

一致性算法
Raft 算法
概念
term:任期,比如新的选举任期,即整个集群初始化时,或者新的Leader选举就会开始一个新的选举任期。 大多数:假设一个集群由N个节点组成,那么大多数就是至少N/2+1。例如:3个节点的集群,大多数就是至少2;5个节点的集群,大多数就是至少3。 状态:每个节点有三种状态,且某一时刻只能是三种状态中的一种:Follower(图左),Candidate(图中),Leader(图右)。假设三种状态不同图案如下所示:

Leader选举
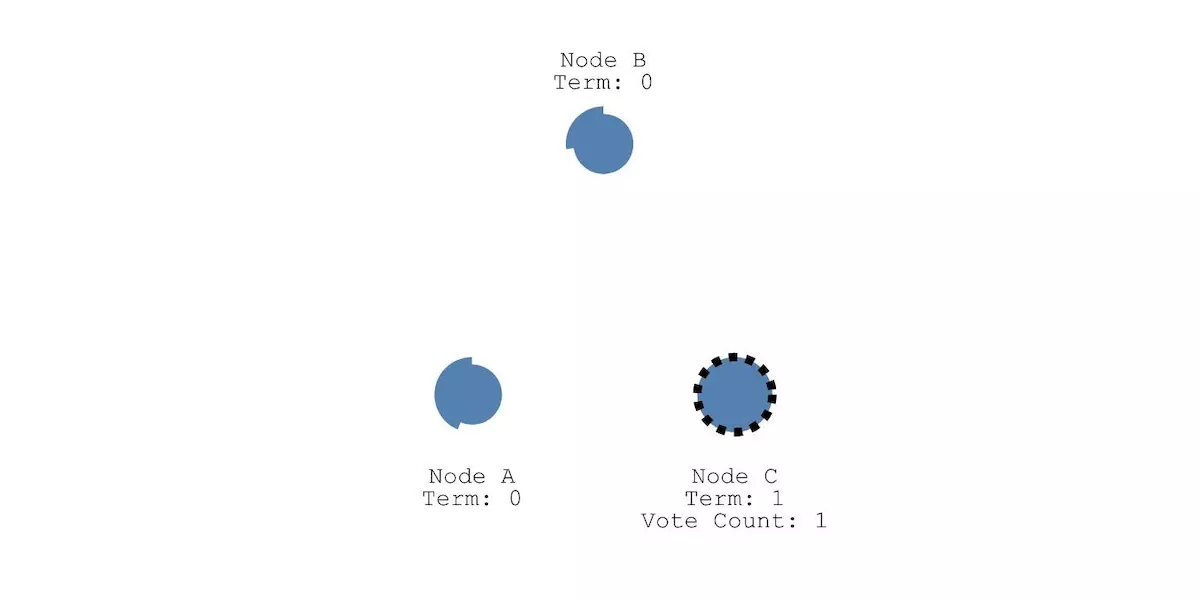
Leader选举需要某个节点发起投票,在确定哪个节点向其他节点发起投票之前,每个节点会分配一个随机的选举超时时间(election timeout)。在这个时间内,节点必须等待,不能成为Candidate状态。现在假设节点a等待168ms , 节点b等待210ms , 节点c等待200ms 。由于a的等待时间最短,所以它会最先成为Candidate,并向另外两个节点发起投票请求,希望它们能选举自己为Leader:
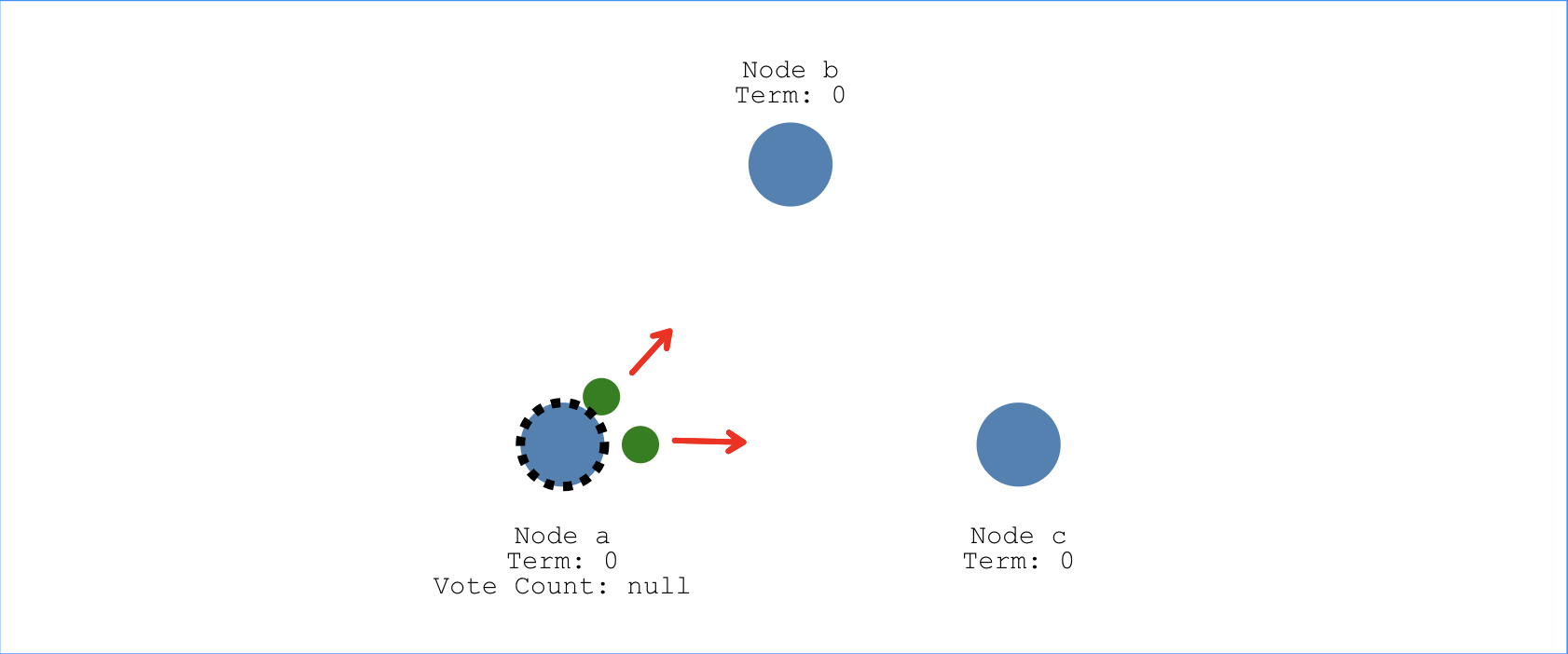
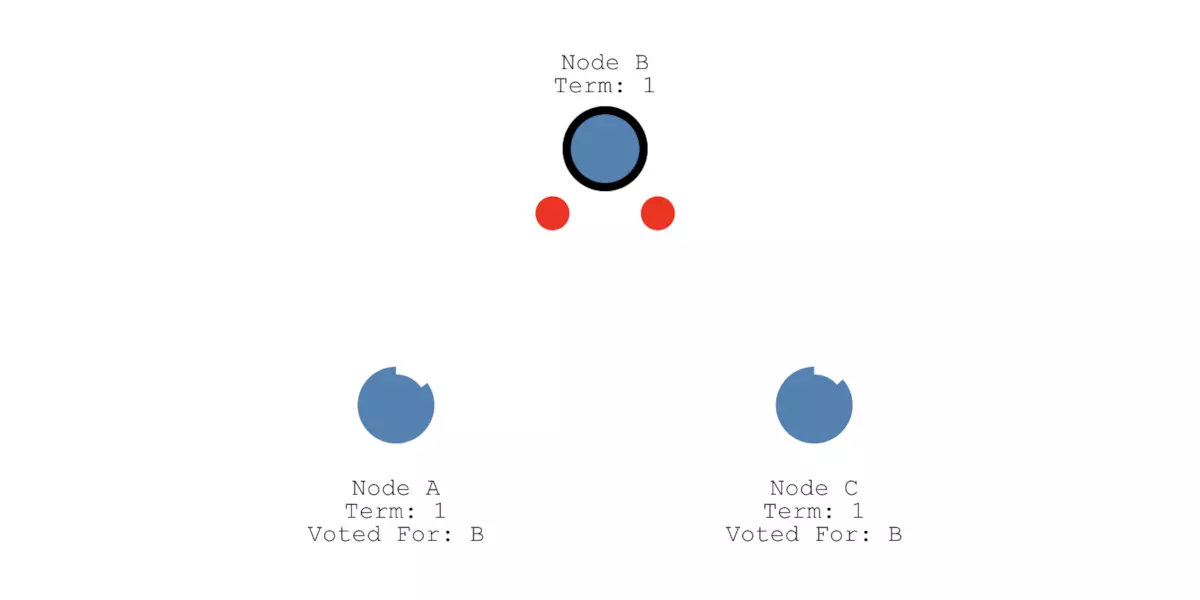
另外两个节点收到请求后,假设将它们的投票返回给Candidate状态节点a,节点a由于得到了大多数节点的投票,就会从Candidate变为Leader,如下图所示,这个过程就叫做Leader选举(Leader Election)。接下来,这个分布式系统所有的改变都要先经过节点a,即Leader节点:
图片: uploader.shimo.im/f/gtd72cGJI… 如果某个时刻,Follower不再收到Leader的消息,它就会变成Candidate。然后请求其他节点给他投票(类似拉票一样)。其他节点就会回复它投票结果,如果它能得到大多数节点的投票,它就能成为新的Leader。 日志复制
