

1.2 为什么要将JavaScript和机器学习结合起来
机器学习,像人工智能和数据科学的其他分支一样,通常使用传统的后端语言,如Python和R,在web浏览器之外的服务器或工作站上运行[18]。这种现状并不奇怪。深度神经网络的训练通常需要一种多核和GPU加速的计算,而不是直接在浏览器中提供;有时训练这种模型所需的大量数据是最方便地从后端接收的,例如,从无限大的本机文件系统。
直到最近,许多人还认为“使用JavaScript进行深度学习”是一种新鲜事物。在本节中,我们将介绍为什么对于许多类型的应用程序,结合深度学习的能力和web浏览器创建独特的机会,特别是在TensorFlow.js的帮助下,使用JavaScript在浏览器环境中进行深度学习是一个明智的选择。
首先,机器学习模型一旦训练好,就必须部署到某个地方,为了对真实数据进行预测(如对图像和文本进行分类、检测音频或视频流中的事件等),而不部署,训练模型只是浪费计算能力。“某处”是一个web前端,这通常是可取的或必须的。本书的读者可能会意识到网络浏览器的整体重要性。在台式机和笔记本电脑上,浏览器是用户访问互联网内容和服务的主要手段。在浏览器上的时间是用户使用这些设备的大部分时间,远远超过第二位。这就是用户完成大量日常工作、保持联系和娱乐的方式。在web浏览器中运行的各种应用程序为应用客户端机器学习提供了丰富的机会。对于移动端,web浏览器在用户参与度和使用时间方面落后于移动应用程序。但是,移动浏览器仍然是一股不可忽视的力量,因为它们的范围更广、即时访问和更快的开发周期[19]。事实上,由于灵活性和易用性,许多移动应用程序(如Twitter、facebook等)针对某些类型的内容也会嵌入js开发的Web视图。
由于广泛使用,只要模型期望的数据类型在浏览器中可用,web浏览器便是部署深度学习模型的选择。但是浏览器中有哪些类型的数据?答案是很多!以深度学习最流行的应用为例:图像和视频中的分类,对象检测,语音转录,语言翻译,文本内容分析。web浏览器配备了可以说是最全面的技术和api来呈现(并在用户允许的情况下捕获)文本、图像、音频和视频数据。因此,强大的机器学习模型可以直接在浏览器中使用,例如,使用TensorFlow.js和简单的转换过程。在本书后面的章节中,我们将介绍在浏览器中部署深度学习模型的许多具体示例。例如,从网络摄像头捕获图像后,可以使用TensorFlow.js运行Mobilenet标记对象,运行YOLO2在检测到的对象周围放置边框,运行Lipnet进行唇读,或运行CNN-LSTM网络对图像添加标题。使用浏览器的WebAudio API从麦克风捕获音频后,TensorFlow.js可以运行模型来执行实时语音识别。还有一些令人兴奋的应用程序也有文本数据,例如为用户文本分配情感评分,如电影评论(第9章)。除了这些数据模式之外,现代网络浏览器还可以访问移动设备上的一系列传感器。例如,HTML5提供了对地理位置(纬度和经度)、运动(设备方向和加速度)和环境光的API访问[20]。再加上深度学习和其他数据方式,这些传感器的数据为许多令人兴奋的新应用打开了大门。
基于浏览器的深度学习应用还有五个好处:降低服务器成本、降低推理延迟、数据隐私、即时GPU加速和即时访问。
降低服务器成本。在设计和扩展web服务时,服务器成本通常是一个重要的考虑因素。及时运行深度学习模型所需的计算通常非常重要,因此必须使用GPU加速。如果模型没有部署到客户端,则需要将它们部署在GPU支持的机器上,例如,具有来自Google云或Amazon Web服务的CUDA GPU的虚拟机。这样的云GPU机器通常很昂贵。即使是最基本的GPU机器,目前每小时的成本也在0.5-1美元左右[21],[22]。随着流量的增加,云GPU机群的成本越来越高,更不用说可伸缩性和服务器堆栈的复杂性增加了。所有这些问题都可以通过将模型部署到客户端来消除。通过浏览器的缓存和本地存储功能(第2章),客户端下载模型(通常大小为几兆字节或更多)的开销可以得到缓解。
