

内容包括:
1. 基本神经网络实力,用于线性回归的简单机器学习任务
2. 张量和张量运算
3. 基本的神经网络优化
没有人喜欢等待,当我们不知道要等多久的时候,等待特别烦人。任何用户体验设计师都会告诉你,如果你无法解决延迟,那么最好就是给用户一个可靠的等待估计时间。估计延迟时间是一个预测问题,TensorFlow.js库可以根据上下文和用户情况,构建准确下载时间的预测,使我们能够为用户提供更清晰、可靠的体验。
在本章中,我们将以一个简单的下载时间预测问题为例,介绍一个完整的机器学习模型的主要组成部分。我们将从实用的角度讨论张量、建模和优化。我们将介绍它们是什么、如何工作以及如何恰当地使用它们。
一个专注的研究者需要多年的研究才能完全理解深度学习的内部原理,其需要熟悉许多数学科目。然而,对于深度学习的实践者来说,拥有线性代数、微分学和高维空间统计的专业知识是有帮助的,但不是必要的,甚至对于构建复杂的高性能系统也是如此。我们在这一章,以及在这本书中的目标是,在可能的情况下,使用代码而不是数学符号来介绍必要的技术主题。我们的目标是传达对机器及其用途的直观理解,而不需要领域专业知识。
2.1示例1:使用TensorFlow.js预测下载的持续时间
我们将构建一个最小神经网络,根据下载文件大小,利用TensorFlow.js(TFJS)库预测下载时间。除非您已经有使用TFJS或类似库的经验,否则您不会立即理解第一个示例的所有内容,这很好。这里介绍的每一个主题都将在接下来的章节中详细介绍,所以不要担心某些部分在你看来是模糊的!我们将从编写一个接受文件大小作为输入的短程序开始,并输出下载文件的预计时间。
2.1.1概况:预测
当你第一次学习机器学习系统时,你可能会被各种各样的新概念和术语吓倒。因此,首先查看整个工作流是有帮助的。这个例子的概要如下图所示,我们将在本书的例子中重复看到这个模式。
图2.1 第一个示例,“下载时间预测”系统中涉及的主要步骤概述。
2.1.2关于代码列表和控制台交互的说明
本书中的代码将以两种格式呈现。
第一种格式是代码列表,它显示了您可以在引用的代码存储库中找到的结构代码。每个列表都显示在一个框中,包括一个标题和一个数字。例如,下面清单2.1中的示例包含一个非常简短的HTML代码片段,您可以将其逐字复制到文件中,例如,在您的计算机上,尽管它在/tmp/tmp.html,但是在web浏览器中打开file:///tmp/tmp.html。
代码的第二种格式是控制台交互。这些非正式的代码块旨在JavaScript REPL[38]上的示例交互,例如浏览器的JavaScript控制台(Cmd-Opt-J, Ctrl+Shift+J、或Chrome中的F12,但您的浏览器/操作系统可能不同)。控制台交互在前面用大于号表示,就像我们在Chrome或Firefox中看到的那样,它们的输出显示在下一行。例如,下面的交互创建一个数组并打印值。您在JavaScript控制台上看到的输出可能略有不同,但要点应该是相同的。
> let a = ['hello', 'world', 2 * 1009]
> a;
(3) ["hello", "world", 2018]
从本书中的代码中测试、运行和学习的最佳方法是克隆引用的存储库,然后使用它们。在本书的开发过程中,我们经常会使用一个简单的交互式共享存储库“CodePen”(CodePen.io)。例如,清单2.1可以在codepen.io/tfjs-book/pen/VEVMbx上实现。当您导航到“CodePen”页面时,它会自动运行。您应该能够看到打印到控制台的输出。单击左下角的“控制台”打开控制台。如果“CodePen”没有自动运行,尝试做一些小更改,比如在结尾添加一个空格,以启动它。
此部分可在CodePen代码集CodePen.io/collection/Xzwavm/中找到。CodePen在只有一个JS文件的地方工作得很好,但是在后面的示例中将更大、更结构化的示例就需要保存在GitHub存储库中。对于本例,我们建议阅读本节内容,然后按顺序执行相关的“CodePen”。
2.1.3创建和格式化数据
只要给定它的大小(以MB为单位),我们就可以估计出在给定的机器上下载一个文件需要多长时间。我们将首先使用预先创建的数据集,但是,如果您有兴趣,可以创建一个类似的数据集,对您自己系统的网络统计数据进行建模。
<script src='https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest'></script>
<script>
const trainData = {
sizeMB: [0.080, 9.000, 0.001, 0.100, 8.000, 5.000, 0.100, 6.000, 0.050, 0.500,
0.002, 2.000, 0.005, 10.00, 0.010, 7.000, 6.000, 5.000, 1.000, 1.000],
timeSec: [0.135, 0.739, 0.067, 0.126, 0.646, 0.435, 0.069, 0.497, 0.068, 0.116,
0.070, 0.289, 0.076, 0.744, 0.083, 0.560, 0.480, 0.399, 0.153, 0.149]
};
const testData = {
