

在介绍字符编码规范之前先介绍几个概念:
字节
字节是计算机信息技术中用于表示存储容量的最小计量单位,一位二进制数(0或1)就是1位(bit),8位二进制数为一个字节。
字符
在人文世界中,任何一个文字或者符号都是一个字符,例如:“你”、“我”、“他”、“?”,它们都算一个字符。
字符编码规范的产生
计算机只能识别0和1的二进制数,随着时代的发展,人们希望在计算机中显示字符。于是国际组织就制定了字符编码规范,希望使用不同的二进制数来表示不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们就将这些二进制数和字符的集合称为XX编码,XX字符集。字符编码规范的作用就是规定了如何将计算机能够识别的二进制数和人类能够看懂的字符进行相互转换。
什么是字符编码规范?
字符编码规范其实就是一套规则的集合,它下面有三要素:字库表(characterrepertoire)、编码字符集(coded character set)、字符编码(characterencoding form)。
规范规范,就像小时候听说过的《小学生行为规范》一样,它有很多规则组成,规定了我们在学习方面要如何去做、在思想品德方面要如何去发展……。那么字符编码规范也是类似的:字库表存储了本字符编码规范中可以显示使用的所有字符;编码字符集与字库表是一一对应的,编码字符集用一个编码值codepoint来表示一个字符在字库中的位置(地址);字符编码则是规定了如何将序号转换成二进制序列
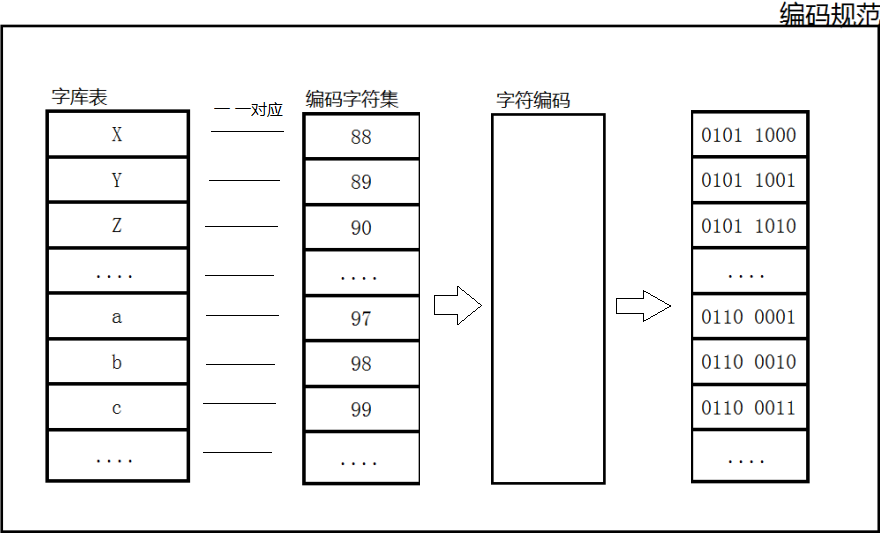
常见的字符编码规范以及它们之间区别
ASCII码
American Standard Code for Information Interchange美国信息交换标准代码,是最早产生的编码规范,一共包含00000000~01111111共128个字符。可以表示阿拉伯数字和大小写英文字母,以及一些简单的符号和控制符,ASCII编码规范中一个字符占一个字节。
GB2312和GBK
当中国也有了计算机之后,为了显示中文,必须设计一套用于将汉字转换为计算机可以存储的二进制的编码。GB2312应运而生,它包含了六千多个常用汉字和字符,所有字符都是双字节存储;GBK是GB2312的扩展,向下兼容GB2312,包含两万两千多个字符,所有字符都是双字节存储。
值得注意的是:就算使用的是GBK编码,半角的英文字符也是占用一个字节的内存。
String s="a";
byte[] nn =s.getBytes("GBK");
for (byte b : nn) {
System.out.println(Integer.toBinaryString(b));
}
>>>输出结果:1100001
半角状态的字母a占一个字节(01100001),全角状态的字母abcd占两个字节,a(10100011 11100001)
在网上查了一些资料后看到一个说法:GB2312和GBK不对半角下的英文字符编码,对半角状态英文字符编码那是ASCII码的工作
ISO-8859-1
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是00000000-11111111最多能显示256个字符,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,不支持中文。另外ISO-8859-1也是很多开源软件的默认编码集,例如:Tomcat、Mysql等,可以想象JavaWeb系统中文乱码它是头号罪犯。
在查ISO资料的时候,百度百科的介绍中有这么一段话“因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。”大概意思就是因为一个ISO-8859-1字符正好是八位二进制数来表示,就算把其他编码的二进制(例如GBK编码中,“我”这个字符的字节流是11001110 11010010,如果要当成ISO-8859-1来用大不了就是一个字符拆成两个来用)当做ISO-8859-1的字节流来处理也不会改变原来的二进制序列,如果把上述字节流当成除ISO-8859-1之外的编码来处理,则可能对原来的字节流造成损害不可复原。下面举例说明:
//原始字符串
String GBKStr="我是谁";
System.out.println("GBK原字符:"+GBKStr);
//将字符串用GBK编码成二进制序列
byte[] GBKByteArr =GBKStr.getBytes("GBK");
//将GBK二进制序列当成ISO-8859-1二进制序列来用
String iso8859=new String(GBKByteArr,"ISO-8859-1");
System.out.println("当做ISO-8859-1使用:"+iso8859);
//将GBK二进制序列当成ASCII二进制序列来用
String ASCII=new String(GBKByteArr,"ASCII");
System.out.println("当做ASCII使用:"+ASCII);
//再从ISO-8859-1还原成GBK
String iso8859toGBK=new String(iso8859.getBytes("ISO-8859-1"),"GBK");
System.out.println("从ISO-8859-1还原成GBK:"+iso8859toGBK);
//再从ASCII还原成GBK
String ASCIItoGBK=new String(ASCII.getBytes("ASCII"),"GBK");
System.out.println("从ASCII还原成GBK:"+ASCIItoGBK);
最终结果:
GBK原字符:我是谁
当做ISO-8859-1使用:ÎÒÊÇË
当做ASCII使用:������
从ISO-8859-1还原成GBK:我是谁
从ASCII还原成GBK:??????
