

业精于勤,荒于嬉;行成于思,毁于随!学习从来都不是一蹴而就的事情,需要每天的点滴积累与沉淀,从而由量变引发质变!
我在 github 上建了一个仓库 全栈每日一题,每天早上9点发布一个web全栈的题目。有关前端,nodejs,运维,数据库以及软技能等,促进个人技术职业成长,欢迎交流。
为什么建这个仓库?
每个人的学习方式不一样,有的人自律性强一些就会工作之余去学习新知识技术,构建自己的知识技术体系,暂且叫自我驱动型吧,而有些人仅仅满足于目前当前工作,工作中出问题才去学习去网上找资料等等,暂且叫这种被动驱动型,建这个仓库用每日一题的方式来倒逼强迫自己每天去学习去查漏补缺 ,系统构建前端完整的知识体系,而且可以在Issues与大家一起交流观点技术等。
一万小时定律
最近有在看两本书,叫《刻意练习》和《持续行动》,人的行为和习惯通过刻意持续的练习是可以改变和养成的,还有著名的21天习惯养成记和一万小时定律,关键得自己有毅力去坚持去行动等。
要成为某个领域的专家,需要10000小时,按比例计算就是:如果每天工作八个小时,一周工作五天,那么成为一个领域的专家至少需要五年。这就是一万小时定律。
本期
第110题(2019-12-21):聊聊前端模块化方案及import、require、export、module.exports 的区别?
1.什么是模块?
- 将一个复杂的程序依据一定的规则(规范)封装成几个块(文件), 并进行组合在一起
- 块的内部数据与实现是私有的, 只是向外部暴露一些接口(方法)与外部其它模块通信
2.模块化规范
- CommonJs
- AMD
- CMD
- ES6模块化

3.import、require、export、module.exports的区别?
他们都是成对使用的,不能乱用:
module.exports 和 exports是属于CommonJS模块规范,对应---> require属于CommonJS模块规范;
export 和 export default是属于ES6语法,对应---> import属于ES6语法。
服务器端(Nodejs)
导出:module.exports 或 exports
导入:require
示例用法
module.exports={
add:add,
jian:jian
}const express = require('express');浏览器端
导出:export 或 export default
导入:import
示例用法
//单个导出
export const TOKEN_ERR = 400;// 批量导出
export{
jia,jian
}
import axios from 'axios'
import {getCookie} from 'api/config'第109题(2019-12-20):面试官:你使用过哪些前端异常处理方式?
- 可疑区域增加 Try-Catch(只能捕获同步函数)
- 全局监控 JS 异常 window.onerror
- 全局监控静态资源异常 window.addEventListener
- 捕获没有 Catch 的 Promise 异常:unhandledrejection
- VUE errorHandler 和 React componentDidCatch
- 监控网页崩溃:window 对象的 load 和 beforeunload
- 跨域 crossOrigin 解决
- 使用badjs监控错误并报告
- node express中使用log4js日志模块
- 使用domain模块
- 使用EventEmitter
为什么出这道题或者说为什么要捕获异常呢?
大家主要平时工作中可能没有重视异常捕获的重要性,觉得程序代码能正常跑就行了,没想过在特殊情况下(比如网络服务器故障,后台返回的数据undefined等等)的异常处理,这也是程序员很重要的一种能力,基于以下几点前端异常捕获非常必要而且重要的:
- 学会异常处理能减少一些常见的bug,避免一处报错影响整个程序的执行;
- 异常处理可以定位、预防、复现问题等;
- 完善的前端方案,前端监控系统,比如线上出问题了,如果没有错误的日志也无从排查问题,笔者在公司的node项目中就是使用log4js日志模块去上报输出错误日志。
所以我简单总结了一下前端异常捕获的一些方式,大家有更好的或者其他的方式也欢迎补充!
