

netty是什么
Netty是一个异步事件驱动的网络应用程序框架 用于快速开发可维护的高性能协议服务器和客户端。
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
使用场景
Dubbo RocketMQ Zookeeper Hadoop Spring-Cloud-Gateway 大数据、微服务、游戏、直播、IM、物联网等
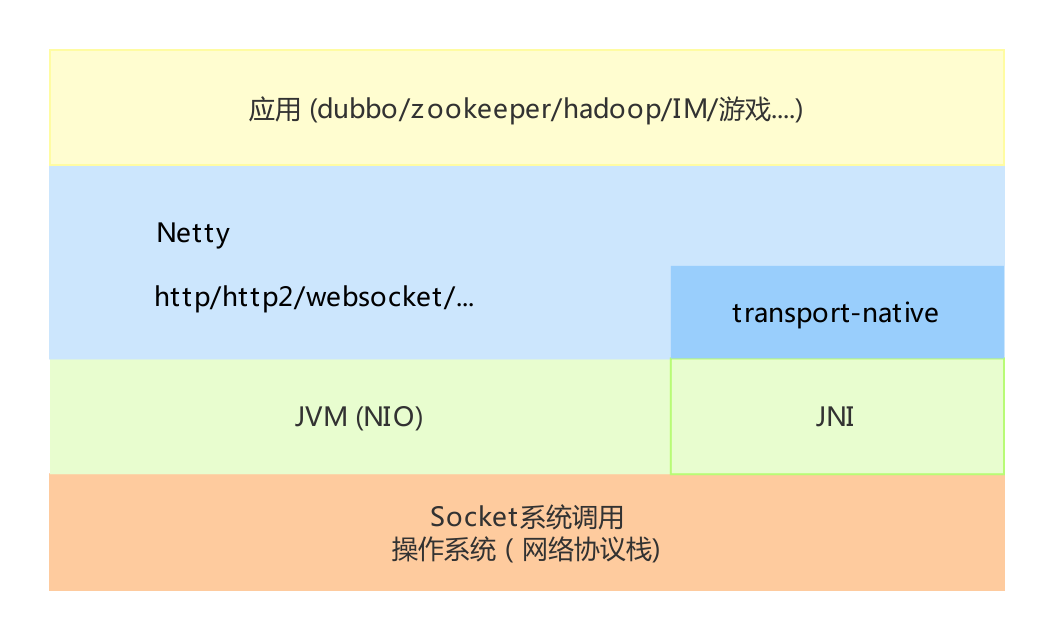
netty的特性
- 不同类型传输层统一的API封装
- 基于灵活且可扩展的事件模型,可以清晰地分离关注点
- 异步非阻塞
- 高度可定制的线程模型
- 内置多种编解码功能,支持多种主流协议
- 高性能(高吞吐量、低延迟、更少的资源占用和不必要的内存copy)
- 没有额外的依赖,Netty 4.x JDK6 is enough
- 完整的SSL/TLS和StartTLS支持
功能模块
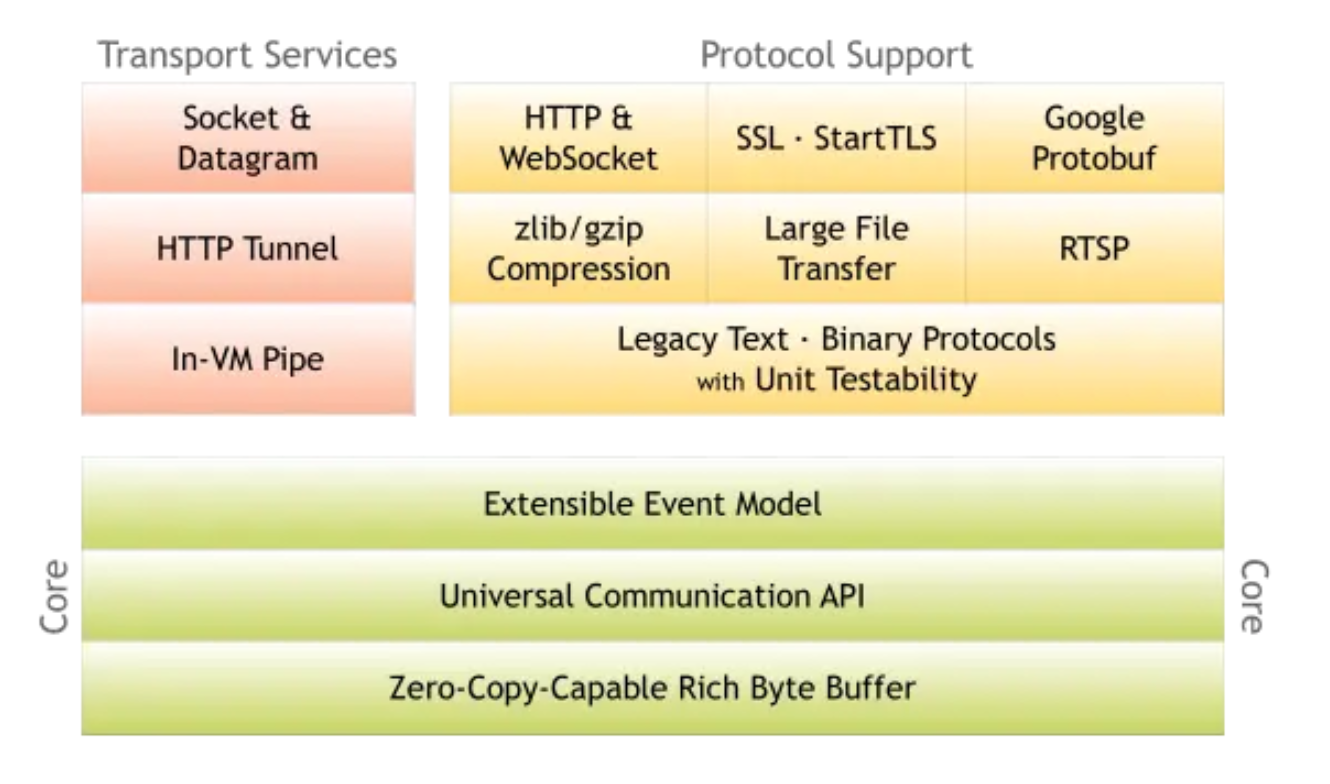
- Core核心模块 灵活且可扩展的事件模型 统一的传输层API 零拷贝的字节缓冲区
- Transport Services Sokect/Datagram (tcp/udp) HTTP Tunnel (Http隧道代理) In-VM Pipe (JVM进程内通信)
- Protocol Support Http/WebSocket/RTSP (应用层协议) SSL/StartTLS (传输层安全加密) Google Protocol Buffer (高效的数据存储格式) zlib/gizp Compression (数据压缩算法) Large File Transfer (大文件传输)
netty使用
Server示例


示例说明
ServerMain
- 创建bossGroup和workerGroup事件循环处理组
- NioEventLoopGroup包含多个NioEventLoop
- NioEventLoop对应一个线程循环,一个Selector,处理IO事件
- bossGroup 处理接收连接请求,创建通道 (一个线程)
- workerGroup 处理通道IO读写事件 (机器核心数 * 2)
- 创建serverHandler和loggingHandler事件处理器
- 通过ServerBootstrap进行server端配置,采用门面模式,封装内部细节,简化使用
- 设置事件循环处理组 bossGroup & workerGroup
- 设置通道实现类 NioServerSocketChannel
- 设置通道配置项 ChannelOption.SO_BACKLOG (监听连接请求的队列大小)
- 设置父通道事件处理器
- 设置子通道事件处理器
- ChannelPipeline channel管道,和Channel一一对应
- ChannelPipeline 维护通道上行以及下行操作处理器链条
- 绑定指定端口 异步操作,返回ChannelFuture (可设置回调)
- 等待Channel关闭
- 优雅关闭事件循环处理组
EchoServerHandler
- @ChannelHandler.Sharable 声明该Handler无状态,可用于多个Channel的处理
- ChannelInboundHandlerAdapter 通道上行(被动)事件处理适配器,子类可以只实现自己关心的事件处理方法
- channelRead 从通道读取到数据时调用,将读取的数据写回到缓冲区 ctx.write
- channelReadComplete 从通道读取数据完毕时调用,将缓冲区的数据写到通道上 ctx.flush
- exceptionCaught I/O异常或者Handler内部处理异常调用,关闭通道 ctx.close()
Client示例


原理解析
套接字
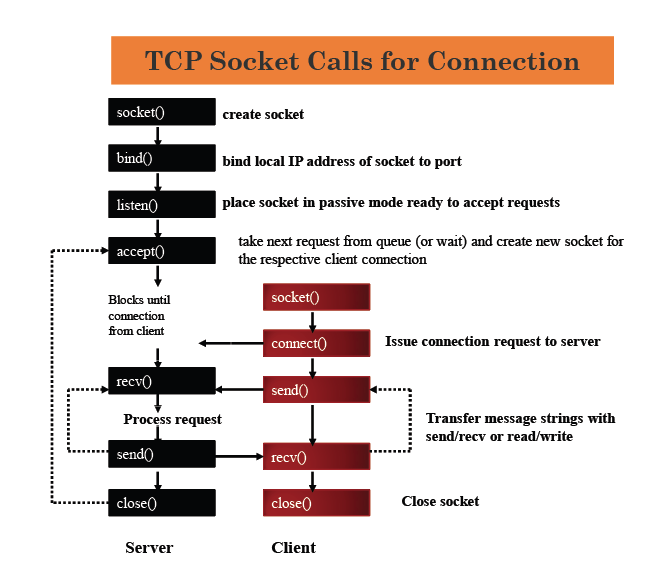
Linux操作系统为了方便开发者进行网络编程,封装了一系列称为套接字 ( sockets ) 统调用 ( system call ),支持阻塞与非阻塞模式,并且借助 ( I/O Multiplexing ) I/O 多路复用 ( select/poll/epoll ) 能够开发出高性能的网络应用程序。
I/O 多路复用
I/O多路复用允许进程同时监听多个文件描述符,这样进程就可以知道哪些文件描述符存在I/O就绪了。
- select 监听的文件描述符不能超过1024
- select 和 poll 存在性能问题
- 每次调用时,内核会对传入的文件描述符数组都检查一遍,记录其中有哪些文件描述符存在I/O就绪(修改数组),这个过程中,数据就会在用户态和内核态直接来回拷贝,增加额外开销
