前言
k-nearest neighbor,k-NN
bagging集成学习思想。(k个训练数据,每个都会给出一个label,我们对此进行投票决定)
解决分类问题
通过欧式距离(或者其他指标,比如余弦距离)计算距离相似度,距离越小,相似度越高。
连续型特征,类别型特征不行(比如性别男女,血型A,B,AB,O),因为类别型特征无法计算距离
数据归一化(最小最大归一化,标准化)
把数据分为训练集和测试集。
通过训练数据来训练模型,其实就是确定k的取值,当k取什么值的时候,模型在训练数据集上和测试数据集上分类的效果都很好,及训练误差和泛化误差都很小。
训练数据集合的误差叫做训练误差,测试数据集合的误差叫做泛化误差。
泛化误差大,就是泛化能力差。
投票机制vote:对新数据分类的时候,采用的投票机制,及相似度最大的前k个训练数据的类别的众数。
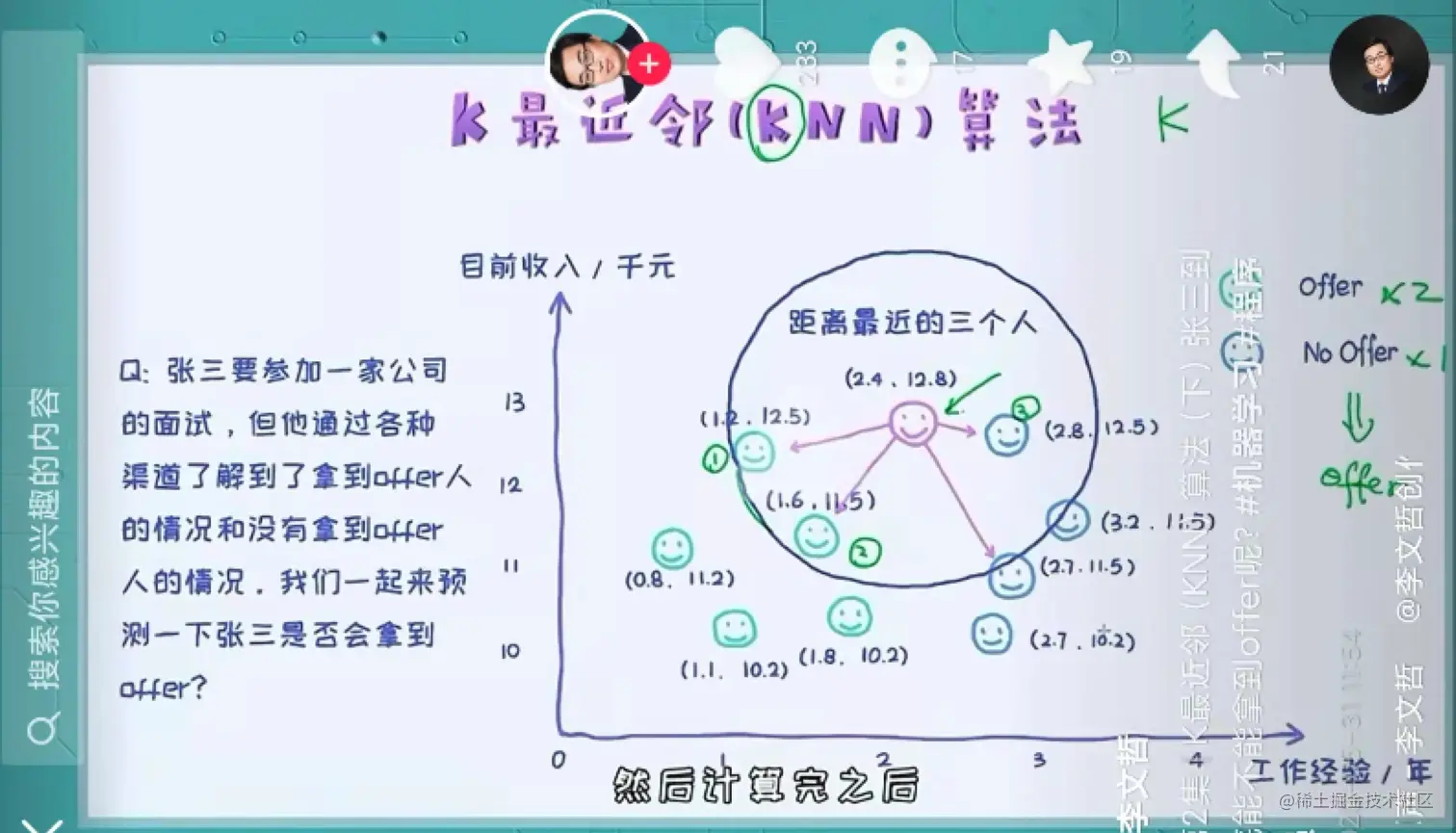
knn算法最重要的3个因素是:
1.K值的选择
2.距离度量的方法,欧式距离,余弦距离等都是可以衡量距离(相似度)的指标。
3.分类决策规则,是采用平等投票机制,还是加权投票机制。
1/简介
knn-近邻算法(k-nearest neighbor,k-NN)是一种分类算法,该算法较为简单。
它的工作原理是:
存在一个已知类别的数据集合,可以看作是基准数据集。
输入没有类别的新数据,将新数据与基准数据集中的每一条数据计算欧式距离,
然后选择出距离最小的前k条基准数据(有类别)
