

此文为学习何晗老师《自然语言处理入门》笔记
中文分词算法大致分为基于词典规则与基于机器学习这两大派别。
词典分词是最简单、最常见的分词算法,仅需一部词典和一套查词的规则即可。
基于词典分词的缺点:词典中的字符串就是词,词典之外的字符串就不是词了。 事实上,语言中的词汇量是无穷的,无法用任何词典完整收录。而语言也是时时刻刻的发展变化的,任何词典都只是某个时间点的快照。
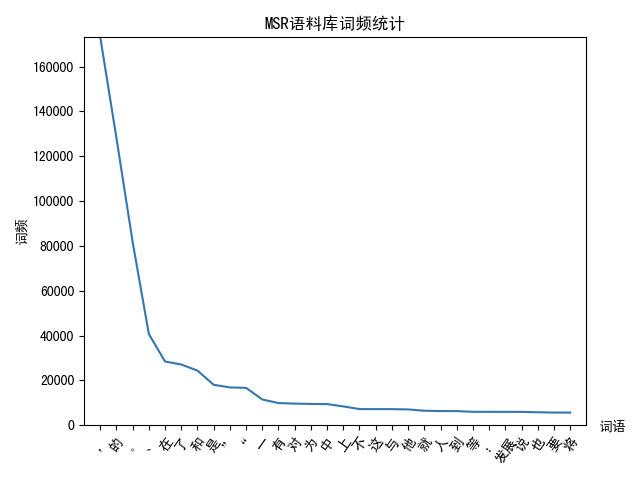
词的性质 - 齐夫定律
一个单词的词频与它的词频排名成反比。
HanLP词典
| 词 | 词性 | 数量 | 词性 | 数量 | ... |
|---|---|---|---|---|---|
| 希望 | v | 386 | n | 96 | |
| 希罕 | a | 1 | |||
| 希腊 | na | 19 | |||
| 希腊共和国 | ns | 1 |
上面的第一行表示 “希望” 这个词以动词(v)身份出现了386次,名词(n)出现了96次。词频是基于某个语料库上统计的。在词典分词中,词性和词频没有用处。
切分算法
完全切分
完全切分指的是找出一段文本中的所有单词。这并不是标准意义上的分词。
计算过程:遍历文本中的连续序列,查询该序列是否在词典中。
def full_segment(text, dic):
'''
:param text: 字符串
:param dic: 词典
'''
word_list = []
for i in range(len(text)):
for j in range(i + 1, len(text) + 1):
word = text[i, j]
# 查询词典
if word in dic:
word_list.append(word)
return word_list
时间复杂度
正向最长匹配
考虑到越长的单词表达的意义越丰富,则可以定义单词越长优先级越高。
最长匹配计算方法:以某个下标为起点递增查询的过程中,优先输出更长的单词
def forward_segment(text, dic):
'''
:param text: 字符串
:param dic: 词典
'''
word_list = []
i = 0
while i < len(text):
longest_word = text[i]
# 遍历所有可能的结尾
for j in range(i + 1, len(text) + 1):
word = text[i:j]
# 查询词典
if word in dic:
longest_word = word
# 得到最长单词
word_list.append(longest_word)
# 跳到下一个起点
i += len(longest_word)
return word_list
逆向最长匹配
逆向最长匹配即为从后往前的扫描
def backward_segment(text, dic):
'''
:param text: 字符串
:param dic: 词典
'''
word_list = []
i = len(text)
while i > 0:
longest_word = text[i - 1]
# 遍历所有可能的结尾
for j in range(0, i):
word = text[j:i]
# 查询词典
if word in dic:
longest_word = word
# 得到最长,跳出
break
# 得到最长单词
# 逆向扫描,先查出来的单词放在后面
word_list.insert(0, longest_word)
# 跳到下一个终点
i -= len(longest_word)
return word_list
双向最长匹配
算法规则如下:
- 同时计算正向和逆向最长匹配
- 若两者词数不同,则返回词数更少的那个
- 否则,返回两者中单字更少的
- 当单字数也相同时,优先返回逆向最长匹配的结果
这种规则的出发点来自语言学上的启发:汉语中单字词的数量要远远小于非单字词。这种算法也称为启发式算法。
# 统计单字词的个数
def count_single_char(word_list):
return sum(1 for word in word_list if len(word) == 1)
def bidirectional_segment(text, dic):
'''
:param text: 字符串
:param dic: 词典
'''
# 规则1
f = forward_segment(text, dic)
b = backward_segment(text, dic)
if len(f) < len(b):
# 规则2
return f
else:
count_single_char(f) < count_single_char(b):
# 规则3
return f
else:
# 规则4
return b
对比
正向/逆向/双向最长匹配歧义对比,标粗的为正确的理解
| 序号 | 原文 | 正向最长匹配 | 逆向最长匹配 | 双向最长匹配 |
|---|---|---|---|---|
| 1 | 项目的研究 | [项目, 的, 研究] | [项, 目的, 研究] | [项, 目的, 研究] |
| 2 | 商品和服务 | [商品, 和服, 务] | [商品, 和, 服务] | [商品, 和, 服务] |
| 3 | 研究生命起源 | [研究生, 命, 起源] | [研究, 生命, 起源] | [研究, 生命, 起源] |
| 4 | 当下雨天地面积水 | [当下, 雨天, 地面, 积水] | [当, 下雨天, 地面, 积水] | [当下, 雨天, 地面, 积水] |
| 5 | 结婚的和尚未结婚的 | [结婚, 的, 和尚, 未, 结婚, 的] | [结婚, 的, 和, 尚未, 结婚, 的] | [结婚, 的, 和, 尚未, 结婚, 的] |
| 6 | 欢迎新老师生前来就餐 | [欢迎, 新, 老师, 生前, 来, 就餐] | [欢, 迎新, 老, 师生, 前来, 就餐] | [欢, 迎新, 老, 师生, 前来, 就餐] |
双向最长匹配正确率, 反而小于逆向最长匹配
。