降低推理延迟。对于某些类型的应用程序,对延迟的要求非常严格,因此必须在客户端运行深度学习模型。任何涉及实时音频、图像和视频数据的应用程序都属于这一类。如果需要将图像帧传输到服务器进行推断,请考虑会发生什么情况。假设图像是以400×400像素的中等大小从网络摄像头捕获的,每个颜色通道有3个颜色通道(RGB)和8位深度,速率为每秒10帧。即使使用JPEG压缩,每个图像的大小也约为150kb。在一个具有大约300 kbps上传带宽的典型移动网络上,上传每个图像可以花费超过500毫秒,从而导致对于某些应用(例如,游戏)来说是明显的并且可能是不可接受的延迟。这个计算没有考虑到网络连接的波动(和可能的损失)、下载推断结果所需的额外时间以及大量移动数据的使用,每一个都可能是一个showstopper。客户端推断通过在设备上保留数据和计算来解决这些潜在的延迟和连接问题。如果没有纯粹在客户端运行的模型,就不可能运行实时机器学习应用程序,例如标记对象和检测网络摄像头图像中的姿势。即使对于没有延迟要求的应用程序,模型推断延迟的减少也会导致更高的响应性,从而改善用户体验。
数据隐私。将训练和推理数据留在客户端的另一个好处是保护用户的隐私。数据隐私的话题在今天变得越来越重要。对于某些类型的应用程序,数据隐私是绝对的要求。与健康和医疗数据相关的应用就是一个突出的例子。考虑一个“皮肤病诊断辅助工具”,它从网络摄像头收集患者皮肤的图像,并使用深度学习生成皮肤状况的可能诊断。许多国家的健康信息隐私法规不允许将图像传输到中央服务器进行推断。通过在浏览器中运行模型推断,任何数据都不需要离开用户的手机或存储在任何地方,从而确保用户健康数据的隐私。考虑另一个基于浏览器的应用程序,它使用深度学习为用户提供如何改进在应用程序中编写的文本的建议。有些用户可能会使用此应用程序编写敏感内容(如法律文档),并且对通过公共internet传输到远程服务器的数据感到不适。纯粹在客户端浏览器JavaScript中运行模型是解决这一问题的有效方法。
即时WebGL加速。除了数据的可用性之外,在web浏览器中运行机器学习模型的另一个先决条件是通过GPU加速获得足够的计算能力。如上所述,许多最先进的深度学习模型计算量非常大,因此必须在GPU上通过并行计算加速(除非您愿意让用户等待几分钟以获得单个推理结果,而这在实际应用中很少发生)。幸运的是,现代的web浏览器配备了WebGL API,尽管webgl api最初是为加速2D和3D图形的渲染而设计的,但它可以巧妙地用于加速神经网络所需的并行计算。js的作者在库中精心包装了基于WebGL的深度学习组件加速,因此可以通过一行JavaScript导入来获得加速。基于WebGL的神经网络加速可能无法与NVIDIA的CUDA和CuDNN(由TensorFlow和PyTorch等Python深度学习库使用)等本地、定制的GPU加速完美媲美,但它仍能使神经网络的速度提高一个数量级,并使人体姿态的Posenet提取等实时推理成为可能。
如果在预训练模型上进行推理是昂贵的,那么在这种模型上进行训练或转移学习就更为昂贵。训练和转移学习能够实现令人兴奋的应用,例如深度学习模型的个性化、深度学习的前端可视化以及联合学习(在许多设备上训练相同的模型,将训练结果聚合以获得良好的模型)。TensorFlow.js的WebGL加速使纯在web浏览器中以足够的速度训练或微调神经网络成为可能。
即时访问。一般来说,在浏览器中运行的应用程序具有“零安装”的自然优势:访问应用程序所需的一切就是键入URL或单击链接。这就避免了任何潜在的繁琐和容易出错的安装步骤,以及安装新软件时可能存在的风险访问控制。在浏览器深度学习的背景下,TensorFlow.js提供的基于WebGL的神经网络加速不需要特殊类型的图形卡,也不需要为这些图形卡安装驱动程序,这通常是一个不平凡的过程。最新台式机、笔记本电脑和移动设备配有可供浏览器和WebGL使用的图形卡。这些设备,只要安装了TensorFlow.js兼容的web浏览器(低条),就可以自动运行WebGL加速神经网络。这是一个特别吸引人的特点,在一些地方,方便获得是至关重要的。
| 利用GPU和WebGL加速计算 | |
|---|---|
| 信息框1.2 | 训练机器学习模型并将其用于推理需要大量的数学运算。例如,广泛使用的“密集”神经网络层涉及将一个大矩阵与一个向量相乘,并将结果添加到另一个向量。这种类型的典型操作涉及数千或数百万个浮点操作。这类操作的一个重要事实是它们通常是可并行化的。例如,将两个向量相加可分为许多较小的运算,即添加两个单独的数字。这些较小的操作并不相互依赖。例如,不需要知道索引0处两个向量的两个元素的和,就可以计算索引1处两个元素的和。因此,无论向量有多大,都可以同时执行较小的操作,而不是一次执行一个操作。串行计算,如向量加法的朴素CPU实现,称为单指令单数据(SISD)。GPU上的并行计算称为单指令多数据(SIMD)。与GPU相比,CPU计算每个单独的加法所需的时间通常更少。但数据到达一定数量,GPU的SIMD便会优于CPU的SISD。一个深层神经网络可能包含数百万个参数。对于给定的输入,可能需要数十亿个逐元素的数学运算才能运行(如果不是更多的话)。GPU所能实现的大规模并行计算在这种规模下更加有效。 |
