

作者:靠发型吃饭的柳树
原文地址:https://mp.weixin.qq.com/s/223b7xAABBtplpAv5OjAIg
食谱的故事
那一年,伦敦,Shay Banon 在找工作,他老婆在烹饪学校学习厨艺。
Shay 发现,老婆每天都要在大量的食谱中找自己想要的那份食谱,于是在找工作之余,开始给老婆做一个食谱搜索的工具。
市面上的搜索引擎,似乎没什么选择,只有 Lucene,但是 Lucene 又很难用,于是 Shay 在外面又抽象了一层,屏蔽了 Lucene 底层的复杂逻辑。
Shay 开源了这套给老婆搜索食谱用的系统,叫 Compass.
后来, Shay 找到了工作,他发现之前写的那套系统,在追求高性能、高可用的生产环境,实在太脆弱,于是又重新写了一套,Compass 也改名为了 Elasticsearch.
Shay 在把 Compass 重写为 Elasticsearch 时,面对的问题,其实就是:
你已经拥有了 Lucene,拥有了倒排索引,如何用它们来创造一个,让用户用起来特别爽、又特别可靠的搜索引擎?
Now,让我们跟着 Shay 的脚步,一起设计一个高性能高可靠的 Elasticsearch 吧!
开始
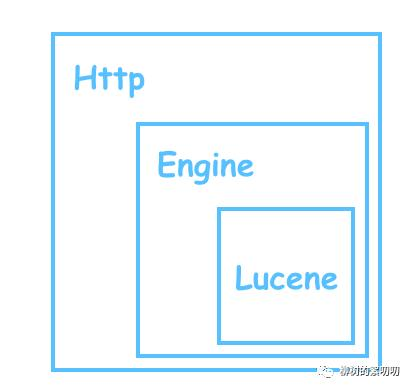
Shay 现在拥有的一切:
- Lucene:一个开源的搜索库
- Engine:屏蔽 Lucene 操作细节的抽象层
- Http:对外提供 restful api,让不同开发语言的应用都可以接入
简单画个图:
空节点
现在我们屏蔽 Elasticsearch 的底层实现,其实一个 Elasticsearch 实例对于我们来说,就是一个节点,一个可以提供数据搜索和探寻能力的节点:
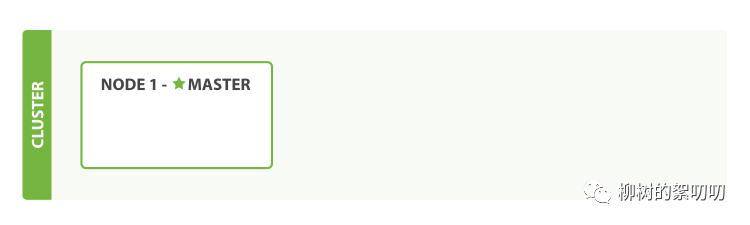
一开始,里面空空如也,什么都没有。
加点东西
Mysql 往数据库插入数据之前,需要先创建表,指定字段、主键等等,Elasticsearch 也需要创建“表”。
在 Elasticsearch 的领域语言里,「表」被称为「索引」,「行数据」被称为「文档」。
现在我们往节点里面定义一个「索引」blog:
PUT /blogs{ "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 }}你会发现,和 Mysql 不同,我们并没有定义这个“表”里有什么字段,这就是 nosql 的好处,你可以在之后插入的文档里,随时给这个“表”添加新的字段。
我们定义的是两个配置:
- number_of_shards:主分片数。shards,分片,分片有「主分片」和「副本分片」,这里指的是「主分片」,默认是 5 个主分片,这里指定为 3,即 blog 索引的数据,会被分散到 3 个分片里面,起到控制每个分片里文档数量个数的作用,提供查询和搜索效率,可以理解为 Mysql 里的分表。
- number_of_replicas:副本分片数。replicas,副本,也就是上面说的「副本分片」。副本分片只是一个主分片的拷贝,作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
现在我们的节点,不再是空空如也,而是这样:
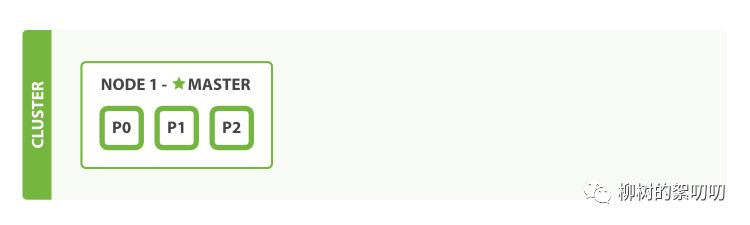
P0、P1、P2 就是 blog 索引的 3 个主分片。
为什么没有副本分片?
