

一.模型之母:简单线性回归&最小二乘法
线性回归算法的作用是使用单一特征来预测响应值。是一种根据自变量X预测因变量Y的方法。假设两个变量是线性相关的,那么我们要找到一个线性函数,根据特征或自变量X来精确预测响应值Y。
如何找到最佳拟合线
在这个回归模型中,我们尝试通过寻找最佳拟合线来最小化预测的误差——根据线性回归预测的结果误差最小。我们尝试最小化观察值和预测值之间的长度,长度越小,误差就越小,反之亦然。
1.1那么什么是简单线性回归?
所谓简单,是指只有一个样本特征,即只有一个自变量;所谓线性,是指方程是线性的;所谓回归,是指用方程来模拟变量之间是如何关联的。 简单线性回归,其思想简单,实现容易(与其背后强大的数学性质相关。同时也是许多强大的非线性模型(多项式回归、逻辑回归、SVM)的基础。并且其结果具有很好的可解释性。
1.2 求解思路
下面我们可以用一个简单的例子来直观理解线性回归模型。
小A开了一家玩具厂,他想分析一下玩具产量与成本之间的关系,于是小A制作了如下表格:
| 玩具个数 | 成本 |
| --- | --- |
| 10 | 7.7 |
| 10 | 9.87 |
| 11 | 10.87 |
| 12 | 12.18 |
| 13 | 11.43 |
| 14 | 13.36 |
| 15 | 15.15 |
| 16 | 16.73 |
| 17 | 17.4 |
为了更加直观地了解数据,小A对数据进行了可视化:
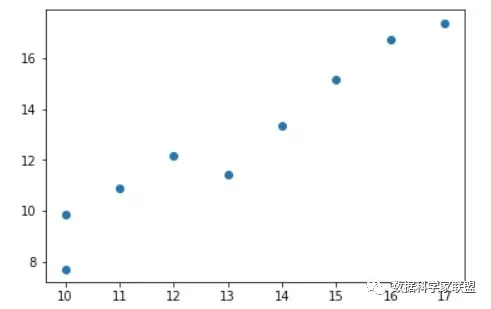
从图像中我们可以发现,产量和成本之间,存在着一定的线性关系,似乎是在沿着某条直线上下随机波动。
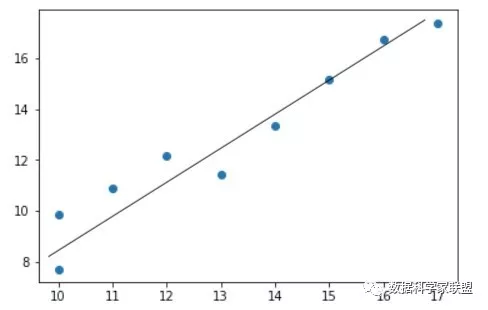
假设我们找到了最佳拟合的直线方程:y = ax + b
则对于每个样本点 ,根据我们的直线方程,预测值为:
很显然,我们希望直线方程能够尽可能地拟合真实情况,也就是说真值 和预测值 的差距尽量小。只有所有的样本的误差都小,才能证明我们找出的直线方程拟合性好。
通常来说,为了防止正误差值和负误差值相抵的情况,使用绝对值来表示距离:,但是在线性回归中,我们需要找极值,需要函数可导,而 不是一个处处可导的函数,因此很自然地想到可以使用:
考虑所有样本,我们推导出:
考虑所有样本,我们推导出:
因此我们目标是:已知训练数据样本x、y ,找到a和b的值,使 尽可能小,从而得出最佳的拟合方程。
1.3 一种基本推导思路
在上一小节中,找到一组参数,使得真实值与预测值之间的差距尽可能地小,是一种典型的机器学习算法的推导思路
我们所谓的建模过程,其实就是找到一个模型,最大程度的拟合我们的数据。 在简单线回归问题中,模型就是我们的直线方程:y = ax + b 。
要想最大的拟合数据,本质上就是找到没有拟合的部分,也就是损失的部分尽量小,就是损失函数(loss function)(也有算法是衡量拟合的程度,称函数为效用函数(utility function)):
因此,推导思路为:
通过分析问题,确定问题的损失函数或者效用函数;
- 然后通过最优化损失函数或者效用函数,获得机器学习的模型
- 近乎所有参数学习算法都是这样的套路,区别是模型不同,建立的目标函数不同,优化的方式也不同。
回到简单线性回归问题,目标:
已知训练数据样本x、y ,找到a和b的值,使 尽可能小
这是一个典型的最小二乘法问题(最小化误差的平方)
通过最小二乘法可以求出a、b的表达式:
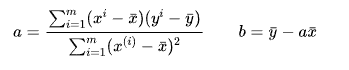
二. 最小二乘法
2.1 由损失函数引出一堆“风险”
2.1.1 损失函数
在机器学习中,所有的算法模型其实都依赖于最小化或最大化某一个函数,我们称之为“目标函数”。
最小化的这组函数被称为“损失函数”。什么是损失函数呢?