图1.7 WebGL加速中如何利用GPU的并行计算能力实现比CPU更快的矢量运算。
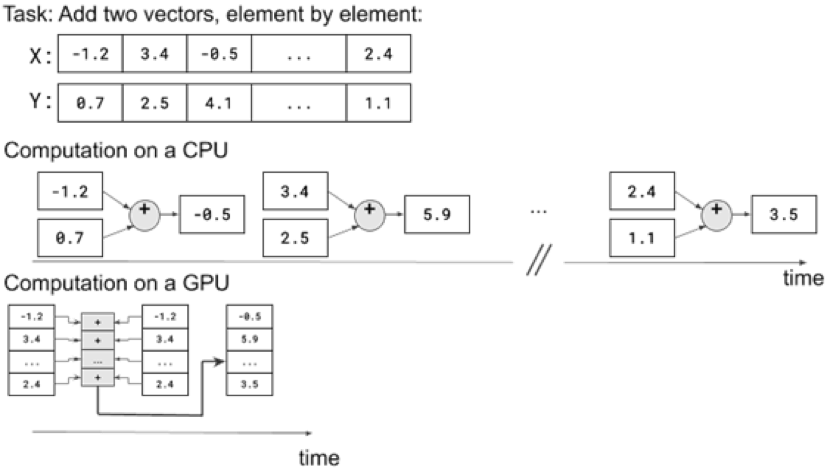
准确地说,现在的CPU也能够执行某些级别的SIMD指令。然而,GPU具有更多的处理单元(成百上千个),可以同时在输入数据的多个切片上执行指令。向量加法是一个相对简单的SIMD任务,因为计算的每一步只执行一个索引,不同索引的结果是相互独立的。在机器学习中其他SIMD任务更为复杂。例如,在矩阵乘法中,每个计算步骤都使用来自多个索引的数据,并且索引之间存在依赖关系。但通过并行化加速的基本思想不变。
有趣的是,GPU最初不是为加速神经网络而设计的。这从他们的名字中看出:图形处理单元。图形处理器的主要功能是处理二维和三维图形。在许多图形应用中,如3D游戏,关键是在尽可能短的时间内处理完成,以便屏幕上的图像能够以足够高的帧速率更新,以获得平滑的游戏体验。这是GPU的创造者利用SIMD并行化的最初动机。但是,令人惊喜的是,这种并行计算的GPU也满足了机器学习的需要。
TensorFlow.js用于GPU加速的WebGL库最初是为在web浏览器中渲染3D对象上的纹理(表面图案)等任务而设计的。但纹理只是数字数组!因此,我们可以假设这些数字是神经网络权重,重新利用WebGL的SIMD纹理来运行神经网络。这正是TensorFlow.js在浏览器中加速神经网络的方式。
除了上述优点外,基于web的机器学习应用程序与不涉及机器学习的一般web应用程序具有以下优点:
- 与本机应用程序开发不同,使用TensorFlow.js编写的JavaScript应用程序将在许多设备系列上均可工作,从Mac、Windows和Linux桌面到Android和iOS设备。
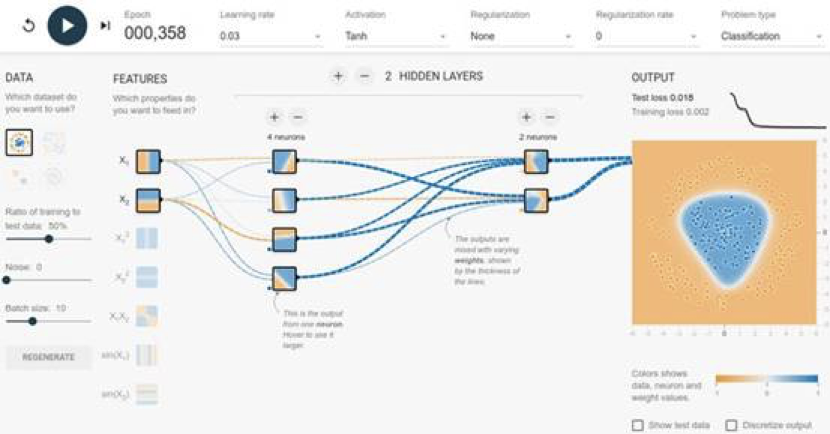
- 凭借其优化的二维和三维图形功能,web浏览器是数据可视化和交互性最丰富和成熟的环境。在展示神经网络行为和内部结构时,很难想象有哪种环境能胜过浏览器。以TensorFlow Playground(Playground.TensorFlow.org)为例。它是一个非常流行的web应用程序,你可以用神经网络交互式地解决分类问题。您可以调整神经网络的结构和超参数,并观察其隐藏层和输出结果如何变化(参见下面的图1.8)。如果你以前没有玩过,我们强烈建议你试试。许多人认为,这是他们所看到的关于神经网络主题的最有教育意义和最令人愉快的教材之一。TensorFlow Playground实际上是TensorFlow.js的重要前身。作为Playground的后代,TensorFlow.js拥有更广泛的深度学习能力和更优化的性能。此外,它还配备了一个专用组件,用于深度学习模型的可视化(详细内容见第7章)。无论您是想沿着TensorFlow Playground的路线构建基础教育应用程序,还是以直观、吸引人的方式展示您尖端深度学习研究,TensorFlow.js将帮助你朝着你的目标迈进一大步(参见实时tSNE嵌入可视化[23]等例子)。
图1.8 TensorFlow Playground(playground.tensorflow.org/)是一款基于浏览器的流… Smilkov和他在谷歌的同事完成。TensorFlow Playground也是后来TensorFlow.js项目的重要前身。
使用Node.js进行深入学习。出于安全和性能方面的原因,web浏览器被设计成一个资源受限的环境,即内存和存储配额有限。这意味着浏览器不是用大量数据训练大型机器学习模型的理想环境,尽管它非常适合许多利用较少资源的推理、小规模训练和转移学习任务。但是,Node.js完全弥补了这一不足。Node.js允许JavaScript在web浏览器之外运行,从而允许它访问所有本地资源,如RAM和文件系统。TensorFlow.js附带了Node.js版本,称为tfjs-node。它直接绑定了从C++和CUDA代码编译的本机编译库,因此用户可以使用与TensorFlow在Python中所使用的相同的并行CPU和GPU操作内核。经验上讲,tfjs-node的模型训练速度与Python中的Keras相当。因此,tfjs-node是一个适合于训练大数据量机器学习模型的环境。在本书中,您将看到一些例子,我们使用tfj-node来训练超出浏览器能力的大型模型(例如,第5章中的单词识别器和第9章中的文本情感分析器) 但是,选择Node.js而不是更成熟的Python环境来训练机器学习模型的可能原因是什么?