这就是k-近邻算法中k的出处,通常k是不大于20的整数。
最后,选择k个最相似数据中出现次数最多的类别,作为新数据的类别。
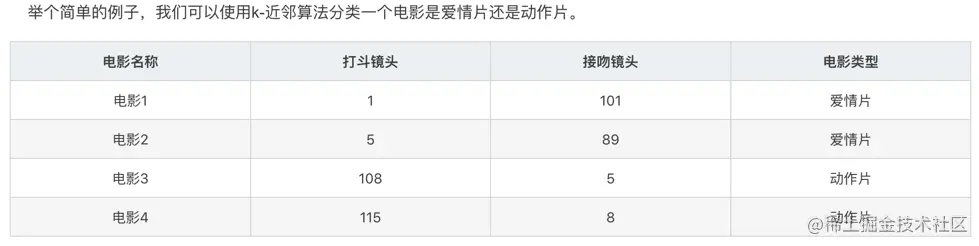
上图就是我们已知类别的基准数据集。这个数据集合有两个特征,打斗镜头和接吻镜头。
除此之外,我们也知道每个电影的所属类型。
用肉眼粗略地观察,接吻镜头多的,是爱情片。打斗镜头多的,是动作片。
如果现在给我一部电影,告诉我这个电影打斗镜头数和接吻镜头数这2个特征
不告诉我这个电影类型,我可以根据你给我的信息进行判断,这个电影是属于爱情片还是动作片。
而k-近邻算法也可以像我们人一样做到这一点,不同的地方在于,我们的经验更"牛逼",而k-邻近算法是靠已有的数据。
比如,你告诉我这个电影打斗镜头数为2,接吻镜头数为102,我的经验会告诉你这个是爱情片,k-近邻算法也会告诉你这个是爱情片。
你又告诉我另一个电影打斗镜头数为49,接吻镜头数为51,我"邪恶"的经验可能会告诉你,这有可能是个"爱情动作片",画面太美,我不敢想象。
但是k-近邻算法不会告诉你这些,因为在它的眼里,电影类型只有爱情片和动作片。
它会提取样本集合中特征最相似数据(最邻近)的分类标签,得到的结果可能是爱情片,也可能是动作片,但绝不会是"爱情动作片"。
当然,这些取决于数据集的大小以及最近邻的判断标准等因素。
k值不宜太大,也不宜太小,否则都不准确
2/距离度量
如下图所示,怎么判断红色圆点标记的电影所属的类别呢?