损失函数描述了单个样本预测值和真实值之间误差的程度。用来度量模型一次预测的好坏。
损失函数是衡量预测模型预测期望结果表现的指标。损失函数越小,模型的鲁棒性越好。。
常用损失函数有: 损失函数有:
- 0-1损失函数:用来表述分类问题,当预测分类错误时,损失函数值为1,正确为0
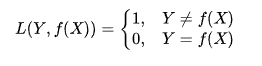
- 平方损失函数:用来描述回归问题,用来表示连续性变量,为预测值与真实值差值的平方。(误差值越大、惩罚力度越强,也就是对差值敏感)
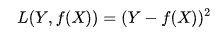
- 绝对损失函数:用在回归模型,用距离的绝对值来衡量
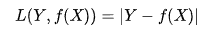
- 对数损失函数:是预测值Y和条件概率之间的衡量。事实上,该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
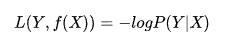
以上损失函数是针对于单个样本的,但是一个训练数据集中存在N个样本,N个样本给出N个损失,如何进行选择呢?
这就引出了风险函数。
2.1.2 期望风险
期望风险是损失函数的期望,用来表达理论上模型f(X)关于联合分布P(X,Y)的平均意义下的损失。又叫期望损失/风险函数。
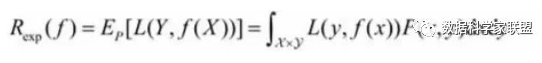
2.1.3 经验风险
模型f(X)关于训练数据集的平均损失,称为经验风险或经验损失。
其公式含义为:模型关于训练集的平均损失(每个样本的损失加起来,然后平均一下)
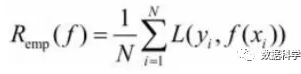
经验风险最小的模型为最优模型。在训练集上最小经验风险最小,也就意味着预测值和真实值尽可能接近,模型的效果越好。公式含义为取训练样本集中对数损失函数平均值的最小。
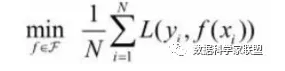
2.1.4 经验风险最小化和结构风险最小化
期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练样本数据集的平均损失。根据大数定律,当样本容量N趋于无穷时,经验风险趋于期望风险。
因此很自然地想到用经验风险去估计期望风险。但是由于训练样本个数有限,可能会出现过度拟合的问题,即决策函数对于训练集几乎全部拟合,但是对于测试集拟合效果过差。因此需要对其进行矫正:
- 结构风险最小化:当样本容量不大的时候,经验风险最小化容易产生“过拟合”的问题,为了“减缓”过拟合问题,提出了结构风险最小理论。结构风险最小化为经验风险与复杂度同时较小。
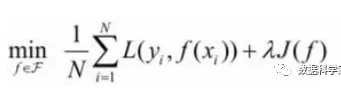