假设接下来客户端发起一个SET 5的请求,这个请求会首先由leader即节点a接收到,并且节点a写入一条日志。由于这条日志还没被其他任何节点接收,所以它的状态是uncommitted。
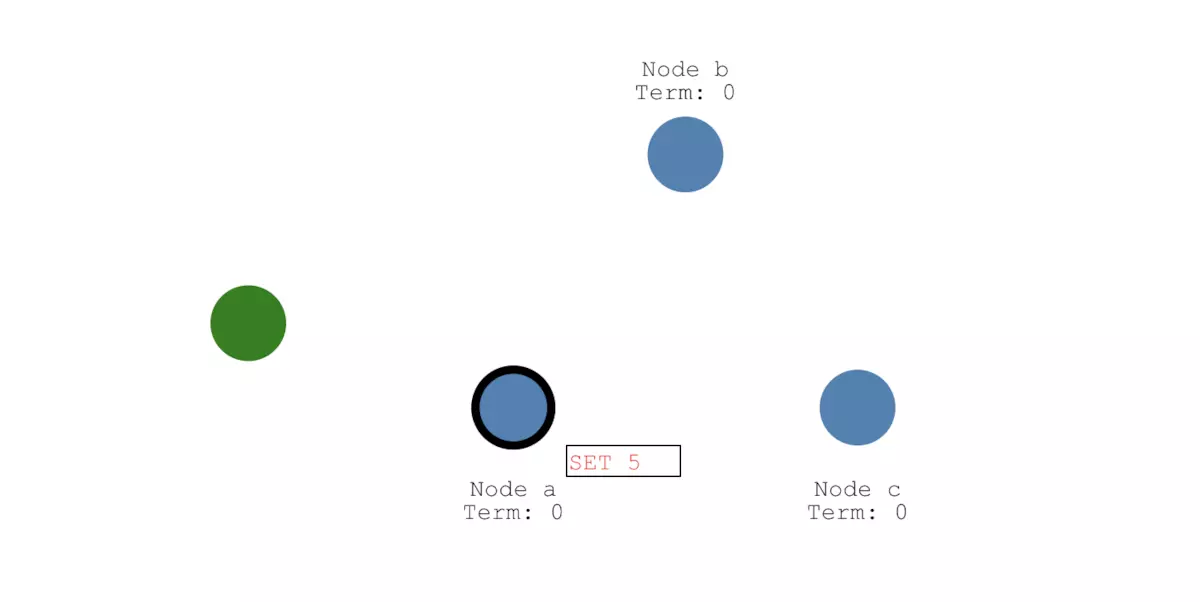
为了提交这条日志,Leader会将这条日志通过心跳消息复制给其他的Follower节点:
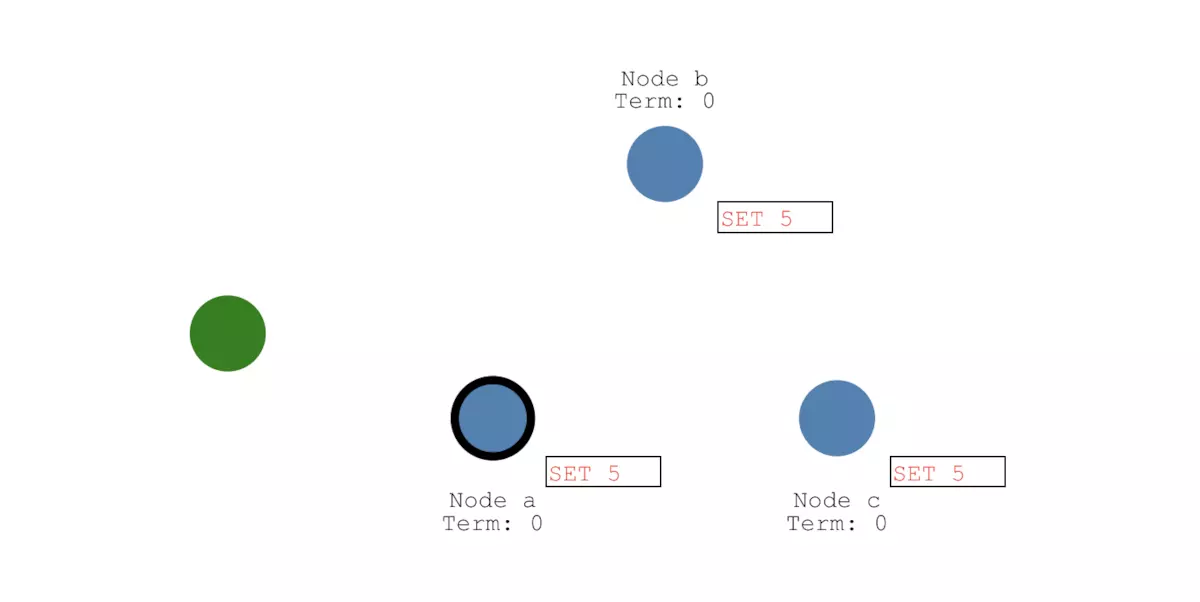
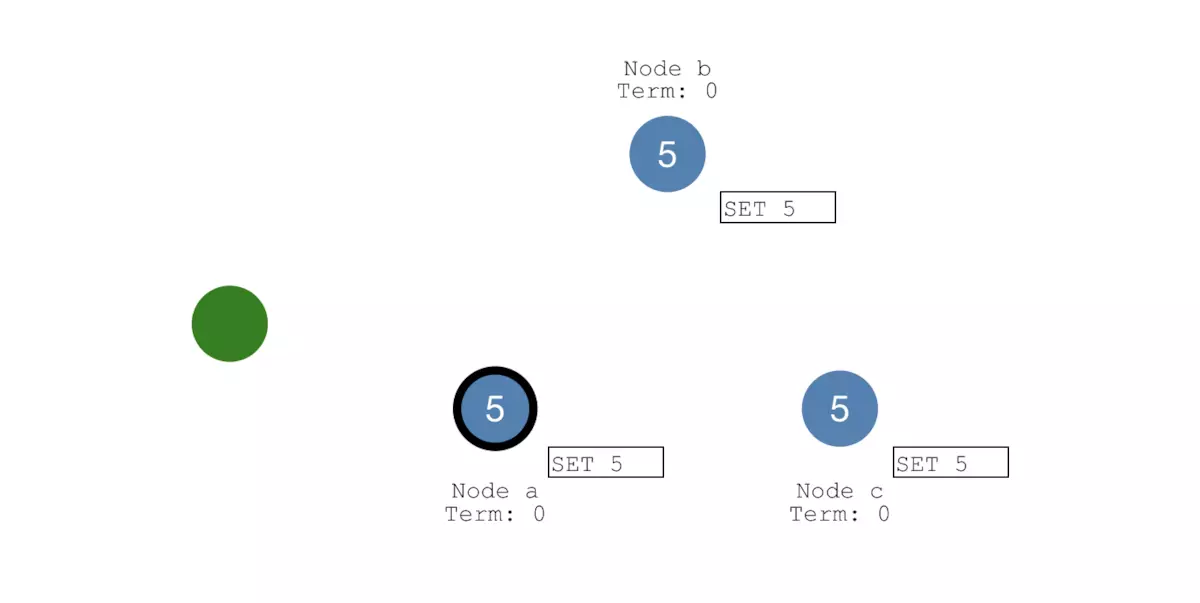
一旦有大多数节点成功写入这条日志,那么Leader节点的这条日志状态就会更新为committed状态,并且值更新为5:
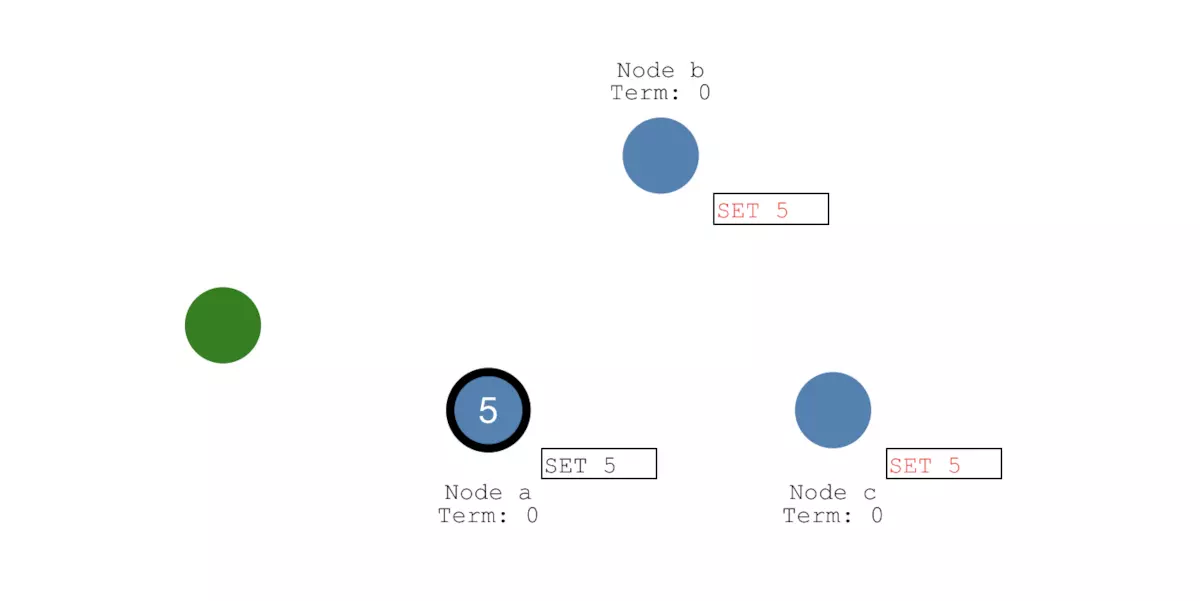
Leader节点然后通知其他Follower节点,其他节点也会将值更新为5。如下图所示,这个时候集群的状态是完全一致的,这个过程就叫做日志复制(Log Replication):
两个超时
接下来介绍Raft中两个很重要的超时设置:选举超时和心跳超时。
选举超时
为了防止3个节点(假设集群由3个节点组成)同时发起投票,会给每个节点分配一个随机的选举超时时间(Election Timeout),即从Follower状态成为Candidate状态需要等待的时间。在这个时间内,节点必须等待,不能成为Candidate状态。如下图所示,节点C优先成为Candidate,而节点A和B还在等待中:
选举超时
心跳超时
如下图所示,节点A和C投票给了B,所以节点B是leader节点。节点B会固定间隔时间向两个Follower节点A和C发送心跳消息,这个固定间隔时间被称为heartbeat timeout。Follower节点收到每一条日志信息都需要向Leader节点响应这条日志复制的结果:
心跳超时
重新选举