sizeMB: [5.000, 0.200, 0.001, 9.000, 0.002, 0.020, 0.008, 4.000, 0.001, 1.000,
0.005, 0.080, 0.800, 0.200, 0.050, 7.000, 0.005, 0.002, 8.000, 0.008],
timeSec: [0.425, 0.098, 0.052, 0.686, 0.066, 0.078, 0.070, 0.375, 0.058, 0.136,
0.052, 0.063, 0.183, 0.087, 0.066, 0.558, 0.066, 0.068, 0.610, 0.057]
};
</script>
这里介绍了如何使用@latest后缀加载tfjs库的最新版本(在编写本文时,此代码使用tfjs 0.13.5运行)。稍后我们将更详细地介绍将TFJS导入到应用程序中的不同方法,但需要提前引用<script>。第一个script>加载TensorFlow包并定义成tf,该符号提供了一种引用TensorFlow中名称的方法。例如,引用tf.add()是TensorFlow add的操作,该操作添加两个张量。接下来,通过加载上述的tfjs脚本,tf在全局中便可用。
上面的清单创建了两个常量,trainData 和 testData,每个常量表示下载一个文件花费的时间(timeSec)和该文件的大小(sizeMB)的20个示例。sizeMB中的元素和timeSec中的元素有一一对应的关系。例如,训练数据中的第一个元素有0.080 MB,下载该文件需要0.135秒,即第一个元素的timeSec,以此类推。我们在这个例子中只要给出sizeMB,那就能估计出timeSec。在第一个例子中,我们通过在代码中硬编码直接创建数据。这种方法对于这个简单的例子来说是方便的,但是当数据集的大小增加时,它会变得非常笨拙。之后的例子将说明介绍从外部存储器或通过网络传输数据得到输入数据。
回到数据上。从下面的图表中,我们可以根据文件大小和下载时间对互相进行预测。现实生活中的数据是复杂的,但是在这个例子中,我们应该能够对给定文件大小的持续时间做出很好的线性估计。根据判断,当文件大小为0时,持续时间应该为0.1秒左右,然后每增加一个MB,持续时间就增加0.07秒左右。
图2.2测量的下载持续时间与文件大小。如果您对如何创建这样的绘图感兴趣,那么代码将列在code pen CodePen.io/tfjs-book/pen/dgQVze中

本文的工作流程总结如下:首先在训练数据上拟合神经网络,对给定的数据进行准确预测。最后,我们将使用网络输入测试数据的sizeMB,来预测timeSec。但首先,我们必须将这些数据转换成TFJS能够理解的格式,这是我们使用张量的第一个例子。清单2.2中的代码显示了您将在本书中看到的tf.*名称空间下函数的第一次使用。这里我们展示了存储在原始JavaScript数据结构中的数据转换为张量的方法。尽管用法非常简单,但是那些希望在这些api中更进一步的读者应该阅读本书末尾的附录A4,它不仅涵盖了像tf.tensor2d()`等创建张量的函数,还包括执行操作转换和组合张量的函数,以及如何按惯例打包成张量的常见(如图像的和视频的)数据类型。我们并没有深入研究主文本中的低级API,因为这些材料有些枯燥,没有与特定的示例问题联系在一起。
清单2.2将数据转换成张量(来自CodePen 2-b)
const trainTensors = {
sizeMB: tf.tensor2d(trainData.sizeMB, [20, 1]), #A:
timeSec: tf.tensor2d(trainData.timeSec, [20, 1])
};
const testTensors = {
sizeMB: tf.tensor2d(testData.sizeMB, [20, 1]),
timeSec: tf.tensor2d(testData.timeSec, [20, 1])
};
一般来说,目前所有的机器学习系统都使用张量作为基本的数据结构。其中张量是基本要素,因此TensorFlow和TensorFlow.js也以它们命名。第一章的快速回顾:
张量是数据的容器-几乎总是数值数据。所以它可以被看作是数字的容器。您可能已经熟悉了向量和矩阵,它们分别是一维张量和二维张量。张量是矩阵到任意维数的推广。维度的数量和每个维度的大小称为张量的形状。例如,一个3 x 4的矩阵是具有形状[3,4]的张量。长度为10的向量是具有形状的一维张量[10]。 在张量的上下文中,维数通常称为轴。在TensorFlow.js中,tensor是一种常见的表示形式,无论是在CPU、GPU还是其他硬件上,它允许组件之间进行通信和工作。随着需求的增加,我们将有更多关于张量及其常见用例的讨论,但是现在让我们继续我们的预测。
2.1.4定义简单模型
在深度学习的背景下,从输入特征到目标的函数称为模型。模型函数获取特征、运行计算并生成预测。我们在这里建立的模型是一个以文件大小作为输入和输出持续时间的函数(见图2.2)。在深度学习的术语中,有时我们使用网络作为模型的同义词。我们的第一个模型将是线性回归。
