一.从输入url到页面响应的整个宏观过程
1.输入了一个url地址
2.浏览器查找域名的IP地址
- DNS查找
- 浏览器缓存:在浏览器缓存中查找DNS,每个浏览器缓存时间不同
- 系统缓存:如果浏览器缓存没找到就在系统缓存中使用
gethostbyname查找
- 路由器缓存:在路由器中查找DNS缓存
- ISP的DNS缓存
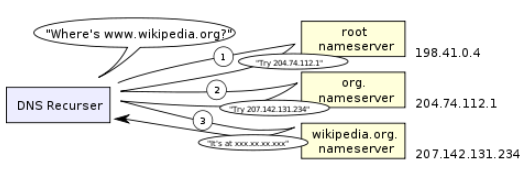
- 递归搜索:从根域名服务器开始递归搜索,从.com顶级服务器到域名服务器
3.浏览器给web服务器发送HTTP请求
GET http:
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
- HTTP请求:
- Connection要求服务器为了后面的请求不要关闭TCP连接
- cookies跟踪网站状态匹配的键值。会存储登录用户名,密码和一些用户设置。以文本形式存储在客户机中,每次请求的时候发给服务器。
- 斜杠问题
http://facebook.com/最后的斜杠是必要的- 不加斜杠浏览器不清楚到底是文件夹还是文件
- 这样服务器会响应一个重定向,造成不必要的握手
4.服务器的永久重定向响应
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
- 服务器给浏览器响应一个301永久重定向响应
- 让浏览器访问
http://www.facebook.com/而不是http://facebook.com/
- 原因:
- 搜索引擎会认为这是两个地址,而搜索引擎知道301永久重定向,就会把www和不带www的地址归到一个网站
- 不同的地址会占缓存
5.浏览器跟踪重定向地址
GET http:
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
6.服务器"处理"请求
- 服务器处理请求并返回响应
- web服务器软件
- web服务器软件收到HTTP请求确定执行什么请求处理并生成HTML
- 就是将地址映射为服务器的文件地址
- 请求处理
- 阅读请求及其参数和cookies
- 也会更新数据,并将数据存储在服务器上
- 生成HTML响应
7.服务器发回HTML响应
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
- 以blob类型传输,整个响应体用gzip算法压缩
- Content-type是text/html,让浏览器以HTML形式呈现
8.浏览器开始显示HTML
9.浏览器发送GET请求获取嵌入在HTML中的对象
- 浏览器显示过程中,发现需要获取其他地址内容,此时发送请求获取文件

- 过程同上
- 这些静态文件会允许浏览器缓存
- 服务器的响应会包含缓存的期限信息
- 通常网站会使用第三方CDN(内容分发网络)
10.浏览器发送异步(AJAX)请求
- 页面一直保持与服务器连接状态
- 更新页面时会通过js代码给服务器发送异步请求
二.其中数据包在这个网络通信过程中的经历
1.应用层
2.传输层
- 这些数据通过传输层发送,使用协议(TCP...)