可以看到把GBK编码的字节流当做ISO-8859-1字节流来使用,三个字符的字节流被解码成了六个字符,并且再还原为GBK是正常的;但是把GBK编码的字节 流当做ASCII来使用,解码成了乱码,并且再还原回去也是不正常的了,说明原来的字节流已经被改变了。
Unicode
就在大家的编码集不统一、各玩各的情况下(中国的GBK、日本的Shfit_Jis……),造成了很多麻烦,于是国际组织就决定制定一个可以容纳世界上所有文字和符号的字符编码规范,这就是Unicode。它为世界上所有字符都分配了一个唯一数字编号,数字编码范围是0X000000到0X10FFFF(110多万个),这样全世界人民只使用这一套编码规范就行了。
Unicode编码规范只是为每个字符分配了一个唯一的数字编号,但是并没有规定这个数字编号该如何编码成字节流(二进制序列)。在此之前出现的部分早期编码规范没有涉及到编码方式这个概念,都是直接把数字编号转换成对应的二进制数,例如ASCII、GB2312、GBK等。而到了Unicode这里人们考虑到了一些问题:Uncode编码规范的字库表有110多万个,2个字节=2^18=65536,3个字节=2^32≈4.29x10^9。如果还是像以前那种方式编码,那么每个字符都要占三个字节,相对于以前的编码规范(例如美国人用ASCII),字符显示提高了兼容性的代价就是无论保存在磁盘还是在网络上传输几乎都是接近三倍资源的消耗。这个时候就需要一个优良的编码方式来解决这个问题,UTF-32、UTF-16、UTF-8就是针对于Unicode的一种编码实现方案,UTF-8编码方案就是英文字符占一个字节(因为最常用),常用中文占3个字节,少数生僻字符占四个字节。
下面从常见的几个编码集中任选一个字符来比较一下它们的区别:
| 编码规范 | 字库表 | 字符编码集 | 字符编码 | 字节流 |
|---|---|---|---|---|
| ASCII | a | 97(十进制) | 直接翻译成二进制 | 01100001 |
| GBK | 中 | D6D0(十六进制) | 直接翻译成二进制 | 11010110 11010000 |
| Unicode | 中 | 4E2D(十六进制) | UTF-32、UTF-16、UTF-8 | UTF-8:11100100 10111000 10101101 |
小结:常见编码集的区别
| 编码规范 | 英文字符大小 | 中文字符大小 | 特点 |
|---|---|---|---|
| ASCII | 1 字节 | 无中文字符 | 最早的字符编码集,总共128个字符 |
| ISO-8859-1 | 1字节 | 无中文字符 | 向下兼容ASCII,总共256个字符,是很多开源软件的默认编码集 |
| GBK | 1 字节(半角状态英文) | 2字节 | 包含两万多个汉字字符 |
| UTF-8 | 1字节 | 通常3字节 | 向下兼容ASCII,包含世界上所有字符 |