- epoll 由 epoll_create、epoll_ctl、epoll_wait一组系统调用组成,内部使用红黑树记录进程所要监听的文件描述符(及其要监听的事件),使用双向链表记录有哪些文件描述符已经就绪了
- epoll_create()初始化epoll实例
- epoll_ctl()负责增加、删除或修改红黑树上的节点
- epoll_wait()则负责返回双向链表中就绪的文件描述符(及其事件)
- ep_poll_callback() 当监听的 fd 有对应事件发生则触发该回调,将该 fd 加到双向列表中,并唤醒由于epoll_wait()阻塞的用户进程
NIO相关概念
Java体系中的网络编程则是NIO,屏蔽了底层的差异,提供了一套统一的API。
- ServerSocketChannel 面向流(tcp连接)的用于监听sockets且可被select的通道(server端)
- SocketChannel 面向流(tcp连接)可被select的通道(client/server端)
- Selector 可被select通道的多路复用器
- SelectionKey 记录SelectableChannel和Selector之间关系的对象,由SelectableChannel.register()方法返回
- ByteBuffer 字节缓冲区以及之上的一组操作,用于在通道读写操作是传递数据
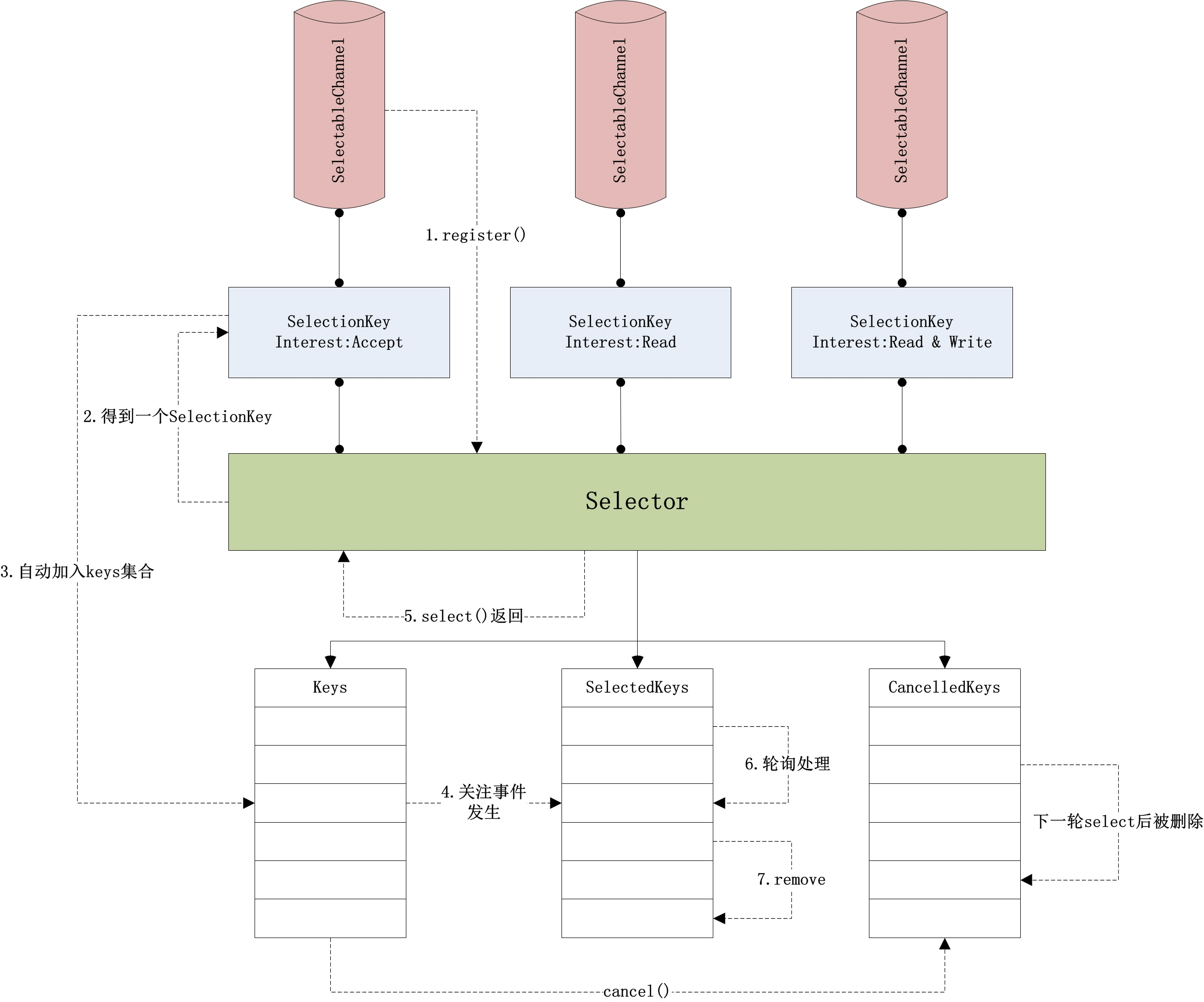
SelectableChannel是一类可以与Selector进行配合的通道,例如Socket相关通道以及Pipe产生的通道都属于SelectableChannel。这类通道可以将自己感兴趣的操作(例如read、write、accept和connect)注册到一个Selector上,并在Selector的控制下进行IO相关操作。
Selector是一个多路复用器,它负责管理已注册的多个SelectableChannel,当这些通道的某些状态改变时,Selector会被唤醒(从select()方法的阻塞中),并对所有就绪的通道进行轮询操作。
SelectionKey是一个用来记录SelectableChannel和Selector之间关系的对象,它由SelectableChannel的register()方法返回,并存储在Selector的多个集合中。它不仅记录了两个对象的引用,还包含了SelectableChannel感兴趣的操作,即OP_READ,OP_WRITE,OP_ACCEPT和OP_CONNECT。
Selector对象包含三个SelectionKey集合,分别是keys集合,存储了所有与Selector关联的SelectionKey对象;selectedKeys集合,存储了在一次select()方法调用后,所有状态改变的通道关联的SelectionKey对象;cancelledKeys集合,存储了一轮select()方法调用过程中,所有被取消但还未从keys中删除的SelectionKey对象。 其中最值得关注的是selectedKeys集合,它使用Selector对象的selectedKeys()方法获得,并通常会进行轮询处理。
Selector 对应多个 SelectableChannel SelectableChannel 对应一个 Selector SelectionKey 与 SelectableChannel 一一对应
借助Selector,应用程序即可使用少量的线程资源来管理大量的socket连接
线程模型
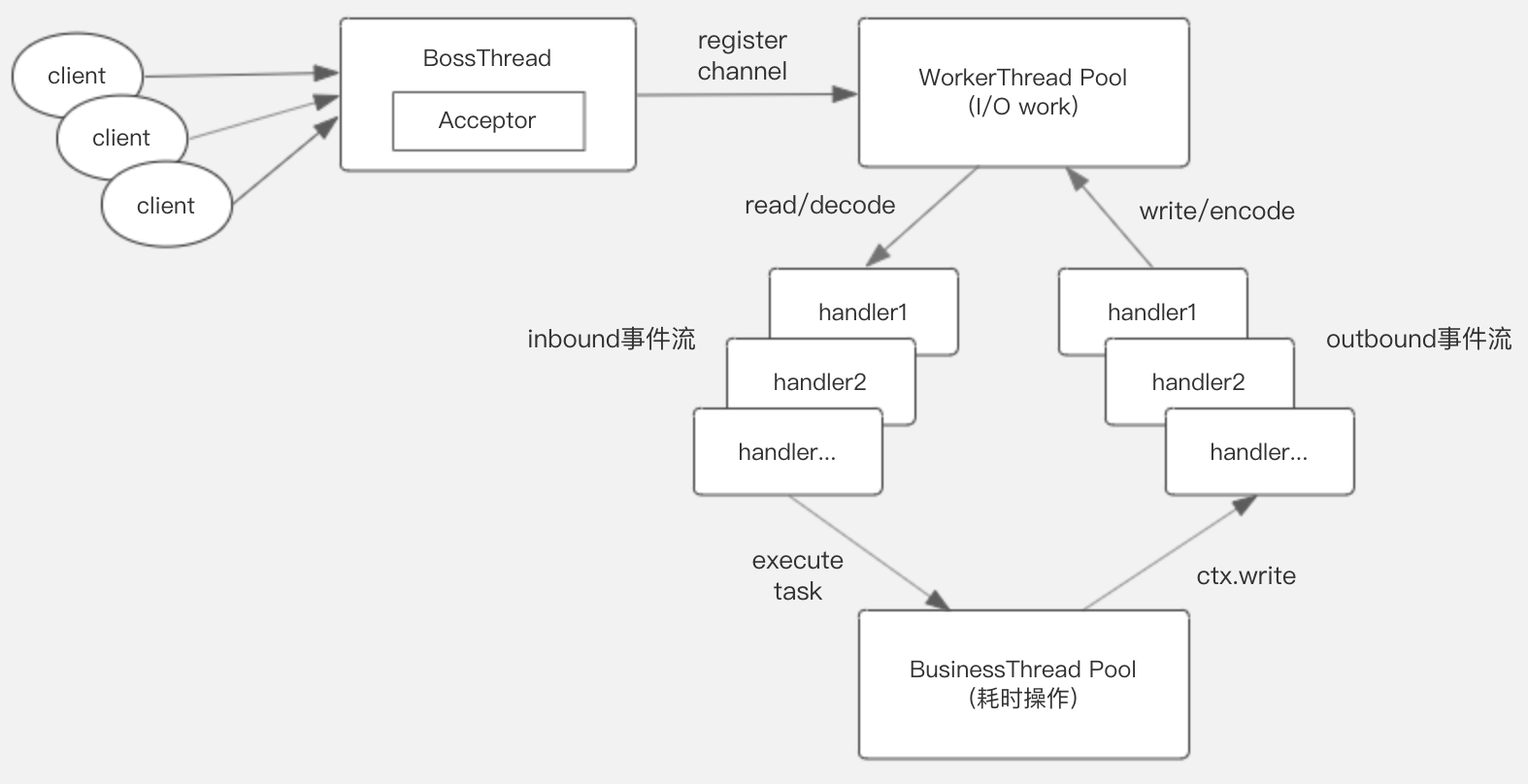
Boss线程监听端口,监听连接请求,将建立的通道channel注册分发到Worker线程。一个Boss线程,可以监听多个端口,当然也可设置多个Boss线程来并发监听多个端口。
Worker线程处理通道Channel的读写操作,以及 数据的编码与解码操作,但是涉及耗时的业务逻辑处理,比如读写数据库,需要由独立的业务线程池处理,避免占用I/O线程读写数据。
主要类图
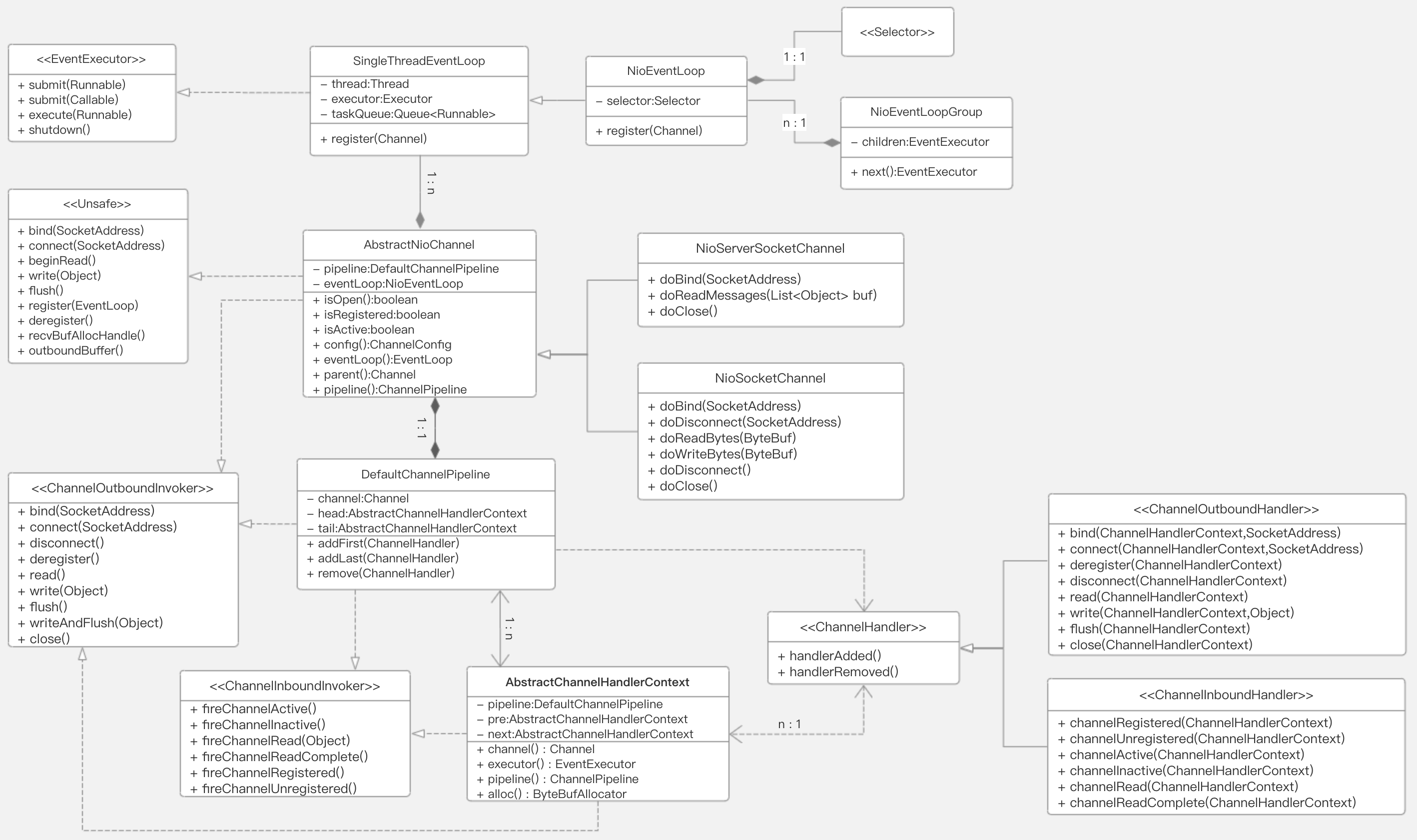
NioEventLoopGroup包含多个NioEventLoop,每个NioEventLoop表示单个线程的EventExecutor,内部维护一个待执行队列,关联多路复用器Selector,内部线程负责处理NIO事件和执行任务。
NioServerSocketChannel 和 NioSocketChannel 是对Java NIO的 ServerSocketChannel 和 SocketChannel的封装,内部包含其实例,都继承自AbstractNioChannel,并且实现了Unsafe(内部channel方法)和ChannelOutboundInvoker(下行事件触发/主动操作)接口。