选举过程中,如果Leader节点出现故障,就会触发重新选举。如下图所示,Leader节点B故障(灰色),这时候节点A和C就会等待一个随机时间(选举超时),谁等待的时候更短,谁就先成为Candidate,然后向其他节点发送投票请求:
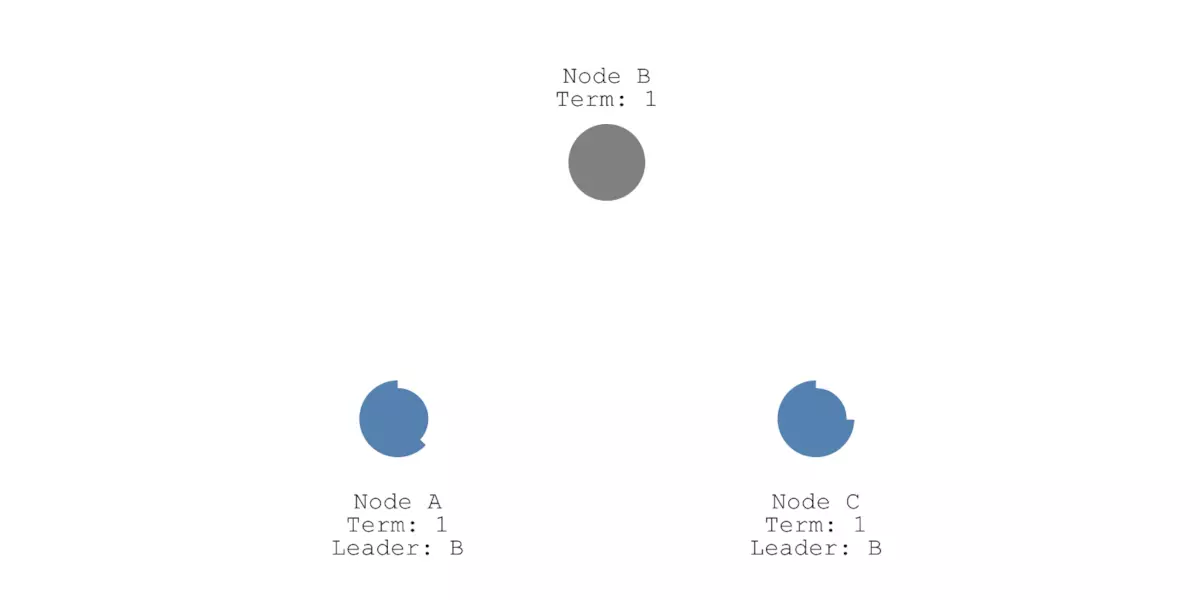
re-election
如果节点A能得得到节点C的投票,加上自己的投票,就有大多数选票。那么节点A将成为新的Leader节点,并且Term即任期的值加1更新到2:
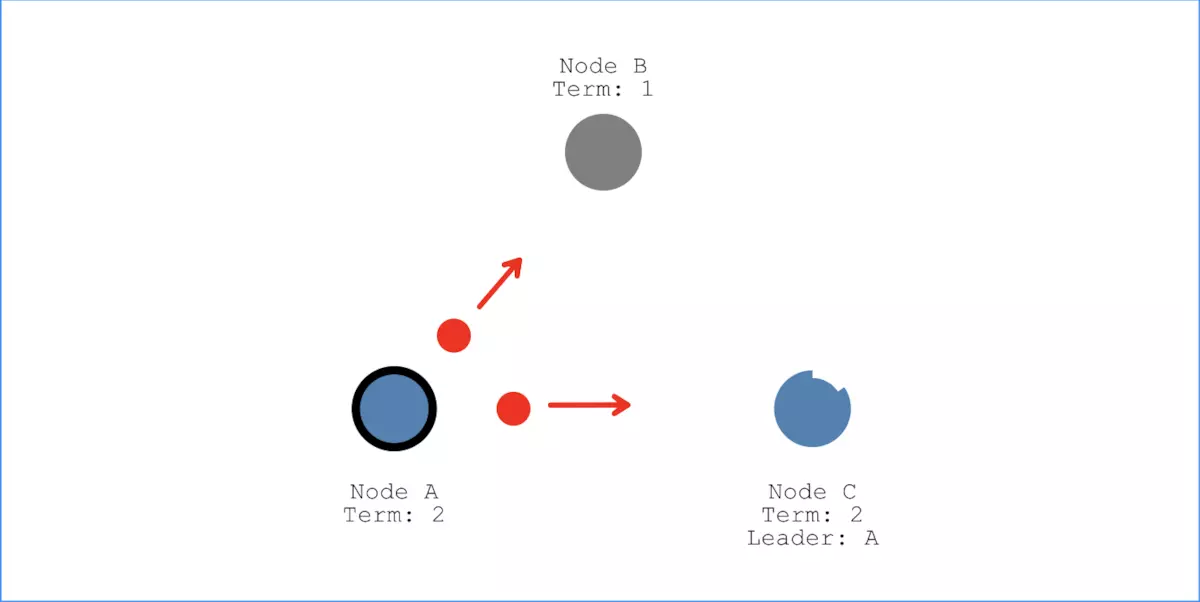
新Leader节点
需要说明的是,每个选举期只会选出一个Leader。假设同一时间有两个节点成为Candidate(它们随机等待选举超时时间刚好一样),如下图所示,并且假设节点A收到了节点B的投票,而节点C收到了节点D的投票:
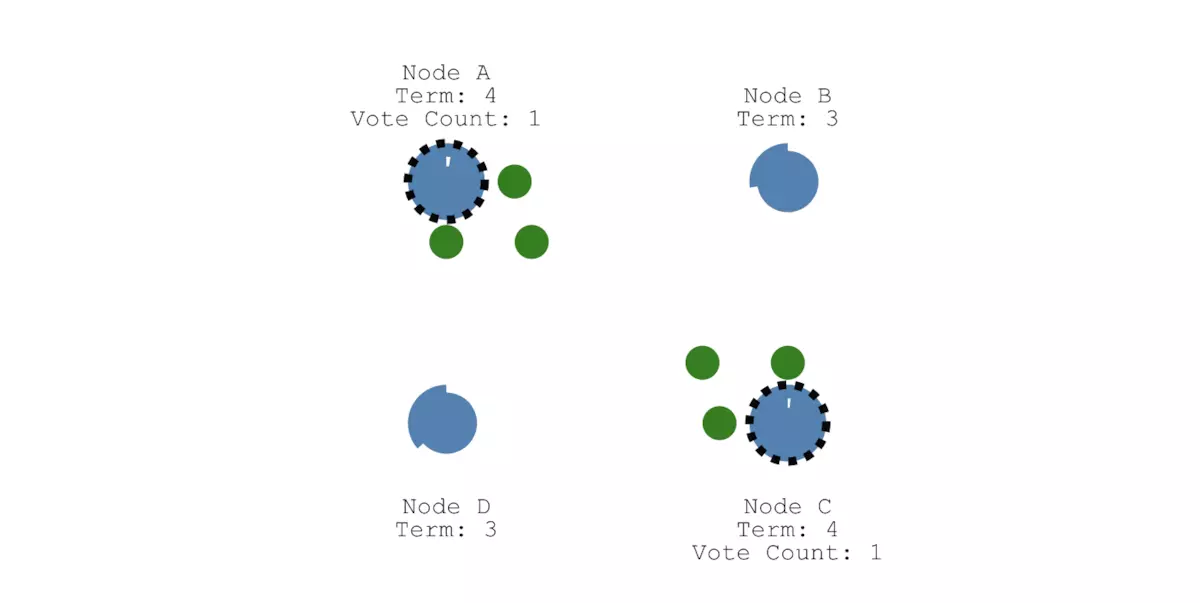
2个Candidate节点
这种情况下,就会触发一次新的选举,节点A和节点B又等待一个随机的选举超时时间,直到一方胜出:
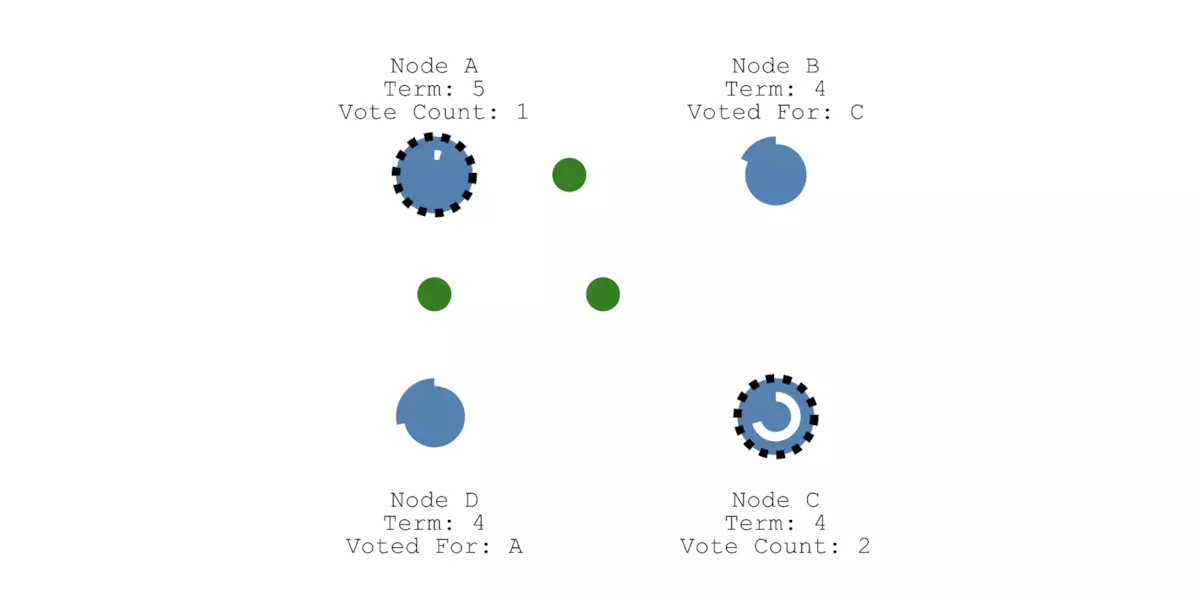
我们假设节点A能得到大多数投票,那么接下来节点A就会成为新的Leader节点,并且任期term加1:
网络分区
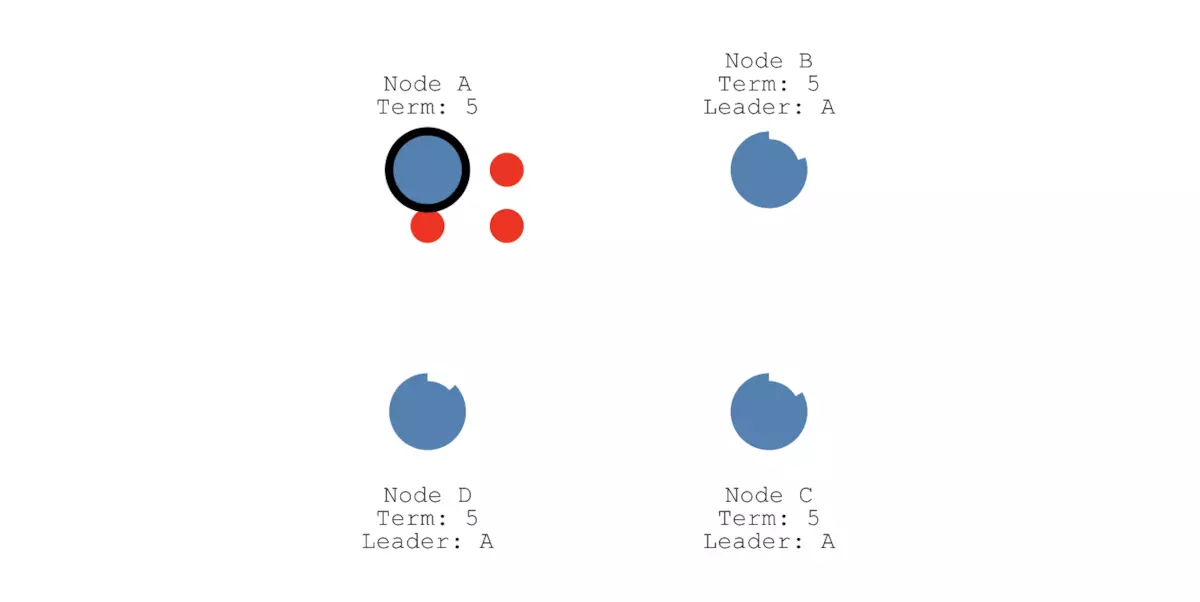
在发生网络分区的时候,Raft一样能保持一致性。如下图所示,假设我们的集群由5个节点组成,且节点B是Leader节点:
5个节点的集群
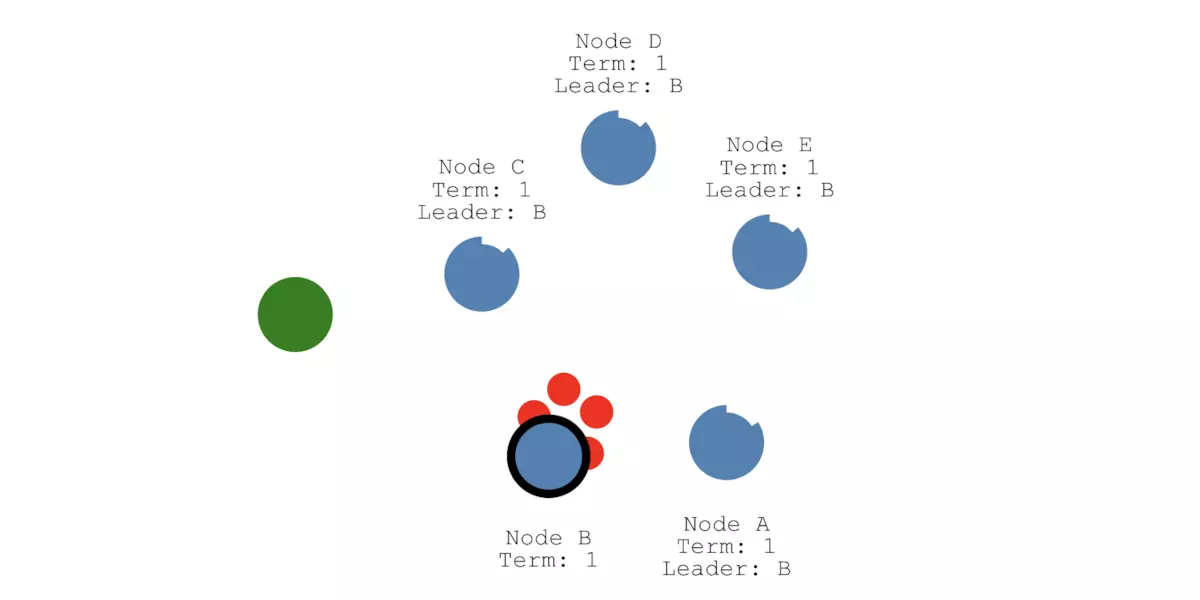
我们假设发生了网络分区:节点A和B在一个网络分区,节点C、D和E在另一个网络分区,如下图所示,且节点B和节点C分别是两个网络分区中的Leader节点:
发生网络分区
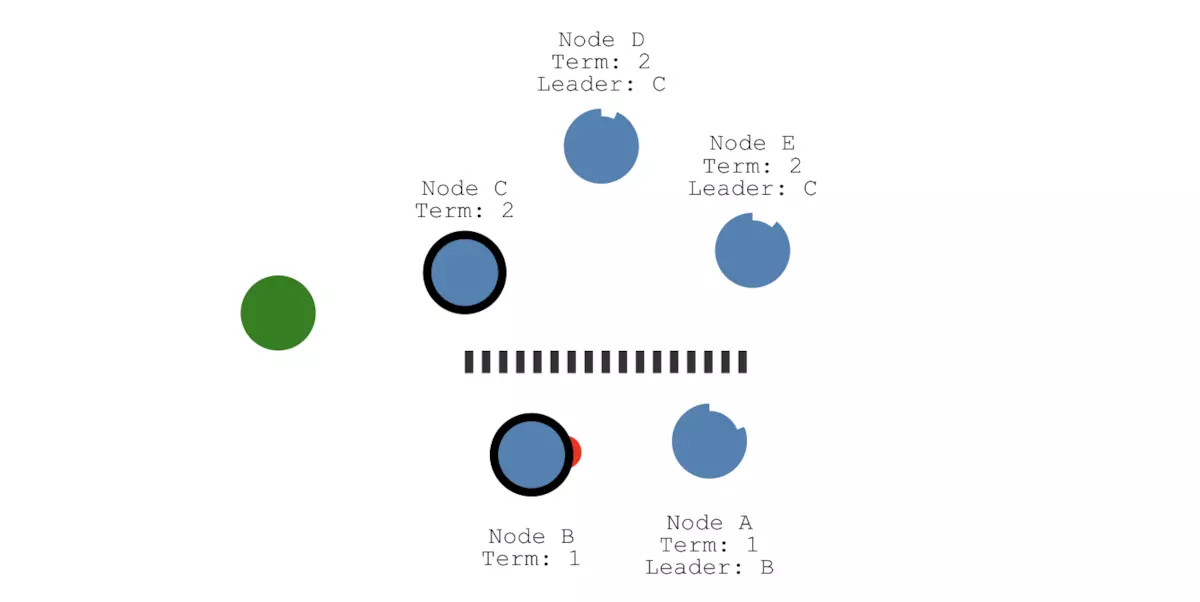
