

InnoDB体系架构
主要有后台线程,内存池和文件三部分组成
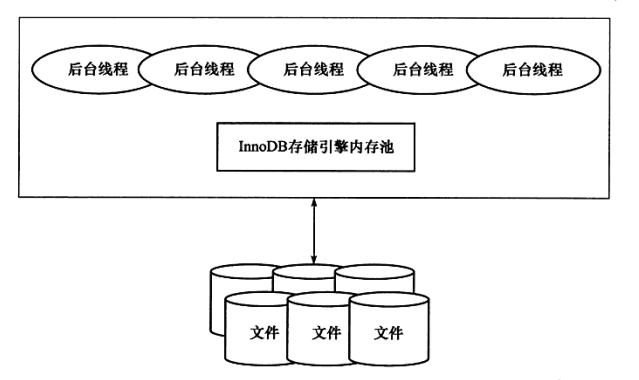
后台线程
负责刷新内存池中的数据
将已修改的数据文件刷新到磁盘文件
保证再数据库发生异常的情况下InnoDB能恢复到正常运行状态
-
Master Thread
主要负责将缓存池中的数据异步刷新到磁盘,保证数据的一致性
脏页的刷新
合并插入缓存(insert buffer)
undo页的回收
-
IO Thread
AIO来处理写请求
-
Purge Thread
事务呗提交后,其所使用的undolog可能不在需要,因此需要PurgeThread来回收已经使用并分配的undo页
-
Page Cleaner Thread
1.2.X版本中引入,完成脏页的刷新操作,减轻Master Thread的工作
内存池
缓冲池
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引、InnoDB存储的锁信息、数据字典信息等
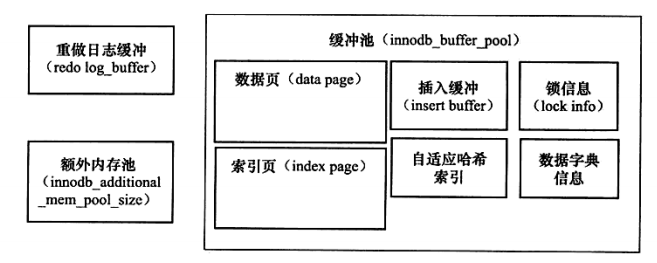
LRU List、Free List和Flush List
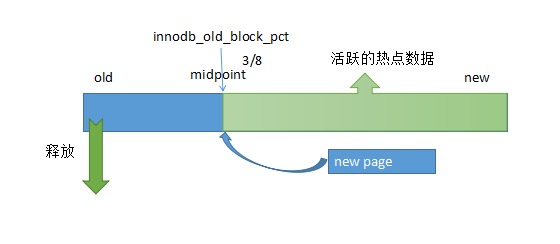
LRU List
缓冲池不可能缓存所有磁盘上的数据,这时候就需要通过LRU(Latest Recent Used,最近最少使用)算法来进行管理。即最频繁使用的页再LRU列表的前端
缓冲池中页的大小默认是16KB
InnoDB存储引擎对传统的LRU算法锁了一些优化,加入了midpoint位置。新读取到的页,不会直接放入到LRU列表的首部,而是放在LRU列表的midpoint位置,大概在5/8的位置
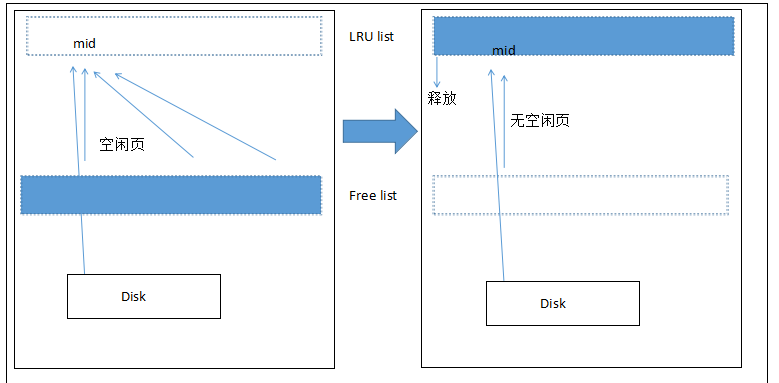
Free List
LRU管理已经读取的页,数据库启动时,LRU列表是空的,没有页。此时的页都放在Free list。
当需要从缓冲池中分页时,先查看Free list是否有空闲的页,若有,则从Free list中删除该页,放入到LRU列表。若没有,则根据LRU算法,释放LRU列表尾端的页,将该内存分给新页。
Flush List
LRU列中数据被修改后,产生脏页。数据库通过checkpoint机制将脏页刷新会磁盘,flush list中的页即为脏页列表。脏页即存在于LRU中,也存在于Flush中。LRU list用于管理缓冲池中页的可用性,Flush list用于将页刷新回磁盘。
重做日志缓存
首先将重做日志信息放入到缓冲区,然后按照一定频率将其刷新到重做日志文件,该文件默认大小为8M
触发缓冲到文件的时机:
- Master Thread每一秒将重做日志缓冲刷新到重做日志文件
- 每个事务提交时会将重做日志缓冲刷新到重做日志文件
- 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件
Checkpoint技术
保证持久性
事务数据库系统普遍都采用Write Ahead Log策略,当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志来完成数据的恢复
当前数据库对 redo log 的设计都是循环使用的,为了防止被覆盖,必须强制 Checkpoint,将缓冲池中的页至少刷新到当前 redo log 的位置。
InnoDB 通过 Log Sequence Number, LSN 来标记版本,这是 8 字节的数字,每个页有 LSN,重做日志中也有 LSN,Checkpoint 也有 LSN,这个是联系三者的关键变量。
mysql> SHOW ENGINE INNODB STATUS\G
---
LOG
---
Log sequence number 293590838 LSN1事务创建时一条日志
Log flushed up to 293590838
Pages flushed up to 293590838
Last checkpoint at 293590829
0 pending log flushes, 0 pending chkp writes
1139 log i/o's done, 0.00 log i/o's/second
CheckPoint 机制