通过公式可以看出,结构风险:在经验风险上加上一个正则化项(regularizer),或者叫做罚项(penalty) 。正则化项是J(f)是函数的复杂度再乘一个权重系数(用以权衡经验风险和复杂度)
2.1.5 小结
1、损失函数:单个样本预测值和真实值之间误差的程度。
2、期望风险:是损失函数的期望,理论上模型f(X)关于联合分布P(X,Y)的平均意义下的损失。
3、经验风险:模型关于训练集的平均损失(每个样本的损失加起来,然后平均一下)。
4、结构风险:在经验风险上加上一个正则化项,防止过拟合的策略
2.2 最小二乘法
2.2.1 什么是最小二乘法
言归正传,进入最小二乘法的部分。
大名鼎鼎的最小二乘法,虽然听上去挺高大上,但是思想还是挺朴素的,符合大家的直觉。
最小二乘法源于法国数学家阿德里安的猜想:
对于测量值来说,让总的误差的平方最小的就是真实值。这是基于,如果误差是随机的,应该围绕真值上下波动。
即:
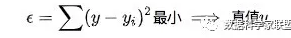
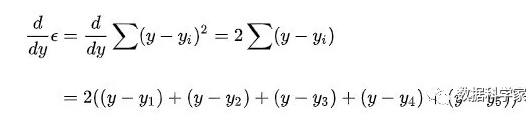
进而:
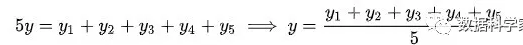
正好是算数平均数(算数平均数是最小二乘法的特例)。
这就是最小二乘法,所谓“二乘”就是平方的意思。
(高斯证明过:如果误差的分布是正态分布,那么最小二乘法得到的就是最有可能的值。)
2.2.2 线性回归中的应用
我们在第一章中提到:
目标是,找到a和b,使得损失函数:
尽可能的小。
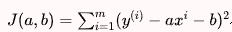
这里,将简单线性问题转为最优化问题。下面对函数的各个位置分量求导,导数为0的地方就是极值:
对 b 进行求导:
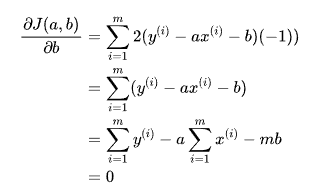
然后mb提到等号前面,两边同时除以m,等号右面的每一项相当于均值。
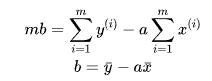
现在 对 a 进行求导:
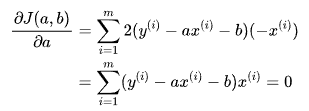
此时将对 b 进行求导得到的结果 代入上式中,得到:
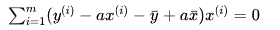
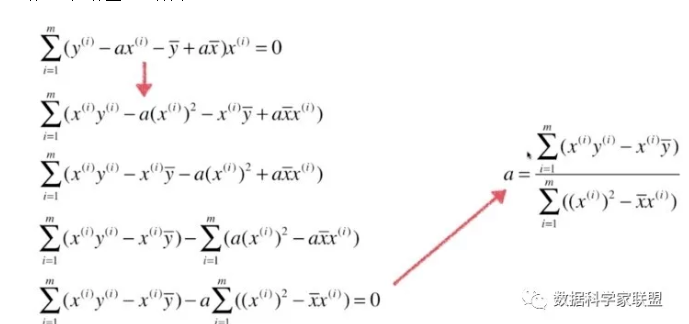
将上式继续进行整理:
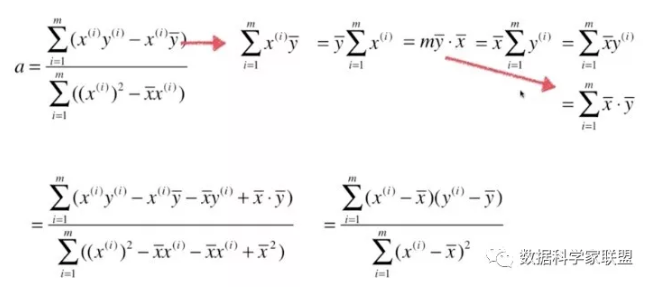
这样在实现的时候简单很多。
最终我们通过最小二乘法得到a、b的表达式:
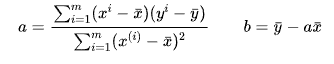
三.简单线性回归的代码实现
首先我们自己构造一组数据,然后画图
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1.,2.,3.,4.,5.])