我们假设还有一个客户端,并且往节点B上发送了一个SET 3,由于网络分区的原因,这个值不能被另一个网络分区中的Leader即节点C拿到,它最多只能被两个节点(节点B和C)感知到,所以它的状态是uncomitted(红色):
操作1
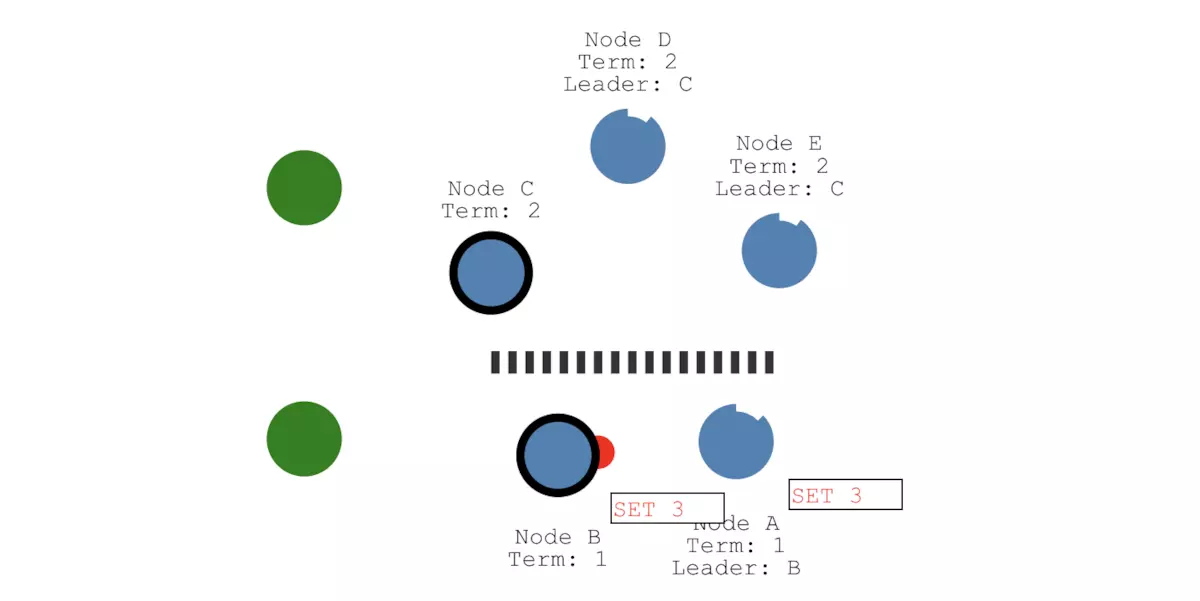
另一个客户端准备执行SET 8的操作,由于可以被同一个分区下总计三个节点(节点C、D和E)感知到,3个节点已经符合大多数节点的条件。所以,这个值的状态就是committed:
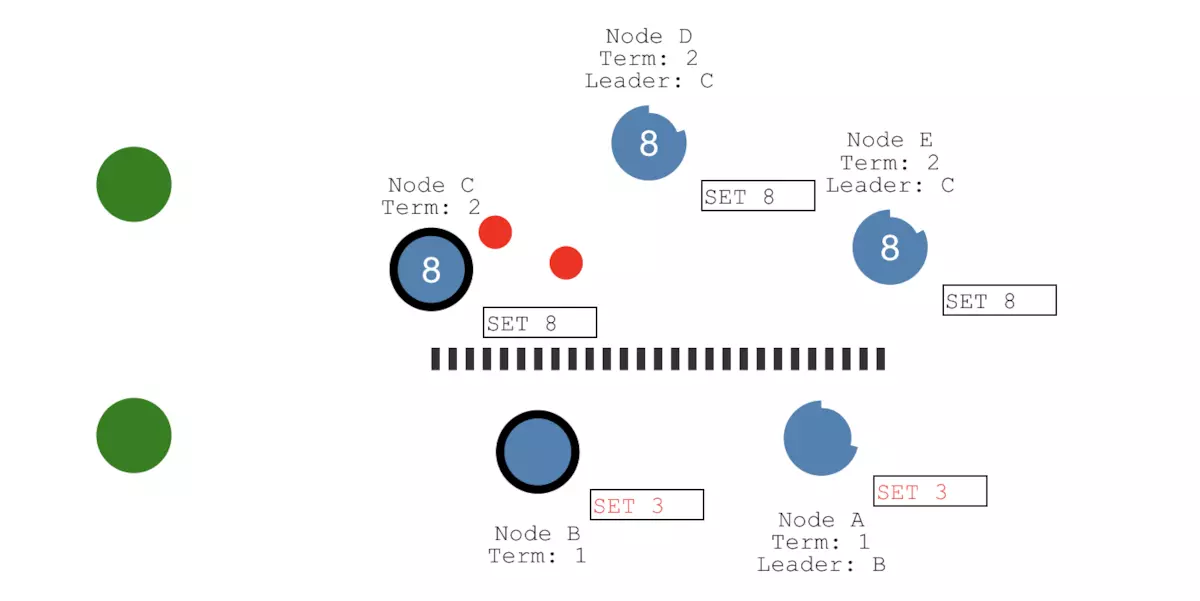
操作2
接下来,我们假设网络恢复正常,如下图所示。节点B能感知到C节点这个Leader的存在,它就会从Leader状态退回到Follower状态,并且节点A和B会回滚之前没有提交的日志(SET 3产生的uncommitted日志)。同时,节点A和B会从新的Leader节点即C节点获取最新的日志(SET 8产生的日志),从而将它们的值更新为8。如此以来,整个集群的5个节点数据完全一致了:
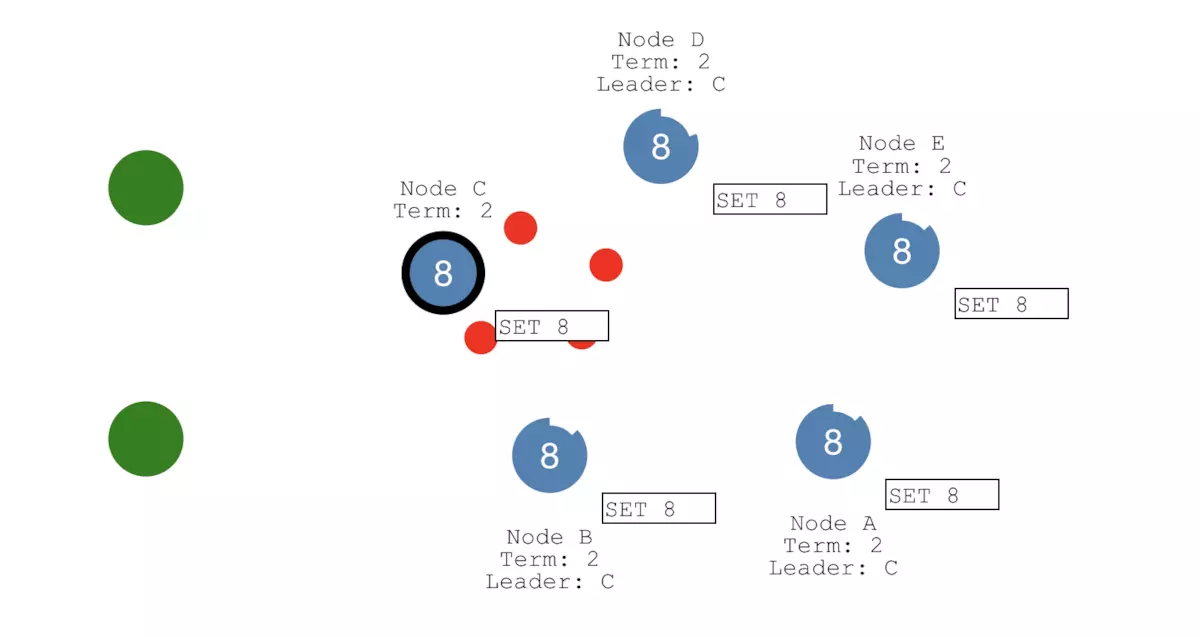
Gossip
Gossip协议是一个通信协议,一种传播消息的方式,灵感来自于:瘟疫、社交网络等。使用Gossip协议的有:Redis Cluster、Consul、Apache Cassandra等。
六度分隔理论
说到社交网络,就不得不提著名的六度分隔理论。1967年,哈佛大学的心理学教授Stanley Milgram想要描绘一个连结人与社区的人际连系网。做过一次连锁信实验,结果发现了“六度分隔”现象。简单地说:“你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。
数学解释该理论:若每个人平均认识260人,其六度就是260↑6 =1,188,137,600,000。消除一些节点重复,那也几乎覆盖了整个地球人口若干多多倍,这也是Gossip协议的雏形。