第108题(2019-12-19):输入npm install 之后执行了什么操作?
npm install 命令
- npm install 命令用来安装模块到node_module目录中 在安装之前,npm install默认会找到当前路径下的package.json读取依赖信息,具体的可以看看npm官网的介绍,install | npm Documentation。
- 检查node_module目录之中是不是已经存在指定的模块,如果存在,就不再进行安装,即使远程仓库已经有了新版本,也是如此。
- 如果你希望,一个模块不管是否安装过都重新新安装一遍,可以用-f 或者—force参数 。
npm install <packageName> --force- 如果想更新已安装的模块,可以使用npm-update命令,会先远程仓库更新到最新版本,如果本地版本不存在,或者远程仓库已经有最新版本就会安装。
npm update模块的安装进程
- 发出npm install命令 npm 向registry查询模块压缩包的网址 下载压缩包,放在~/.npm目录 解压压缩包到当前项目的node_modules目录 。
- 注意,一个模块安装后,本地其实保存了两份,一份是~/.npm下的压缩包,另一份是node_modules目录下解压后的代码。
- 在npm install运行的时候,只会检查node_modules中的模块,而不会检查/.npm.也就是说,如果在/.npm中有压缩包但是node_modules中没有模块,npm install会从远程仓库再下载一次压缩包。
执行npm install之后的细节
- 执行工程自身的preinstall
- 定义首层依赖模块
- 模块扁平化(dedupe)
- 安装模块
- 执行工程自身生命周期
- 更新版本
由于文章篇幅有限,就不对每一个细节去详解了,感兴趣的可以网上搜集相关资料深究一下,同时推荐一篇阮一峰老师的相关文章,npm 模块安装机制简介。
第107题(2019-12-18):一个TCP 连接可以发多少个 HTTP 请求?
现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接。这样的好处是连接可以被重新使用,之后发送 HTTP 请求的时候不需要重新建立 TCP 连接,以及如果维持连接,那么 SSL 的开销也可以避免,两张图片是我短时间内两次访问 https://www.github.com 的时间统计(注:可在chrome开发者工具Network面板的Timing选项查看此图):
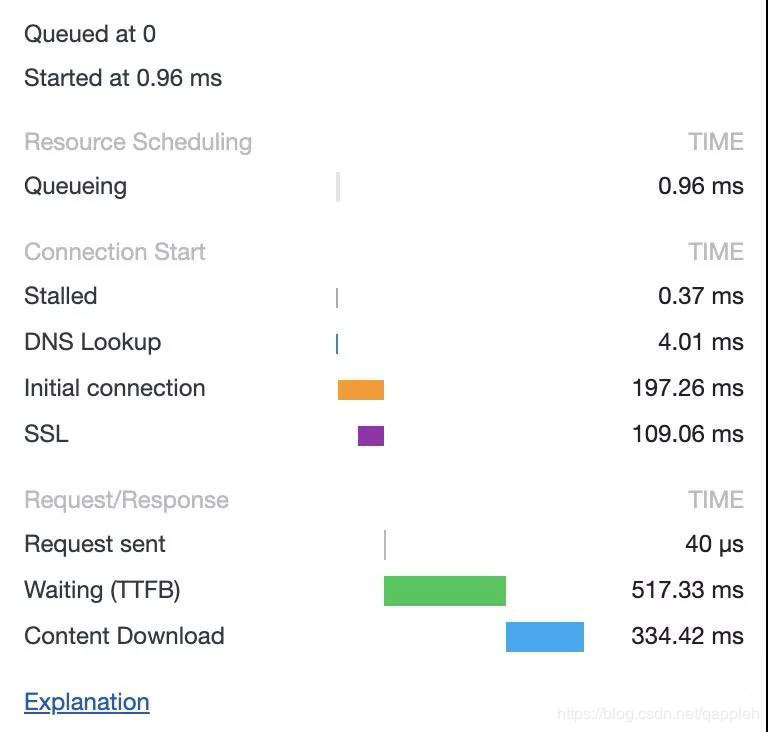
头一次访问,有初始化连接和 SSL 开销

初始化连接和 SSL 开销消失了,说明使用的是同一个 TCP 连接
持久连接:既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
所以如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
第106题(2019-12-17):babel转换es6语法工作原理是什么?
1. 什么是babel ?