答案是1)性能和2)兼容现有的堆栈和开发人员技能。首先,在性能方面,最先进的JavaScript解释器(例如Node.js使用的V8引擎)执行JavaScript代码的即时(JIT)编译,优于Python的性能。因此,在tfj-node中训练模型通常比在Keras(Python)中训练模型快,只要模型足够小,语言解释器的性能就是决定因素。其次,Node.js是一个非常流行的用于构建服务器端应用程序的环境。如果您的后端已经用Node.js编写,并且您希望将机器学习添加到堆栈中,那么使用tfjs-node通常比使用Python更好。通过将代码保持在一种语言中,您可以直接重用大部分代码,包括用于加载和格式化数据的部分,这将帮助您更快地建立训练模型。通过避免向堆栈中添加新语言,可以保持堆栈的复杂性和维护成本,从而节省了雇用Python程序员的时间和成本。
最后,除了可能依赖于仅浏览器或Node api的相关代码之外,用TensorFlow.js编写的机器学习代码将可以同时在浏览器环境和Node.js中工作。本书中您将遇到的大多数代码示例都可以在这两种环境中工作。我们将独立于环境、机器学习代码部分,特定环境的数据以及用户界面代码分开。这样的好处是,您只需学习一个库,就可以在服务器端和客户端进行深度学习。
JavaScript生态系统:在评估JavaScript是否适合某些类型的应用程序(如深度学习)时,不应忽视JavaScript是一种具有异常强大生态系统的语言这一因素。多年来,JavaScript在GitHub上的代码量和pull操作一直排在几十种编程语言的第一位[24]。事实上,截至2018年7月,在公共JavaScript存储库NPM上,有超过60万个JavaScript包。这是PyPI(Python公共存储库)中包数量的四倍多[25]。尽管Python和R有一个更好的机器学习和数据科学社区,JavaScript社区也在为机器学习相关的数据建立支持。如何从云存储和数据库中获取数据呢?Google云和Amazon Web服务都提供Node.js api。当今最流行的数据库系统,如MongoDB和RethinkDB,对Node.js驱动程序都有强大的支持。如何用JavaScript包装数据?我们推荐Ashley Davis的《JavaScript中的数据争论》一书[26]。如何可视化你的数据?有成熟而强大的库,如d3.js、vega.js和plotly.js,它们在许多方面都超过了Python可视化库。一旦你准备好了输入数据,本书的核心TensorFlow.js将从这里开始,帮助你创建、训练和执行你的深度学习模型,以及保存、加载和可视化它们。最后,JavaScript生态系统仍在以令人兴奋的方式不断发展。它的覆盖范围正在从传统的据点,即web浏览器和Node.js后端环境扩展到新的领域,如桌面应用程序(例如Electron)和本机移动应用程序(例如React native、Ionic)。为这样的框架编写UI和应用程序通常比使用大量匹配平台的应用程序创建工具更容易。JavaScript是一种有潜力为所有主要平台带来深度学习能力的语言。
下表总结了结合JavaScript进行深度学习的主要好处。
表1.2简要总结了使用JavaScript进行深入学习的好处
| JavaScript进行深入学习的好处 | |
|---|---|
| 与客户端相关的原因 | 1. 由于数据的局部性,减少了推理和训练延迟; 2. 在客户端脱机时运行模型的能力; 3. 隐私保护(数据永远不会离开浏览器); 4. 降低服务器成本; 5. 简化部署堆栈 |
| 与web浏览器相关的原因 | 1. 提供多种数据模式(HTML5视频、音频和传感器API)进行推理和训练; 2. 零安装用户体验; 3. 通过WebGL API在多种gpu上实现并行计算的零安装访问; 4. 跨平台支撑; 5. 可视化和交互性的理想环境; 6. 固有的互联环境可以直接访问机器学习数据和资源的各种来源 |
| 与JavaScript相关的原因 | 从许多方面来看,JavaScript是最流行的开源编程语言,因此有着JavaScript优势: 1. JavaScript在客户端和服务器端都有一个充满活力的生态系统和广泛的应用程序; 2. Node.js允许应用程序在服务器端运行,而不受浏览器的资源限制; 3. V8引擎使JavaScript代码运行迅速 |
1.2.1为什么选择TensorFlow.js?
