共用体类型: 也被称之为联合体,使用union 申明,使几个不同类型的变量共享同一个内存地址
这样 a成员、b成员、c成员可以存放在同一个 内存单元中了
好处: 可以节省一定的内存开销
缺点: 在同一时刻仅仅只能存储一个成员
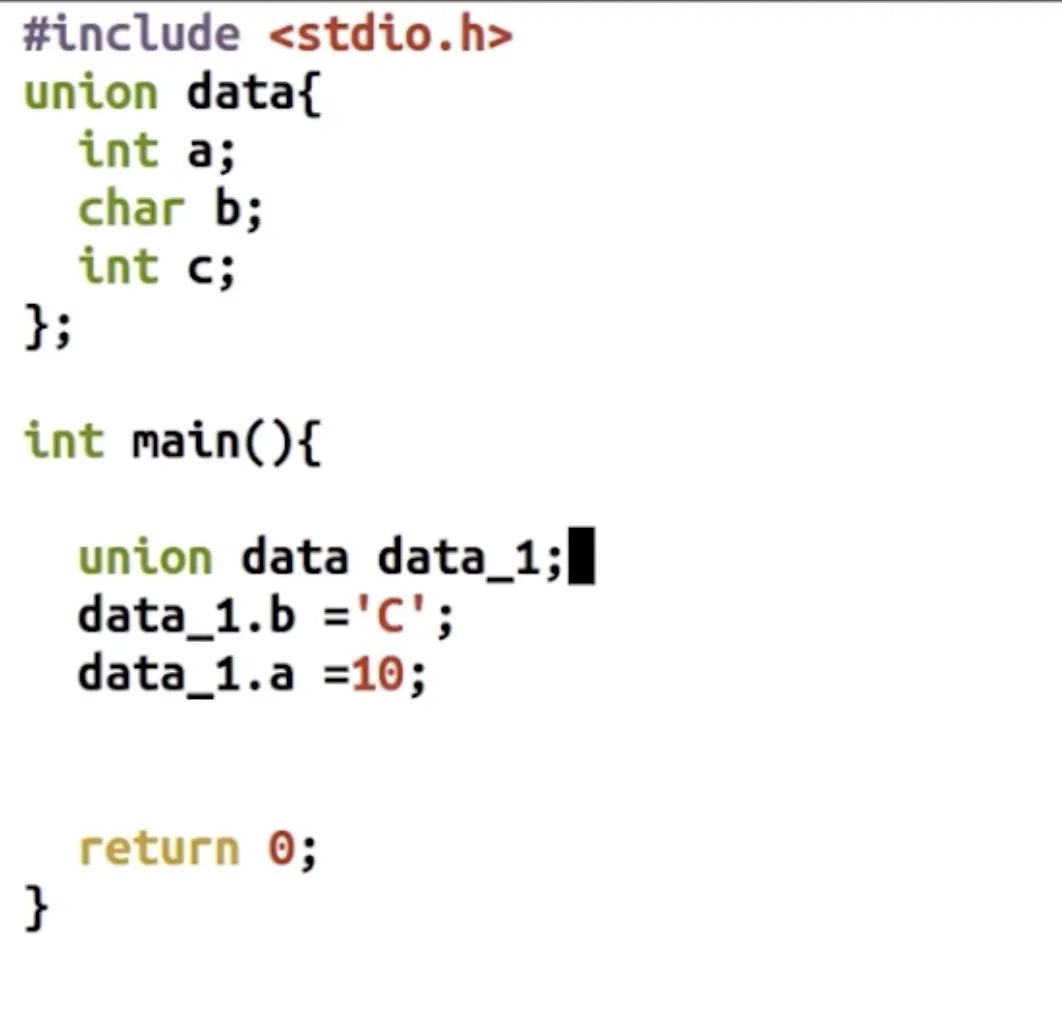
data_1.b = 'C';
data_1.a = 10;
最后保存下来的是 后面这一条, 共用体只能有一个值,

字节大小:
共用体的字节,使用成员中字节最长的那一个,比方说int是四个字,char只有一个字节,所以int的这个类型就是最长的,四个字节。所以呢,这个共用体类型就在四个字节。
结构体不一样,假设我现在这个union,换成ctruct。
我们看到这个东西的时候可能会下意识的去想,这个struct的类型对象,它所占用的内存空间。应该就是这几个成员的和,4加1加4等于9。
其实不是这样的,结构体对象所占用的空间大小涉及到了一个字节对齐的问题。这个字节对齐的目的,主要是为了让计算机能够快速读写,是一种以空间换取时间的一个方式。
结构体对象的这个大小。有这样的一个公式。结构体的大小等于最后一个成员的偏移量,加上最后一个成员的大小,再加上末尾的填充字节数。
首先我来解释一下偏移量的概念,所谓的偏移量的就是某一个成员的实际地址和这个结构体首地址之间的距离。比如说这个成员a,由于是第一个成员,所以他的地址就是结构体的首地址,那么它相对于结构体的首地址的偏移就是零。那么第二个成员b,他离结构体的首地址隔了一个变量a的大小,所以b的偏移量就是4。
那么在结构体做字节对齐的时候有这样的一个准则。每个成员相对于结构体首地址的偏移量都得是当前成员所占内存大小的整数倍,如果不是,编译器,就会在成员之间加上填充字节。比方说这里的这个a成员由于它的批量是零,这个没有问题。本来看一下b成员,并成员它所占的字节数是一。他的偏移量是四。这个时候他的偏移量四是它自身大小一的整数倍。所以呢,这里编译器不会在成员a和成员b之间填充字节。
但是c。对于c来说它的自身大小也是四字节,但是他目前的这个偏移量是四加一等于五。不是四的整数倍。所以编译器就会在b成员的后边作为一个字节填充,让c的偏移量变成8字节,这个时候他的偏移量,就是它的自身类型大小的整数倍。同样的结构体占总大小也变成了12,8+4=12。
然后到了这里还没结束,编译器还要去判断。现在的结构体总大小是不是结构体中最宽的基本类型成员大小的整数倍,在我们这个里边的最宽的基本类型就是int,是四字节,是能够被12整除的,所以这里是没有问题,那么如果这个最宽的基本类型不能够被我们当前的这个偏移量加上最后一个类型大小的和整除的话,那就还要在c的后边去做一个字节填充。那这样的我们得到的结果就是这个struct类型的真实的大小。