在机器学习的背景下,回归意味着模型将输出实值数字并尝试匹配训练目标,而分类则从一组选项中输出选择。在回归任务中,输出离目标较近的数字的模型比输出离目标较远的数字的模型要好。如果我们的模型预测一个1MB文件大约需要0.15秒,那么(如图2.2所示)比我们的模型预测一个1MB文件大约需要600秒要好。
线性回归是一种特殊的回归类型,其中输出作为输入的函数,可以表示为一条直线(或者类比地,当存在多个输入特征时,可以表示为高维空间中的平面)。模型的一个重要特性是它们是可调的。这意味着可以调整输入输出计算。我们使用此属性来优化模型以更好地“拟合”数据。在线性情况下,模型的输入输出关系总是一条直线,但我们可以调整斜率和y截距。 让我们建立我们的第一个网络:
清单2.3构造一个线性回归模型(来自CodePen 2-c)
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1], units: 1}));
神经网络的核心组成部分是层,这是数据处理模块,你可以把它看作是一个从张量到张量的可调函数。在这里,我们的网络由一层组成。该层对输入张量的形状有约束为[1q]。这意味着该层期望输入的形式是一个只有一个值的一维张量。对于每个示例,密集层的输出始终是一维张量,但该维度的大小由单元配置参数控制。在这种情况下,我们只需要一个输出数字,因为我们正试图准确地预测一个数字,即timeSec。
密集层是一个在每个输入和每个输出可调的倍增部分。由于只有一个输入和一个输出,这个模型是一个简单的线性方程y = m * x + b。层内部的m是kernel和b是偏差,如图2.3所示。因此在本例中,我们为输入(sizeMB)和输出(timeSec)之间的关系构造了一个线性模型。timeSec = kernel * sizeMB + bias
这个方程式有四项。就模型训练而言,其中受训练数据影响的两个参数是固定的:(sizeMB)和(timeSec)(见清单2.1)。另外两个项,即m和偏差b,是模型的参数。它们的值是在创建模型时是随机选择的。这些随机值不能很好地预测下载持续时间。为了进行更准确的预测,我们必须通过模型从数据中学习来寻找更好的kernel值和偏差值。这个搜索就是训练过程。
为了找到一个好的kernel值和偏差值(统称为“权重”),我们需要两件事:
- 一种测量方法,使用权重进行反馈。
- 一种更新权重值的方法,根据上面提到的度量,下次会比现在做得更好。
图2.3简单线性回归模型的图解。模型只有一层。模型的可调参数(或权重)显示在稠密层中。

- 损失函数--误差测量。这是如何在训练数据上测量网络的性能。损失越少越好,当我们训练时,我们应该能够计算出随着时间的推移所造成的损失,并看到误差的下降。如果我们的模型训练了很长一段时间,损失没有减少,这可能意味着我们的模型没有习得去拟合数据。在这本书的过程中,你将学会调试这样的问题。
- 一个优化器--网络根据数据和损失函数更新其权重的算法。 关于loss函数和优化器的确切目的,以及如何为它们选择,将在接下来的几章中进行深入的探讨。
清单2.4配置训练选项:模型编译(来自CodePen 2-c)
model.compile({optimizer: 'sgd', loss: 'meanAbsoluteError'});
在清单2.4中,我们在模型上调用compile方法,将“ sgd”指定为优化器,将“ meanAbsoluteError”指定为损耗。 “ meanAbsoluteError”表示损失函数,计算预测与目标之间的距离,取其绝对值(使它们全部为正),然后返回这些值的平均值。
meanAbsoluteError = average( absolute(modelOutput - targets) )
例如,给定:
modelOutput = [1.1, 2.2, 3.3, 3.6]
targets = [1.0, 2.0, 3.0, 4.0]
然后,
meanAbsoluteError = average([|1.1 - 1.0|, |2.2 - 2.0|,
|3.3 - 3.0|, |3.6 - 4.0|])
= average([0.1, 0.2, 0.3, 0.4])
= 0.25
如果我们的模型做出了非常糟糕的预测,并且与目标相距甚远,那么meanAbsoluteError将会非常大。相反,我们使每个预测完全正确,在这种情况下,模型输出与目标之间的差异将为零,因此损失“ meanAbsoluteError”将为零。
清单2.4中的“ sgd”代表随机梯度下降,我们将在下面的2.2节中对其进行更多描述,简要地讲,我们将使用微积分来确定应对权重进行哪些调整以减少损失;然后进行调整并重复该过程。 现在,我们的模型已经准备就绪。
2.1.5在训练数据中进行模型拟合
通过调用模型的fit()方法,可以在TFJS中训练模型。我们将在训练数据中进行模型拟合。我们传入sizeKB张量作为输入,并将timeMS张量作为输出。我们还将传入一个带有epochs字段的配置对象,该字段指定我们希望对训练数据进行10次遍历。在深度学习中,整个训练集的每次迭代都称为一个epoch。
清单2.5 线性回归模型拟合
(async function() {
await model.fit(trainTensors.sizeMB,
trainTensors.timeSec,
{epochs: 10});
})();
