

1. 变量在内存中的存储位置?
变量分为基础数据类型和引用数据类型,基础数据类型有:string, boolean, number, symbol,undefined,Null 引用数据类型:Object js的常见内置对象:Date,Array,Math,Number,Boolean,String,Array,RegExp,Function...
基础数据类型存放 && 复制
let a = 1
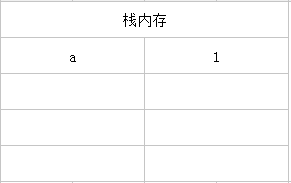
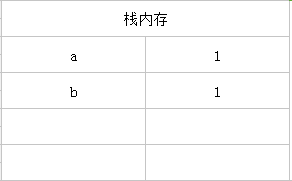
基础数据类型,当一个变量像另一个变量赋值的时候,会创建一个新的值赋值给另一个变量
let b = a
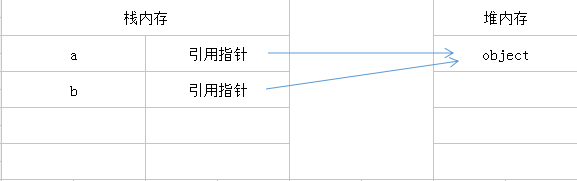
引用数据类型的存放
引用数据类型的值是保存在堆中的对象,也就是变量存的是一个存在栈中的指针,指针指向内存的某处(堆内存某处)
const a = new Object();

当需要修改a对象的值,会先从栈中取出A的值(指针),然后通过指针找到堆中的对象,然后操作对象中的值。
a.name = "boy"

当复制a给b变量时,现在栈中新建一个空间保存a变量存的指针。
堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。对于堆,我们可以随心所欲的进行增加变量和删除变量,不用遵循次序。
栈区(stack) 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。
堆区(heap) 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构
2. require 模块的顺序?
nodejs require模块会有三个步骤:路径分析、文件定位、编译执行
nodejs中个模块分为两类:核心模块和文件模块(用户自己写的)。
当node开始启动时,会加载核心模块到内存中,因为核心模块是已经编译好的二进制执行文件,于是可以省去文件定位和编译执行两步。
文件模块的加载就需要经过完整的三个步骤,而且是动态加载,加载完成会放入缓存中,以便再次加载,再次加载可以不经过三个步骤,节约时间。
路径分析:
- 核心模块比如:fs、path等这些模块
- .或者..开头的相对路径文件模块
- /开头的绝对路径文件模块
- 非路径形式文件模块,比如connect
核心模块不说了,相对路径和绝对路径文件模块将路径变为真实路径然后加载文件模块,编译执行后放入缓存中。
非路径形式文件模块是从最近的node_modules文件目录下查找,然后查找父级node_modules,然后再想上一级路径下的node_modules查找,要是没找到就包error。
文件定位 当require的至少一个文件名,不带后缀,那么node会按照.js、.node、.json顺序判断
如果找到了相对的目标目录和包,就找是否存在package.json,然后JSON.parse()得到描述对象,取描述对象的main属性,要是不存在main属性或者不存在package.json文件就默认找index.js文件开始编译执行,然后加入缓存中
3. A模块 require 模块B , B 模块 require A模块 是怎么解决这个问题的?
- 模块在开始执行的时候就会被加入缓存
A模块编译执行到引用B的那步,然后B模块开始编译执行到require A模块的时候,从缓存中加载A模块(还没有完整执行完成的A模块)以及执行的那步,然后进行执行。
面对循环依赖问题:每个模块先导出自身,在导入其他模块
module.exports = = {
A: 'this is a Object'
};
let n = require('./b.js')
4. 异步流程控制有哪些?
- async模块
- promise + async/await
[基于Promise和Async/Await的异步流程控制] zhuanlan.zhihu.com/p/26054307
这里推荐一篇关于nodejs事件循环讲解的文章:【Node.js】理解事件循环机制