要深入学习JavaScript,需要选择一个库。这本书的选择是TensorFlow.js。在本节中,我们将介绍什么是TensorFlow.js以及选择它的原因。
1.2.1.1 TensorFlow、Keras和TensorFlow.js简介
TensorFlow.js是一个库,使您能够在JavaScript中进行深度学习。顾名思义,TensorFlow.js被设计成与用于深度学习Python框架的TensorFlow一致和兼容。为了理解TensorFlow.js,我们需要简要地检查TensorFlow的历史。
TensorFlow于2015年11月由一个在谷歌从事深度学习的工程师团队开发。这本书的作者是这个小组的成员。自从TensorFlow开源发布以来,它获得了极大的普及。它现在被用于谷歌和更大技术社区的工业应用和研究项目。“TensorFlow”这个名字是为了反映用这个框架编写的典型程序中发生的事情:称为“tensors”的数据表现形式的流动是层和其他数据处理节点在机器学习模型上进行推理和训练的过程。
首先,什么是“张量”?这只是计算机科学家简明扼要地解释“多维数组”的一种方式。在神经网络和深度学习中,每一条数据和每一个计算结果都用张量表示。例如,灰度图像可以表示为2D数组的数据,即2D张量;彩色图像通常表示为3D张量,额外的维度是颜色通道。声音、视频、文本和任何其他类型的数据都可以用张量表示。每个张量都有两个基本属性:数据类型(如float32、int32)和形状。形状描述了张量沿其所有维度的大小。例如,2D张量可以具有形状[128,256],3D张量可以具有的形状[10,20,128]。一旦数据被转换成给定数据类型和形状的张量,它就可以输入到接受数据类型和任何类型形状的层中,而不管数据的原始含义如何。因此,张量是深度学习模式的通用语。
图1.9多个层的张量“流”,这是TensorFlow和TensorFlow.js中的常见场景。
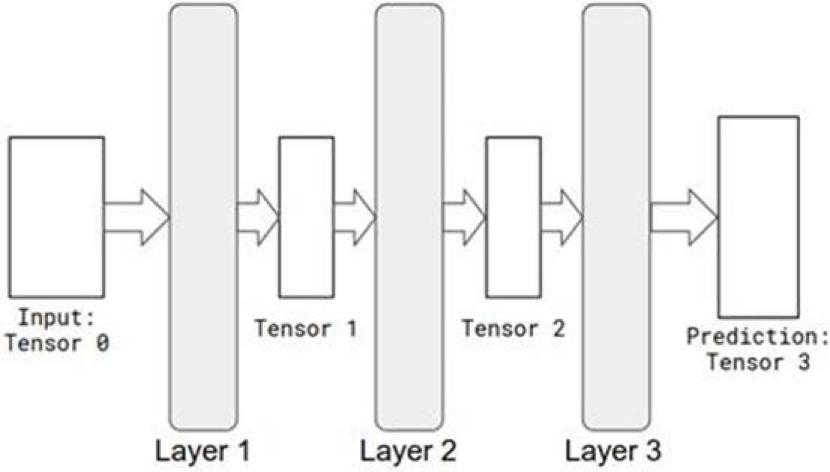
但为什么是张量呢?在前一节中,我们了解到运行深层神经网络所涉及的大部分计算是作为大规模并行操作执行的,通常在GPU上执行,这需要对多个数据块执行相同的计算。张量是将我们的数据组织成可以有效并行处理的结构的容器。当我们将形状为[128,128]的张量A添加到形状为[128,128]的张量B时,很明显需要进行128*128个独立的添加。
“流动”部分是什么样子?可以理解成张量是一种携带数据的流体。在TensorFlow中,它流经一个图,即由相互关联的数学运算(称为节点)组成的数据结构。如图1.9所示,节点可以是神经网络中的连续层。每个节点都将张量作为输入,并生成张量作为输出。当“张量流体”通过张量流图“流动”时,它被转换成不同的形状和不同的值。这对应于表示的转换,也就是神经网络所做工作的关键,正如我们在前面的章节中所描述的。利用TensorFlow,机器学习工程师可以编写各种各样的神经网络,从浅到深,从用于计算机视觉的卷积神经网络到用于序列任务的递归神经网络。图形数据结构可以序列化和部署并运行在多种类型的设备中,从大型机到移动电话。
最关键的是,TensorFlow被设计为非常的通用和灵活:操作可以是任何明确定义的数学函数,而不仅仅是神经网络层。例如,它们可以是低级的数学运算,例如两个张量的相加和相乘,即发生在神经网络层内的运算。这给了深度学习工程师和研究人员很大的权力来定义任意和新颖的深度学习操作。然而,对于大多数深度学习的实践者来说,操纵这样的低级机器比它的价值更麻烦。它会导致代码臃肿,更容易出错,开发周期更长。大多数深度学习的工程师使用少数固定层类型(例如卷积、池、密集,我们将在后面的章节中详细了解)。他们很少需要创建新的图层类型。这可以类似于乐高。在乐高中,只有少数的方块类型。乐高建设者不需要考虑做一个乐高积木需要什么。但这又不同于玩具,比如Play Doh,它类似于TensorFlow的低级API。然而,乐高积木也会带来大量的可能性和无限的能量。用乐高或Play Doh建造玩具屋是可能的,除非你对房子的大小、形状、质地或材料有非常特殊的要求,否则用乐高建造玩具屋要容易得多,也快得多。对我们大多数人来说,我们建造的乐高屋将比我们建造的Play Doh屋更稳固,看起来更漂亮。
在TensorFlow的世界里,LEGO的等价物是名为Keras[27]的高级API。Keras提供了一组最常用的神经网络层,每个层都有可配置的参数。它还允许用户将层连接在一起形成神经网络。此外,Keras还有以下的作用:
- 指定如何训练神经网络(损失函数、度量和优化器)
- 输入数据训练或评估神经网络或使用模型进行推理
- 监控正在进行的培训过程(回调)
- 保存和加载模型
- 打印或绘制模型的体系结构。 使用Keras,用户可以用很少的代码行执行完整的深入学习工作流。由于低级API的灵活性和高级API的可用性,TensorFlow和Keras形成了一个在工业和学术方面(28)采用的深层学习框架领域的生态系统。作为正在进行的深度学习革命的一部分,他们让更广泛的受众学习到深度学习。在TensorFlow和Keras等框架之前,只有那些具有CUDA编程技巧和丰富的C++编写神经网络经验的人才能够进行深度学习。使用TensorFlow和Keras,创建GPU加速的深层神经网络所需的技能和精力要少得多。