y = np.array([1.,3.,2.,3.,5,])
plt.scatter(x,y)
plt.axis([0,6,0,6])
plt.show()
下面我们就可以根据样本真实值,来进行预测。
实际上,我们是假设线性关系为: 这根直线,然后再根据最小二乘法算a、b的值。我们还可以假设为二次函数:。可以通过最小二乘法算出a、b、c
实际上,同一组数据,选择不同的f(x),即模型,通过最小二乘法可以得到不一样的拟合曲线。
不同的数据,更可以选择不同的函数,通过最小二乘法可以得到不一样的拟合曲线。
下面让我们回到简单线性回归。我们直接假设是一条直线,模型是:
根据最小二乘法推导求出a、b的表达式:
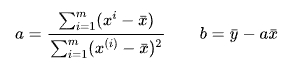
下面我们用代码计算a、b:
# 首先要计算x和y的均值
x_mean = np.mean(x)
y_mean = np.mean(y)
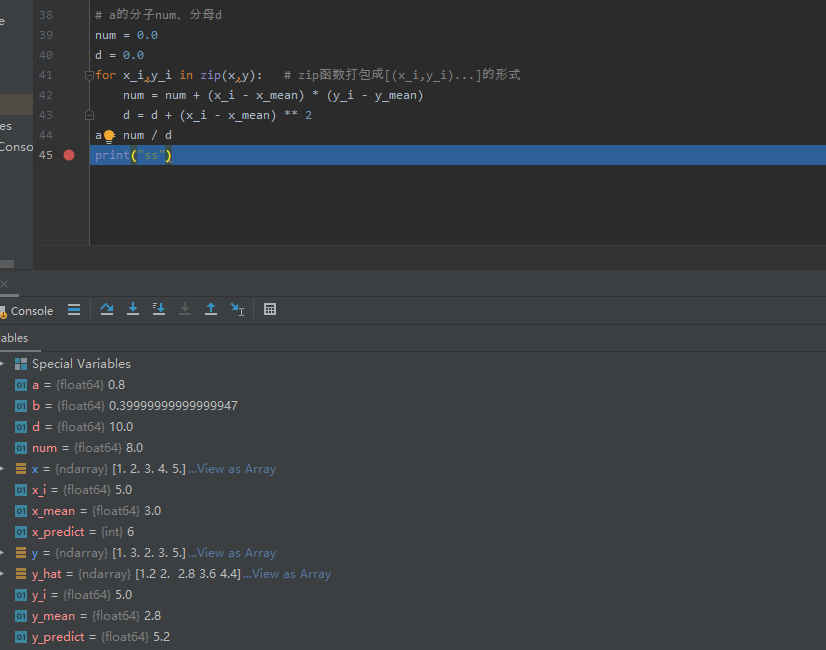
# a的分子num、分母d
num = 0.0
d = 0.0
for x_i,y_i in zip(x,y): # zip函数打包成[(x_i,y_i)...]的形式
num = num + (x_i - x_mean) * (y_i - y_mean)
d = d + (x_i - x_mean) ** 2
a = num / d
b = y_mean - a * x_mean
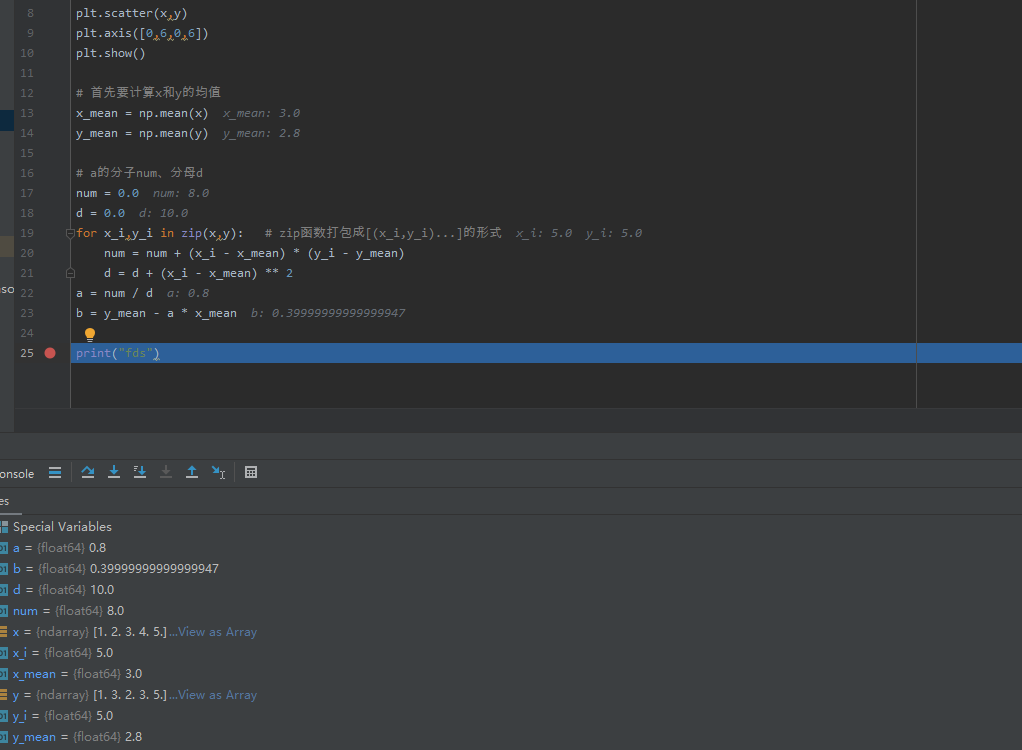
在求出a、b之后,可以计算出y的预测值,首先绘制模型直线:
y_hat = a * x + b
plt.scatter(x,y) # 绘制散点图
plt.plot(x,y_hat,color='r') # 绘制直线
plt.axis([0,6,0,6])
plt.show()
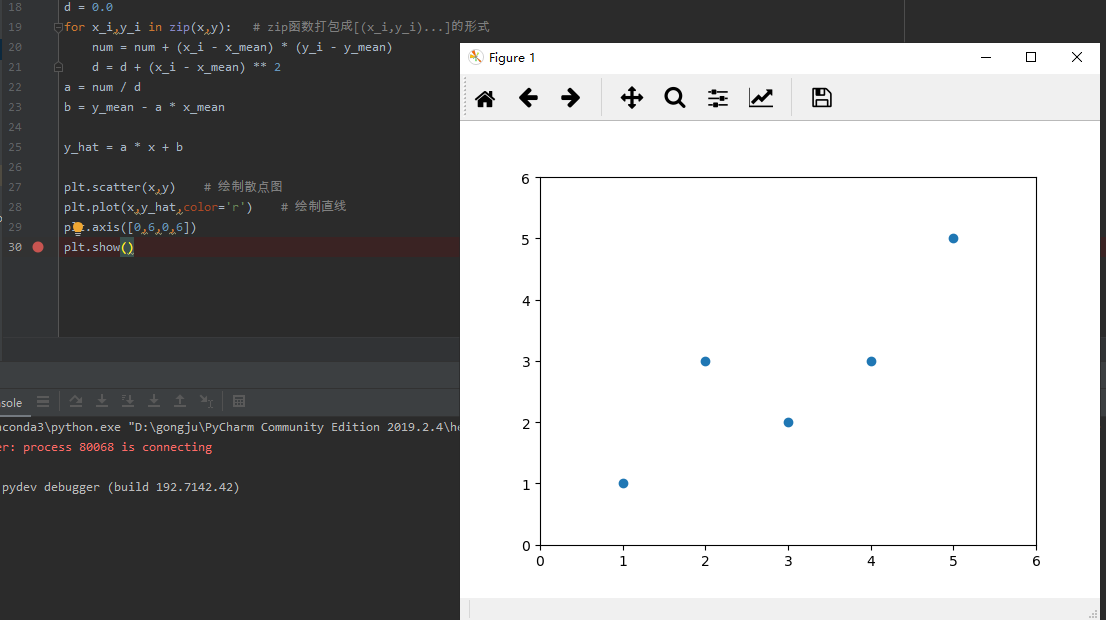
然后进行预测:
x_predict = 6
y_predict = a * x_predict + b
print(y_predict)
四.向量化运算
我们注意到,在计算参数a时:
# a的分子num、分母d
num = 0.0
d = 0.0
for x_i,y_i in zip(x,y): # zip函数打包成[(x_i,y_i)...]的形式
num = num + (x_i - x_mean) * (y_i - y_mean)
d = d + (x_i - x_mean) ** 2
a = num / d
我们发现有这样一个步骤:向量w和向量v,每个向量的对应项,相乘再相加。其实这就是两个向量“点乘”