原理
Gossip协议基本思想就是:一个节点想要分享一些信息给网络中的其他的一些节点。于是,它周期性的随机选择一些节点,并把信息传递给这些节点。这些收到信息的节点接下来会做同样的事情,即把这些信息传递给其他一些随机选择的节点。一般而言,信息会周期性的传递给N个目标节点,而不只是一个。这个N被称为fanout(这个单词的本意是扇出)。
用途
Gossip协议的主要用途就是信息传播和扩散:即把一些发生的事件传播到全世界。它们也被用于数据库复制,信息扩散,集群成员身份确认,故障探测等。
基于Gossip协议的一些有名的系统:Apache Cassandra,Redis(Cluster模式),Consul等。 图解 接下来通过多张图片剖析Gossip协议是如何运行的。如下图所示,Gossip协议是周期循环执行的。图中的公式表示Gossip协议把信息传播到每一个节点需要多少次循环动作,需要说明的是,公式中的20表示整个集群有20个节点,4表示某个节点会向4个目标节点传播消息:

Gossip Protocol
如下图所示,红色的节点表示其已经“受到感染”,即接下来要传播信息的源头,连线表示这个初始化感染的节点能正常连接的节点(其不能连接的节点只能靠接下来感染的节点向其传播消息)。并且N等于4,我们假设4根较粗的线路,就是它第一次传播消息的线路:
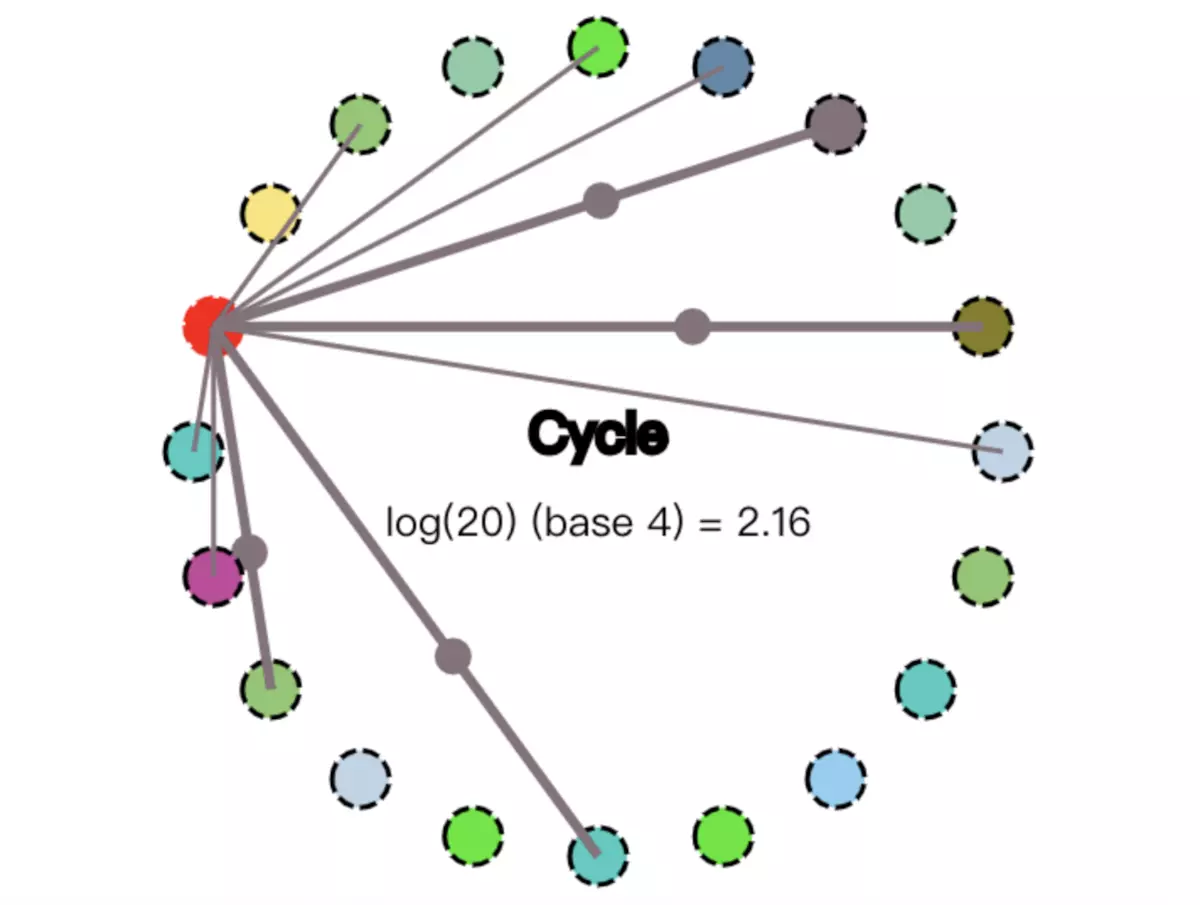
first infected node
第一次消息完成传播后,新增了4个节点会被“感染”,即这4个节点也收到了消息。这时候,总计有5个节点变成红色:
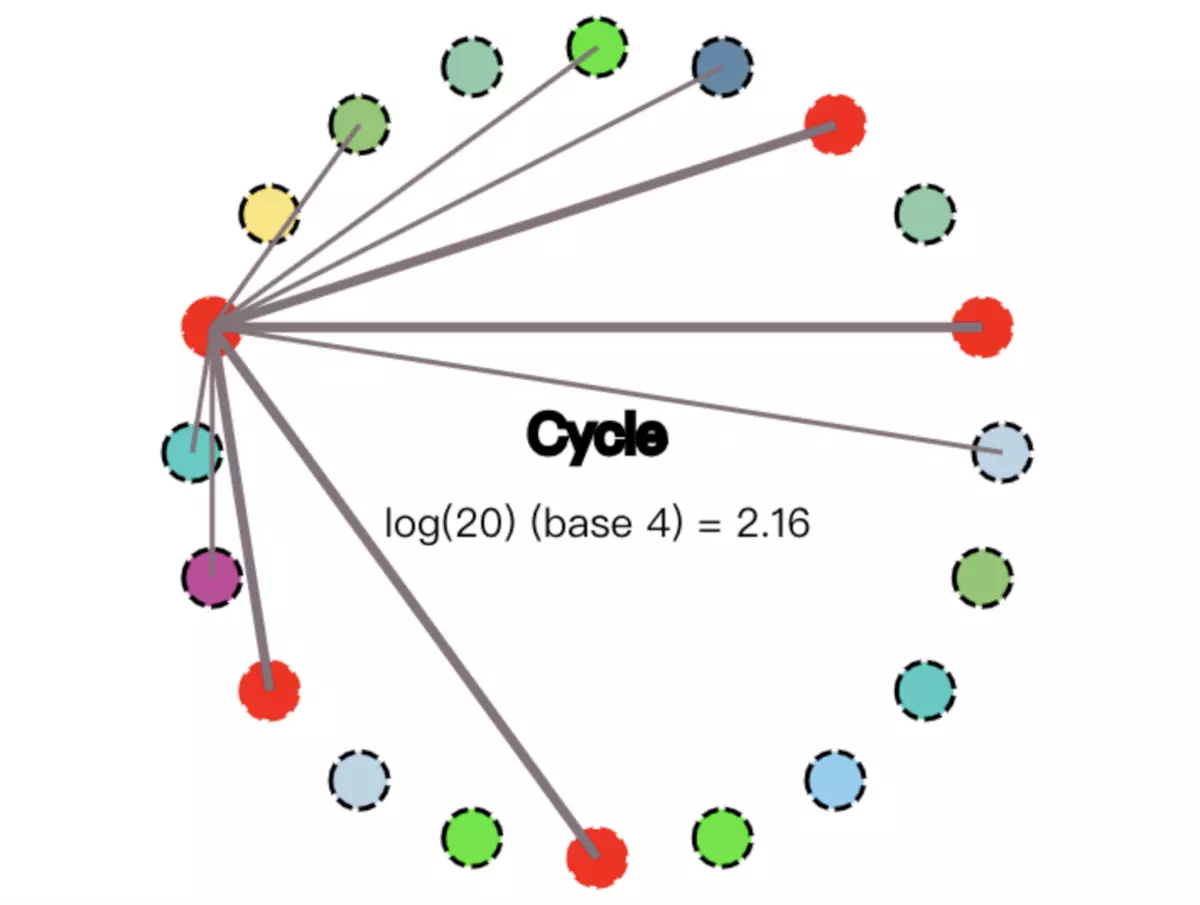
infected nodes
那么在下一次传播周期时,总计有5个节点,且这5个节点每个节点都会向4个节点传播消息。最后,经过3次循环,20个节点全部被感染(都变成红色节点),即说明需要传播的消息已经传播给了所有节点:
