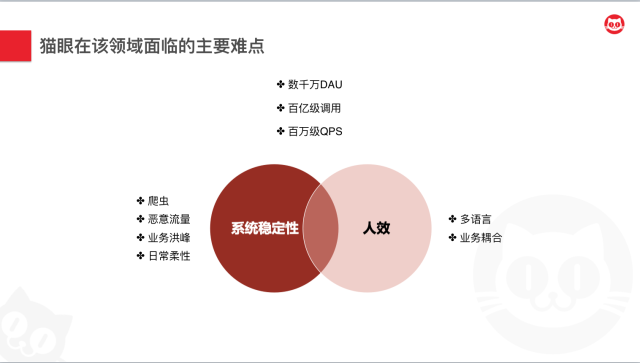
- 从系统层面来说,主要面临的是系统稳定性的问题。大家都知道,每一家公司都会有一些数据资产是很敏感的,所以需要对于一些爬虫和恶意流量进行准实时的处理。另外,猫眼娱乐作为一个全娱乐领域的平台型公司,也会承载业务在大档期和大活动中流量几倍、十倍甚至百倍千倍的压力爆发,如何在这种情况下,保障系统的可用性,也是一个值得研究的问题。以及,故障是无法避免的,无论流量高低。所以如何保障系统的日常柔性可用,也是需要关注的问题
从人这一层面来说,主要面临的是人效问题。服务治理的各种中间件采用的总体上是一个富SDK的方式嵌入业务方。所以这必然会带来两个问题,多语言的情况下会带来更高的维护成本,以及SDK升级所会带来的和业务相互耦合掣肘的问题。
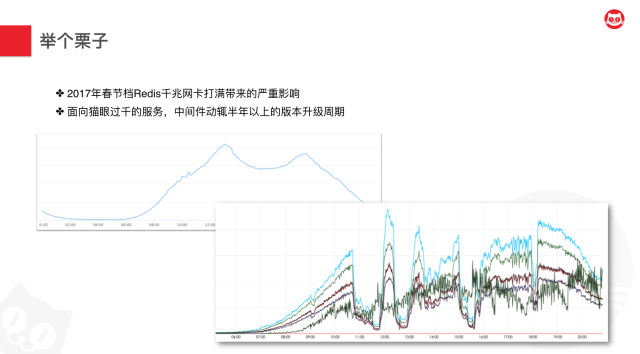
- 在稳定性这方面,2017年春节档Redis千兆网卡打满带来的严重影响,我们常规时候的流量曲线会有两个规律的早晚高峰,而大家可以看到,在故障当天,因为网卡打满导致了非常长时间的服务不可用。这也是猫眼经历过的一个非常重大的事故。
- 而在人效方面,目前猫眼有1000+的服务,中间件的升级动辄半年以上的版本升级周期,这个其实对于业务方或者底层架构团队来说都是非常不友好的一个体验。
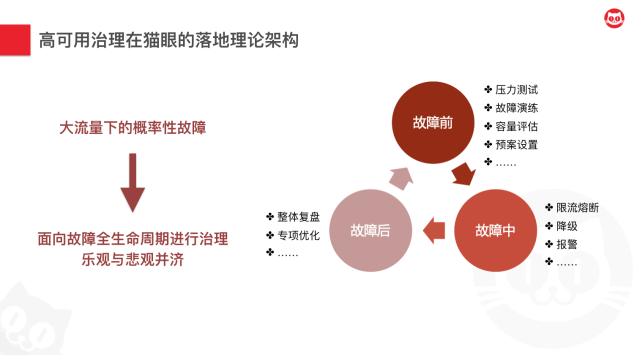
怎么理解这句话呢,从乐观角度上来说,我们通过各种测试和评估,我们的系统应该可以避免所有的问题。但是从悲观角度来看,基于墨菲定律,我们知道可能发生的就一定会发生,所以我们必须来看假定问题发生,我们能做什么。以及问题真的发生,我们又能做什么。
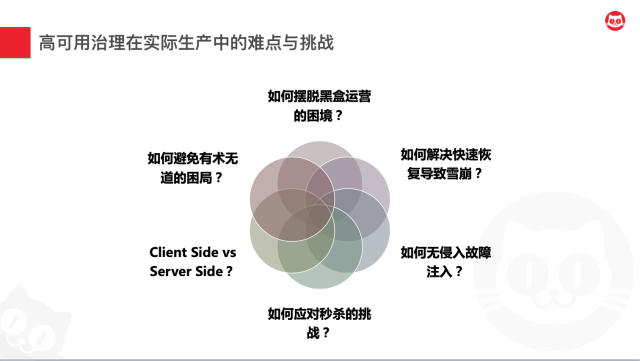
另外,高可用领域中,流控的常规解决方案是用富SDK来做的,而富SDK是否能满足业务快速滚动以及流控自身敏捷迭代升级的诉求呢?而如果将流控功能都剥离到Server端,我们知道分布式环境中会带来最大麻烦的就是网络,全部剥离到Server端的话如何保障实时性和可靠性?也就是所谓的Client Side或Server Side,我们应该如何抉择?