DefaultChannelPipeline是Netty事件管道的默认实现,内部维护 head表示头结点 和 tail表示尾节点的双向链表,每个节点都是一个ChannelHandlerContext实例,ChannelHandlerContext关联着一个ChannelHandler(channel事件处理器)。Channel通道的上行事件 和 下行事件 都会通过 ChannelPipeline,就将内部复杂的处理逻辑分离,开发者只需要关注相应的事件即可 (关注点分离/责任链模式)。
ChannelPipeline与Handler
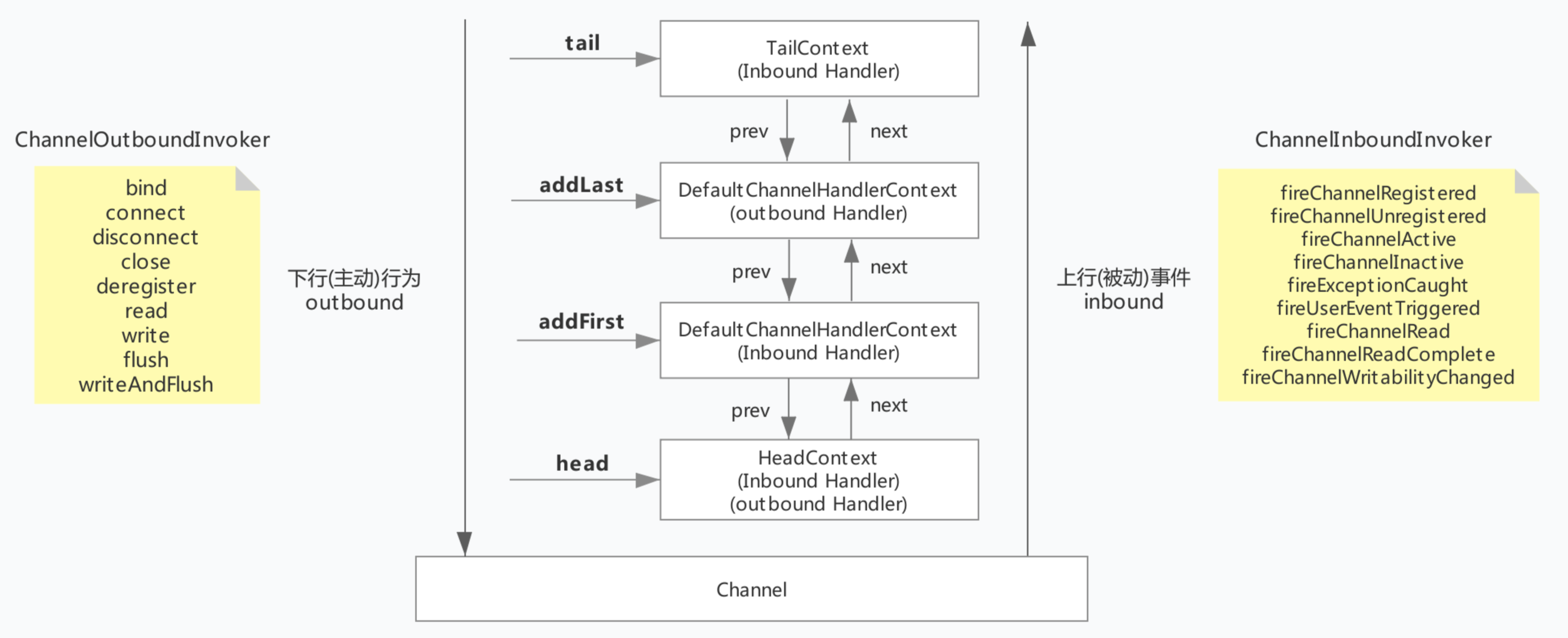
ChannelPipeline是ChannelHandler的编排管理容器,它内部维护了一个ChannelHandler的链表和迭代器,可以方便地实现ChannelHandler的查找、添加、替换和删除。消息经过ChannelPipeline在ChannelHandler中的处理流程
ChannelPipeline p = ...;
p.addLast("1", new InboundHandlerA());
p.addLast("2", new InboundHandlerB());
p.addLast("3", new OutboundHandlerA());
p.addLast("4", new OutboundHandlerB());
p.addLast("5", new InboundOutboundHandlerX());
inbound event order : 1, 2, 5 outbound action order : 5, 4, 3
ChannelHandler
- 无状态的ChannelHandler可以使用单例,即多个channel共享一个,减少对象创建,如LoggingHandler,用@ChannelHandler.Sharable标记
- 有状态的ChannelHandler,每个channel不能共享,各自拥有一个handler实例(大部分的业务handler都是有状态)
在实际业务场景中,ChannelPipeline通常需要添加如下几类ChannelHandler。
- 协议解码ChannelHandler
- 协议编码ChannelHandler
- 业务逻辑执行ChannelHandler
对于耗时的业务逻辑执行,例如访问数据库、中间件、第三方系统等,则需要切换到业务线程池中,避免阻塞Netty的NioEventLoop线程,导致消息无法接收和发送。
server端启动流程
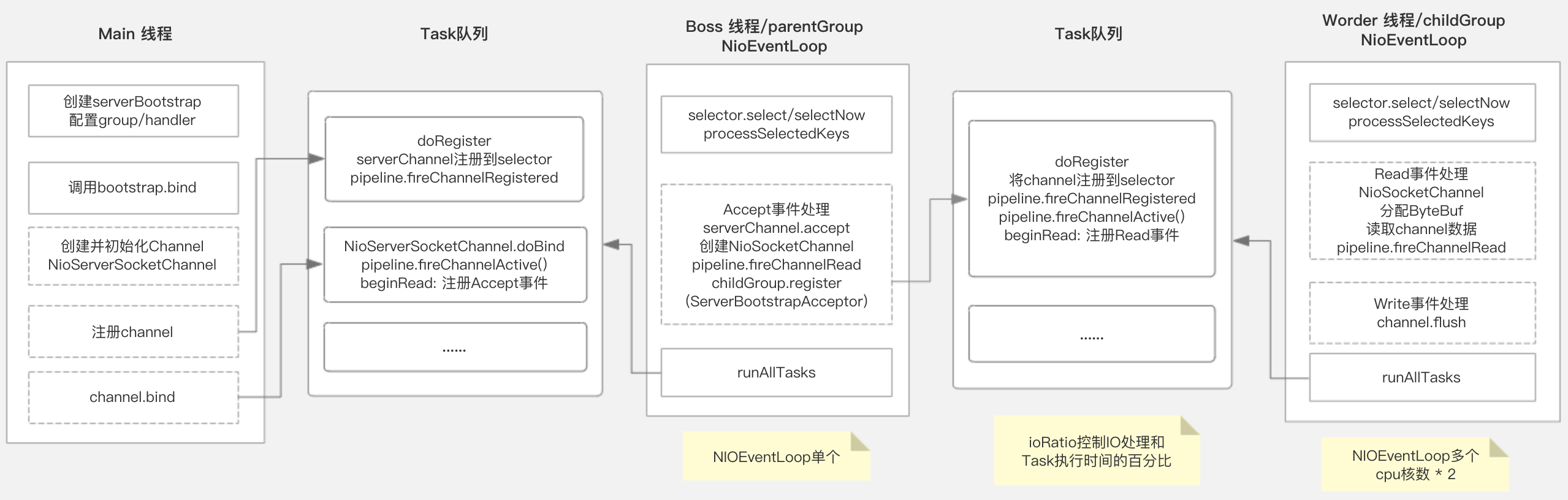
Main线程
- 创建ServerBootstrap,配置EventLoopGroup及Handler
- 调用ServerBootstrap绑定指定端口
- 创建并初始化NioServerSocketChannel
- 将serverChannel注册到bossGroup
- 将register和bind操作加入到bossGroup任务队列中
Boss线程
- 执行register任务
- 将serverChannel注册到Selector
- 调用pipeline.fireChannelRegistered通知链路
- 执行bind任务
- 调用serverChannel.doBind监听指定端口
- 调用pipeline.fireChannelActive通知链路
- 注册SelectKey感兴趣事件为Accept
- 处理Accept事件
- 调用serverChannel.accept
- 创建NioSocketChannel
- 调用pipeline.fireChannelRead(NioSocketChannel) 通知链路
- 调用childGroup.register 注册NioSocketChannel
- 将register操作加入到childGroup任务队列中
Worker线程
- 执行register任务
- 将channel注册到Selector
- 调用pipeline.fireChannelRegistered通知链路
- 调用pipeline.fireChannelActive通知链路
- 注册SelectKey感兴趣事件为Read
- 处理Read事件
- 分配ByteBuf
- 读取channel数据
- 调用pipeline.fireChannelRead(ByteBuf) 通知链路
- 处理Write事件
- channel.flush 触发真正写数据
client端启动流程
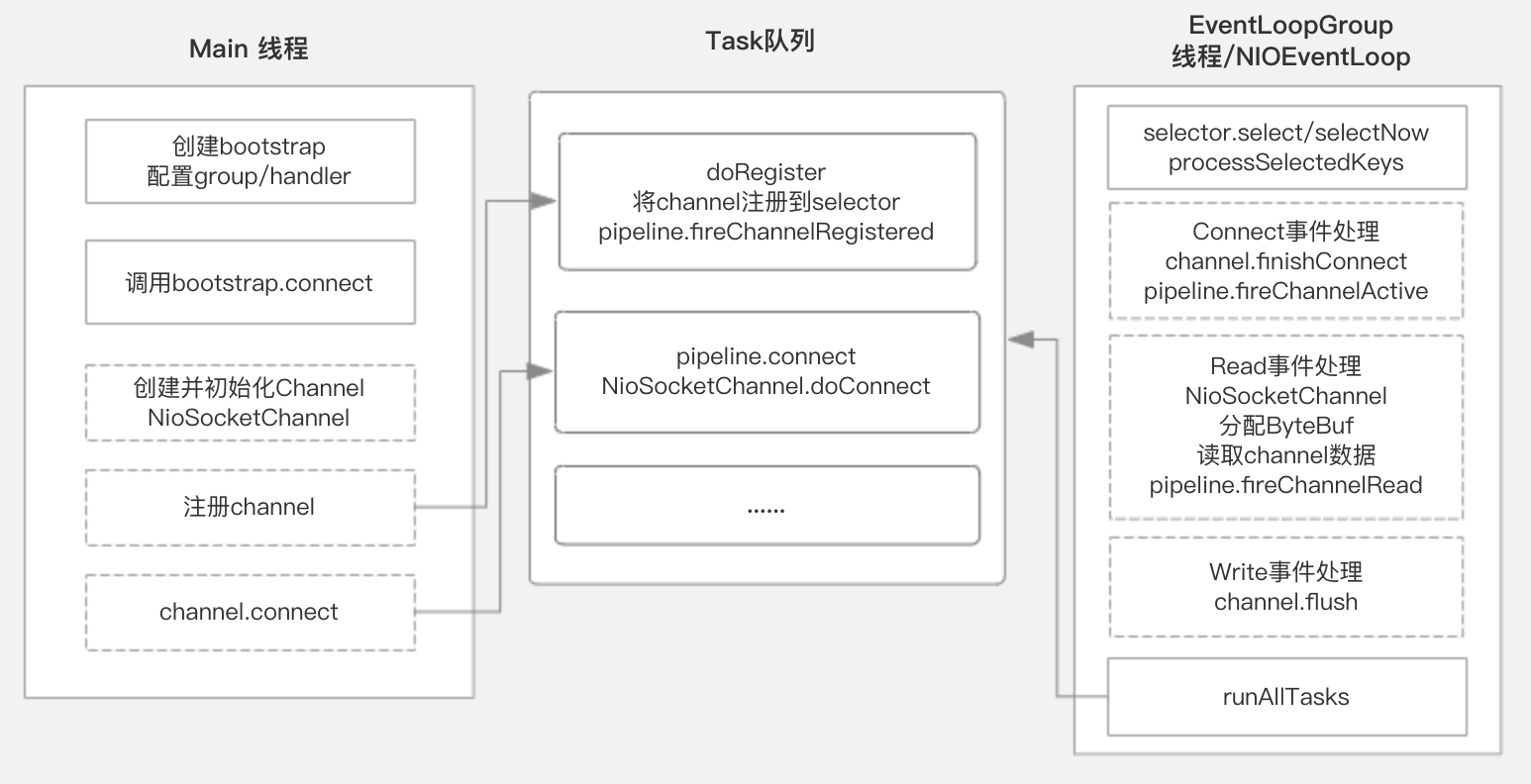
Main线程
- 创建Bootstrap,配置EventLoopGroup及Handler
- 调用ServerBootstrap绑定指定端口
- 创建并初始化NioSocketChannel