因为对于单节点的架构来说,进行冗余备份就毫无意义的,只会浪费内存和磁盘。
再加个节点
现在我们往集群里添加第二个节点,很简单,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中:
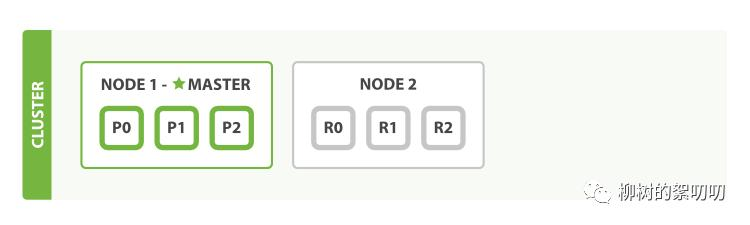
原先被雪藏起来的三个副本分片,现在都在这个新增的节点上,被激活了。
水平扩容
这套架构,用着用着,我们发现两个节点的 CPU 、RAM 等硬件资源都十分紧张,随时可能奔溃,怎么办?
没有什么是加一套机器不能解决的,如果有,那就加两套:
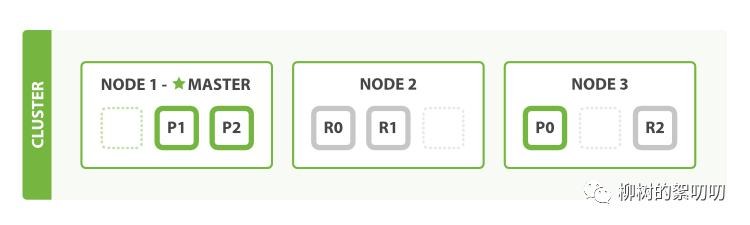
甚至你还能把副本分片的数量调整到 2:
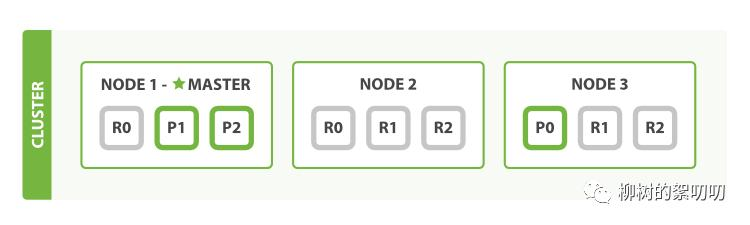
当然,上面那句话是句玩笑话,如果没有把单机的性能发挥到极限,不去思考如何提升单机的性能和算法的优势,一味的依靠拓机器数量,是十分愚蠢的。
在我们加了一个节点进去后,Elasticsearch 集群自动的帮我们重新平均分布所有的数据。
Elasticsearch 前面的这个 elastic,果然名不虚传。
故障处理
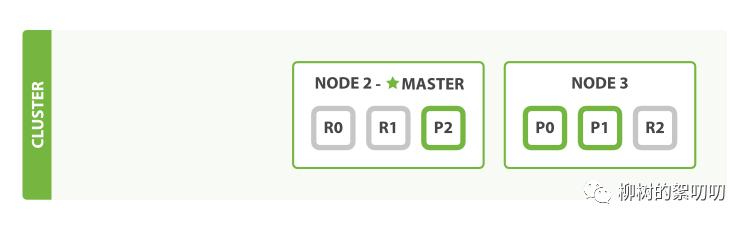
这套架构是高可靠的,假设 Master 节点 Node1 突然奔溃了,这时候集群会选举出一个新的节点。
这还不够,我们失去 Node 的同时,也失去了原来 Node 1 上的两个主分片,P1 和 P2,幸运的是,Node 2 和 Node 3 上有对应的副本分片,集群会把对应的副本分片提升为主分片:
通过自己封装的 Engine 层,屏蔽了 Lucene 的底层复杂的操作;
通过集群架构,构建了一套高性能、高可靠的搜索系统;
Shay 把原本复杂、上手难度极大的 搜索库 Lucene,打造为了对使用者非常友好的 Elasticsearch。
尾声
又后来,Shay 和他的伙伴们创建了一家公司,Elastic.
这家公司围绕 Elasticsearch ,对外界提供数据搜索和探索的服务。
对于一家公司来说,它可以直接使用 Elastic 提供好的现成的搜索服务,比如日志搜索、监控、站点搜索等等,来给自己的应用集成搜索功能,这是 Elastic 的 SAAS 业务;
当然,如果你是一家有开发能力的公司,可以直接使用 Elasticsearch,来赋予应用数据搜索和探寻的能力,这是 Elastic 的 PAAS 业务。

