

URL去重算法
基于改进爬虫技术的 SQL 注入的自动化扫描工具的研究与设计论文中提到的下面的算法:
1.hash算法
- 优点:这种算法去重的精确度比较高,漏报率比较少,可以达到比较好的去重的效 果,在一定程度上避免获取重复的URL。
- 缺点:用hash表存储URL的去重算法是将整个URL进行哈希,之后映射到物理 地址上,一个URL就会占一个相对比较大的空间,随着URL数量的增加,需要 的存储空间也会越来越多。
2.基于MD5的压缩URL去重算法
- 优点:MD5算法是将URL输出压缩成128位的整数,通过hash函数映射物理地址,从而形成键值对。它与基于hash的存储算法的区别就是存储URL使用的空间消耗减少了,因为一个完整的URL肯定要比压缩后的URL占用的空间大。
- 缺点:由于算法是以URL-地址为键值对来存储的,因此在数据量比较大的情况下会出现内存溢出的情况,造成空间和时间上的浪费。而且URL和映射的MD5值不是一一对应的,可能会出现共用MD5值的情况,这种情况下,另一个URL就不会再被访问。
3.爬虫算法-Bloom Filter
- 详细介绍1:www.jouypub.com/2018/0038d9…
- 详细介绍2:www.jianshu.com/p/8193d7dc8…
- 定义:布隆过滤器(BloomFilter)是一种数据结构。它是在前两种算法的基础上提出的一种改进算法。布隆过滤器是由若千hash函数和一个定量长度的0、1组合的向量构成的。相对于前两种算法,布隆过滤器在一定程度上节省了空间,提高了利用率。
- 原理:一个布隆过滤器一般是由m个互相独立的hash函数hl,h2,...hm(取值范围为[0,1,...,k]的整数)和一个位向量组成。位向量的初始值全为0。在插入新的数据时,用m个hash函数来对n个数据的集合计算出地址序列,地址序列长度为K,然后将相对应的位向量置为1,这就代表将数据存入。要判断数据是否重复的时候就检查新输入数据的位向量构成的地址序列与集合中已经存在的数据的值是否相同,若相同则该数据对象属于该由0和1组成的组合集,反之则不属于。
- 算法目前存在的缺点:a)由于布隆过滤器是利用多个hash计算将地址序列某几个位置为1来存储URL,在对多个URL进行存储之后,可能会出现某些URL的映射的地址序列的对应位置己经变为1,这样系统就会判断URL已经存在,但是实际上,该URL还未被爬取过,这样就会造成误判。b)由于多个URL共享地址序列,在根据hash函数来判断是否将相对位置置为1,这样地址序列是一个二进制序列。那么,在URL出现失效的情况下也不能删除无效的URL,因为若是将此URL对应的地址序列的对应位置删除,那么就有可能影响到其他的URL的判断,从而造成错误。
- 对算法对改进:
(1)对URL进行预处理 本文改进的SVCBF算法在布隆过滤器算法的基础上去重的准确度更高。基本的布隆过滤器是直接对URL进行hash的位映射,这样由于URL的长度的不同会造成误判。本文改进的算法对URL进行了预处理,压缩URL保证同样长度URL的输出,减少映射的出错率。 (2)可变长度的计数 在对映射URL的位向量采用可变长度的计数,使得映射的URL的保存位置具有更多地灵活性。和前人相比,采用可变长度的计数有以下优点:第一,可以对URL进行删除和更新;第二,计数长度的可变减少了计数位置为0时产生的不必要的消耗。 - 论文的不足点:
第一,本文增加了爬虫模块的设计,对爬虫增加了设置代理伪装的部分,通过设置User-Agent模仿正常的用户访问在一定程度上可以绕过网站的反爬虫机制,但是,网站的反爬虫种类不止一种,本文还需要补充一些网站对反爬虫机制的应对方法,提高爬虫爬取的准确性。
第二,Web应用防火墙(WAF)的种类特别多,使用WAF的网站也越来越多,随着技术的提高,为了防止网站受到攻击,防火墙的技术也在不断地发展,要想减少检测的误报率,就需要研宄更多的Web应用防火墙的识别和绕过技术。
第三,本文只是针对SQL注入攻击进行了检测,在实际情况中,网站不止存在一种漏洞,要想全面检测网站的安全性,就需要对其他类型的漏洞,比如OWASP提出的TOP10漏洞进行研宄分析,分析它们的漏洞原理检测方法,这样才能全面的检测一个网站的安全性。
Fast Hash Table Lookup Using Extended Bloom Filter: An Aid to Network Processing:
1.hash算法 (MD5 或 SHA-1)
1)哈希表查找涉及哈希计算,然后是内存访问。虽然通过使用 MD5 或 SHA-1 等复杂的加密哈希函数可以适度减少冲突导致的内存访问,但这些函数很难快速计算。在高速分组处理设备的环境中,即使使用专用硬件,这种散列函数也可能需要几个时钟周期来产生输出。例如,散列核心的一些现有硬件实现消耗 超过 64 个时钟周期,这超过了最小分组时间的预算。此外,这种散列函数的性能并不比假设均匀随 机散列的理论性能好。
2)计数布隆过滤器通过用计数器替换过滤器中的每一位来扩展简单的二进制布隆过滤器。这使得有可 能对布隆过滤器表示的集合执行删除操作。
博客
- bloom filter算法优化:
1.blog.csdn.net/qq_12902597…
2.oserror.com/backend/blo…
3.Scrapy爬虫去重效率优化之Bloom Filter的算法的对接:cloud.tencent.com/developer/a…
基于Scrapy框架的分布式爬虫系统设计与实现
- 1.文章主要工作:
(1)针对传统的内存去重策略,实现了基于 Redis 的布隆过滤器去重方法, 将 URL 字符串表示成二进制向量,降低了字符串数据的空间占用率并且提高去 除重复数据的效率,同时在多节点的情况下仍可以保证良好的去重效果。