我们利用了ES2017 / ES8的async / await功能,以便可以在浏览器中运行时以不阻塞主UI线程来使用此fit()方法。这类似于JavaScript中‘异步获取’需要消耗长时间的函数。这里,我们使用“立即调用的异步函数表达式” [39]模式等待fit调用完成,然后再继续,但是之后的示例将在后台进行训练,前台线程中会执行其他工作。
一旦模型完成拟合,我们将要查看它是否有效。我们将根据训练期间未使用的数据来评估模型。将测试与训练数据分离(从而避免对测试数据进行训练)的主题将在本书中反复出现。这是机器学习工作流程中的重要组成部分。
> model.evaluate(testTensors.sizeMB, testTensors.timeSec).print();
Tensor
0.31778740882873535
模型的评估方法是计算损失函数,并将其应用于提供的示例特征和目标。它与fit()方法相似,但评估不会更新模型的权重。我们使用evaluate()来评估测试数据上模型的优劣,以便对模型在将来的应用程序中的表现有所了解。
在这里,我们看到测试数据中的平均损耗约为0.318。由于默认情况下模型是从随机初始状态训练而来的,因此您将获得不同的值。换句话说,该模型的平均绝对误差接近0.3秒。这个好吗?我们可以选定一个常数为平均延迟。让我们看看TFJS对张量的数学运算会产生什么样的误差。首先,我们将计算在我们的训练集上的平均下载时间。
> const avgDelaySec = tf.mean(trainData.timeSec);
> avgDelaySec.print();
Tensor
0.2950500249862671
接下来,让我们手动计算meanAbsoluteError。平均绝对误差仅是我们的预测与实际值相差多少的平均值。我们将使用tf.sub()来计算测试目标与我们的(恒定)预测之间的差异,tf.abs()来获取绝对值,并且然后以tf.mean取平均值。
> tf.mean(tf.abs(tf.sub(testData.timeSec, 0.295))).print();
Tensor
| 信息框2.1 | |
|---|---|
| 张量的链式API 在tf命名的API中,有些方法可以使用链式API来实现,比如下面的代码和 meanAbsoluteError是一致的。>testData.timeSec.sub(0.295).abs().mean().print(); #Chaining API pattern Tensor 0.22020000219345093 |
预测的平均误差约为0.295秒,其比我们的网络有着更好的估计。这意味着我们模型的准确性甚至比常识的方法还要差!我们可以做得更好吗?我们可能没有经过足够的训练。请记住,在训练过程中,kernel和bias的值会逐步更新。在这种情况下,每个epoch都是一个步骤。如果仅针对少数时期(步骤)训练模型,则参数值很难接近最佳值。让我们再训练模型几个周期,然后再次评估。
> model.fit(trainTensors.sizeMB, trainTensors.timeSec, {epochs: 200});
好多了!看来我们以前的模型尚未充分拟合训练数据。现在,我们的估计平均在0.05秒以内。比猜测的平均值要精确四倍。在这本书中,我们将提供有关如何避免过度拟合以及更隐蔽的过度拟合问题的指南。
2.1.6使用训练模型进行预测
好的,不错!因此,现在有了一个可以在给定输入文件大小的情况下准确预测下载时间的模型,但是我们如何使用它呢?答案是模型的预测方法。
> const smallFileMB = 1;
> const bigFileMB = 100;
> const hugeFileMB = 10000;
> model.predict(tf.tensor2d([[smallFileMB], [bigFileMB], [hugeFileMB]])).print();
Tensor
[[0.1373825 ],
[7.2438402 ],
[717.8896484]]
在这里,我们看到我们的模型预测10,000 MB的文件下载将花费大约718秒。请注意,我们的训练数据中没有任何接近此大小的示例。通常,将数据外推到训练数据之外是非常冒险的,但是存在一个简单的问题,只要我们不遇到内存缓冲区,I / O连接等新问题,它是否可能是准确的呢。如果我们可以在此范围内收集更多的训练数据,那就更好了。
我们需要将输入变量包装到适当形状的张量中。在清单2.3中,我们将输入形状(即维度)定义为[1],因此模型期望每个示例都具有该形状。 fit()和predict()一次可以处理多个示例。为了提供n个样本,我们将它们堆叠在一起成为单个输入张量,因此该张量必须具有[n,1]的形状。如果我们忘记了,而是为模型提供了错误形状的张量,那么我们将出现错误,例如以下代码:
> model.predict(tf.tensor1d([smallFileMB, bigFileMB, hugeFileMB])).print();
Uncaught Error: Error when checking : expected dense_Dense1_input to have 2 dimension(s), but got array with shape [3]
请注意这种形状不匹配的情况,因为这是非常常见的错误!