- 将channel注册到group
- 将register和connect操作加入到group任务队列中
Worker线程
- 执行register任务
- 将channel注册到Selector
- 调用pipeline.fireChannelRegistered通知链路
- 执行connect任务
- 调用NioSocketChannel.doConnect 与指定地址建立连接
- 处理Connect事件
- NioSocketChannel.doFinishConnect完成连接
- 调用pipeline.fireChannelActive通知链路
- 注册SelectKey感兴趣事件为Read
- 处理Read事件
- 分配ByteBuf
- 读取channel数据
- 调用pipeline.fireChannelRead(ByteBuf) 通知链路
- 处理Write事件
- channel.flush 触发真正写数据
数据读流程
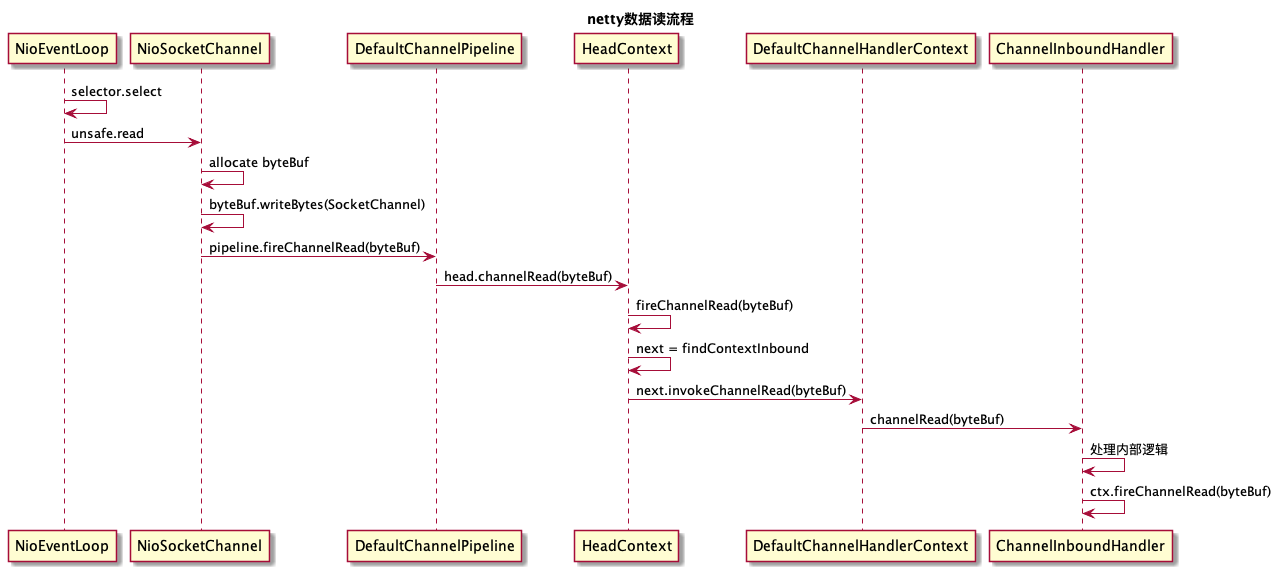
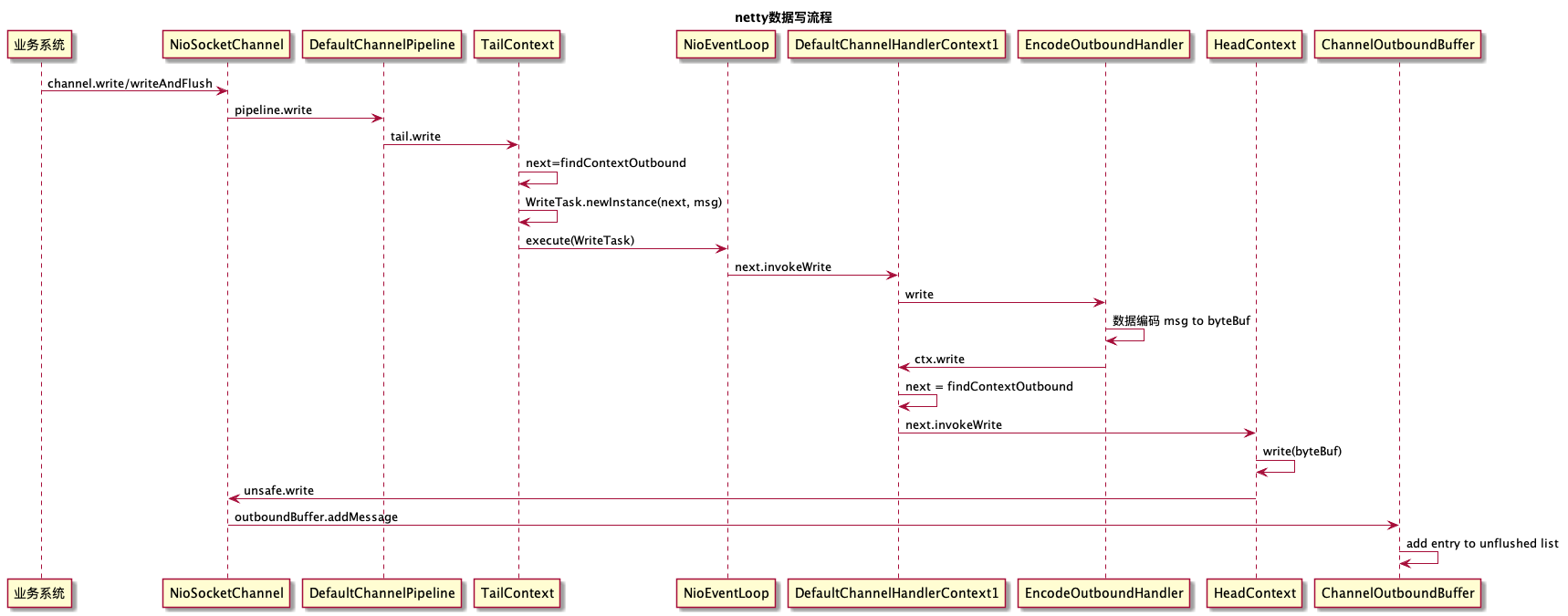
数据写流程
业务调用write方法后,经过ChannelPipeline职责链处理,消息被投递到发送缓冲区待发送,调用flush之后会执行真正的发送操作,底层通过调用Java NIO的SocketChannel进行非阻塞write操作,将消息发送到网络上
为了尽可能地提升性能,Netty采用了串行无锁化设计,在I/O线程内部进行串行操作,避免多线程竞争导致性能下降
ChannelOutboundBuffer
ChannelOutboundBuffer是Netty的发送缓冲队列,它基于链表来管理待发送的消息
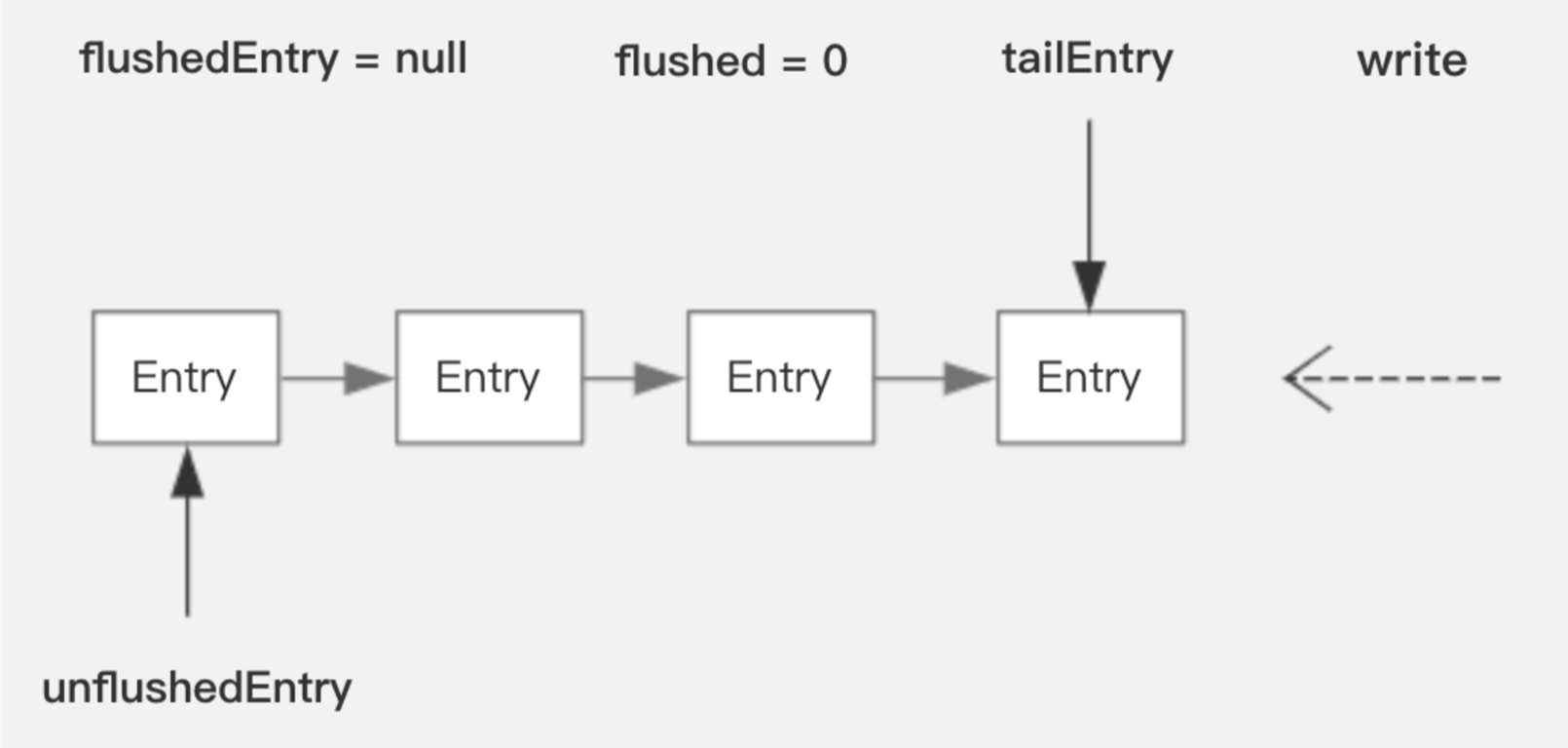
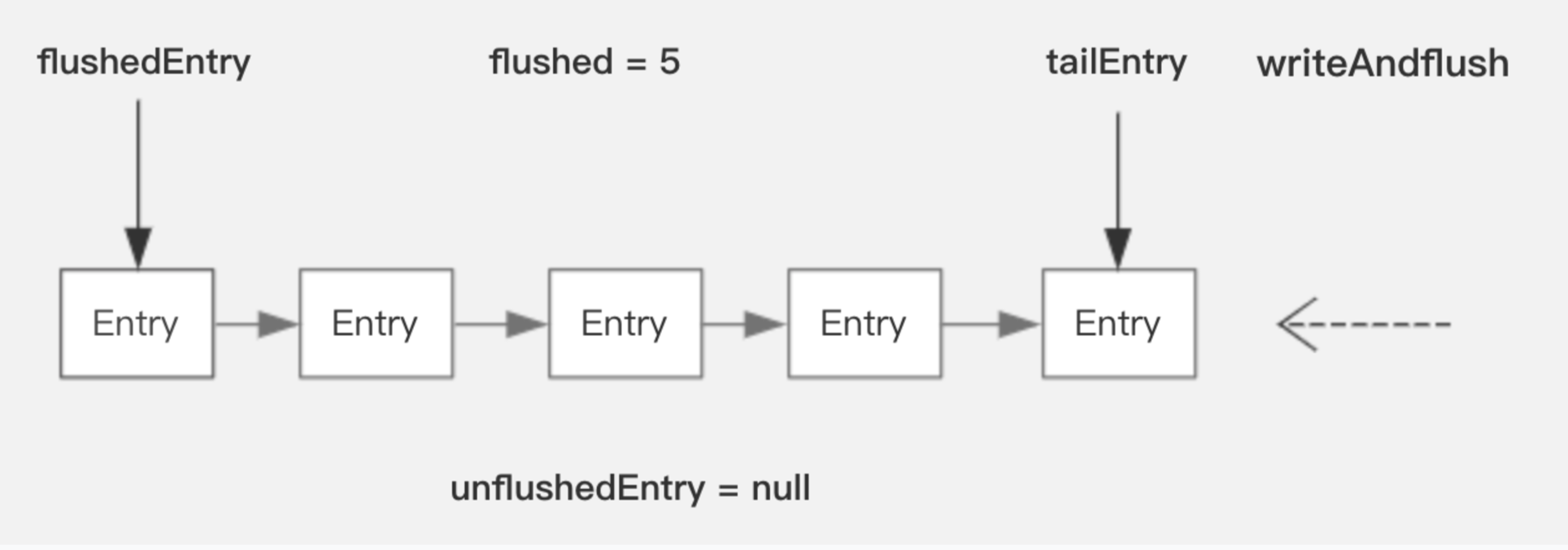
当调用write时只是将数据对象加入到链表尾部,并不会触发数据写 当调用writeAndFlush/flush 或者 channel通道Write事件触发时,就会进行数据真正写操作doWrite。
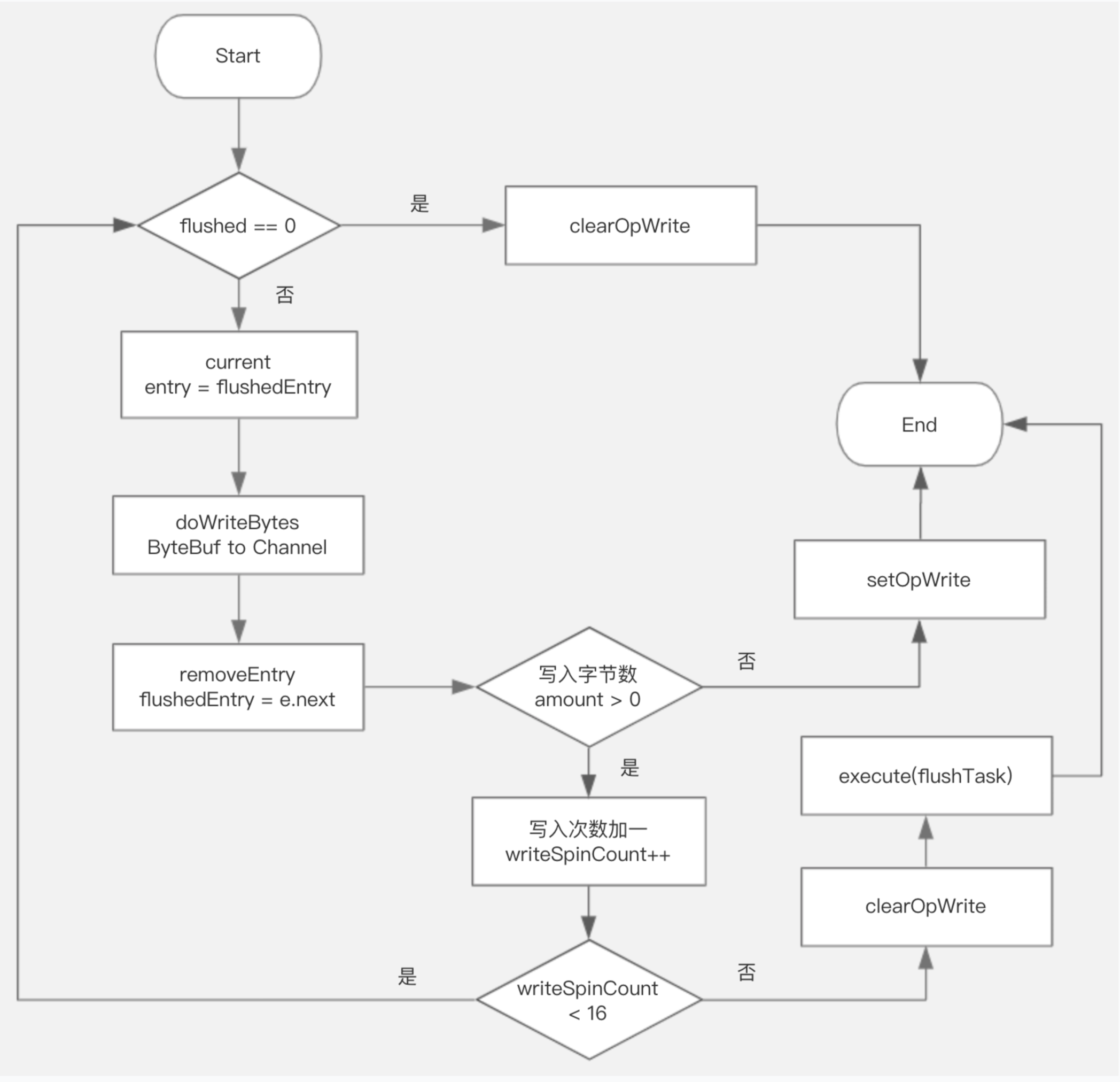
数据真正写流程
- 当没有数据可写时,说明是通道Write事件触发,所以需要clearOpWrite,即取消监听通道写事件;结束
- 获取当前节点(flushedEntry),将ByteBuf写入到Channel,如果ByteBuf数据写入完毕则删除当前节点(flushedEntry指针右移);继续
- 写入字节数 <=0,表示写入缓存区已满,则需要setOpWrite,等待下一个Write事件;结束
- 将writeSpinCount加一,若writeSpinCount < 16 ;继续
- writeSpinCount >= 16 表示不可再写,要让出线程资源,clearOpWrite取消监听通道写事件,同时向当前通道的I/O线程的任务队列加入flushTask稍后再调用
消息发送高低水位控制 当消息队列中积压的待发送消息总字节数到达高水位时,标记Channel的状态为不可写(并非真正不可写),调用ChannelPipeline发送通知事件fireChannelWritabilityChanged,业务可以监听该事件及时获取链路可写状态。在业务中合理利用该机制,避免发送队列积压严重,提升系统的可靠性
常用Handler
粘包/拆包
假设客户端向服务端连续发送了两个数据包,用packet1和packet2来表示,那么服务端收到的数据可以分为三种: 第一种情况,接收端正常收到两个数据包,即没有发生拆包和粘包的现象。

第二种情况,接收端只收到一个数据包,但是包含了发送端发送的两个数据包的信息,这种现象即为粘包。这种情况由于接收端不知道这两个数据包的界限,所以对于接收端来说很难处理。

第三种情况,这种情况有两种表现形式,如下图。接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。这两种情况如果不加特殊处理,对于接收端同样是不好处理的。

发生TCP粘包、拆包主要是由于下面一些原因:
- 应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包
- 应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包
- 进行MSS(最大报文长度)大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包
- 接收方法不及时读取套接字缓冲区数据,这将发生粘包
解决方案通常有三种:
- 消息固定长度(不推荐)
- 使用定界符分隔消息
- 使用长度字段来定义消息的长度(推荐)