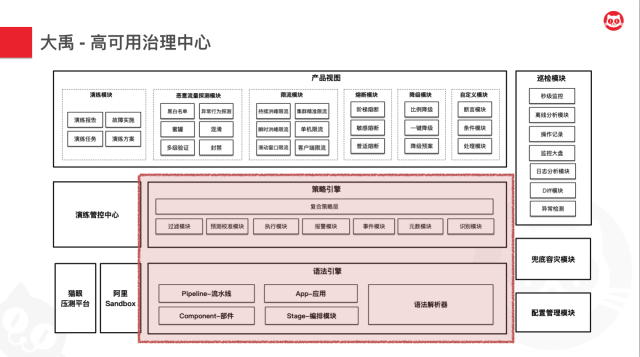
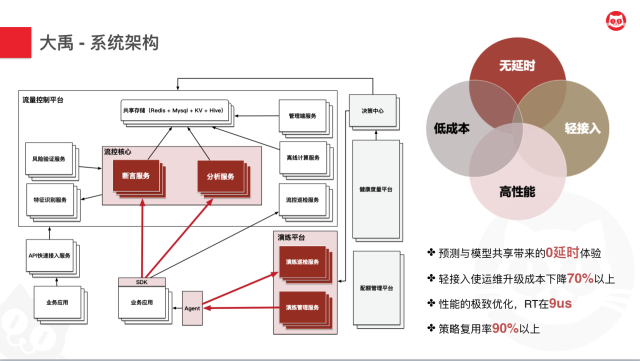
- 在最上层,是我们的产品层,高可用治理中心目前提供出了恶意流量探测、演练、限流、熔断、降级的产品,同时,为了达到策略上线效率的最大化,我们还提供了可自定义规则的模块,我们将一条策略抽象为以断言、条件判断和处理三个组件为核心的一个表达式,这样就可以在无需前端任何产品级别开发的前提下完成策略的快速上线。同时你可以基于我们原子的策略组件的自由拼装,来实现你想要的自定义的策略能力。
- 左下角的演练管控中心则支撑起了演练产品,他底层依托阿里的Sandbox实现动态注入和销毁,同时协同猫眼的全链路压测平台来提供流量的模拟和调度。在最右边则是一些基础模块,包括全方位巡检和兜底容灾的模块,以及配置分发模块。
- 接下来,我们可以看到支撑产品形态的核心能力是一个策略引擎,除了演练模块之外,其余无论是哪个产品,底层都是由这个策略引擎进行支撑的。策略引擎提供了各种策略模块的支撑,并提供了复合的策略层能够进行自由的组合拼装来实现你所需要的策略。
- 而在策略引擎的底层依托于高可用治理中心的语法引擎,我们将策略的场景最近高层次的抽象,提取出四个模块——App、Pipeline、Stage、Component四部分。并通过高度内聚的语法解析器来进行解析。具体我们后面会有介绍。
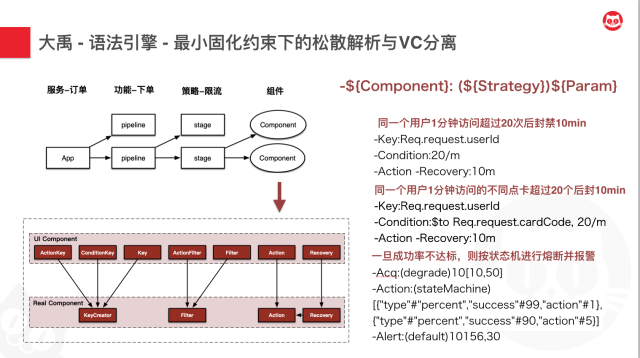
我们接着看,可以看到实际中,我们可以定义很多策略组件,比如特征维度、过滤器、动作、条件判断、恢复策略等等。而这些策略你可以定义实际组件和视图组件,来让你的语义尽可能地友好。所以你可以看到,有很多组件,他们在视图层和控制层其实是分离的,他们可以是一对一、多对一、一对多的关系。这样就可以让你的视图层尽可能友好的情况下,实现控制层最大程度的精简。
整个语法引擎的核心表达式即如标题右侧所示。如何解析由Component自己定义说了算。这样就实现了组件与组件之间的松耦合和自己内部的高内聚,用轻量级的原子解析,来避免将语法解析器做成一个难以维护的巨无霸产品。
右下方是一些简单的示例。可以看到,无论你是简单的频率限制、或者稍微复杂一点的反爬策略,再或者是状态机熔断这类规则,都可以通过我们的表达式轻松搞定。
最小固化约束下的松散解析,加上VC的分离,这就是猫眼高可用治理语法引擎的核心理念。
下方有个演练平台,即用来进行压测模拟、故障模拟、预案验证。这边不做过多介绍。