(2)针对异步加载的动态页面采用了模拟浏览器的加载方式,保证在多数 情况下能够完整加载动态网页并获取网页的内容。
(3)对Scrapy的框架的调度器,数据管道以及下载器等组件进行定制开发, 使系统在分布式环境下完成数据地抓取和存储任务。
(4)对抓取数据进行统计和分析。本文首先结合 Elasticsearch 将爬虫获取 到的数据进行实时搜索,其次根据主题词统计结果生成词云分布图进行展示,最 后提出数据质量优劣的评价指标并使用层次分析法确定评价准则的权重进行计 算,得出数据评价结果。 -
- Scrapy 框架:主要组件包括框架引擎(Scrapy Engine)、调度中心 (Scheduler)、下载器(Downloader)、爬虫(Spiders)、数据管道(Item Pipeline)、下载中间件(Downloader Middlewares)、爬虫中间件(Spider Middlewares)七个部分。本文在 Scrapy 框架基础上对于关键接口进行重写,完全能够实现一个高效 的爬虫系统。
- 3.分布式爬虫系统的理论基础:分布式系统是由一组通过网络进行通信的计算机组成的系统,其目的是为了共同的计算任务而协调工作。分布式爬虫可以整合多个计算机节点的性能去执行爬虫任务并能够获取、存储和处理更大量级的数据。分布式爬虫相对于单节点的爬虫,其处理性能与可扩展性更加强大。
- 4.Scrapy-Redis 框架:Scrapy-Redis 是结合 Scrapy 框架和 Redis 数据库的分布式网络抓取的程序,其分布式主要体现在使用 Redis 数据 库实现多个 Spider 共享抓取的链接,利用原生 Redis 的集合实现 URL 去重,并 且在 Redis 还存储了大量关于爬虫节点的状态信息。
- 5.总结与展望:本文首先提出爬虫技术对于快速获取数据的重要性,考虑到编写爬虫过程 中的系统的复杂性以及通用性,得出实现一个可定制的通用性爬虫工具的必然 性。通过对爬虫热点技术的学习、国内外现状的调研以及对 Scrapy 框架的深度 剖析,设计并实现了一套灵活的分布式网络爬虫系统,并针对目标网站进行内 容的抓取。本系统采用分布式结构是主从式架构,底层采用 Redis 数据库集群 的方案来过滤爬虫中重复的 URL 链接,同时也增强了系统的扩展性。
网页学习
1.Bloom filter的概念及原理
1)算法的核心思想:利用多个不同的Hash函数来解决“冲突”。
2)缺点:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。
3)适用场景:黑名单、爬虫重复URL检测、字典纠缠、磁盘文件检测、CDN(squid)代理缓存技术。
详细介绍见:ifengkou.github.io/bloomfilter…
4)误判率p,位数组m,以及k的确定方法:www.jetchen.cn/bloom-filte…
自己总结Bloom filter:
- 概念:布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
- n:参与去重的元素个数;
- m:m位的Bitset(位数组);
- k:hash函数的个数;
- 当k=
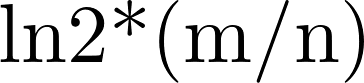 时,出错率最低,错误率为(1/2)^k=(0.6189)^m/n;
时,出错率最低,错误率为(1/2)^k=(0.6189)^m/n; - 根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
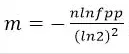
- m≥
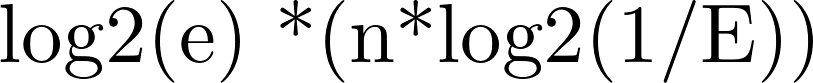 ,其中E为最大错误率;
,其中E为最大错误率; - 我们假设 P 为 0.01,此时最优的 m 应大概是 n 的 13 倍,而 k,应大概为 8。要使错误率不超过E,m至少需要取到最小值的1.44倍。
- 空间复杂度:100万个URL时,假设要求误判率为1%,因此该公式可转化为m=9.6∗n
- 时间复杂度:BloomFilter的时间复杂度仅与Hash函数的个数k有关,即O(k)
simhash算法
算法原理及概念
- 1.涞源:simhash是locality sensitive hash(局部敏感哈希)的一种,最早由Moses Charikar在《similarity estimation techniques from rounding algorithms》一文中提出。按照Charikar在论文中阐述的,64位simhash,海明距离在3以内的文本都可以认为是近重复文本。
- 2.海量数据去重之SimHash算法简介和应用:blog.csdn.net/u010454030/…
LSH之simHash算法:yq.aliyun.com/articles/28…
优点:传统的加密式hash,比如md5,其设计的目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。我们理想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能直接反映输入内容的相似程度。很明显,前面所说的md5等传统hash无法满足我们的需求。 - 3.用simhash算法做url去重
1)先泛化url再使用simhash算法去重:docs.ioin.in/writeup/www…
2)完整代码地址: jerrychan807.github.io/2019/08/26/…
2)写论文时可用: dawnnnnnn.com/2019/04/Url…