ByteToMessageDecoder
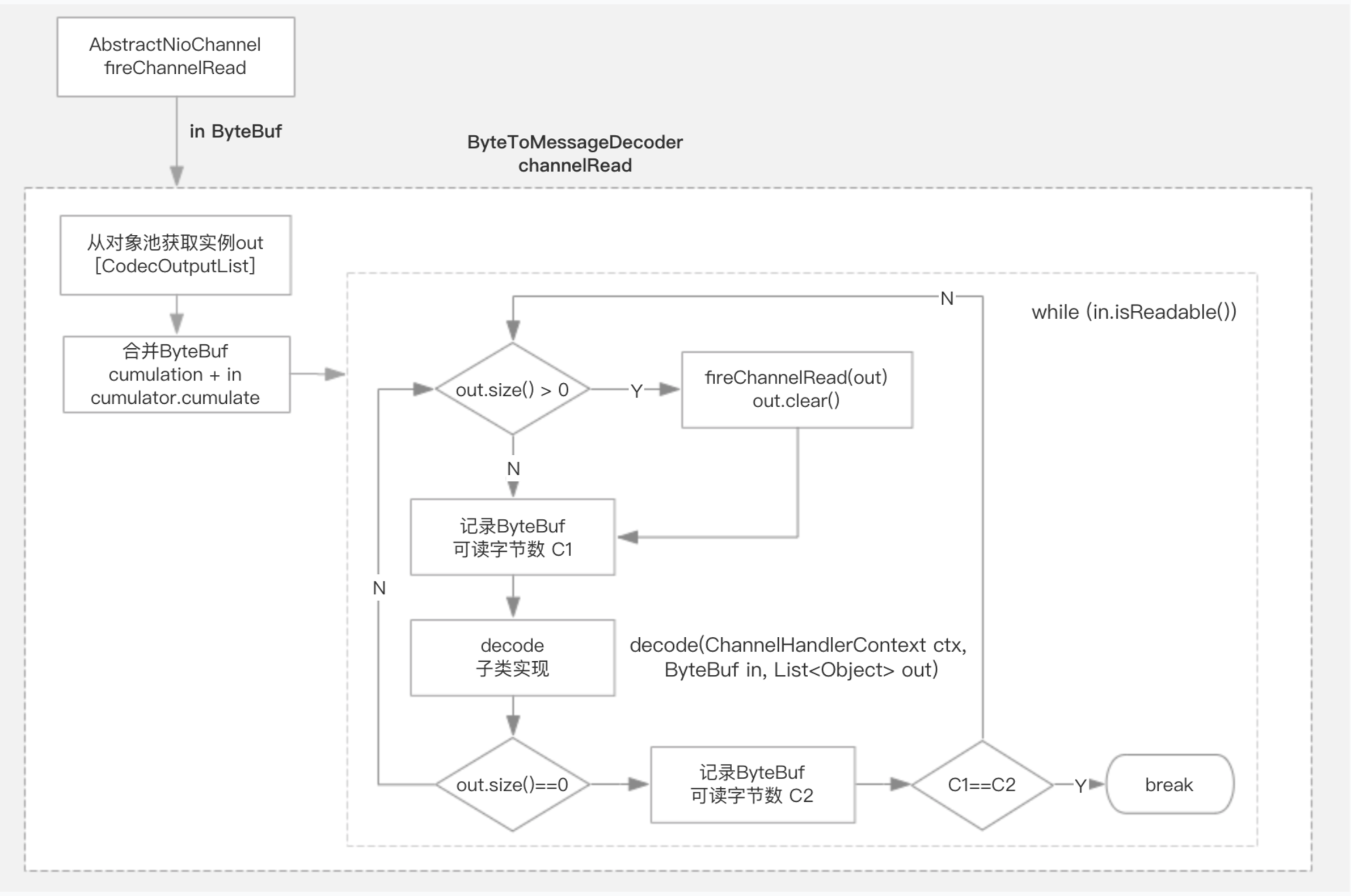
为了解决粘包、拆包的问题,Netty使用模板方法的设计模式,提供了抽象类 ByteToMessageDecoder,其内部封装了数据解码细节,子类只需要decode方法即可。ByteToMessageDecoder继承自ChannelInboundHandlerAdapter,主要实现了channelRead方法来解析读取的数据ByteBuf。
数据解析过程:
- 从对象池获取out实例(CodecOutputList)
- 将新读取的in 与 累计的cumulation 进行合并
- while (in.isReadable()) 处理解析数据
- out.size > 0 fireChannelRead(msg) 通知链路处理
- 调用子类decode方法 (将读取的数据转换成多个消息对象)
- 前后可读字节数未变化 并且 out.size未发生变化 则退出循环 (表明读取数据不够一个消息)
- 回收out对象到对象池
注意点
- 子类decode方法 处理读取数据时,应先判断是否满足要求的大小,不满足时不应该改动ByteBuf的readerIndex
- ByteToMessageDecoder 属于有状态的Handler,不可共享,每个Channel通道对应一个实例
/**
* 将读取的数据转换成多个消息对象
* @param ctx 此Handler所属的ChannelHandlerContext
* @param in 要读取的数据ByteBuf
* @param out 要解析成的对象列表
* @throws Exception is thrown if an error occurs
*/
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;
FixedLengthFrameDecoder
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
Object decoded = null;
if (in.readableBytes() >= frameLength) {
decoded = in.readRetainedSlice(frameLength);
}
if (decoded != null) {
out.add(decoded);
}
}
DelimiterBasedFrameDecoder
使用定界符来分隔消息,比如\r\n
LengthFieldBasedFrameDecoder
使用消息中表示长度字段来定义消息的长度
WebSocket13FrameDecoder
WebSocket的协议格式

WebSocket的解析过程
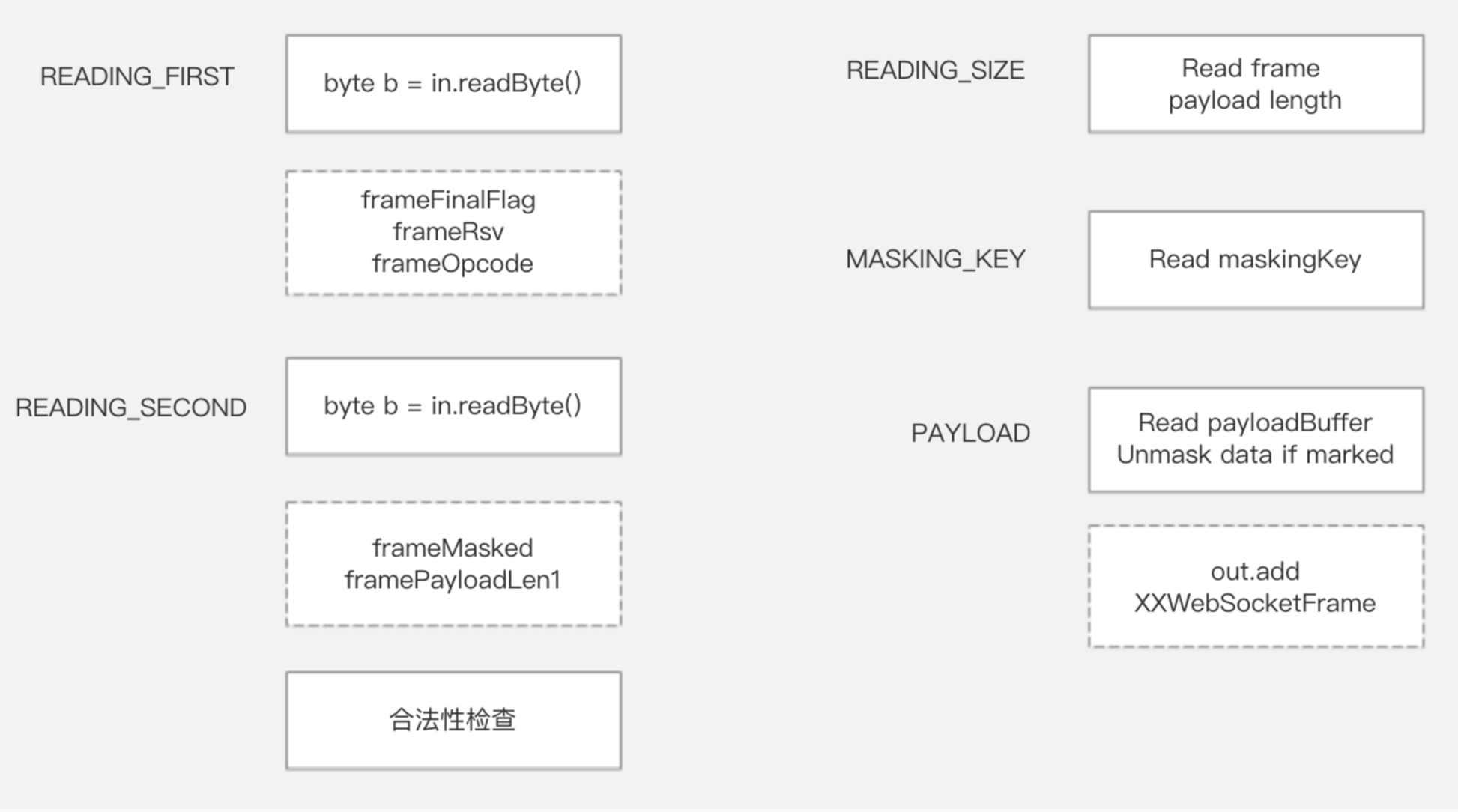
计算framePayloadLength示例:
if (framePayloadLen1 == 126) {
if (in.readableBytes() < 2) {
return;
}
framePayloadLength = in.readUnsignedShort();
if (framePayloadLength < 126) {
protocolViolation(ctx, in, "invalid data frame length (not using minimal length encoding)");
return;
}
} else if (framePayloadLen1 == 127) {
if (in.readableBytes() < 8) {
return;
}
framePayloadLength = in.readLong();
if (framePayloadLength < 65536) {
protocolViolation(ctx, in, "invalid data frame length (not using minimal length encoding)");
return;
}
} else {
framePayloadLength = framePayloadLen1;
}
常见的使用方式
- pipeline.addLast(new XxxProtocolEncoder());
- pipeline.addLast(new XxxProtocolDecoder());
- pipeline.addLast(new BusinesHandler());
字节缓冲区 (数据容器)
ByteBuf
Netty提供了两个指针变量用于支持顺序读取read()和写入write()操作:readerIndex用于标识读取索引,writerIndex用于标识写入索引。两个位置指针将ByteBuf缓冲区划分为三部分.