说到这,大家如果了解Servicemesh的可能会有点熟悉,这种远端实时控制的方式,是不是有点类似于Istio的Mier服务?是的,在我们16年启动的时候,也是经历了控制平面如何切割,Server还是Client为重的苦苦思索和探索,后来确定了猫眼的流控路线是Server Side为主的方式进行。这个路线也为后续猫眼的发展带来了非常大的便利。仅这个架构选型几年内节省了数百人天以上的投入。你们可能会有疑问,Mixer在Servicemesh中被认为是一个相对没那么成功的实现,那猫眼是如何规避的呢?我们接着往下看。
- 时效性。我们采用了一些预测算法来进一步保障决策的实时性,同时,断言分析底层依赖同一套策略模型,所以你想要绝对的实时,我们也能够快速地让断言服务同时具备实时分析能力。目前能够做到无延时判断。
- 轻接入。采用API快速接入服务、轻SDK的方式,让运维升级成本下降70%以上。
- 高性能。1)就近的本地缓存,并进行严格的Key控制来防止指数级增长撑爆业务进程的case出现。2)分析和断言流程的快慢分离,比较重的分析流程异步化,进一步提升实时流量性能。3)基于请求特征树缓存来加速特征提取,速度比Spring快50%以上。同时也通过这种方式对请求大小进行了压缩。通过以上这些方式对性能的优化。目前我们的RT仅在9us。这个其实也就侧面解决了Mixer目前的最大困扰。
- 低成本。除了上述因为采用Server-Side为主进行一些重策略的处理所带来的运维成本大幅下降之外,策略底层是由一个个策略原子组件所构成,这些组件本身具备高度的可复用性,目前策略复用率在90%以上。
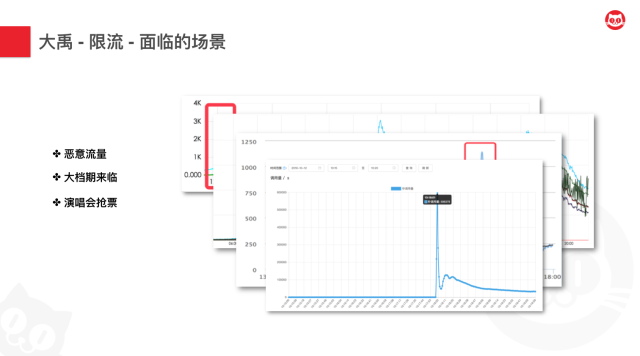
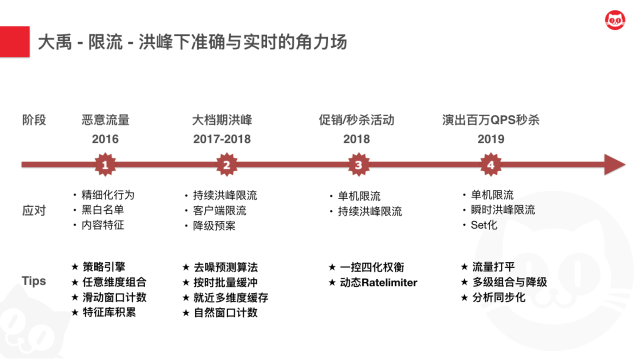
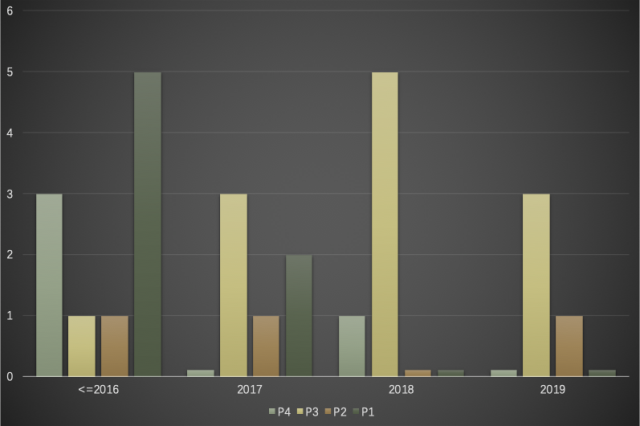
在2016年及以前,我们其实面临了非常多的恶意流量、爬虫流量,在尝试对猫眼进行一些攻击和商业敏感数据的抓取,针对这个问题,我们研制了策略引擎,并基于此搭建了流控平台,在此基础上,在策略上,我们提供了一些精细化的行为探测,黑白名单,以及基于请求内容特征的决策策略。
实现的关键点主要有四个,第一,从0到1研制策略引擎,第二,策略需要支持任意维度的组合。第三,基于Redis采用滑动窗口计数。第四,进行行为和内容特征库的持续持久化积累。
阶段二:大档期洪峰