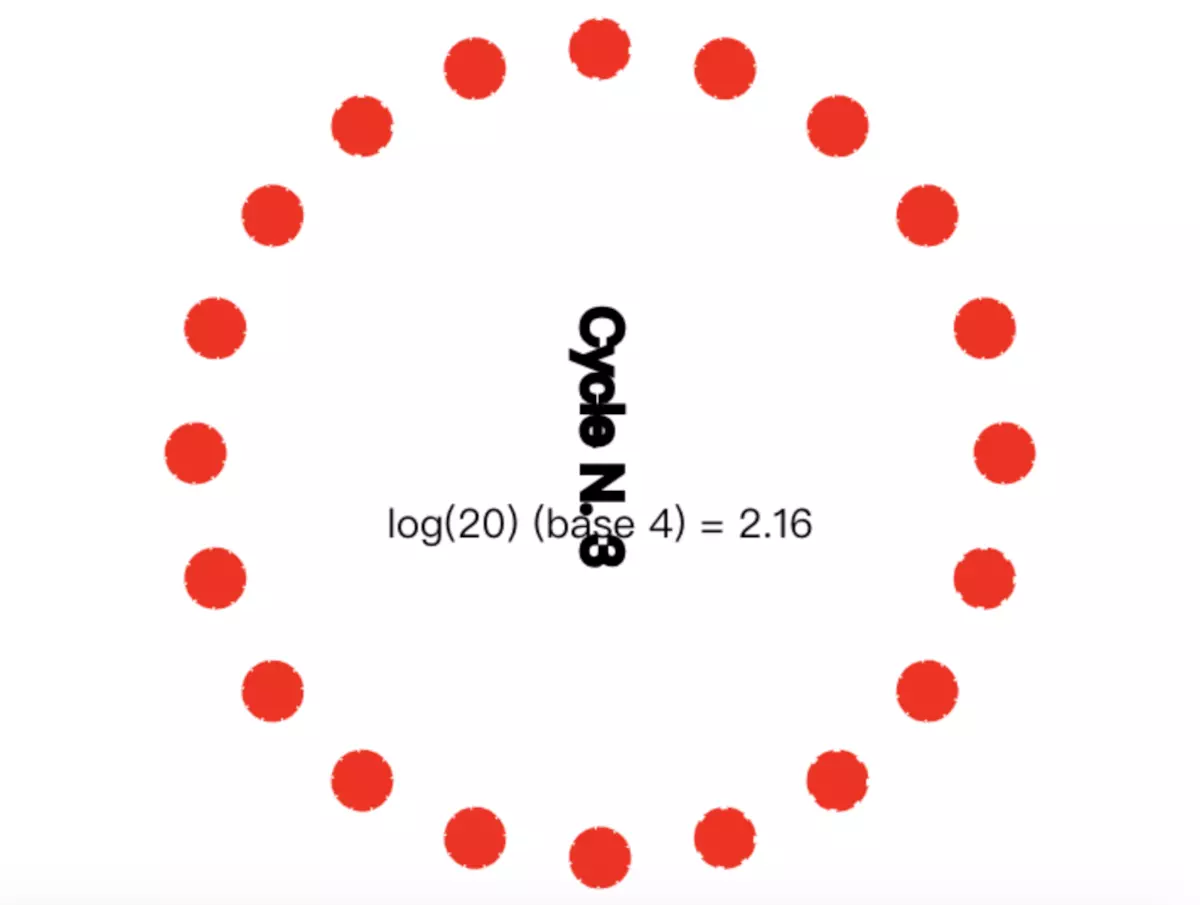
infected all nodes
需要说明的是,20个节点且设置fanout=4,公式结果是2.16,这只是个近似值。真实传递时,可能需要3次甚至4次循环才能让所有节点收到消息。这是因为每个节点在传播消息的时候,是随机选择N个节点的,这样的话,就有可能某个节点会被选中2次甚至更多次。
发送消息
由前面对Gossip协议图解分析可知,节点传播消息是周期性的,并且每个节点有它自己的周期。另外,节点发送消息时的目标节点数由参数fanout决定。至于往哪些目标节点发送,则是随机的。
一旦消息被发送到目标节点,那么目标节点也会被感染。一旦某个节点被感染,那么它也会向其他节点传播消息,试图感染更多的节点。最终,每一个节点都会被感染,即消息被同步给了所有节点 可扩展性 Gossip协议是可扩展的,因为它只需要O(logN) 个周期就能把消息传播给所有节点。某个节点在往固定数量节点传播消息过程中,并不需要等待确认(ack),并且,即使某条消息传播过程中丢失,它也不需要做任何补偿措施。大哥比方,某个节点本来需要将消息传播给4个节点,但是由于网络或者其他原因,只有3个消息接收到消息,即使这样,这对最终所有节点接收到消息是没有任何影响的。
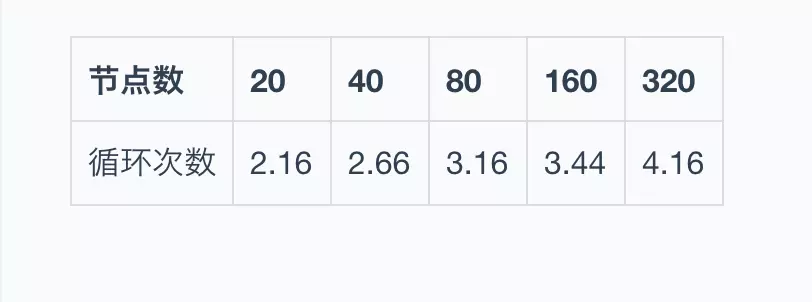
如下表格所示,假定fanout=4,那么在节点数分别是20、40、80、160时,消息传播到所有节点需要的循环次数对比,在节点成倍扩大的情况下,循环次数并没有增加很多。所以,Gossip协议具备可扩展性:
失败容错 Gossip也具备失败容错的能力,即使网络故障等一些问题,Gossip协议依然能很好的运行。因为一个节点会多次分享某个需要传播的信息,即使不能连通某个节点,其他被感染的节点也会尝试向这个节点传播信息。 健壮性 Gossip协议下,没有任何扮演特殊角色的节点(比如leader等)。任何一个节点无论什么时候下线或者加入,并不会破坏整个系统的服务质量。