字符乱码产生的原因以及如何解决乱码
字符乱码产生的根本原因
首先通俗的介绍一对概念
- 字符编码:将人类能够理解的字符转换成计算机能够识别的二进制序列。
- 字符解码:与编码相反,将二进制转换为字符。
而乱码产生的根本原因就是在编码解码的过程中没有按照同一个编码规范来编码解码或者是要编码的字符不包含在指定的编码规范中
例如最常见的JavaWeb系统中文乱码,要向客户端(浏览器)输出一段中文字符串
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String str ="你好!";
//向客户端输出参数
response.getWriter().write(str);
}
这段代码最终在浏览器上显示的就是三个问号???,因为Tomcat这个web应用服务器默认编码集是ISO-8859-1,是不含中文的,这个时候要显示中文肯定是不行。如果我们指定了一个包含中文字符的编码集进行编码,再告诉浏览器用同样的编码集进行解码,就可以正常显示中文字符了
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//指定编码时使用什么编码集
response.setCharacterEncoding("GBK");
//通知客户端使用什么编码集解码
response.setHeader("Content-Type", "text/html;charset=GBK");
String str ="你好!";
//向客户端输出参数
response.getWriter().write(str);
}
Web应用中可能产生乱码的各个节点
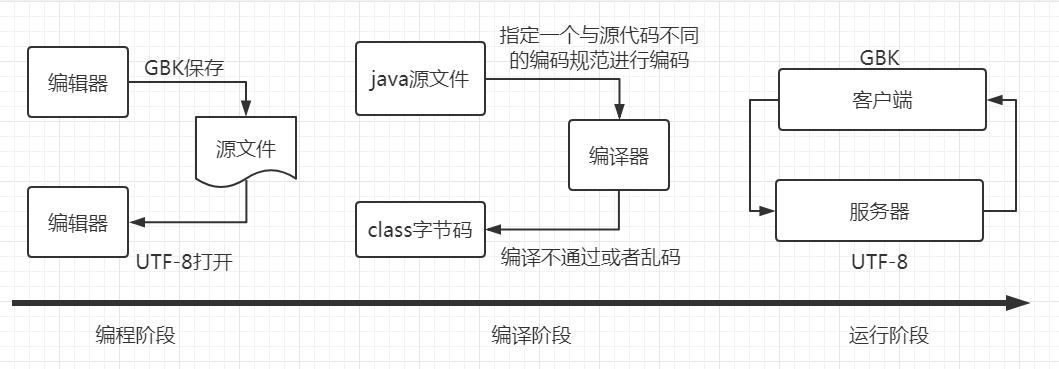
- 编码阶段:当你打开同事传给你或者从github上下载的源代码文件时发现里面的中文注释是一堆乱码,是因为你的编辑器使用的编码集与文件使用的编码集不一致,调整为一样的即可。
- 编译阶段:如果是IDE工具自动打包发布,一般都没什么问题。在命令行里面编译java源文件时可以指定编码集,如果指定的编码集与代码使用的编码集不一致则可能乱码或者编译报错。javac -encoding utf-8 D:/MyCharset.java
- 运行阶段:绝大部分的乱码问题都是在运行阶段产生的,例如:客户端向服务器提交中文字符串参数、读取的配置文件中有中文字符等等。
运行阶段中可能产生乱码的节点
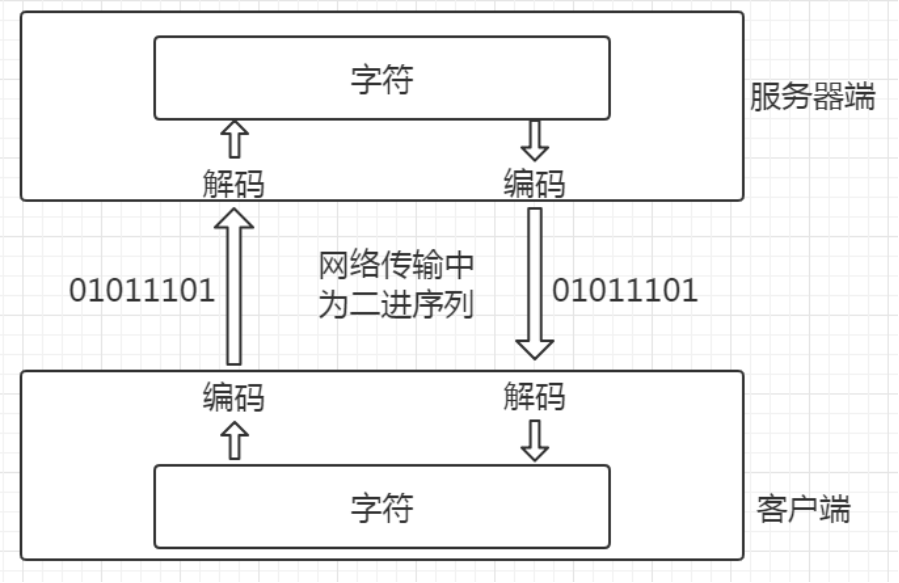
小结:解决乱码的思路
网上解决乱码的具体代码数不胜数,这里不再赘述。但是我们在了解了字符编码相关知识及乱码产生原因后只需要牢牢抓住一点:乱码的根本原因就是在编码解码的过程中没有按照同一个编码规范来编码解码,然后再按照各个节点挨个排查,就能很快定位并解决问题。