到了下一个阶段的攻防,主要就是流量过载的防御,2017年大年初一的服务雪崩给业务带来了较大影响。大档期洪峰来临后,我们这个阶段要求实时性要进一步提升,而本来的这种异步分析的方式是无法满足我们需求的,我们研发了持续洪峰限流策略,基于去噪预测算法基于过去的历史数据来预测当前时刻的数据,准确率可以达到99.2%。这不到1%的一个qps牺牲来换取0延时的效果,是可以接受的。同时我们采用多级缓存、批量缓冲以及自然窗口计数的方式,进一步降低对Redis的依赖,彻底实现了Redis无热点情况下的集群持续洪峰限流策略。
除此之外,我们也提供了其他的能力。比如客户端限流,我们都知道限流越靠前效果越好,所以我们也将限流前置到了客户端层面。以及降级预案,我们可以选择非核心交易链路的功能,进行紧急情况下的部分流量降级和全部降级。
通过第二阶段的攻防,我们对于实时性有了更高的要求,准确性可以有接受小的牺牲。第二阶段完成后,接入的系统能够承载数百倍过载流量压力而不被压垮。
从2018年下半年开始,我们也不断衍生出银行活动和演出秒杀的场景。这类秒级别激增的流量,用预测算法已经无法很好支持,因为这种瞬时激增的脉冲流量是无法被预测的,更甚可能由于去噪预测算法会将其标识为噪点数据而导致误差的进一步放大。
- 因为此时入口服务由于大流量的突发冲击,持续洪峰限流策略基于过去的预测算法会失效,已经难以满足要求,而猫眼入口服务的负载均衡策略的RR策略,而且能够更加实时地反应,所以单机限流策略能够取代前者发挥很好的作用。
- 同时内部服务的流量策略是多样的,且流量已经一定程度被打散,所以采用持续洪峰的集群式限流仍然可以起到作用,且相较于单机限流会更为保险不容易误判。
- 对系统进行兜底控制。如上面我们所做的单机+集群持续洪峰限流策略双管齐下。
对业务进行场景化。比如答题、玩游戏。
对业务进行异步化。比如排队
对资源静态化。一些内容和功能可以分发到CDN、服务端LB上去做静态化提速。
对资源进行隔离。无论是Set化、还是其他方式,对服务器、缓存、数据库等等的热点资源进行物理/逻辑层面隔离。
阶段四:百万级别QPS秒杀
但是呢,还没结束。随着业务的蓬勃发展,2019年演出迎来了百万级别的QPS秒杀场景,我们发现后续步骤用持续洪峰限流也已经无法满足要求,即使经过前面几个步骤的打散,后续步骤的一些系统qps仍然会有激增到很高的情况,我们的用户、订单服务都遭受到类似的问题冲击影响了系统的稳定性甚至导致关联业务受损。
所以这时候我们对于这类的场景,进行了如下几点的处理。
- 由于复杂服务拓扑部署结构和LB策略的不同,所以内部流量本身是不均匀的。无法直接对一些下沉在底部的基础服务直接使用单机限流。所以我们将业务流量通过RR策略重新导到流控服务端进行流量打平,再在流控Server端完成单机限流。