Babel 是一个工具链,主要用于将 ECMAScript 2015+ 版本的代码转换为向后兼容的 JavaScript 语法,以便能够运行在当前和旧版本的浏览器或其他环境中。下面列出的是 Babel 能为你做的事情:
- 语法转换
- 通过 Polyfill 方式在目标环境中添加缺失的特性 (通过 @babel/polyfill 模块)
- 源码转换 (codemods)
- 更多! (查看这些 视频 获得启发)
以箭头函数为例:
// Babel 输入: ES2015 箭头函数
[1, 2, 3].map((n) => n + 1);
// Babel 输出: ES5 语法实现的同等功能
[1, 2, 3].map(function(n) {
return n + 1;
});2.Babel的运行原理
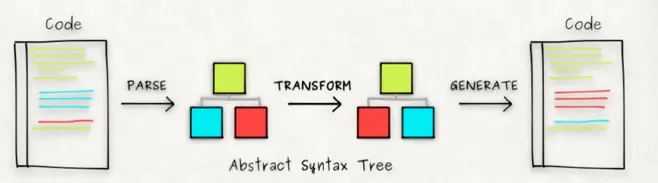
Babel 的编译过程和大多数其他语言的编译器相似,可以分为三个阶段:
- 解析(Parsing):将代码字符串解析成抽象语法树。
- 转换(Transformation):对抽象语法树进行转换操作。
- 生成(Code Generation): 根据变换后的抽象语法树再生成代码字符串。
如下图:
1.解析
解析步骤接收代码并输出 AST。 这个步骤分为两个阶段:词法分析(Lexical Analysis) 和 语法分析(Syntactic Analysis)。
词法分析
词法分析阶段把字符串形式的代码转换为 令牌(tokens) 流。
你可以把令牌看作是一个扁平的语法片段数组:
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
...
]每一个 type 有一组属性来描述该令牌:
{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
},
...
}和 AST 节点一样它们也有 start,end,loc 属性。
语法分析
语法分析阶段会把一个令牌流转换成 AST 的形式。 这个阶段会使用令牌中的信息把它们转换成一个 AST 的表述结构,这样更易于后续的操作。
简单来说,解析阶段就是
code(字符串形式代码) -> tokens(令牌流) -> AST(抽象语法树)Babel 使用 @babel/parser 解析代码,输入的 js 代码字符串根据 ESTree 规范生成 AST(抽象语法树)。Babel 使用的解析器是 babylon。
2.转换
转换步骤接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。 这是 Babel 或是其他编译器中最复杂的过程。
Babel提供了@babel/traverse(遍历)方法维护这AST树的整体状态,并且可完成对其的替换,删除或者增加节点,这个方法的参数为原始AST和自定义的转换规则,返回结果为转换后的AST。
3.生成
代码生成步骤把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)。