2.1.7第一个示例的总结
下图显示了模型的输出(timeSec)与输入(sizeMB)的函数关系,对于模型在过程中的四条线,从10次的欠拟合开始,到200次收敛
图2.4 在10/20/100/200次循环训练后的线形模型
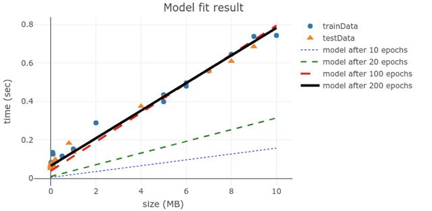
如果您对如何绘制上述数据有兴趣,请访问codepen.io/tfjs-book/pen/VEVMMd。
这就是我们的第一个例子。 您刚刚看到了如何用很少的几行JavaScript代码来构建,训练和评估TFJS模型。 在下一节中,我们将更深入地研究model.fit内部的情况。
清单2.6 构建,训练和评估TFJS模型
const model = tf.sequential([tf.layers.dense({inputShape: [1], units: 1})]);
model.compile({optimizer: 'sgd', loss: 'meanAbsoluteError'});
(async () => await model.fit(trainTensors.sizeMB,
trainTensors.timeSec,
{epochs: 10}))();
model.evaluate(testTensors.sizeMB, testTensors.timeSec);
model.predict(tf.tensor2d([[7.8]])).print();
2.2 model.fit()内部:剖析例1中的梯度下降
2.2.1 梯度下降的优化
在上一节中,我们建立了一个简单的模型并将其拟合到一些训练数据中,在给定文件大小的情况下,我们可以做出合理准确的下载时间预测。它不是最令人印象深刻的神经网络,但其工作原理与我们将要构建的大型,复杂得多的系统完全相同。我们发现将其拟合10次并不是很好,但是拟合200次就产生了较好的模型[40]。让我们更详细地了解模型训练下到底发生了什么。
output = kernel * input + bias
最初,这些赋值为较小的随机值(称为随机初始化)。当然,当kernel和bias是随机的时,kernel * input + bias不会产生任何有用的信息。利用我们的想象力,根据这些参数的变化,我们可以描绘出平均绝对误差的值。当它们逼近我们在图2.4中看到的直线的斜率和截距时,损耗将变小,反之,损耗将变得更糟。所有可调参数函数的损耗称为损耗面。
图2.5损失表面以等高线图形式显示了针对模型的可调参数显示的损失。通过这种鸟瞰图,我们可以看到对于低损耗{bias:0.08,kernel:0.07}(标有白色“ X”)是一种合理的选择。我们很难测试所有不同的参数来构建这样的地图,但是可以这样做的话,优化将非常容易。只需选择与最低损耗相对应的参数即可!
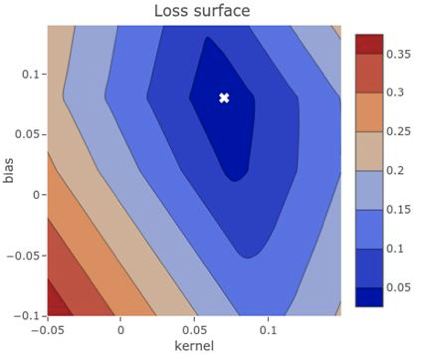
这是一个很小的示例,并且我们只有两个可调参数和一个目标值,因此可以将损耗表面显示为2D等高线图,如图2.5所示。该损失表面具有良好的碗形,碗的底部的全局最小值表示最佳配置参数。但是,总的来说,深度学习模型的损失面要比这种模型复杂得多。它将具有两个以上的维度,并且可能具有许多局部最小值,即,点低于附近的任何点,但不是最低的。
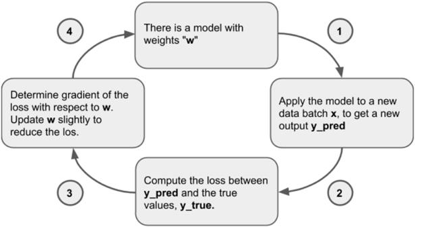
我们看到该损失表面的形状像一个碗,其最佳值(最低值)在{bias:0.08,kernel:0.07}附近。这符合我们的数据形成的直线,即使文件大小接近零,下载时间也约为0.10秒。我们模型的随机初始化从一个随机参数开始,类似于该图中的随机位置,从中我们可以计算出初始损失。接下来,我们根据反馈信号逐渐调整参数。这种逐渐的调整,也称为训练,是“机器学习”中的“学习”。这是在训练循环中发生的,如下图2.6所示。
图2.6此流程图描述了该训练循环通过梯度下降来更新模型。
-