- 但是,这个对于QPS不高的场景,比如业务方设置QPS为150,但是当前流控服务端机器数只有100台,则最大会带来50%的误差,进而产生误判,这种情况是不可被接受的。所以我们针对QPS不高(5k)的场景,自动将其降级为击穿到Redis进行自然窗口计数实时分析判断。来解决这个误差问题。
- 前面提到分析和断言两个服务底层依赖的其实是同一套策略引擎,以便于同步、异步分析的随时切换。所以我们在这个策略中进行了策略引擎的同步化定制,同时将业务SDK缓存失效,以此在牺牲1-2ms性能的基础上达到绝对的实时。
- 同时,在后续流控马上会对其进行Set化。针对演出业务进行独立Set部署。避免大流量下的业务之间相互影响问题。
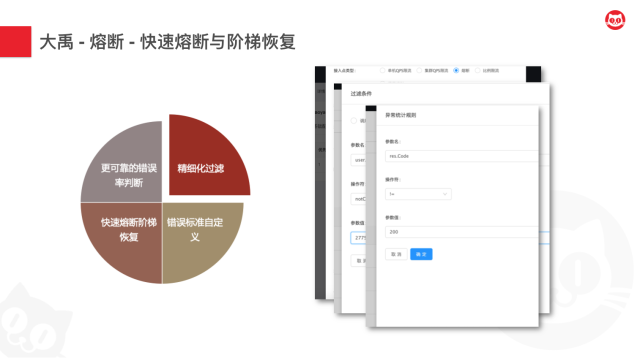
- 我们能够支持精细化的过滤和错误判断标准的自定义
- 同时为了避免快速恢复导致服务雪崩,因而我们采用了阶梯式的熔断策略。有点类似于开手动挡的车,可以跨档降速,但不能跨档提速。通过这种方式,我们提供了这种快速熔断-阶梯恢复的策略。
- 我们目前基于猫眼业务主要提供的是基于错误率的判断,但我们都知道,当流量较低的时候,按照错误率来判断很容易造成误伤,而流量很低的时候,我们进行熔断的现实意义也不是很大,所以我们也设置了当前熔断策略启动的流量阈值。
提完了限流、熔断。之后不得不说道目前业内提到的一个越来越流行的做法,即基于类似BBR的TCP拥塞控制算法的方式来进行自动化的处理,来避免各种参数配置带来的不可控的成本和影响。这是一个非常好的思路。
这其实给我们提供了很大的想象空间的同时也能解放人力,是未来猫眼希望去深耕的一个方向。
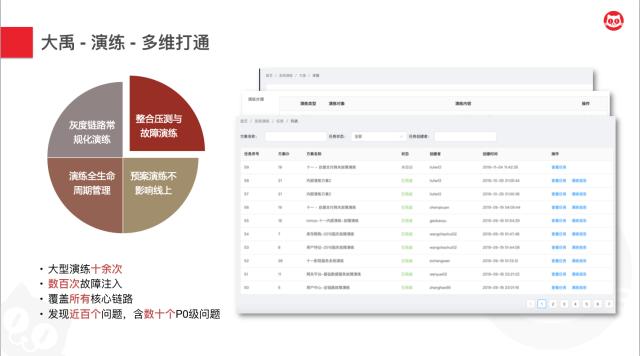
同时,我们知道,为了尽量降低风险,一般的演练都会放到晚上高峰期之后再进行。所以针对这种情况,我们也实现了在灰度链路上进行演练,以此来大幅削减演练的成本。两年以来,我们累计进行十余次大型演练,发现了超百个问题,包含数十个致命级别的问题。这说明,我们的演练事实上发挥了非常关键的作用。
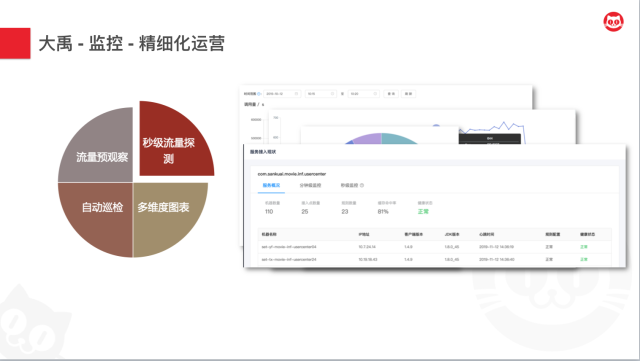
同时,我们也提供了“流量预观察”的能力。因为我们知道,一条策略上线是否可靠,是否会阈值设置有问题带来一些不可控的影响,上线之前基本业务方心里是没有底的。这个时候我们提供了这种预观察的能力,能够模拟策略生效,让你实时观察实际的影响。从而给你提供了“反悔”的机会。这种能力在我们的限流熔断足够智能化无参化之前,是一个极其重要的能力。