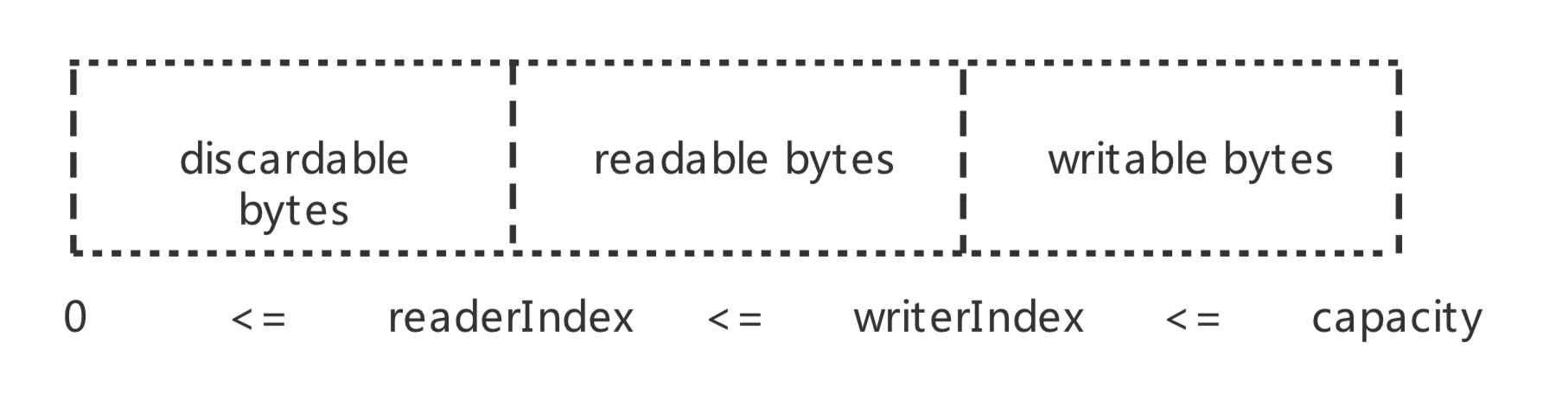
顺序读写 read write 调用ByteBuf的read操作时,从readerIndex处开始读取。从readerIndex到writerIndex的空间为可读的字节缓冲区;从writerIndex到capacity的空间为可写的字节缓冲区;从0到readerIndex的空间是已经读取的缓冲区,可以调用discard操作来重用这部分空间,以节约内存,防止ByteBuf不断扩张。
随机读写 get set 可以随机指定读写的索引位置, ByteBuf会对其索引和长度等进行合法性校验,内部不会更改readerIndex和writerIndex,需要使用者自己控制。另外,set操作与write操作不同的是,它不支持动态扩展缓冲区,所以使用者必须保证当前的缓冲区可写的字节数大于需要写入的字节数,否则会抛出数组或者缓冲区越界异常。
注意事项
- ByteBuf的线程并发安全问题,特别要防止Netty NioEventLoop线程与应用线程并发操作ByteBuf。
- ByteBuf的申请和释放,避免忘记释放、重复释放,以及释放之后继续访问。(Netty某些场景下内部会隐式释放,当应用继续访问或者释放时就会发生异常)
引用计数
Netty4开始引入了引用计数的特性,缓冲区的生命周期可由引用计数管理,当缓冲区不再有用时,可快速返回给对象池或者分配器用于再次分配,从而大大提高性能,进而保证请求的实时处理。
引用计数两个基本规则
- 对象的初始引用计数为1
- 引用计数为0的对象不能再被使用,只能被释放
在代码中,可以使用retain()使引用计数增加1,使用release()使引用计数减少1,这两个方法都可以指定参数表示引用计数的增加值和减少值。当我们使用引用计数为0的对象时,将抛出异常。
谁负责释放对象 通用的原则是:谁最后使用含有引用计数的对象,谁负责释放或销毁该对象。一般来说,有以下两种情况:
- 一个发送组件将引用计数对象传递给另一个接收组件时,发送组件无需负责释放对象,由接收组件决定是否释放。
- 一个消费组件消费了引用计数对象并且明确知道不再有其他组件使用该对象,那么该消费组件应该释放引用计数对象。
派生缓冲区 通过duplicate(),slice()等等生成的派生缓冲区ByteBuf会共享原生缓冲区的内部存储区域。此外,派生缓冲区并没有自己独立的引用计数而需要共享原生缓冲区的引用计数。也就是说,当我们需要将派生缓冲区传入下一个组件时,一定要注意先调用retain()方法。
另外,实现ByteBufHolder接口的对象与派生缓冲区有类似的地方:共享所Hold缓冲区的引用计数,所以要注意对象的释放。在Netty,这样的对象包括DatagramPacket,HttpContent和WebSocketframe。
内存池
在API Gateway、RPC和流式处理框架中,请求和响应消息往往是“朝生熄灭”的,特别是频繁地申请和释放大块byte数组,会加重GC的负担及加大CPU资源占用率,通过内存池技术重用这些临时对象,可以降低GC频次和减少耗时,同时提升系统的吞吐量。
- GC回收或者引用队列回收效率不高,难以满足高性能的需求
- 缓冲区对象还需要尽可能的重用,避免创建大量短暂对象
Netty的内存池整体上参照jemalloc实现,能够快速分配/回收内存,减少内存碎片,对多核友好,具有可伸缩性的内存分配器
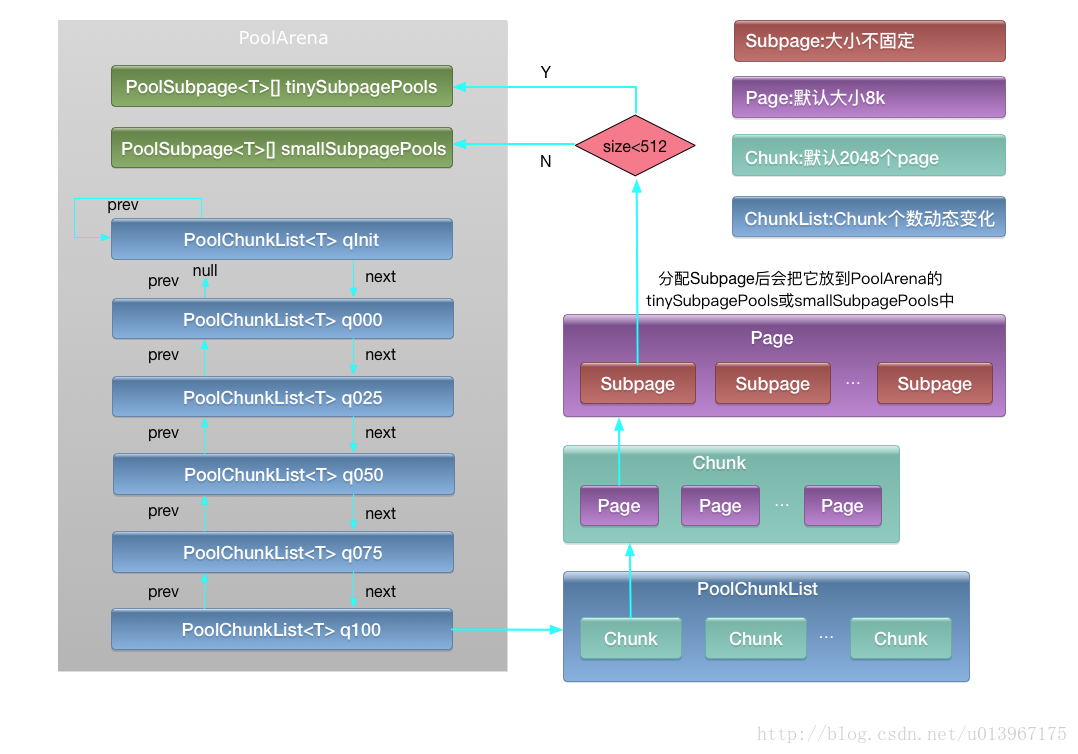
PooledArena:代表内存中一大块连续的区域,PoolArena由多个Chunk组成,每个Chunk由多个Page组成。为了提升并发性能,内存池中包含一组PooledArena,一个PooledArena对应一个或多个I/O线程。
一个PoolArena内存块是由两个SubPagePools(用来存储零碎内存)和多个ChunkList组成,两个SubpagePools数组分别为tinySubpagePools (<512)和smallSubpagePools(<pageSize=8k)每个ChunkList里包含多个Chunk按照双向链表排列,每个Chunk里包含多个Page(默认2048个),每个Page(默认大小为8k字节)由多个Subpage组成。
每个ChunkList里包含的Chunk数量会动态变化,比如当该chunk的内存利用率变化时会向其它ChunkList里移动。
内存分配过程
内存分配的入口是PooledByteBufAllocator.buffer,先从Recycler对象池中获取复用的PooledByteBuf对象,再为PooledByteBuf分配内存,最终内存的分配工作被委托给PoolArena:
- 分配内存大小进行normalizeCapacity处理 (当size>=512时,size成倍增长,即512->1024->2048,而size<512则是从16开始,每次加16字节)
- 分配内存大小为 tiny 和 small大小
- 从线程缓存PoolThreadCache分配 tiny 和 small大小的内存,分配成功则返回
- 从PoolArena的tinySubpagePools 和 smallSubpagePools 分配 tiny 和 small大小的内存,分配成功则返回
- 从PoolChunk分配 (按照一定顺序选择 PoolChunkList 中的chunk)(锁定PoolArena)
- 分配内存大小 不大于 chunkSize(16M)
- 从线程缓存PoolThreadCache,分配成功则返回
- 从PoolChunk分配 (按照一定顺序选择 PoolChunkList 中的chunk)(锁定PoolArena)
- 分配内存大小 大于 chunkSize
- 直接在池外分配 allocateHuge (直接创建非池化的Chunk来分配,并且该Chunk不会放在内存池中重用)
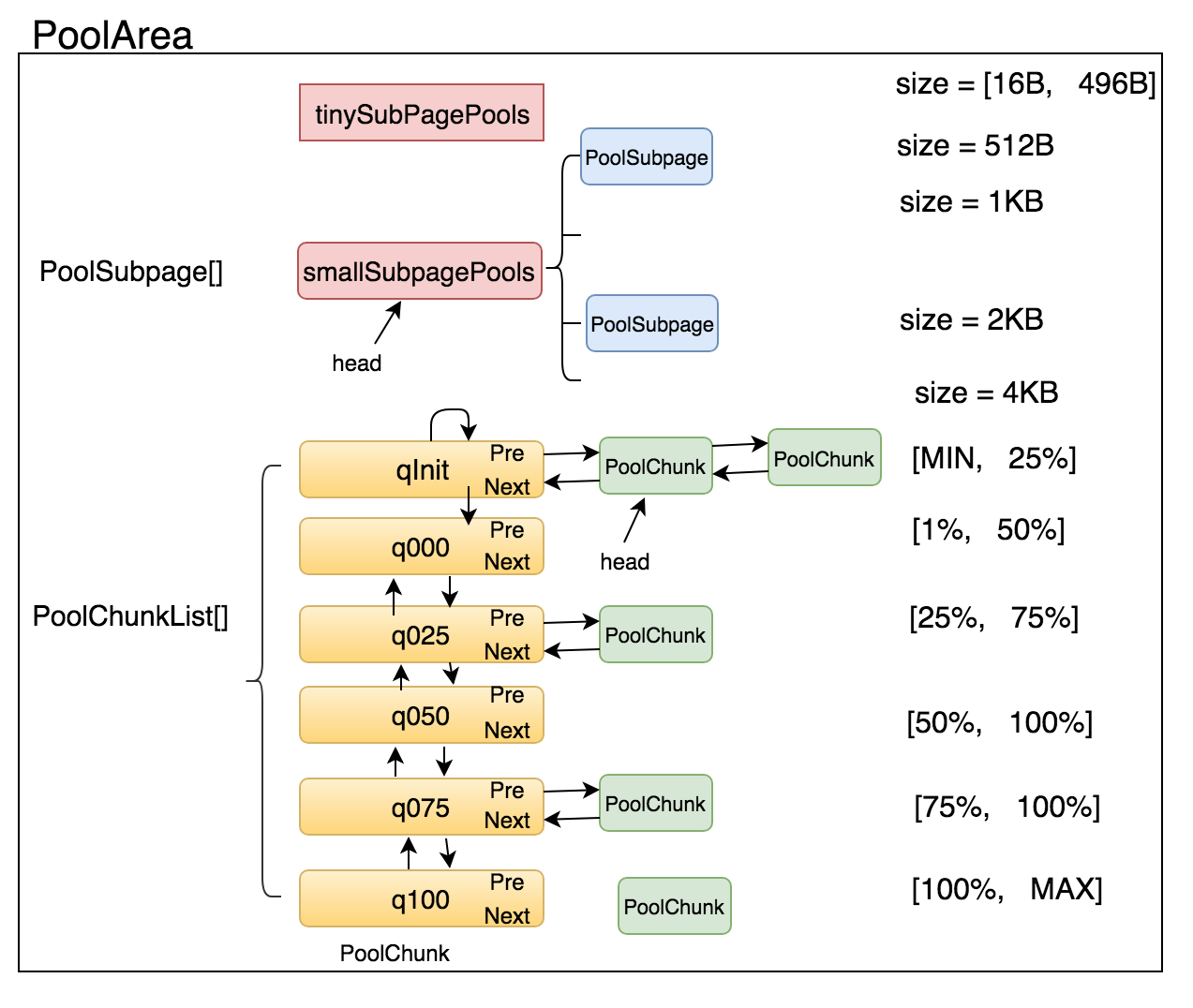