- 这里包上head,包含端口号,tcp的各种信息。组成tcp数据传送单位segment。
- 利用这些信息发送的一方不断发送等待确认,发送一个数据段后,开启一个计数器,当收到确认后才发送下一个,如果超过技术时间仍未收到确认则重发
- 接收端收到错误数据就丢弃,这就使得发送端超时重发
- tcp协议控制了数据报的发送序列的产生,实现流量控制和数据完整。
3.网络层
- 这些发送的数据送到网络层,继续打包,包上网络层的head
- head包含源,目的的ip地址,这层的数据单元称为packet
- 网络层负责如何穿过路由器,到达目的地址
- 根据目的ip地址查找下一跳路由地址
- 在本机查找本机的路由表route print
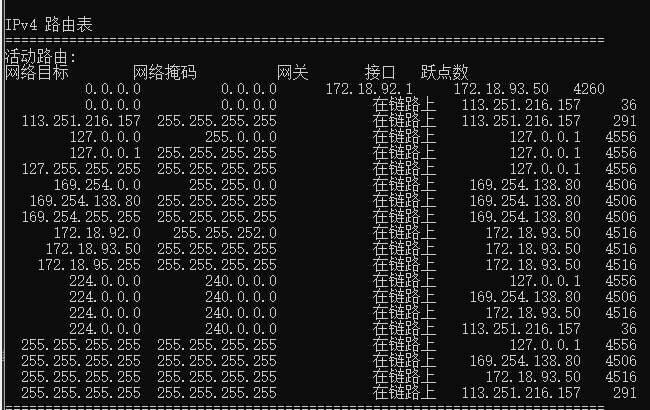
- 查找过程:
- 根据目的地址,得到目的网络号,如果在同一个内网,则直接放松
- 如果不在同一个内网,则查询路由表,找到下一个路由
- 如果找不到明确的路由,通过默认网关将数据传送给下一个指定的路由,所以网关也可能是路由器,也可能只是个网关
- 路由器收到数据后,再次查询下一路由,若找不到就通过默认网关地址。数据包中含有一个最大路由跳数,如果超过这个跳数就会丢弃数据报,这可防止无限传递
- 路由器收到数据包后,只会查看网络层的数据,目的ip,所以传输层的数据对它来说是透明的
- 查找到下一跳ip地址后,还需要知道它的mac地址,要作为链路层数据的头部。这时候需要arp协议
- 查找arp缓冲 arp -a可查看
- 如果里面含有对应ip的mac地址就直接返回
- 没有就需要发生arp请求,该请求包含源ip和源mac地址以及目的ip地址,在网内进行广播,所有主机会检查自己的ip和目的ip是否一样,如果一样就返回自己的mac地址,并将请求的ip mac都保存
- 这样就得到了目的ip的mac地址
3.链路层
- 将mac地址和链路层控制信息加入数据包中,形成Frame
- Frame在链路层写一下完成相邻节点之间的数据传输,建立连接,控制传输速度,数据完整
4.物理层
- 物理线路只负责将数据以bit为单位传输到下一个目的地
5.接收端
p.s.
三.TCP/IP的基本模型和基本概念
- 物理层
- 设备,中继器repeater,集线器hub。
- 这一层来说,一个端口收到数据会转发到所有端口
- 链路层
- SDLC HDLC ppp协议
- 网卡,网桥,集线器modem(存议
- 所有交换机需要工作在数据链路层,但仅仅工作在链路层的是二层交换机
- 其他什么三层,四层,七层交换机工作范围包括很大,但基本功能在二层
- 有了mac地址表才避免了冲突,交换机通过目的mac地址知道把数据转发到哪个端口,不像hub转发到所有端口,所以交换机是可以划分冲突域的
- 网络层
- 网际协议IP:负责在主机和网络之间寻址,和路由数据包
- 地址解析协议ARP:获得同一物理网络中的硬件主机地址
- 网际控制消息协议ICMP:发送消息报告有关数据报的传送错误
- 互联组管理协议IGMP:被IP主机哪来向本地多路广播路由器报告主机组成员
- 这层设备有三层交换机,路由器
- 传输层
- TCP和UDP
- 端口的概念
- TCP/UDP使用IP地址标识网上主机,使用端口号标识应用程序。
- 端口号是16位的无符号整数,TCP和UDP的端口号是两个独立的序列。
- 利用端口号,一台主机上多个进程可以同时使用TCP/UDP提供的传输服务,并且是端到端的,数据由IP传递,但与IP数据报的传递路径无关。
- 通过三元组唯一标识一个应用进程:协议+本地地址+本地端口号
- tcp和udp可以使用相同的端口
- 通过(协议+源端口+源ip+目的端口+目的ip)可以标识一组网络连接
- 应用层
- 基于tcp的有 Telnet FTP SMTP DNS HTTP
- 基于UDP的有 RIP NTP DNS SNMP TFTP