然而,Gossip协议也有不完美的地方,例如,拜占庭问题(Byzantine)。即,如果有一个恶意传播消息的节点,Gossip协议的分布式系统就会出问题。
Paxos
Paxos算法是一个非常经典的算法,在分布式系统中有非常广泛的使用,比如在大名鼎鼎的ZooKeeper中就有很核心的使用。
对于工程方向的技术人来说,对Paxos算法只要从一个高层次的角度,对他核心的思想理解就已经可以了。 所以本文我们用比较通俗易懂的方式,从一个有趣的角度来描述一下Paxos算法的核心思想
团建主席的选举过程
假如现在一个公司的团队里有25个人,现在这25个人之间需要找一个人出来作为团建主席,也就是专门负责这个团队团建相关的组织事宜,比如组织大家出去旅游、出去吃喝玩乐。 这个团建的场景,以及团建主席这个角色大家应该很熟悉。
提示音: 其实这个场景引申到技术里,就是非常典型的一个分布式系统选举的场景。
如果有25台机器,这些机器之间要选举出来某一台机器来作为一个Leader角色的节点,负责对集群进行整体上的 管控,是不是就跟一个团队选举一个团建主席一个道理。
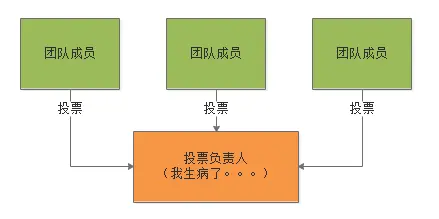
此时肯定有人说,那还不简单,找一个人作为投票负责人,先让有兴趣担任团建主席的人自愿申请提名自己,然后大家分别对这些人进行投票,投票给谁都告诉那个投票负责人,由那个人统计各个候选人的票数,看哪个人的票数多最后就选择谁当团建主席就可以了。
这个方案确实是没问题的,但是Paxos算法是不认可这种方式的。从Paxos算法的角度而言,它会觉得如果大家都依赖一个投票负责人来进行投票,那万一投票负责人突然失联了怎么办? 比如家里有人生病了去医院了,或者自己突然食物中毒去医院了,那大家不就没法选举出来一个团建主席?