在 Innodb 每次都取最老的 modified page 对应的 LSN,并将此脏页的 LSN 作为Checkpoint 点记录到日志文件,意思就是 “此 LSN 之前对应的日志和数据都已经刷新到磁盘” 。
当 MySQL 启动做崩溃恢复时,会从 last checkpoint 对应的 LSN 开始扫描 redo log ,并将其应用到 buffer pool,直到 last checkpoint 对应的 LSN 等于 log flushed up to 对应的LSN,则恢复完成。
如下是整个 redo log 的生命周期。
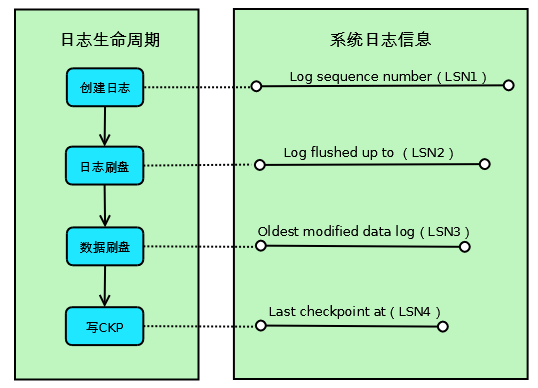
- 创建阶段 (log sequence number, LSN1):事务创建一条日志,当前系统 LSN 最大值,新的事务日志 LSN 将在此基础上生成,也就是 LSN1+新日志的大小;
- 日志刷盘 (log flushed up to, LSN2):当前已经写入日志文件做持久化的 LSN;
- 数据刷盘 (oldest modified data log, LSN3):当前最旧的脏页数据对应的 LSN,写 Checkpoint 的时候直接将此 LSN 写入到日志文件;
- 写CKP (last checkpoint at, LSN4):当前已经写入 Checkpoint 的 LSN,也就是上次的写入;
对于系统来说,以上 4 个 LSN 是递减的,即: LSN1>=LSN2>=LSN3>=LSN4 。
InnoDB关键特性
- 插入缓存
- 两次写
- 自适应哈希索引
- 异步IO
- 刷新邻接页
插入缓冲
问题:通过自增唯一主键(聚集索引)插入数据时,不需要磁盘的随机读取,但是当表中有多个非聚集的辅助索引,这个时候插入B+数就是离散的,为了解决随机访问磁盘导致的性能下降,就出现了Insert Buffer
对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在索引池中,若在,则直接插入;若不在,则先放入到一个Insert Buffer对象中,然后再以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge操作
使用条件:
- 索引时辅助索引
- 索引不是唯一的
Insert Buffer的升级版:Change Buffer
对DML操作:Insert、Delete、Update都进行缓冲
具体实现
Insert Buffer的数据结构时一棵B+树,负责所有表的辅助索引进行Insert Buffer

合并
等到合适的时机,会把Insert Buffer合并到索引树中
- 辅助索引背督导缓冲池中
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- Master Thread
两次写
作用:数据页的可靠性保证
背景:从page写到磁盘,page大小为16kb,磁盘的每次IO为4kb,所以每页需要多次写入(partial page write),在途中如果宕机,则可能导致写入数据只成功了一部分
重做日志中记录的是对页的物理操作,如偏移量800,写"aaa"记录
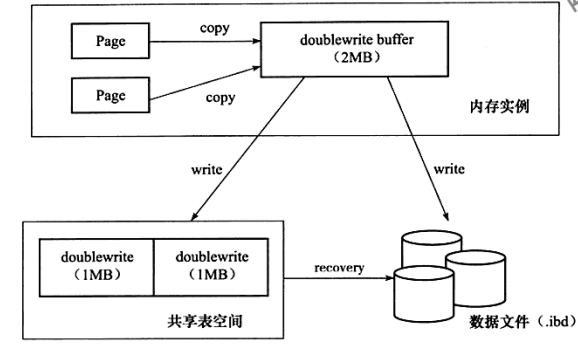
- 如果是写doublewrite buffer本身失败,那么这些数据不会被写到磁盘,InnoDB此时会从磁盘载入原始的数据,然后通过InnoDB的事务日志来计算出正确的数据,重新写入到doublewrite buffer。
- 如果 doublewrite buffer写成功的话,但是写磁盘失败,InnoDB就不用通过事务日志来计算了,而是直接用buffer的数据再写一遍。
- 在恢复的时候,InnoDB直接比较页面的checksum,如果不对的话,就从硬盘载入原始数据,再由事务日志开始推演出正确的数据。所以InnoDB的恢复通常需要较长的时间。
自适应哈希索引
InnoDB存储引擎会监控对表上各索引页的查询,如果观察到简历哈希索引可以带来速度提升,则建立哈希索引。
生成条件:
- 访问模式一致
- 以该模式访问了100次
- 页通过该模式访问了N次,其中N=页中记录*1/16
参考
jin-yang.github.io/post/mysql-…
MySQL技术内幕(InnoDB存储引擎)
