

mysql的组成部分
下面是mysql的逻辑架构图:
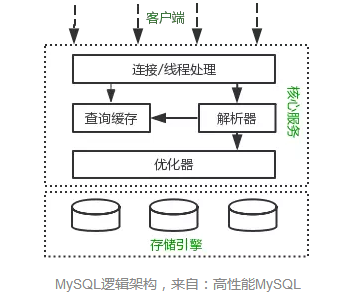
mysql 的逻辑架构分为三层最上面的是客户端层,诸如:连接处理、授权认证、安全等功能均在这一层处理。
然后是核心服务层:包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下面是存储引擎层:负责数据的读写,和linux的文件系统类型,该层通过实现几个api为核心服务层提供服务,这样api隔离了不同存储引擎的差距,所以要根据业务来选择存储引擎。
mysql 的查询过程
下面是mysql的查询过程图:
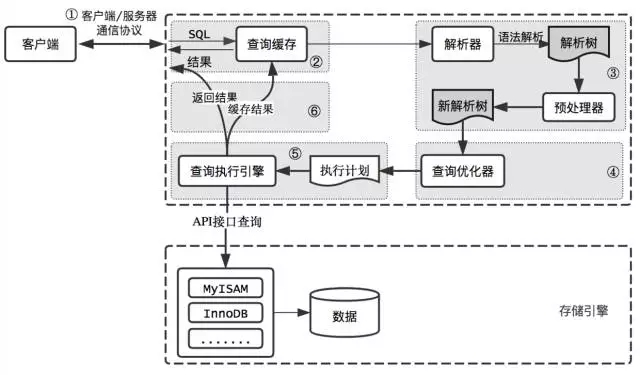
客户端/服务端通信协议是一钟“半双工”协议,意思就是当客户端发请求给服务器时,服务器只能读取请求数据,这时候服务器不能发送查询结果给客户端,同理当服务器发送查询结果给客户端时,这时也不能读取客户端的请求 (所以查询尽量返回需要的数据,减少不必要的列)
查询缓存,在如果打开了缓存,在sql语句进去解析器前会检查缓存中是否存在该sql语句,要是存在就只能返回缓存中的结果;
MySQL将缓存存放在一个引用表(不要理解成table,可以认为是类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义
缓存失效会在何时发生?当执行sql语句时,mysql缓存系统会跟踪执行过程中涉及到的每张表,当相关的表的数据或者结构变化时,缓存就失效了。要是缓存了大量结果,在失效的那一刻,mysql要把缓存中的结果失效,这会消耗大量系统资源,甚至会使系统僵死。
缓存对读操作也有影响。查询前需要先检查缓存是否命中,需要消耗系统资源;查询完后,需要缓存查询结果,也需要消耗系统资源
如果系统确实存在一些性能问题,可以尝试打开查询缓存,并在数据库设计上做一些优化,比如:
-
用多个小表代替一个大表,注意不要过度设计
-
批量插入代替循环单条插入
-
合理控制缓存空间大小,一般来说其大小设置为几十兆比较合适
-
可以通过SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存
语法解析和预处理,语法解析会更加sql关键字生成一棵解析树,这个过程也包括sql语法规则的检查,预处理是检查解析树中关键字是发正确,关键字的顺序是非正确,并且会检查是否存在对应的数据表或者字段
查询优化器,会根据合法的解析树生成查询计划,当然会有很多种执行计划,然后找出最好的执行计划。mysql使用的是基于成本的优化器,它预测每个查询计划的执行成本,选出成本最低的执行计划。
有非常多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确、不会考虑不受其控制的操作成本(用户自定义函数、存储过程)、MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但成本小并不意味着执行时间短)等等。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
-
重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
-
优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值,具体原理见下文)
-
提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
-
优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
查询执行引擎,通过存储引擎实现的接口(这些接口被称为handler api),完成执行计划。执行计划中每一张表都是一个handler实例,查询优化器可以通过该handler实例获取数据表的属性,比如表的列名、索引信息等
返回结果给客户端,最后会将查询结果返回给客户端,即使没有查到数据可以会返回这次查询的相关信息,比如查询的执行时间和查询涉及到的行数等,如果打开了查询缓存,还需要将查询结果缓存下来。
从哪些方面优化?
mysql级别优化:
- 数据库设计,数据表、字段设计、存储引擎;
- 利用好MySQL自身提供的功能,如索引等;
- 横向扩展:MySQL集群、负载均衡、读写分离;
- SQL语句的优化(收效甚微)
在硬件级别进行优化:磁盘寻址、磁盘读写、cpu周期、内存带宽;
字段的设计?
