

主从复制过程
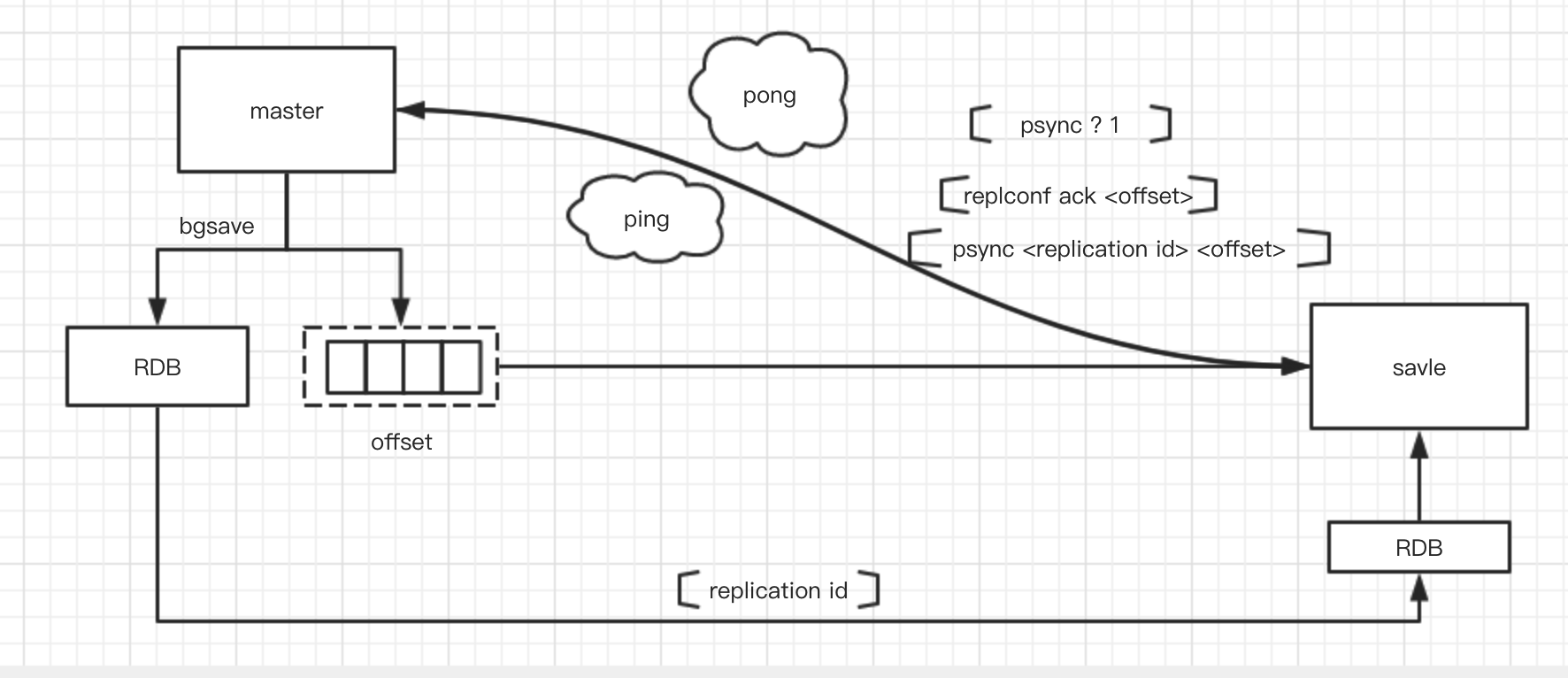
1. 初始复制阶段
当从库接收到save of masterip masterport命令的时候,从库和指定的主库建立socket连接,连接建立完成后,从库向主库发送ping命令,确认主库是否可用。如果可用则主库返回pong命令,否则从库将会进行重试。
如果主库连接设置了密码,则从库需要设置masterauth参数,此时从库会发送auth命令,命令格式为“auth + 密码”进行密码验证。如果验证不通过或者从库没有配置masterauth参数则socket连接断开。
上述步骤完成后,主库和从库会保持长连接,进入下一个阶段。
2. 数据同步阶段
每一个Redis master都有一个Replication ID:这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增。
所以基本上每一对给定的Replication ID, offset都会标识一个 master 数据集的确切版本。
-
全量复制
当从库和主库建立连接之后,如果从库没有复制过任何的master数据集,会向主库发送
psync ? 1命令,执行全量复制过程。主库接收到psync命令后,会fork一个子进程,生成RDB文件,同时它开始缓冲所有从客户端接收到的新的写入命令到复制积压缓冲区(replication backlog buffer),然后发送RDB文件给从库。从库保存RDB文件到磁盘,再加载到内存中。再然后将复制积压缓冲区写入命令发送给从库。 -
部分复制(2.8版本之后)
当主从复制在初次复制时,主库将自己的Replication ID发送给从节点,从库将这个Replication保存起来 如果从库重启或者由于网络原因主从连接断开在一段时间主从重新连接之后。如果从库已经复制过某个master数据集,会向主库发送