绘制一批训练样本x和相应的目标y_true。 “批处理”只是将许多输入示例作为张量组合在一起。批处理中示例的数量称为“批处理大小”。在实际深度学习中,通常将其设置为2的幂,例如128和256。将示例分批处理,以利用GPU的并行处理能力并使梯度的计算值更稳定(有关详细信息,请参见下面的2.2.2节)。
-
在x上运行网络(称为正向传递的步骤),以获得预测y_pred。
-
计算批次上的网络损失,以衡量y_true和y_pred之间的差距。回想一下,当调用model.compile()时指定了损失函数。
-
慢慢减少批次损失的方式更新网络中的权重(参数)。各个权重的详细更新由优化器管理,这是我们在model.compile()调用期间指定的另一个选项。 如果您可以在每一步上减少损失,那么最终您将获得一个损失较少的网络。网络“学习”后将其输入映射到正确的结果。看起来像魔术,但是当简化为这些基本步骤时,它被证明很简单。
唯一困难的部分是步骤4,如何确定应增加的权重,应减少的权重以及降低多少?我们可以简单地猜测和测试,仅接受实际上损失减少的更新。这样的算法可能适用于像这样的简单问题,速度非常慢。对于较大的问题,当我们优化数百万个权重时,便变得很难。更好的方法是利用网络中使用的所有操作都是可微的这一事实,根据网络参数来计算损耗的梯度。
什么是“梯度”?除了可以精确地定义它之外,我们还可以将其直观地描述如下: “一个方向,如果将权重在该方向上移动一点,您将在所有可能的方向中最快地增加损失函数。” 即使此定义不是太过严谨的定义,但仍有很多需要解开的内容,因此让我们尝试将其分解。
- 首先,梯度是一个向量。它具有与权重相同数量的元素。它代表权重值空间中的一个方向。如果模型的权重由两个数字组成(如我们的简单线性回归网络中的情况),则梯度为2D向量。深度学习模型通常具有数千或数百万个维度,并且这些模型的梯度是具有数千或数百万个元素的向量(方向)。
- 其次,梯度取决于当前的权重值。换句话说,不同的权重值将产生不同的梯度。从图2.5可以清楚地看出,下降最快的方向取决于您在损耗面上的位置。此位置在左边,我们必须向右走。在底部附近,我们必须向上,依此类推。
- 最后,梯度的数学定义指定了损失函数沿其增加的方向。当然,在训练神经网络时,我们希望减少损失。这就是为什么我们必须沿与梯度相反的方向移动权重的原因。
打个比方,在山脉中远足。想象一下,我们希望旅行到最低海拔的地方。以此类推,我们可以通过沿东西轴和南北轴定义的任何方向移动来更改高度。我们应该将上面的第一个要点解释为,鉴于脚下的坡度,我们的海拔梯度是最陡峭的向上方向。第二点很明显,指出最陡峭的向上方向取决于我们当前的位置。最后,如果我们想降到低海拔,我们应该朝着与梯度相反的方向走。
该训练过程恰当地称为梯度下降。还记得清单2.4中用配置优化器指定模型优化器:“ sgd” 吗?现在应该清楚随机梯度下降的梯度下降部分。“随机”部分仅表示我们在每个梯度下降步骤中从训练数据中抽取随机样本以提高效率,而不是在每个步骤中都使用每个训练数据样本。随机梯度下降是对计算效率的梯度下降的简单修改。
现在,我们有了工具来更完整地说明优化的工作原理,以及为什么200次训练后的下载时间估算模型好于10次。图2.7说明了梯度下降算法如何沿着我们的损失表面向下的路径找到适合我们训练数据的权重配置。图2.7A中的等高线图显示了与以前相同的损耗面,只是将其放大了一点,这里覆盖了路径,便是梯度下降算法。路径从随机初始化开始;即图像上的随机位置。因为我们事先不知道最佳选择,所以我们必须随机选择一个地方开始!沿路径调用了其他几个兴趣点,这些位置说明了与欠拟合和良好拟合模型相对应的位置。图2.7B展示了模型损失随步长变化的曲线图。图2.7C说明了使用相应权重配置所拟合的模型。
简单的线性回归模型是整本书中唯一的模型,我们可以奢侈地生动地形象地看到梯度下降过程。当我们稍后遇到更复杂的模型时,请记住,梯度下降的本质保持不变:只是迭代地降低复杂的高维曲面的坡度,希望我们最终能在损耗非常低的地方结束。