**PoolArena tiny 和 small ** tinySubpagePools 与 smallSubpagePools 一开始都是没有数据的,随着 PoolChunk的分配,不足一个pageSize的内存分配,则被等份切分为多个subpage,然后加入到对应的SubpagePools
tinySubpagePools 数组大小 = 32 ,内存分配范围 = [16 - 496],步幅 = 16 smallSubpagePools 数组大小 = 4,内存分配范围 = [512/1K/2K/4K] 可以通过normCapacity 来 计算 subpage 数组的索引 idx
PoolChunkList PoolArena 通过多个不同PoolChunkList 表示不同内存利用率的chunk列表,使用的顺序:q050、q025、q000、qInit、q075 (提供利用率的同时,增加分配成功的概率)
- qInit:存储内存利用率0-25%的chunk
- q000:存储内存利用率1-50%的chunk
- q025:存储内存利用率25-75%的chunk
- q050:存储内存利用率50-100%的chunk
- q075:存储内存利用率75-100%的chunk
- q100:存储内存利用率100%的chunk
PoolChunk的分配过程
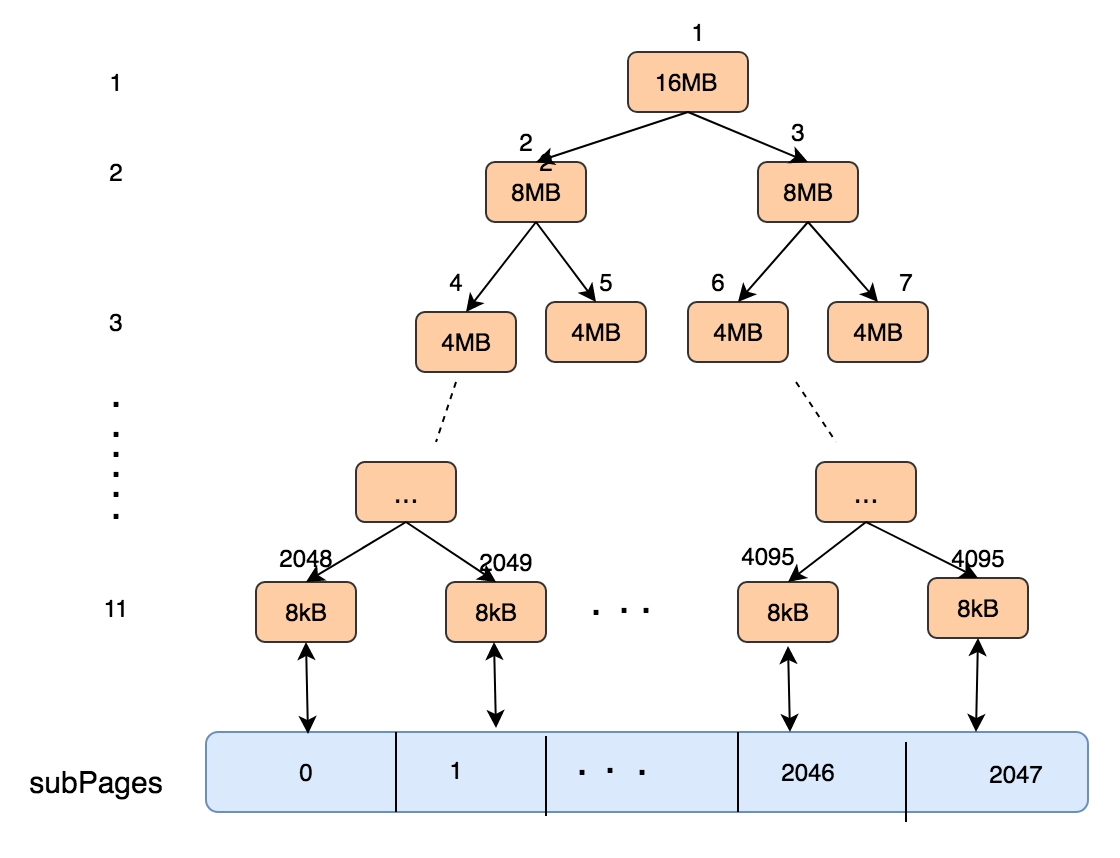
该二叉树将PoolChunk分11层, 第一层为1个16M, 第二层为2个8MB,第三层为4个4MB的内存块, 直到第11层为2048个8KB的内存块, 8kb的内存块称之为page。
PoolChunk用memoryMap和depthMap(数组)来表示二叉树(满二叉树),其中memoryMap存放的是PoolSubpage的分配信息,depthMap存放的是二叉树的深度。depthMap初始化之后就不再变化,而memoryMap则随着PoolSubpage的分配而改变。初始化时,memoryMap和depthMap的取值相同,都是节点所在层高。
分配一个内存大小为 chunkSize/2^k时,则先在第K层找第一个未使用的节点(从左到右),举例:
- 申请16M的内存, 那么直接在该二叉树第一层申请
- 申请8K的内存, 那么在将直接在第11层申请
节点的分配情况有如下三种可能:
- memoryMap[id]=depthMap[id]:表示当前节点可分配内存
- memoryMap[id]>depthMap[id]:表示当前节点至少一个子节点已经被分配,无法分配满足该深度的内存,但是可以分配更小一些的内存(通过空闲的子节点)
- memoryMap[id]=最大深度(默认为11)+1:表示当前节点下的所有子节点都已经分配完,没有可用内存
节点被标记为被占用之后,依次向上遍历更新父节点,直到根节点。将父节点的memoryMap[id]位置信息修改为两个子节点中的较小值
节点被标记为被占用之后,依次向上遍历更新父节点,直到根节点。将父节点的memoryMap[id]位置信息修改为两个子节点中的较小值
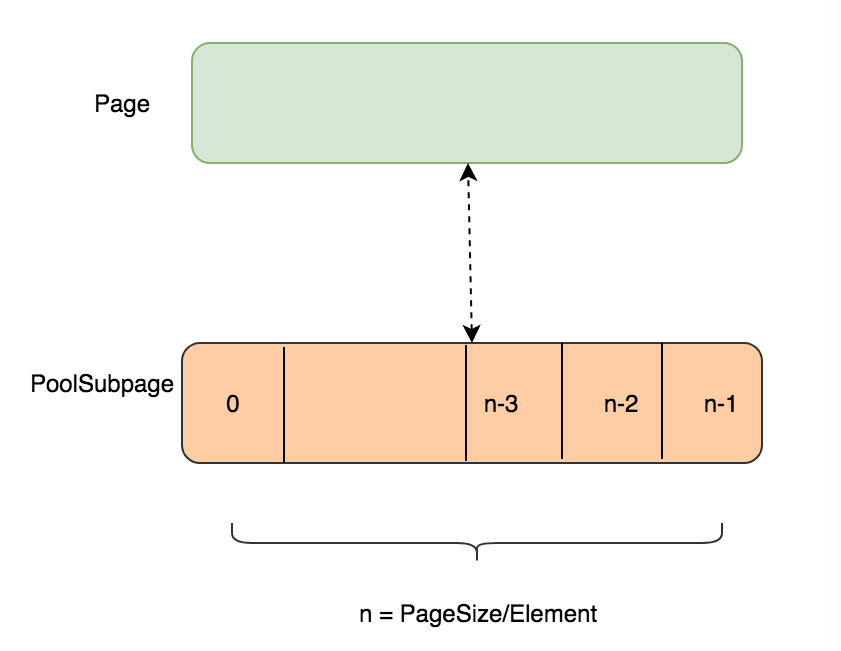
对于不足一个pagesize大小的内存分配,则由PoolSubpage进行处理,每一个PoolSubpage都会与PoolChunk里面的一个叶子节点映射起来, 然后将PoolSubpage根据用户申请的ElementSize化成几等分, 之后只要再次申请ElementSize大小的内存, 将直接从这个PoolSubpage中分配 (添加到PoolArena对应的SubPagePools中)。
PoolThreadCache
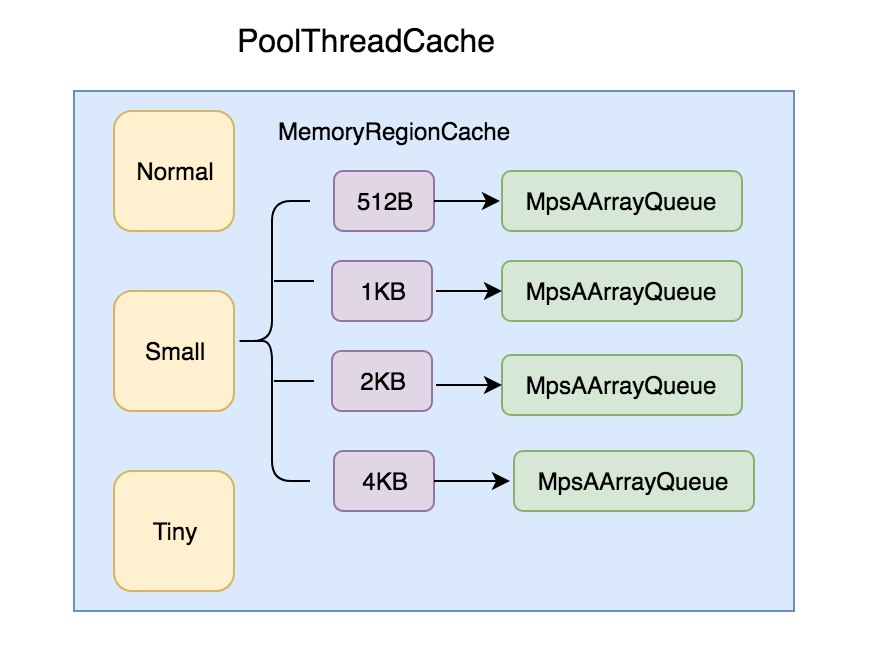
PoolThreadCache的内存来自于当前线程释放的。 PoolThreadCache也是将内存按大小分为tiny、small和normal三种,包含三个MemoryRegionCache数组(按照内存大小可快速定位),每个MemoryRegionCache都有一个Queue(固定大小)队列保存封装的Entry实体对象。
内存释放
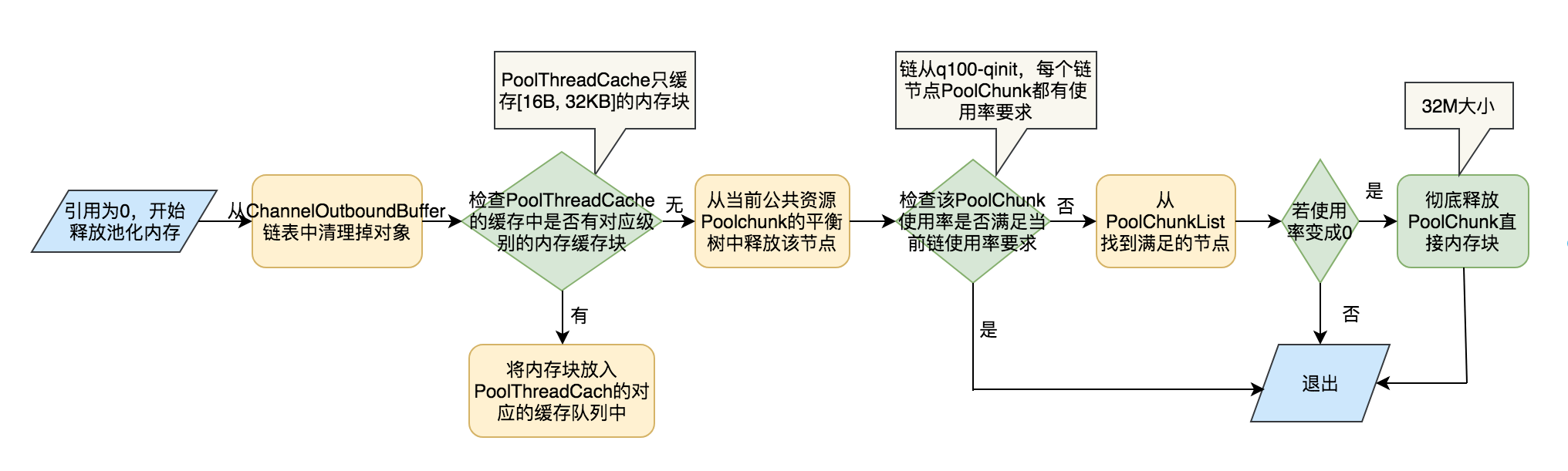
当PooledByteBuf引用计数减为0时,会触发调用deallocate
- Recycler.recycle 归还 ByteBuf
- PoolArena.free 归还 内存 (byte[])
缓冲区泄露检测
由于JVM并没有意识到Netty实现的引用计数对象,它仍会将这些引用计数对象当做常规对象处理,也就意味着,当不为0的引用计数对象变得不可达时仍然会被GC自动回收。一旦被GC回收,引用计数对象将不再返回给创建它的对象池,这样便会造成内存泄露。
为了便于用户发现内存泄露,Netty提供了相应的检测机制并定义了四个检测级别:
- DISABLED 完全关闭内存泄露检测,并不建议
- SIMPLE 以1%的抽样率检测是否泄露,默认级别
- ADVANCED 抽样率同SIMPLE,但显示详细的泄露报告
- PARANOID 抽样率为100%,显示报告信息同ADVANCED
最佳实践
- 单元测试和集成测试使用PARANOID级别
- 使用SIMPLE级别运行足够长的时间以确定没有内存泄露,然后再将应用部署到集群
- 如果发现有内存泄露,调到ADVANCED级别以提供寻找泄露的线索信息
- 不要将有内存泄露的应用部署到整个集群
直接内存vs堆内存
堆内存是在JVM堆上分配的,由JVM负责进行垃圾回收 直接内存是直接在Native堆上分配,并不由JVM负责进行垃圾回收
创建和释放Direct Buffer的代价比Heap Buffer要高 Direct Buffer减少用户态和内核态之间的数据copy
对于涉及大量I/O的数据读写,建议使用Direct Buffer;而对于用于后端的业务消息编解码模块建议使用Heap Buffer
Zero-Copy
Netty中的Zero-copy有两层含义:
- I/O的数据读写时使用Direct Buffer,数据无需在内核态 与 用户态 之间 进行拷贝
- Netty通过ByteBuf.slice和Unpooled.wrappedBuffer等方法拆分、合并Buffer,做到无需拷贝数据 (在协议传输过程中,通常需要拆包、合并包,常见的做法就是通过System.arrayCopy来复制需要的数据,但这样需要付出内容复制的开销)