但有一个问题:不可能在JavaScript中或直接在web浏览器中运行TensorFlow或Keras模型。要在浏览器中提供训练有素的深度学习模型,必须通过对后端服务器的HTTP请求来实现。这就是TensorFlow.js出现的原因。TensorFlow.js是由Nikhil Thorat和Daniel Smilkov发起的,这两位专家在Google从事与深度学习相关的数据可视化和人机交互[29]。正如我们前面提到的,非常流行的“TensorFlow Playground”PPT中的一个深层神经网络植入了TensorFlow.js项目的初始种子。2017年9月,一个名为deeplearn.js的库发布。deeplearn.js有一个类似于TensorFlow的低级API。deeplearn.js支持WebGL加速神经网络操作,使得在web浏览器中运行推理延迟较低的神经网络成为可能。
在deeplearn.js取得初步成功后,Google Brain团队的更多成员加入了这个项目,并将该项目重命名为TensorFlow.js。JavaScript API经过了重大的改进,增强了API与TensorFlow的兼容性。此外,在底层核心之上构建了一个类似Keras的高级API,使用户可以更轻松地在JavaScript库中定义、训练和运行深层学习模型。今天,上面所说的关于Keras的强大和可用性的内容对于TensorFlow.js也是如此。为了进一步增强交互操作性,构建了转换器,使TensorFlow.js可以导入从TensorFlow和Keras保存的模型并将模型导出。自TensorFlow.js从2018年春季的全球TensorFlow开发者峰会[30]和Google I/O[31]上首次亮相以来,它迅速成为了一个非常受欢迎的JavaScript深度学习库,目前在GitHub上的类似库中拥有最多的star和fork(见附录A2)。
图1.10 TensorFlow.js的架构图。 显示了它与Python TensorFlow和Keras的关系。
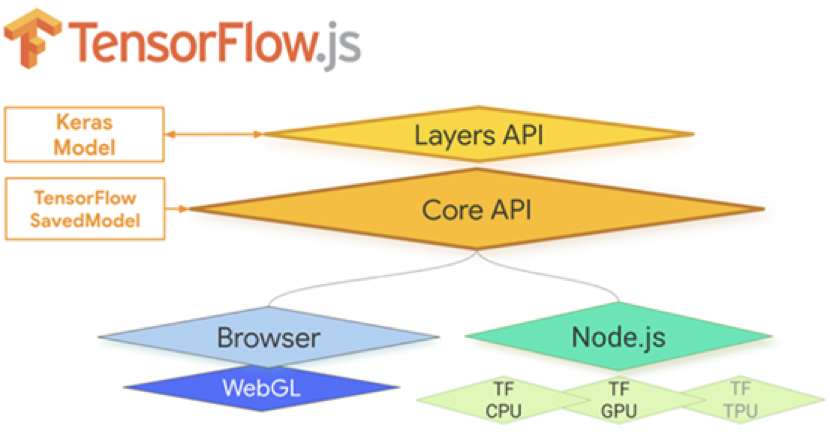
上图概述了TensorFlow.js的体系结构。最底层是负责数学运算的并行计算。这一层对大多数用户来说是不可见的,它们性能越高,越便于在更高级别的API中快速地进行模型训练和推理。在浏览器中,利用WebGL实现GPU加速(参见信息框1.2)。在Node.js中,可以直接绑定到多核CPU进行并行和CUDA GPU进行加速。这些是TensorFlow和Keras在Python中使用的相同方法。建立在最低级别上的是Ops API,它与TensorFlow的低级API具有良好的奇偶性,并支持从TensorFlow加载SavedModels。在最高级别上是类Keras层API。对于大多数使用TensorFlow.js的程序员来说,Layers API是正确的API选择,也是本书的重点。Layers API还支持使用Keras进行双向模型导入/导出。
1.2.1.2为什么选择TensorFlow.js:与类似库的简要比较
TensorFlow.js并不是用于深度学习的唯一JavaScript库,它也不是第一个出现的JavaScript库(例如brain.js和convnetjs的历史要长得多)。那么为什么TensorFlow.js在类似的库中脱颖而出呢?第一个原因是TensorFlow.js的全面性。附录A2提供了此类库与TensorFlow.js的特性比较。从表中可以看到,TensorFlow.js是当前唯一支持生产深度学习工作流所有关键部分的可用库:
-
支持推理和训练
-
支持web浏览器和Node.js
-
利用GPU加速(浏览器中的WebGL和Node.js中的CUDA内核)
-
支持在JavaScript中定义神经网络模型架构
-
支持模型的序列化和反序列化
-
支持与Python深度学习框架之间的转换
-
与Python深度学习框架的API兼容
-
提供内置数据和可视化的API
第二个原因是生态系统。大多数JavaScript深度学习库都定义了自己独特的API,而TensorFlow.js与TensorFlow和Keras紧密集成。您有一个来自Python TensorFlow或Keras的经过训练的模型,并希望在浏览器中使用它?没问题。你已经在浏览器中创建了一个TensorFlow.js模型,并想把它带到Keras中,以便访问更快的加速器,比如Google TPUs?那也行!与非JavaScript框架的紧密集成不仅提高了交互操作性,而且使开发人员更容易在编程语言和基础架构堆栈之间进行迁移。例如,一旦您通过阅读本书掌握了TensorFlow.js,您想在Python中开始使用Keras,它将是一帆风顺的。相反的过程同样简单:对Keras有很好了解的人应该能够快速学习TensorFlow.js(假设有足够的JavaScript技能)。最后也是重要的一点是,TensorFlow.js的受欢迎程度及其社区的实力不容忽视。js的开发人员致力于库的长期维护和支持。从GitHub的star和fork数到外部贡献者的数量,从讨论的活跃程度到StackOverflow上的问题和答案的数量,TensorFlow.js都没有受到任何竞争库的影响。
TensorFlow.js是如何被广泛使用的?
没有什么比库在实际应用中的使用方式更能令人信服地证明它的强大和受欢迎。以下列出了TensorFlow.js的几个应用:
- Google的Magenta项目使用TensorFlow.js运行RNNs和其他类型的深层神经网络,在浏览器中生成乐谱和新颖的乐器声音[32]。
- 纽约大学的Dan Shiffman和他的同事构建了ML5.js,这是一个易于使用的高级API,用于浏览器内使用的各种现成的深度学习,例如对象检测和图像样式传输[33]。
- 开源开发人员阿披实•辛格(Abhishek Singh)创建了一个基于浏览器的界面,将美国手语翻译成语音,帮助不会说话或听不见的人使用亚马逊回声(Amazon Echo)等智能扬声器[34]。