图2.7 A. 使用梯度下降采取200次适中的步骤将参数设置引导到局部最优位置。注释突出显示了20、100和200次训练后的初始权重值。B.损失随时间变化的图,突出显示了对应的损失。C. 在训练10、20、100和200次后,由拟合模型体现的sizeMB与timeSec的函数。在此重复此操作,以使读者可以轻松比较损失表面位置和模型输出。请参阅codepen.io/tfjs-book/pen/JmerMM以使用此代码。
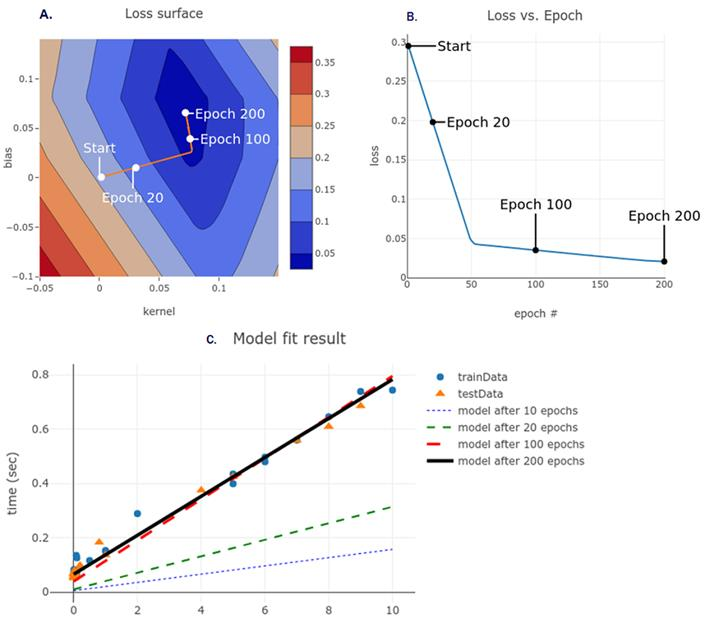
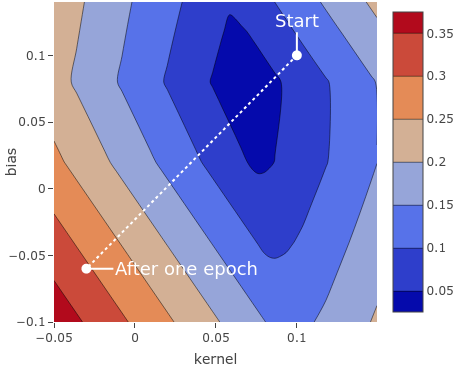
在最初的工作中,我们使用了默认的步长大小(由默认的学习率决定),但是在仅循环训练10次有限数据时,没有足够的步长来达到最佳值。200步就足够了。通常,如何设置训练次数?有一些有用的经验法则,我们将在本书的学习过程中进行介绍,但是没有一成不变的法则。如果我们训练次数太多,那么我们将无法在合理的时间内达到最佳参数。相反,如果我们使用太少的训练,我们将跳过最小值,甚至有可能比我们开始的地方遭受更大的损失。我们模型的参数需要在最优值附近剧烈波动,而不是直接采用快速方法。图2.8说明了当我们的梯度步幅太大时会发生什么。在更极端的情况下,这将导致参数值发散并变为Infinity ,这反过来又会在权重中生成NaN (非数字)值,从而完全破坏了模型。
图2.8 学习率过高时,梯度步长会过大,新参数可能会比旧参数差。这可能会导致振荡行为或某些其他不稳定性,从而导致不确定性或NaN。您可以尝试将CodePen代码中的学习率提高到0.5或更高,以查看此行为。
2.2.2 反向传播:内部梯度下降
上面,我们解释了更新权重的步长大小如何影响梯度下降的过程。但是,我们尚未讨论如何计算更新方向。方向对于神经网络的学习过程至关重要。它们由相对于权重的梯度确定,并且用于计算梯度的算法称为反向传播。反向传播技术是1960年代发明的,是神经网络和深度学习的基础之一。在本节中,我们将使用一个简单的示例来说明反向传播的工作原理。请注意,本节适用于希望了解反向传播的读者。对于只希望通过TensorFlow.js应用该算法的读者来说,这是不必要的,因为这些机制都很好地隐藏在tf.Model.fit()API下。这些读者可以跳过本节,继续阅读第2.3节。
简单的线性模型y’ = v * x。
其中x是输入要素,y'是预测输出。v是反向传播期间要更新的模型的唯一权重参数。假设我们使用平方误差作为损失函数,那么loss,v,x和y(实际目标值)之间具有以下关系:
loss = square(y’ - y) = square(v * x - y)
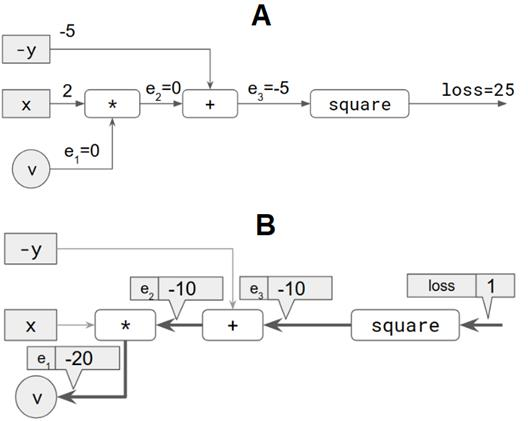
让我们假设以下具体值:两个输入分别为x = 2 和y = 5 ,权重值为v = 0 。然后可以将损失计算为25。这在下图中逐步显示。图2.9面板A中的每个灰色方块代表一个输入(即x 和y )。每个白框都是一个操作。共有三个操作。连接操作的边缘(以及将可调权重v 与第一个操作连接的边缘)标记为e1 ,e2 和e3 。
图2.9 通过仅具有一个可更新权重(v )的简单线性模型说明了反向传播算法。A :模型的正向传递:损失值是根据权重(v )和输入(x 和y )计算的。B :反向传递,从loss到v 逐步计算相对于v 的损耗梯度。
反向传播的重要步骤: “假设其他所有内容(在这种情况下,即x和y)保持不变,则如果v增加单位数量,我们将获得多少损失值变化”该量称为“相对于v的损耗梯度”。为什么我们需要这个梯度?因为一旦有了它,我们就可以在与其相反的方向上改变v ,这样我们就可以减少损失值。注意,我们不需要相对于x或y的损耗梯度,因为x和y不需要更新:它们是输入数据,并且是固定的。
该梯度是从损耗值开始逐步返回变量v的,逐步进行计算,如上面面板B的图2.9所示。进行计算的方向就是将该算法称为“反向传播” 的原因。让我们逐步进行操作。下面讨论的每个步骤都对应图中的粗箭头。
-
在标记为损失的边缘处,我们从1的梯度值开始。这很简单:“ 损失的增加对应于损失本身的单位增加”。
-
