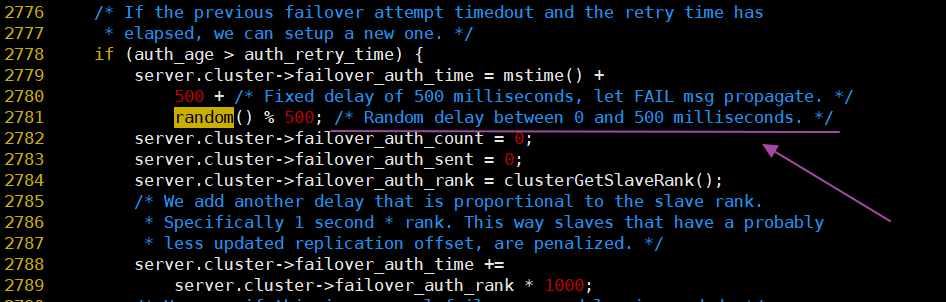
ZSKIPLIST_P*0xFFFFtemplate <typename Key, typename Value>int SkipList<Key, Value>::randomLevel() { static const unsigned int kBranching = 4; int height = 1; while (height < kMaxLevel && ((::Next(rnd_) % kBranching) == 0)) { height++; } assert(height > 0); assert(height <= kMaxLevel); return height;}uint32_t Next( uint32_t& seed) { seed = seed & 0x7fffffffu; if (seed == 0 || seed == 2147483647L) { seed = 1; } static const uint32_t M = 2147483647L; static const uint64_t A = 16807; uint64_t product = seed * A; seed = static_cast<uint32_t>((product >> 31) + (product & M)); if (seed > M) { seed -= M; } return seed;}-
跳表结点的平均层数
如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。
幂次定律
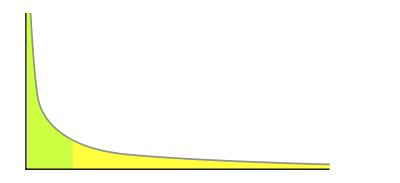
-
节点层数至少为1,大于1的节点层数满足一个概率分布。
-
节点层数恰好等于1的概率为p^0(1-p)。
-
节点层数恰好等于2的概率为p^1(1-p)。
-
节点层数恰好等于3的概率为p^2(1-p)。
-
节点层数恰好等于4的概率为p^3(1-p)。
-
依次递推节点层数恰好等于K的概率为p^(k-1)(1-p)
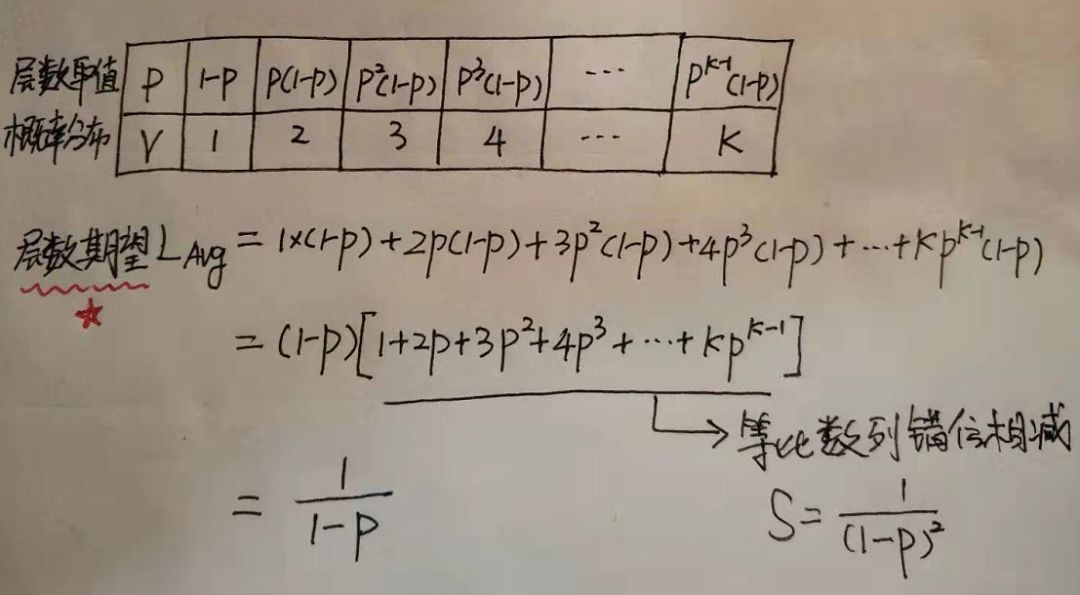
4.参考资料

-
http://note.huangz.me/algorithm/arithmetic/power-law.html
-
https://juejin.cn/post/6844903826097455117
-
https://epaperpress.com/sortsearch/download/skiplist.pdf
-
https://www.h-schmidt.net/FloatConverter/IEEE754.html
-
http://www.ruanyifeng.com/blog/2010/06/ieee_floating-point_representation.html
-
https://cyningsun.github.io/06-18-2018/skiplist.html
5.推荐阅读
白话布隆过滤器BloomFilter 理解缓存系统的三个问题 几种高性能网络模型 二叉树及其四大遍历 理解Redis单线程运行模式 Linux中各种锁及其基本原理 理解Redis持久化 深入理解IO复用之epoll 深入理解跳跃链表[一] 理解堆和堆排序 理解堆和优先队列
6.关于本公众号
开号不久作者力争持续输出原创干货,如果文章有帮助到你,希望朋友们多多转发和分享,作者会更加有动力,推出更好的文章,共同进步。