- Canvas Friends是一款基于TensorFlow.js的类似游戏的web应用程序,可以帮助用户提高绘画和艺术技能[35]。
- MetaCar是一个在浏览器中运行的自动驾驶汽车模拟器,它使用TensorFlow.js来实现对模拟至关重要的强化学习算法[36]。
- Clinic doctor是一个基于Node.js的应用程序,用于监控服务器端程序的性能,它使用TensorFlow.js实现了一个隐马尔可夫模型,并使用它来检测CPU使用率的峰值[37]。
- 参见TensorFlow.js的开源社区构建的其他优秀应用程序库:github.com/TensorFlow/…
1.2.2本书介绍和未介绍的关于TensorFlow.js的内容
通过学习本书中的材料,您应该能够使用TensorFlow.js构建如下应用程序:
- 对用户上传的图像进行分类的网站
- 深层神经网络,从浏览器连接的传感器接收图像和音频数据,并执行实时机器学习任务,如识别和传输学习
- 客户端自然语言AI,如评论情感分类器,以帮助评论更可信
- Node.js(后端)机器学习模型训练器,使用千兆字节级数据和GPU加速
- 一个支持TensorFlow.js的强化学习器,可以解决小规模控制和游戏问题
- 一个仪表板,用于说明训练模型的内部结构和ML实验的结果
重要的是,您不仅知道如何构建和运行这样的应用程序,而且还将了解它们是如何工作的。例如,您将实际了解为各种类型问题创建的深度学习模型所涉及的策略,以及训练和部署此类模型的步骤和问题。
机器学习是一个广阔的领域;TensorFlow.js是一个多功能的库。因此,一些应用程序可应用现有的TensorFlow.js技术,但超出了书中所涵盖的内容。例如:
- 在Node.js环境中,涉及大量数据高性能分布式训练的深度神经网络(按兆字节的顺序)
- 非神经网络技术,如支持向量机、决策树和随机森林
- 先进的深度学习应用程序,如文本摘要引擎,将大型文档简化为几个具有代表性的句子,从输入图像生成文本摘要的图像到文本引擎,以及增强输入图像分辨率的生成图像模型 这本书将带你了解基础的深度学习,你将学习到有关这些应用程序的代码和文章。
与其他任何技术一样,TensorFlow.js也有其局限性。有些任务是TensorFlow.js无法完成的。尽管这些限制在未来可能会被解决,但要知道截至2018年,目前的界限在哪里:
- 运行深度学习模型,内存需求超过浏览器选项卡中的RAM和WebGL限制。对于浏览器内推断,一个模型需要内存大于~100 MB。为了训练,需要更多的内存和计算,因此即使是较小的模型也可能太慢,无法在浏览器选项卡中训练。模型训练通常还涉及比推理更多的数据,这是评估浏览器内训练可行性时应考虑的另一个限制因素
- 创建一个高强化学习者,例如,能够在围棋游戏中击败人类玩家的那种
- 使用Node.js进行分布式(多机)训练深度学习模型
1.3总结
- 人工智能(AI)是研究认知任务的自动化。机器学习是人工智能的一个子领域,它通过学习训练数据中的实例,自动发现执行图像分类等任务的规则。
- 机器学习的一个中心问题是如何将数据的原始表示转换为更易于解决任务的表示。
- 神经网络是机器学习中的一种方法,其中数据表示的转换通过数学运算的连续步骤(即,层)来执行。深度学习领域涉及到深度神经网络,即具有多个层次的神经网络。
- 由于硬件的增强、标记数据的增加和算法的进步,自20世纪20年代初以来,深度学习领域取得了惊人的进展,解决了以前无法解决的问题,创造了令人兴奋的新机会。
- JavaScript和web浏览器是部署和训练深层神经网络的合适环境。
- TensorFlow.js是本书的重点,它是一个全面的、多功能的、强大的开源库,可用JavaScript进行深度学习。
1.4 练习
1.无论你是一个前端JavaScript开发人员还是Node.js开发人员,根据你在本章学到的知识,集思广益地讨论几个可能的案例,让机器学习应用到你正在开发的系统中,使其更加智能化。有关启示,请参阅表1.1和1.2以及上面题为“TensorFlow.js如何被广泛使用”的小节。其他一些例子:
2.一个销售太阳镜等配饰的时尚网站使用网络摄像头捕捉用户面部图像,并使用运行在TensorFlow.js上的深层神经网络检测面部标志点。然后,检测到的标志用来合成覆盖在用户脸上的太阳镜图像,以模拟网页上的试镜体验。这种体验是真实的,因为模拟的try-on可以在低延迟和高帧速率下运行,这要归功于客户端的推断。用户的数据隐私受到尊重,因为捕获的面部图像永远不会离开浏览器。
3.用React Native(一个用于创建本机移动应用程序的跨平台JavaScript库)编写移动体育应用程序跟踪用户身体锻炼行为。使用HTML5 API,应用程序可以从手机的陀螺仪和加速计访问实时数据。数据通过TensorFlow.js驱动的模型运行,该模型自动检测用户当前的活动类型(例如,休息与步行、慢跑与短跑)。
4.浏览器扩展会自动检测使用该设备的人是儿童还是成人(通过使用每5秒一次的帧速率从网络摄像头捕获的图像和TensorFlow.js支持的计算机视觉模型),并使用该信息相应地阻止或授权访问某些网站。
5.基于浏览器环境使用TensorFlow.js实现的递归神经网络来检测代码注释中的错误。
6.基于Node.js的服务器端应用程序,用于协调货物物流服务,使用实时信号,如承运人状态、货物类型和数量、日期/时间和交通信息,来预测每笔交易的预计到达时间(ETA)。训练和推理都是用Node.js编写的,使用TensorFlow.js,简化了服务器堆栈。
参考文献