异步Promise
JDK 的 Future 对象,该接口的方法如下:

Netty 扩展了 JDK 的 Future 接口,扩展的方法如下:

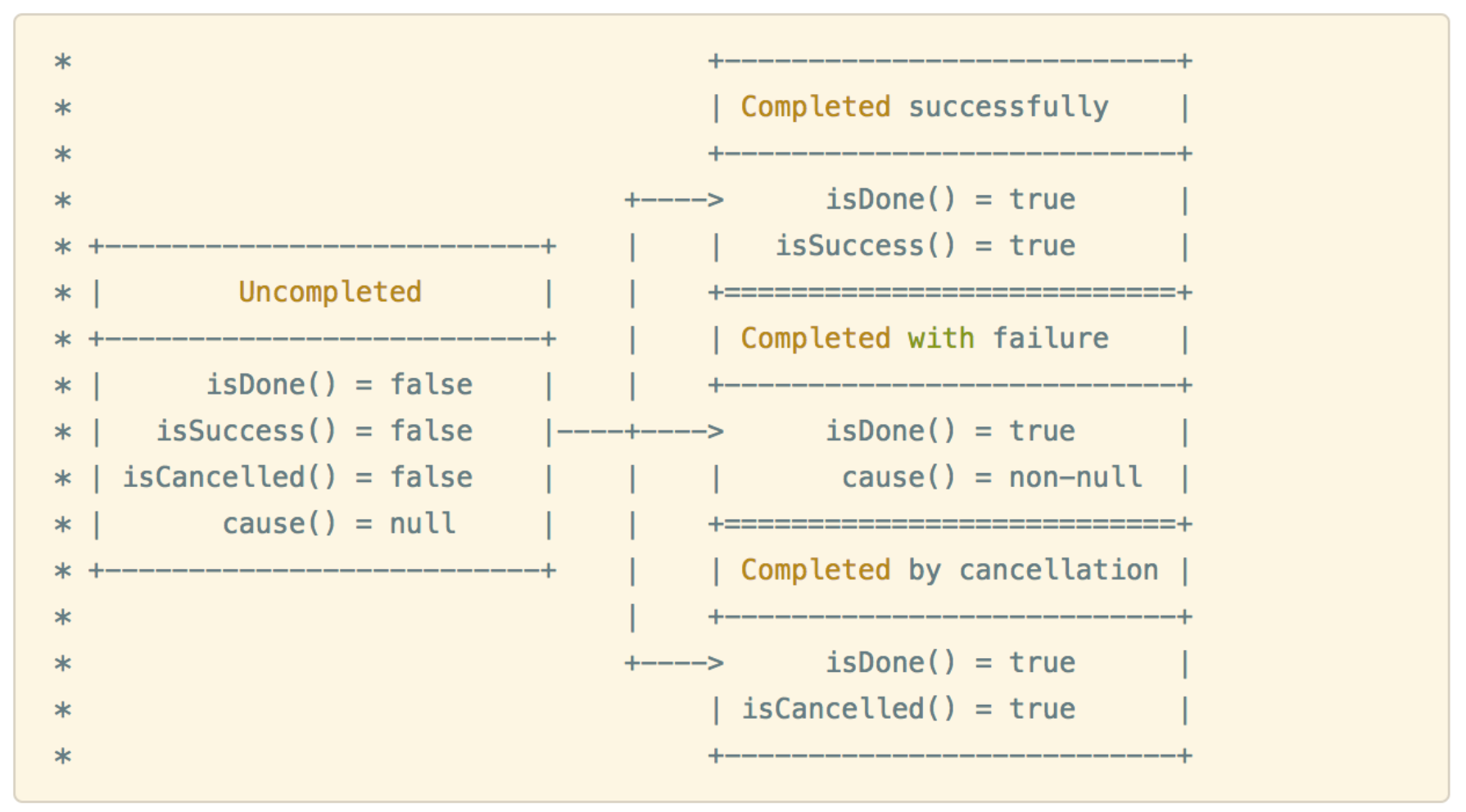
Future 对象有两种状态尚未完成和已完成,其中已完成又有三种状态:成功、失败、用户取消。
Future 接口中的方法都是 getter 方法而没有 setter 方法,也就是说这样实现的 Future 子类的状态是不可变的,如果我们想要变化,Netty 提供的解决方法是:使用可写的 Future 即 Promise。

Promise 接口继承自 Future 接口,它提供的 setter 方法与常见的 setter 方法大为不同。Promise 从 Uncompleted 到 Completed 的状态转变有且只能有一次,也就是说 setSuccess 和 setFailure 方法最多只会成功一个,此外,在 setSuccess 和 setFailure 方法中会通知注册到其上的监听者。
优雅退出
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
});
shutdownGracefully仅仅通过自旋CAS更改内部state NioEventLoop的run方法内部在执行一轮I/O操作以及Task之后,会判断state的值,如果需要关闭则执行closeAll和confirmShutdown方法,执行完毕则退出循环(即I/O线程)
closeAll处理逻辑
- 关闭所有的channel
- 清除outboundBuffer所有未发送的消息并释放资源
- 将SocketChannel从Selector上注销
- pipeline.fireChannelInactive
- pipeline.fireChannelUnregistered
confirmShutdown处理逻辑
- 取消所有的定时任务
- 执行队列中所有待执行的task
- 执行netty的ShutdownHook
最后NioEventLoop线程退出执行并关闭selector
性能调优
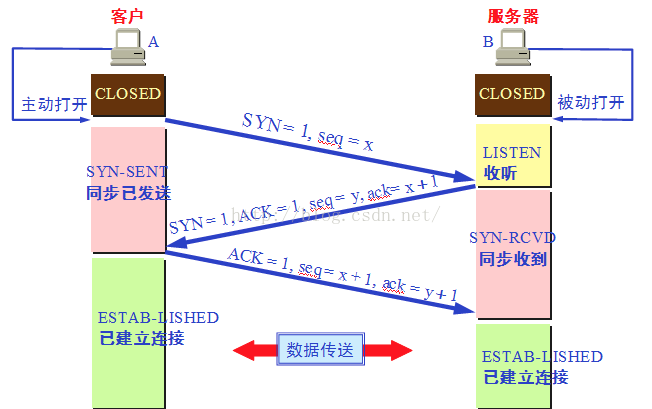
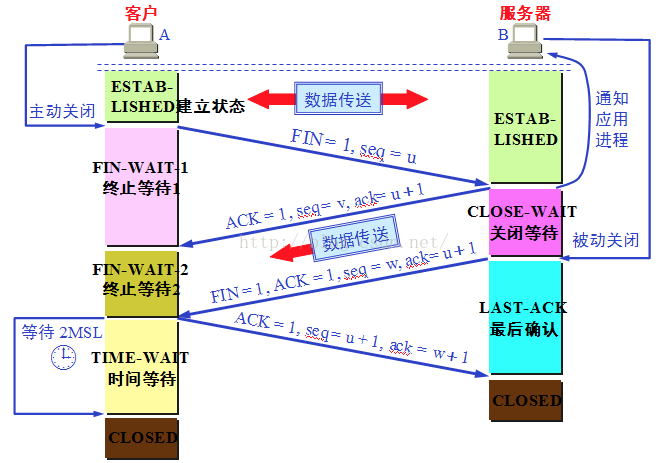
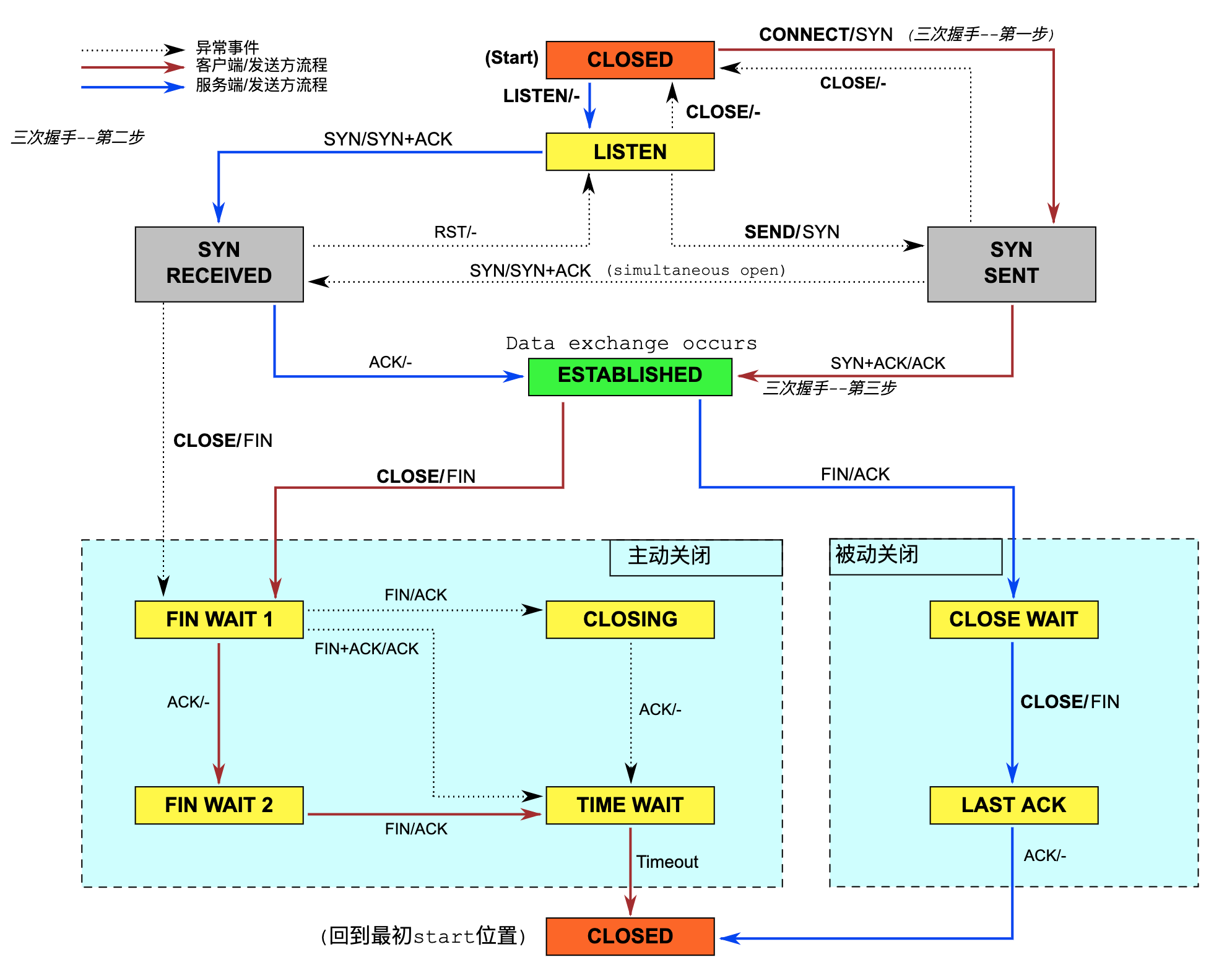
TCP建立连接/释放连接
操作系统TCP/IP参数调优
| 名称 | 描述 | 参考值 |
|---|---|---|
| fs.file-max | 系统级别所有进程可以打开的文件描述符的数量限制 | 1000000 |
| soft nofile | 可打开的文件描述符的最大数(超过会警告) | 1000000 |
| hard nofile | 可打开的文件描述符的最大数(超过会报错) | 1000000 |
| net.ipv4.tcp_tw_reuse | 允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭 (只对客户端起作用,开启后客户端在1s内回收) | 1 |
| net.ipv4.tcp_tw_recycle | 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭 (挂在公网NAT后面的Server不建议开启,且仅在 timestamps 开启时有效) | 0 |
| net.ipv4.tcp_timestamps | 开启TCP时间戳 (默认开启) | 1 |
| net.ipv4.ip_local_port_range | 本地可用端口范围 (默认:32768到61000) | 1024 65000 |
| net.ipv4.tcp_max_tw_buckets | 表示系统同时保持TIME_WAIT套接字的最大数量 | 262144 |
| net.ipv4.tcp_fin_timeout | 停留在FIN_WAIT_2状态的最大时长 | 60 |
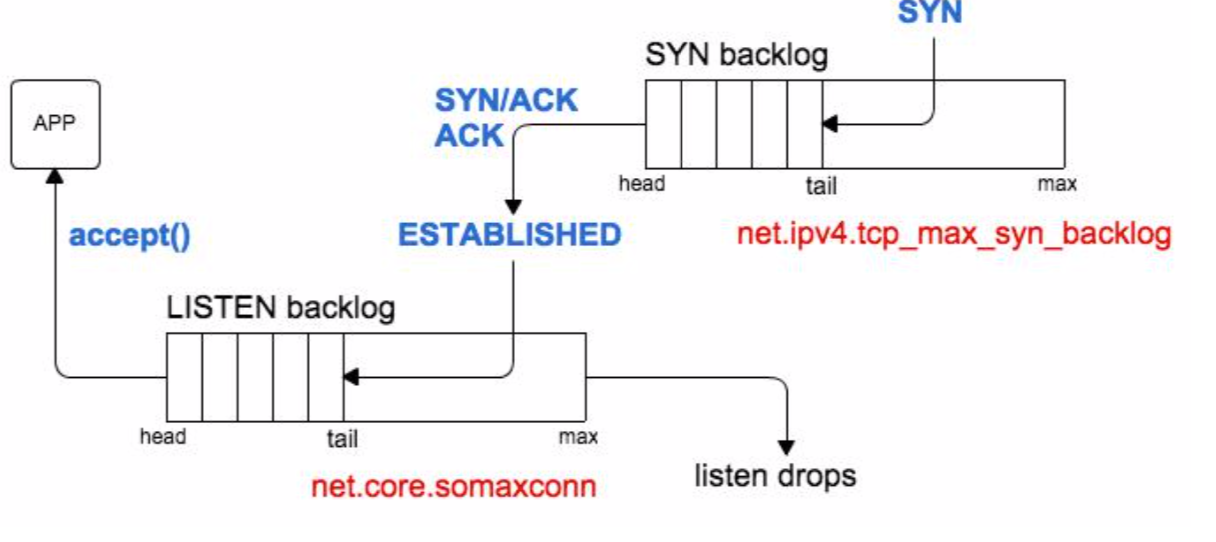
| net.ipv4.tcp_max_syn_backlog | SYN backlog 队列的最大长度,默认1024 | 8192 |
| net.core.somaxconn | listen backlog 队列的最大长度,默认128 | 262144 |
| net.core.netdev_max_backlog | 网络接口接收数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包的最大数目,一般默认值为128 | 262144 |
| net.ipv4.tcp_rmem | 每个TCP连接分配的读缓冲区内存大小 | 4096 87380 4194304 |
| net.ipv4.tcp_wmem | 每个TCP连接分配的写缓冲区内存大小 | 4096 87380 4194304 |
| net.ipv4.tcp_mem | 内核分配给TCP连接的内存,单位是page | 64608 1048576 2097152 |
| net.ipv4.tcp_syncookies | 当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭 | 1 |
| net.ipv4.tcp_sack | TCP的选择性确认SCK机制,数据接收方通知发送方成功接收的数据包段,发送就可以 | 1 |
| net.ipv4.tcp_windows_scaling | 是否要支持超过64KB的窗口 | 1 |
Netty性能调优
设置合理的线程数 I/O工作线程数 默认值(CPU核数 * 2) 业务线程池
设置合理的心跳周期 Netty通过IdleStateHandler来提供链路空闲检测机制
- 读空闲,链路持续时间T没有读取到任何消息
- 写空闲,链路持续时间T没有发送任何消息
- 读写空闲,链路持续时间T没有接收或者发送任何消息
合理使用内存池
防止I/O线程被意外阻塞
I/O线程和业务线程分离
并发连接数的兜底限制