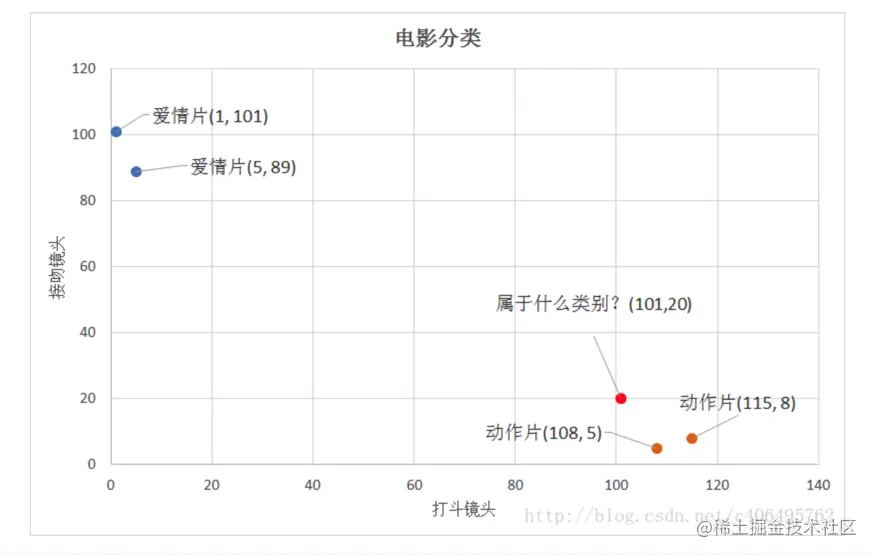
我们可以从散点图大致推断,这个红色圆点标记的电影可能属于动作片,因为距离已知的两个动作片的圆点更近。
k-近邻算法用什么方法进行判断呢?
没错,就是距离度量。
这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用我们高中学过的两点距离公式计算距离,计算红点与其他4个点之间的距离,然后选出距离最小的k个点
通过计算,我们可以得到如下结果:
红点->动作片(108,5)的距离约为16.55
红点->动作片(115,8)的距离约为18.44
红点->爱情片(5,89)的距离约为118.22
红点->爱情片(1,101)的距离约为128.69
通过计算可知,红色圆点标记的电影到动作片 (108,5)的距离最近是16.55。
如果直接根据这个结果,判断该红色圆点标记的电影为动作片,这个算法就是‘最’近邻算法,而非k-近邻算法。
那么k-邻近算法是什么呢?
k-近邻算法步骤如下:
计算红点与其他各个点的距离(也就是与基准数据集中的其他各个点的欧式距离)
按照距离从小到大排序(及相似度从大到小排序)
选取与红点距离最小的k个点,这就是k的出处
确定前k个点所在类别的出现频率
返回前k个点所出现频率最高的类别作为红点的预测分类
4/举一反三
约会网站配对效果判定
海伦女士一直使用在线约会网站寻找适合自己的约会对象。
尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。
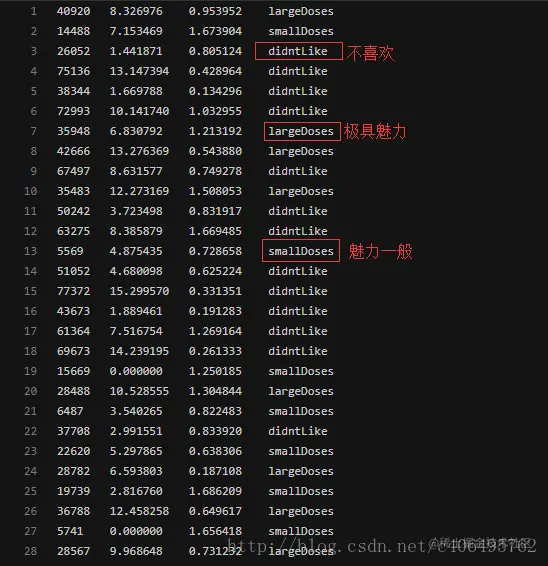
经过一番总结,她发现自己交往过的人可以进行如下分类(这就是标签):
<1>不喜欢的人
<2>魅力一般的人
<3>极具魅力的人
海伦挑选适合自己的约会人选,主要看3个特征:
<1>每年飞行的里程数
<2>玩视频游戏所消耗时间百分比
<3>每周消费的冰淇淋公升数
数据归一化
在数据集合中,我们看到这3个特征的量纲差别很大,但海伦认为这三个特征是同等重要的。
因此作为三个等权重的特征之一,飞行里程数并不应该如此严重地影响到计算结果。
在处理这种不同取值范围的特征时,我们通常采用归一化,将取值范围处理为0到1或者-1到1之间。
下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
newValue = (oldValue - min) / (max - min)
其中min和max分别是数据集中的最小特征值和最大特征值。
虽然改变数值取值范围增加了分类器的复杂度,但为了得到准确结果,我们必须这样做。
在kNN_test02.py文件中编写名为autoNorm的函数,用该函数自动将数据归一化。
分类器建设完之后,需要检验该分类器的准确率,把数据集合分成2部分,80
检查这20