[1] www.cv-foundation.org/openaccess/…
[2] www.cv-foundation.org/openaccess/…
[3] image-net.org/challenges/…
[8] magenta.tensorflow.org/demos
[11] jamanetwork.com/journals/ja…
[12] An important type of symbolic AI is expert systems. See this Britannica article to learn about them: www.britannica.com/technology/…
[13] In fact, such approaches have indeed been attempted before and did not work very well. This survey paper provides good examples of handcrafting rules for face detection before the advent of deep learning: www.sciencedirect.com/science/art…
[14] Another style of machine learning is , in which unlabeled data are used. Examples of unsupervised learning are clustering (discovering distinct subsets of examples in a dataset) and anomaly detection (determine is a given example is sufficiently different from the examples in the training set).unsupervised learning
[15] Tessier-Lavigne, M. (2000) “Visual Processing by the Retina” In Kandel, E. R., Schwartz, J. H., and Jessell, T. M. “Principles of Neural Science (4th Edition)” pp. 507-522, McGraw-Hill.
[16] For a compelling example of similarity in functions, see the inputs that maximally activate various layers of a convolutional neural network (see Chapter 4), which closely resemble the neuronal receptive fields of various parts of the human visual system.
[17] www.theatlantic.com/technology/…
[18] analyticsindiamag.com/top-10-prog…
[19] dazeinfo.com/2017/04/12/…
[20] mobilehtml5.org/
[23] www.googblogs.com/realtime-ts…
[24] githut.info/
[26] Davis A. (2018). Data Wrangling in JavaScript (MEAP Edition). Manning Publications. manning-content.s3.amazonaws.com/download/6/…
[27] In fact, since the introduction of TensorFlow, a number of high-level APIs have emerged, some created by Google engineers and others by the open-source community. Among the most popular ones are Keras, tf.Estimator, tf.contrib.slim and TensorLayers. For the readers of this book, the most relevant high-level API to TensorFlow.js is Keras by far, because the high-level API of TensorFlow.js is modeled after Keras and because TensorFlow.js provides two-way compatibility in model saving and loading with Keras.
[29] As an interesting historical note, these authors also played key roles in creating TensorBoard, the popular visualization tool for TensorFlow models.
[30] www.youtube.com/watch?v=YB-…
[31] www.youtube.com/watch?v=Omo…
[32] magenta.tensorflow.org/demos/
[33] ml5js.org/