提示音: 引申到技术里,那就是25台机器挑选了其中一台机器作为投票选举的负责人,专门收集大家的投票,然后票数排序,最后选择出来一台机器,那万一那台机器突然宕机了怎么办?是不是会导致选举失败?所以Paxos算法是不接受这种方式的。 如下图所示:
所以现在大家就换一个思路了,这25个人不要通过一个投票负责人的方式来投票选举,而是互相之间发送短信,就通过互相发送短信的方式来选举一个团建主席。
这个好处在于哪怕25个人里有12个人都因为工作忙、在开会、孩子生病了,然后没法通过短信的方式参与投票,但是剩余的13个人还是有超过半数的人在这里,他们就可以完成最终的投票。这样投票的过程就不用依赖于某个人了,哪怕将近一半的人都失联了,还是可以选举出来这个团建主席。
提示音: 引申到技术里,就是25台机器不要找一个投票负责人,它们互相之间发送消息进行通信,来尝试选举出来一个团建主席。 这样哪怕有12台机器都故障宕机了,但是剩余的已经过半数的13台机器还是能选举出来一个团建主席的,对系统容错性就有了大大的提升。 那么那25个人到底怎么通过互相发送短信来选举一个团建主席出来呢?
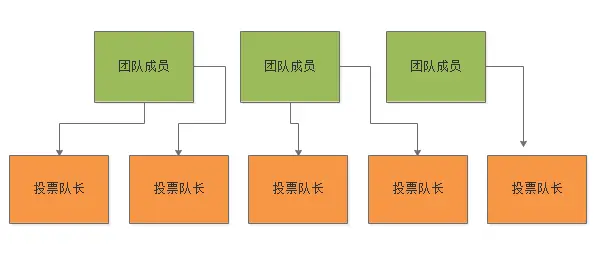
首先这25个人里,需要找出来其中5个人作为选举队长,这5个人负责跟所有人收发短信确定团建主席的人选,然后假设有3个候选人是要提名作为团建主席。 下图展示了这个过程:
Paxos第一阶段:申请阶段
首先,除了那5个队长以外,所有人都需要在第一个阶段尝试申请跟投票队长进行沟通。这个阶段,每个团队成员都会给每个队长发送一条短信,而且是不停的发送短信,短信内容就是我申请跟你进行沟通。
而每个队长也会不停收到每个成员发送过来的短信,对于队长来说,拿到短信就根据时间戳判断,如果一个人发送过来的短信是最新的,那么就回话说我同意跟你进行沟通。
如果一个成员收到超过半数(这里就是3个)的队长的回信说同意沟通,那么就可以告诉那些同意沟通的队长,自己想要投票给谁。但是这里要注意一点,队长是会不断的收到别人发过来的短信的,所以很可能他刚刚答应跟你沟通,结果立马收到别人的短信,发现别人的短信更新,所以就同意跟别人进行沟通了,你的沟通权就会被取消。
所以如果一个成员狂发短信的过程中,突然发现自己被超过半数的队长同意沟通了,别着急高兴。 这个成员需要赶紧继续下一个阶段,告诉那些队长自己想要投票的候选人,要是发晚了,人家队长可能就在跟别人沟通了,不会理你了!
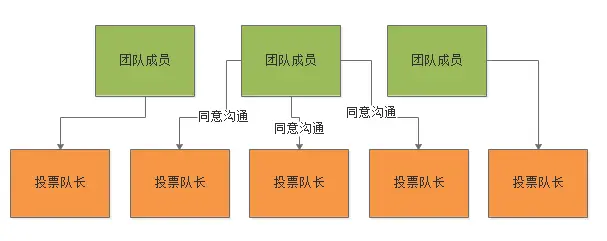
Paxos第二阶段:一个比较顺利的投票阶段
这个时候一个成员获得了跟半数以上队长的沟通资格,然后就可以发送一条短信过去,说自己想要选举的人是三个候选人里的谁,这个人选可能就是成员自己拍脑袋决定的,随机选择的一个候选人而已。
这时大家考虑一下,如果3个队长都没有收到其他成员发过来的更新的申请短信,都保持着跟这个成员的沟通,那么3个队长收到他发过来的投票,比如说选举“张三 ”当做团建主席,那就直接通过了! 这个时候成员发现3个队长都回话说,就用你说的那个“张三”同学作为团建主席了,那就定了,此时团建主席就是这个“张三”了。 后续其他成员发申请短信给队长的时候,如果它们跟那三个队长获得沟通权,三个队长都会回复短信说,就是“张三”了,已经选举出来了。 这个时候,其他成员都会直接遵守这个选举结果,就认为是“张三”了。
另一种情况,此时要是某个其他成员跟 1 个知道“张三”投票结果的队长沟通,然而它跟另外 2 个知道“ 张三 ”投票结果的队长没建立上沟通,却跟剩下的2个还不知道“张三”投票结果的队长沟通,这个成员因为感知到了其中1个队长已经选择了“张三”,此时他就会尝试说,我就投票给“张三”了,通知另外2个还在茫然中的队长是“张三”。 此时另外两个茫然的队长也会选择接受“张三”的投票结果,最后5个队长都会接收“张三”这个投票结果,然后所有成员在跟队长沟通的过程中,也必然会全部接收到“张三”这个投票结果。 最后所有成员都会发现,最终的选举结果,就是:张三。这是一个非常顺利的投票阶段。
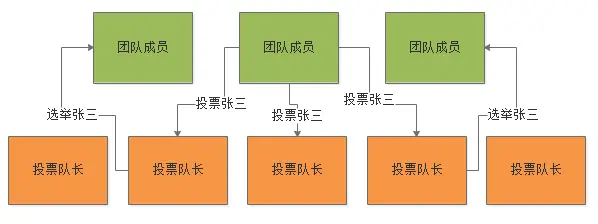
Paxos第二阶段:如果投票不太顺利呢?
那么来复盘一下上面的情况,万一要是投票的过程不太顺利呢? 比如一个成员好不容易获取了跟三个队长的沟通资格,结果发送投票请求过去的时候,其中一个队长已经跟别人建立了沟通,此时就不会理睬你的投票。
那可能就只有2个队长接收了你的“张三”的投票,但是没到3个队长就不能确定选择“张三”。 这个时候怎么办?可能在这种混乱的情况下,比如5个队长里,其中2个队长接收到的投票是“张三”,1个队长是“李四”,2个队长是“王五”,没法确定选举结果。
然后所有成员继续持续不断的重复上述步骤,跟队长申请沟通,然后再尝试投票。 假如一个成员跟3个队长建立了沟通,其中2个队长告诉他自己已经接收到“张三”投票了,1个队长告诉他自己已经接收到“李四”投票了,那么这个成员会看哪个投票是最新的,比如说“李四”那个投票是最新的,那么他就会说,我就投“李四”了。 此时那2个接收到“张三”投票的队长就会改变自己的选票为“李四”,然后就会出现3个队长都接受了“李四”这个投票。
如果另外一个成员跟1个接收“李四”投票的队长以及2个接收“王五”投票的队长建立了沟通,会发现“李四“是最新选出来的,此时他会说,我就投给“李四”了。 然后那2个接收“王五”投票的队长,也会接收“李四”的投票。以此类推,大家开一下自己的脑洞,这个过程可能会持续很长时间,直到最后,所有队长都接受了“李四”的投票,所有成员也会接收“李四”的投票。
引申:Paxos算法专业名词解释 其实上述过程已经用一个简单的投票选举团建主席的例子给简化的非常通俗了,虽然还是有点烧脑,但是建议大家多看几遍,肯定照着思路能大致想明白Paxos算法的一个思路。 他有两个要点:一个是超过半数的运用,一个是只用最新的投票 。 Paxos算法里,对一堆机器中扮演队长角色的机器叫做“Acceptor”,对于普通成员的角色叫做“Proposer”,互相发短信其实就是发消息进行通信,短信的时间戳就是“epoch”。 大家把上述的过程换成机器之间的通信以及选举,就能清楚这个过程了。
参考文章