在标记为e3 的边缘,我们计算相对于e3的损耗梯度。因为该运算是一个平方,并且根据基本演算,我们知道x 2 相对于x 的导数(即,单变量情况下的梯度)为2 * x ,我们得到的梯度值为2 * -5 = -10 。将值-10与之前(即1)的梯度相乘,以获得边缘e3 :-10 上的梯度。这是损失的增加量,如果将e3的值增加1。正如您可能已经观察到的,我们使用的规则是从损失相对于一条边的梯度到下一条边的一个方面,即前一个梯度与当前节点上计算的梯度相乘。该规则有时称为链式规则。
-
在边缘e2处,我们计算e3 相对于e2 的梯度。由于这是一个简单的加法运算,因此无论y或-y的值如何,梯度都仅为1。将此1与边缘e3上的梯度相乘,我们得到边缘e2 上的梯度,即-10。
-
在边缘e1处,我们计算e2 相对于e1 的梯度。这里的运算是x 与v 之间的乘积,即x * v 。因此,相对于e1 (即相对于v )的e2 的梯度为x ,即2。将2的值与边缘e2上的梯度相乘得出最终梯度:2 * -10 = -20 。
到目前为止,我们已经获得了相对于v 的损耗梯度,即-20。为了应用梯度下降,我们需要将该梯度的负值与学习率相乘。假设学习率为0.01。然后我们得到一个梯度更新:
-(-20) * 0.01 = 0.2
这是我们将在此步骤中应用于v 的更新:
v = 0 + 0.2 = 0.2
如您所见,因为我们有x = 2和y = 5,并且要拟合的函数是y'= v * x,所以v的最佳值为5/2 = 2.5。经过一步训练,v的值从0变为0.2。换句话说,权重v 稍微接近所需值。在随后的训练步骤(忽略训练数据中的任何噪声)下,它将越来越近,这将基于与上述相同的反向传播算法。
上面的示例有意简化了,因此很容易理解。即使该示例捕获了反向传播的本质,但在实际的神经网络训练中发生的反向传播在以下方面与它有所不同:
- 除了提供简单的训练示例(在本例中为x = 2 和y = 5 )之外,通常会同时提供许多输入示例的批处理。所有单个示例的损耗值的算术平均值得出梯度的损耗值。
- 通常,需要更新更多元素。因此,会涉及矩阵演算,而不是像上面那样做简单的一元导数。
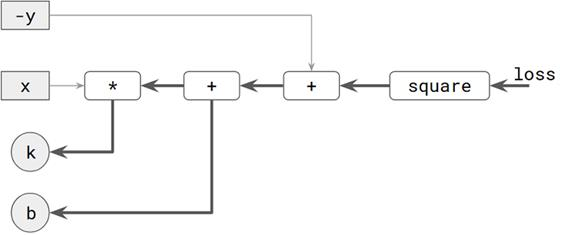
- 不只计算一个变量的梯度,而是通常涉及多个变量。下图(图2.10)显示了一个示例,该示例用于稍微复杂的线性模型,其中有两个要优化的变量。除了k之外,模型还有一个偏差项:y'= k * x + b 。这里有两个要计算的梯度,一个用于k,一个用于b。反向传播的两条路径都从损失开始。它们共享一些共同的边缘,并形成树状结构。 数字。
图2.10 显示了从loss到两个可更新的权重(k和b)的反向传播。
希望对反向传播的数学和算法有更深入了解的读者可以参考信息框2.2中的链接。
| 信息框2.2 | |
|---|---|
| 有关梯度下降和反向传播的进一步阅读 优化神经网络背后的微分运算肯定很有趣,并且可以洞悉这些算法的运行方式,但是除了基础知识外,对于机器学习从业人员也绝对不是必需条件,就像理解TCP / IP协议的复杂性一样,但对于了解如何构建Web应用程序而言并非至关重要。我们邀请好奇的读者探索以下出色的资源,以加深对网络中基于梯度的优化数学的理解。 反向传播演示滚动讲解插图https://google-developers.appspot.com/machine-learning/crash-course/backprop-scroll/ 斯坦福CS231讲座4-反向传播的课程讲义 cs231n.github.io/optimizatio… 安德烈· 卡帕蒂(Andrej Karpathy)的《哈克神经网络指南》karpathy.github.io/neuralnets/ |
在这一点上,您应该对从训练数据中拟合简单模型过程中会发生的事情有一个很好的了解,因此,让我们从解决微小的下载时间预测问题,延伸到使用TensorFlow.js解决一些更具挑战性的事情。在下一部分中,我们将构建一个模型,从多个输入中准确预测房地产价格。