这样我们就可以使用numpy中的dot运算,非常快速地进行向量化运算。
总的来说:
向量化是非常常用的加速计算的方式,特别适合深度学习等需要训练大数据的领域。
对于 y = wx + b, 若 w, x都是向量,那么,可以用两种方式来计算,第一是for循环:
y = 0
for i in range(n):
y += w[i]*x[i]
y += b
另一种方法就是用向量化的方式实现:
y = np.dot(w,x) + b
二者计算速度相差几百倍,测试结果如下:
import numpy as np
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a, b)
toc = time.time()
print("c: %f" % c)
print("vectorized version:" + str(1000*(toc-tic)) + "ms")
c = 0
tic = time.time()
for i in range(1000000):
c += a[i] * b[i]
toc = time.time()
print("c: %f" % c)
print("for loop:" + str(1000*(toc-tic)) + "ms")
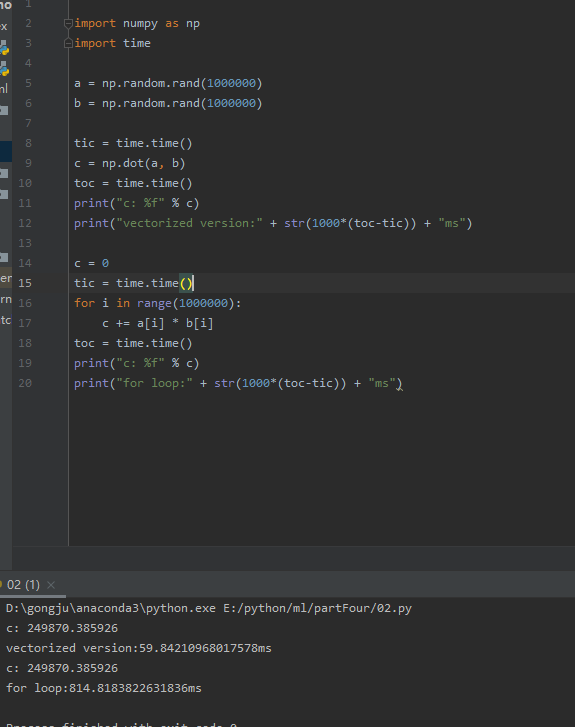
对于独立的样本,用for循环串行计算的效率远远低于向量化后,用矩阵方式并行计算的效率。因此:
只要有其他可能,就不要使用显示for循环。
3.1 代码
还记得我们之前的工程文件吗?创建一个SimpleLinearRegression.py,实现自己的工程文件并调用
import numpy as np
class SimpleLinearRegression:
def __init__(self):
"""模型初始化函数"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练模型"""
assert x_train.ndim ==1, \
"简单线性回归模型仅能够处理一维特征向量"
assert len(x_train) == len(y_train), \
"特征向量的长度和标签的长度相同"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean) # 分子
d = (x_train - x_mean).dot(x_train - x_mean) # 分母
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"简单线性回归模型仅能够处理一维特征向量"