psync Replication ID offset命令,如果主从的Replication ID相同并且offset偏移量之后的命令都在复制积压缓存区中则进行部分复制。复制积压缓冲区是一个固定长度的FIFO队列,大小由配置参数
repl-backlog-size指定,默认大小1MB。该缓冲区由master维护并且有且只有一个,所有slave共享此缓冲区,其作用在于备份最近主库发送给从库的数据。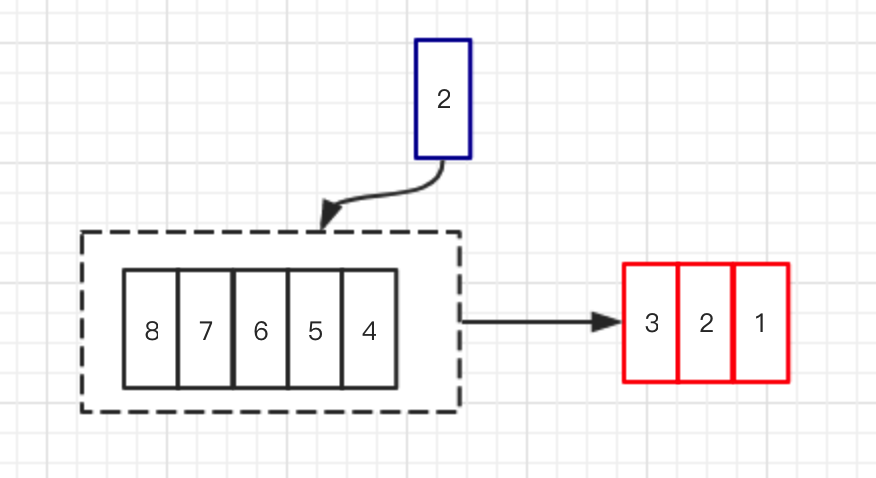
如上图所示,如果在主从连接断开这段时间主库写入命令过快,超出了积压缓冲区的大小,就需要丢弃一些命令。当从库的offset不在主库的积压缓冲区的时候就只能进行全量复制了。
3. 命令传播阶段
当数据同步完成后,主库和从库通过心跳来维持连接,检查对方是否在线。主库缺省情况下每隔10s(通过repl-ping-slave-period参数指定)向主库发送ping命令检查从库是否在线。从库每隔1s向主节点发送replconf ack {offset} 命令,用于向主库汇报自己保存的复制偏移量并检查主库是否在线,如果主库在线会对比复制偏移量向从节点发送未同步的命令。
4. 重新启动和故障转移后的部分重同步
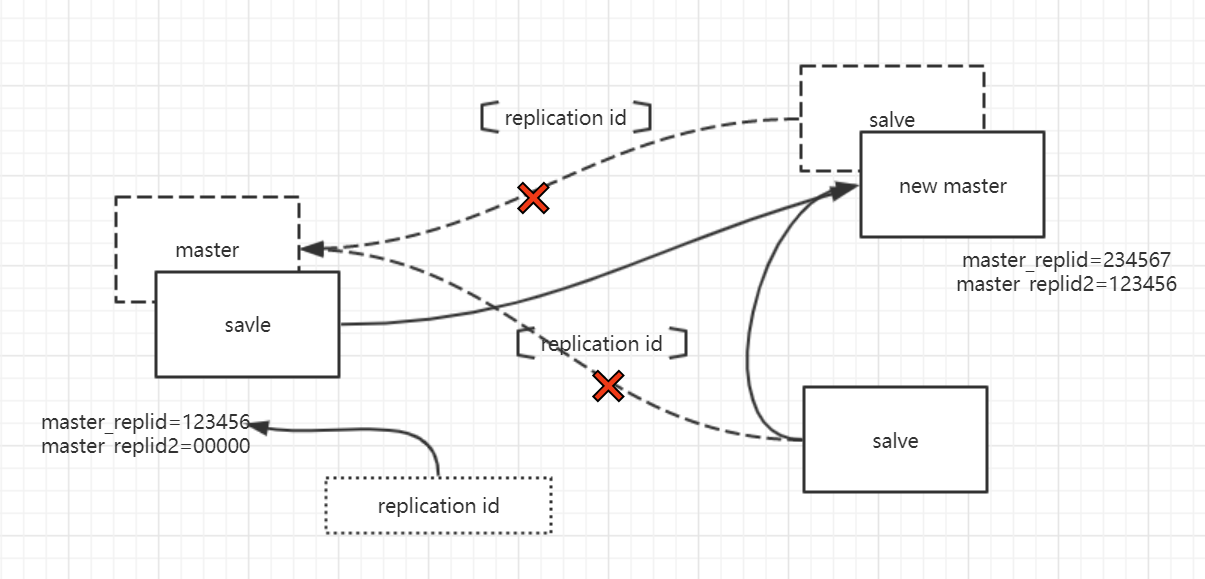
从 Redis 4.0 开始,当一个实例在故障转移后被提升为master时或者实例重启时,它仍然能够与旧 master的slaves进行部分重同步。
-
主库重启
使用shoutdown save 关闭redis实例的时候会调用rdbSaveInfoAuxFields函数,把当前实例的repl-id和repl-offset保存到RDB文件中。重启后会加载RDB文件中的repl-id和repl-offset复制给master-replid。以此来保证主库重启后依然可以部分复制。但是要注意的是如果开启了AOF持久化,则会先加载AOF文件,但是AOF文件中没有复制信息,这会导致全量复制。
-
故障转移后升级