代码生成其实很简单:深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
Babel使用 @babel/generator 将修改后的 AST 转换成代码,生成过程可以对是否压缩以及是否删除注释等进行配置,并且支持 sourceMap。
第105题(2019-12-16):有了解过微前端的概念吗?如果要你去设计实施微前端你会怎么做?
1.微前端是什么?
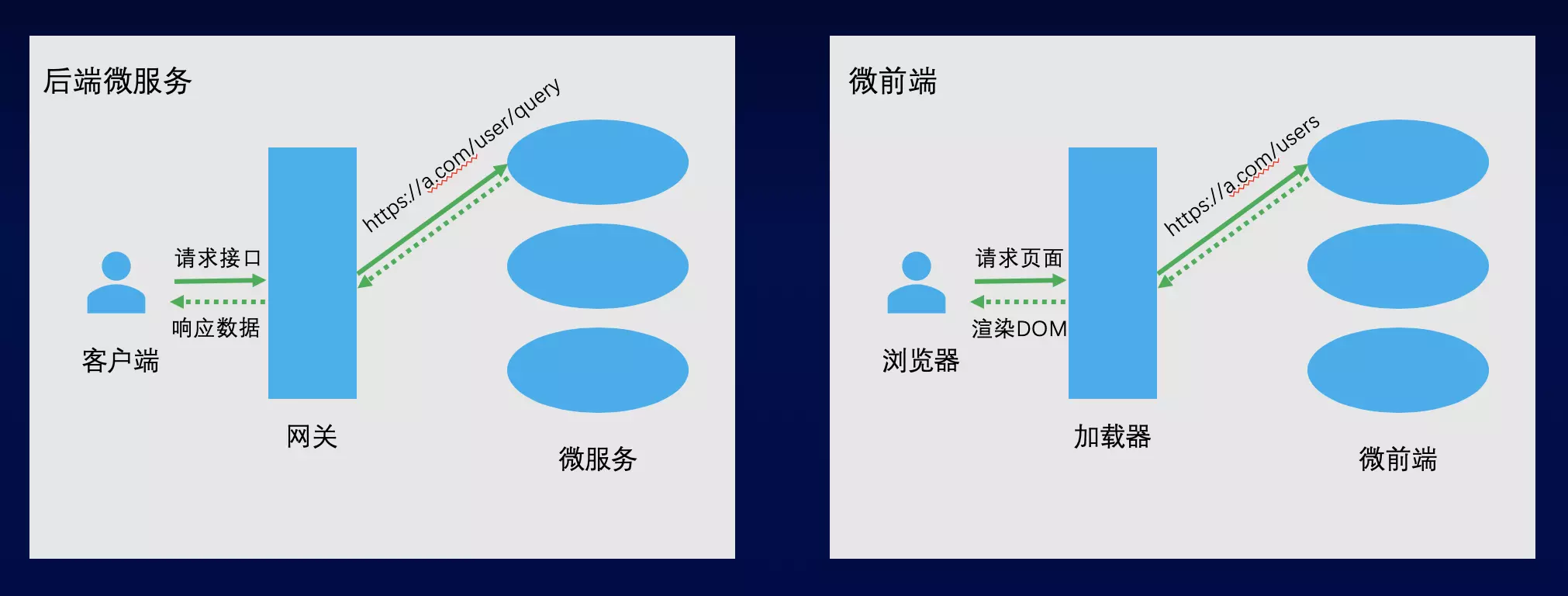
可以跟微服务这么对比着去理解:
| 微服务 | 微前端 |
|---|---|
| 一个微服务就是由一组接口构成,接口地址一般是 URL。当微服务收到一个接口的请求时,会进行路由找到相应的逻辑,输出响应内容。 | 一个微前端则是由一组页面构成,页面地址也是 URL。当微前端收到一个页面 URL 的请求时,会进行路由找到相应的组件,渲染页面内容。 |
| 后端微服务会有一个网关,作为单一入口接收所有的客户端接口请求,根据接口 URL 与服务的匹配关系,路由到对应的服务。 | 微前端则会有一个加载器,作为单一入口接收所有页面 URL 的访问,根据页面 URL 与微前端的匹配关系,选择加载对应的微前端,由该微前端进行进行路由响应 URL。 |
这里要注意跟 iframe 实现页面嵌入机制的区别。微前端没有用到 iframe,它很纯粹地利用 JavaScript、MVVM 等技术来实现页面加载。后面我们将介绍相关的技术实现。
2.实施微前端的六种方式
微前端架构是一种类似于微服务的架构,它将微服务的理念应用于浏览器端,即将 Web 应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。
由此带来的变化是,这些前端应用可以独立运行、独立开发、独立部署。以及,它们应该可以在共享组件的同时进行并行开发——这些组件可以通过 NPM 或者 Git Tag、Git Submodule 来管理。
注意:这里的前端应用指的是前后端分离的单应用页面,在这基础才谈论微前端才有意义。
微前端架构一般可以由以下几种方式进行:
- 使用 HTTP 服务器的路由来重定向多个应用
- 在不同的框架之上设计通讯、加载机制,诸如 Mooa 和 Single-SPA
- 通过组合多个独立应用、组件来构建一个单体应用
- iFrame。使用 iFrame 及自定义消息传递机制
- 使用纯 Web Components 构建应用
- 结合 Web Components 构建
关于微前端可以给大家推荐一本书,电子版点击即可,《前端架构:从入门到微前端》。
最后
- 欢迎加我微信(RHB_1223),拉你进web全栈学习打卡群,每天一道题,补齐自己的知识盲区,进阶高级资深前端!每日一题github主页:每日一题
- 欢迎关注「深圳湾码农】,做持续学习的技术人,回复“1“获取web全栈学习资料等!
- 年底了,为感谢读者的关注与阅读,特意在年底搞了一个抽奖送书活动,希望自己能在2020年写出更多的好文章回馈读者,也希望广大读者开发朋友们2020年更上一层楼,公众号回复“抽奖”即可参与抽书活动。