assert self.a_ is not None and self.b_ is not None, \
"先训练之后才能预测"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
"""返回一个可以用来表示对象的可打印字符串"""
return "SimpleLinearRegression()"
3.2 调用
下面我们在jupyter中调用我们自己写的程序:
首先创建一组数据,然后生成SimpleLinearRegression()的对象reg1,然后调用一下
from myAlgorithm.SimpleLinearRegression import SimpleLinearRegression
x = np.array([1.,2.,3.,4.,5.])
y = np.array([1.,3.,2.,3.,5,])
x_predict = np.array([6])
reg = SimpleLinearRegression()
reg.fit(x,y)
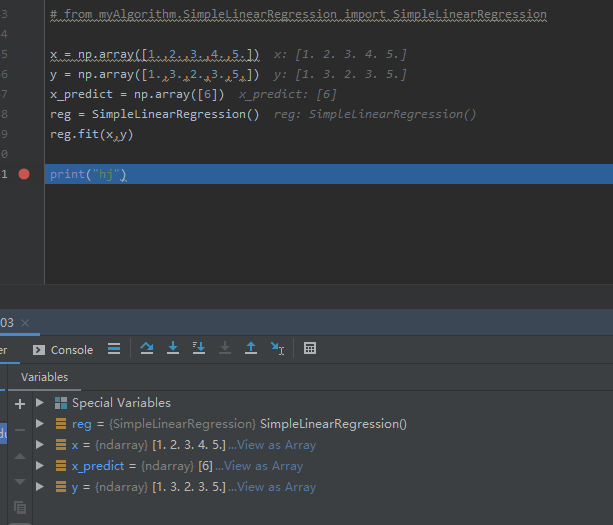
输出:SimpleLinearRegression()
reg.predict(x_predict)
reg.a_
reg.a_
输出:array([5.2]) 0.8 0.39999999999999947
y_hat = reg.predict(x)
plt.scatter(x,y)
plt.plot(x,y_hat,color='r')
plt.axis([0,6,0,6])
plt.show()
五. 多元线性回归
在线性回归的前3篇中,我们介绍了简单线性回归这种样本只有一个特征值的特殊形式,并且了解了一类机器学习的建模推导思想,即:
- 通过分析问题,确定问题的损失函数或者效用函数;
- 然后通过最优化损失函数或者效用函数,获得机器学习的模型。然后我们推导并实现了最小二乘法,然后实现了简单线性回归。最后还以简单线性回归为例,学习了线性回归的评价指标:均方误差MSE、均方根误差RMSE、平均绝对MAE以及R方。
但是,在真实世界中,一个样本通常有很多(甚至成千上万)特征值的,这就是多元线性回归。本篇内容我们学习多元线性回归并实现。
对于下面的样本数据集
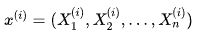
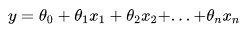
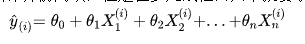
求解思路也与简单线性回归非常一致,目标同样是:
已知训练数据样本x、y ,找到,使 尽可能小.