-
尽量使用整型表示字符串
-
mysql中的enum类型和集合类型,维护成本高,可以使用关联表来代替
-
定长和非定长数据类型的选择 (decimal不会损失精度,存储空间会随数据的增大而增大。double占用固定空间,较大数的存储会损失精度。非定长的还有varchar、text)
- 使用小单位大数额来避免小数
- decimal(8,2)有2位小数的定点数,带有两位小数的定点数
- 字符串存储, 定长char,非定长varchar、text(长度范围0-65535,其中varchar还会消耗1-3字节记录长度,而text使用额外空间记录长度),
-
尽可能选择小的数据类型和指定短的长度
-
尽可能使用 not null, mysql非null字段比null字段处理高效,判断是否等于null, 只能使用 is null, 反正使用is not null
-
单个表的字段不宜太多,上限二十到三十
-
字段名要能够简短且表达出用途
关联表的设计
一对多的话使用外键,多对多使用单独新建一张表将多对多拆分成两个一对多,一对一使用主键或者增加一个外键字段
存储引擎的差异和选择
InnoDB 支持事务,行级锁定,外键
存储差异如下图:
| - | MyISAM | InnoDB |
|---|---|---|
| 文件格式 | 数据和索引是分别存储的,数据.MYD,索引.MYI | 数据和索引是集中存储的,.ibd |
| 文件能否移动 | 能,一张表就对应.frm、MYD、MYI3个文件 | 否,因为关联的还有data下的其它文件 |
| 记录存储顺序 | 按记录插入顺序保存 | 按主键大小有序插入 |
| 空间碎片(删除记录并flush table 表名之后,表文件大小不变) | 产生,定时整理:使用命令optimize table 表名实现 | 不产生 |
| 事务 | 不支持 | 支持 |
| 外键 | 不支持 | 支持 |
| 锁支持(锁是避免资源争用的一个机制,MySQL锁对用户几乎是透明的) | 表级锁 | 行级锁、行级锁 |
行级锁(row-level lock):锁定的是一行或几行记录。共享锁:select * from <table_name> where <条件> LOCK IN SHARE MODE;,对查询的记录增加共享锁;select * from <table_name> where <条件> FOR UPDATE;,对查询的记录增加排他锁。这里值得注意的是:innodb的行锁,其实是一个子范围锁,依据条件锁定部分范围,而不是就映射到具体的行上,因此还有一个学名:间隙锁。比如select * from stu where id < 20 LOCK IN SHARE MODE会锁定id在20左右以下的范围,你可能无法插入id为18或22的一条新纪录。
表级锁(table-level lock):lock tables <table_name1>,<table_name2>... read/write,unlock tables <table_name1>,<table_name2>...。其中read是共享锁,一旦锁定任何客户端都不可读;write是独占/写锁,只有加锁的客户端可读可写,其他客户端既不可读也不可写。锁定的是一张表或几张表。
索引的选择
索引为什么快?关键字比较小,关键字有序,二分查找效率高。
有哪些索引类型? 普通索引(key),唯一索引(unique key),主键索引(primary key),全文索引(fulltext key)
三种索引的索引方式是一样的,只不过对索引的关键字有不同的限制:
- 普通索引:对关键字没有限制
- 唯一索引:要求记录提供的关键字不能重复
- 主键索引:要求关键字唯一且不为null
查看索引:show create table 、 desc
创建索引:
- 建表以后
create table text_index (
id int auto_increment primary key,
first_name varchar(16),
last_name varchar(16),
id_card VARCHAR(18),
information text
);
-- 更改表结构
alter table user_index
-- 创建一个first_name和last_name的复合索引,并命名为name
add key name (first_name,last_name),
-- 创建一个id_card的唯一索引,默认以字段名作为索引名
add UNIQUE KEY (id_card),
-- 鸡肋,全文索引不支持中文
add FULLTEXT KEY (information);
- 创建表时
create table text_index (
id int auto_increment primary key,
first_name varchar(16),
last_name varchar(16),
id_card varchar(18),
information text,
-- 复合索引
key name (first_name, last_name),
-- 唯一索引
unique key (id_card),
-- 全文索引
fulltext key (information
);
删除索引
-- 删除复合索引
alter table text_index drop key name;
-- 删除唯一索引
alter table text_index drop key id_card;
-- 删除全文索引
alter table text_index drop key information;
索引的存储结构
- btree: 一个树节点存储多个关键字,更加关键字大小拖拽子节点,适合范围查询(>=, <=),有序
- hash: 求得关键字hash值,然后存储
- b+tree: 节点上有关键字和行数据,innodb中只用primary key是聚簇结构
使用索引
- where 使用索引字段查询
- order by, 不使用索引,执行计划会将查询结果从磁盘读入到内存中,然后继续内部排序,然后合并排序解析,然后将结果返回;使用索引(innobd),索引字段本身就是有序的,所以不需要进行排序;
- join:对join语句匹配关系(on)涉及的字段建立索引能够提高效率
- 索引覆盖,查询带有索引的字段时,支持从索引表中返回结果,所以select 后尽量选择需要的字段,增加索引的覆盖率
语法细节
- 字段要单独出现,才能使用索引:
-- 使用索引
select * from user where id = 20-1;
-- 不使用索引
select * from user where id+1 = 20;
- like查询, 要不能再匹配词的左边加%符号,不然就不会使用索引
- 复合索引只对第一个字段有效
- or(或操作),两边条件都有索引可用
- 状态值,不容易使用到索引,状态值得数据比较单一,一个状态值会排配大量数据行,这种查询索引比全表扫描效率低。索引是随机访问磁盘,全表扫描是按顺序访问磁盘
ps: 持续更新