其中 是列向量列向量,而且我们注意到,可以虚构第0个特征X0,另其恒等于1,推导时结构更整齐,也更加方便:
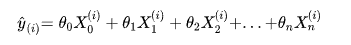
这样我们就可以改写成向量点乘的形式:
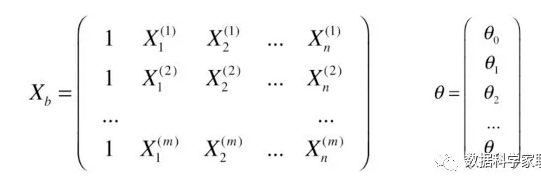
此时,我们可以得出:
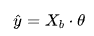
因此我们可以把目标写成向量化的形式:
已知训练数据样本x、y ,找到向量0,使 尽可能小.
推导出可以得到多元线性回归的正规方程解:
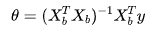
当然了,具体的推导过程不需要了解的,不影响我们的使用,我们只要知道结果思想就行,结果也不用背下来,在网上搜一下就能找到。
但是这种朴素的计算方法,缺点是时间复杂度较高:O(n^3),在特征比较多的时候,计算量很大。优点是不需要对数据进行归一化处理,原始数据进行计算参数,不存在量纲的问题(多选线性没必要做归一化处理)。
5.1多元线性回归的实现
下面我们来使用python代码实现多元线性回归:
import numpy as np
from .metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None # 系数(theta0~1 向量)
self.interception_ = None # 截距(theta0 数)
self._theta = None # 整体计算出的向量theta
def fit_normal(self, X_train, y_train):
"""根据训练数据X_train,y_train训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
# 正规化方程求解
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测的数据集X_predict,返回表示X_predict的结果向量"""
assert self.interception_ is not None and self.coef_ is not None, \
"must fit before predict"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
y_predict = X_b.dot(self._theta)
return y_predict
def score(self, X_test, y_test):
"""很倔测试机X_test和y_test确定当前模型的准确率"""
y_predict = self.predict(self, X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"
其实在代码中,思想很简单,就是使用公式即可。其中有一些知识点:
1、np.hstack(tup):参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。按列顺序把数组给堆叠起来(加一个新列)。
2、np.ones():返回一个全1的n维数组,有三个参数:shape(用来指定返回数组的大小)、dtype(数组元素的类型)、order(是否以内存中的C或Fortran连续(行或列)顺序存储多维数据)。后两个参数都是可选的,一般只需设定第一个参数。(类似的还有np.zeros()返回一个全0数组)
3、numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。inv函数计算逆矩阵
4、T:array的方法,对矩阵进行转置。
5、dot:点乘
5.2 调用
下面我们可以在jupyter notebook中调用我们的算法:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y<50.0]
y = y[y<50.0]
X.shape
输出:(490, 13)
y.shape
输出:(490, )
from myAlgorithm.model_selection import train_test_split
from myAlgorithm.LinearRegression import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, seed = 666)
reg = LinearRegression()
reg.fit_normal(X_train, y_train)
reg.coef_
输出:
array([-1.18919477e-01, 3.63991462e-02, -3.56494193e-02, 5.66737830e-02,
-1.16195486e+01, 3.42022185e+00, -2.31470282e-02, -1.19509560e+00,
2.59339091e-01, -1.40112724e-02, -8.36521175e-01, 7.92283639e-03,
-3.81966137e-01])
reg.interception_
输出:
34.16143549622471
reg.score(X_test, y_test)
输出:
0.81298026026584658
我们看到,reg.coef_这一项的结果是13个系数,这13个系数有正有负。正负代表着该系数所乘的特征与预测目标是正相关还是负相关。正相关,特征越大房价越高;负相关,特征越大,房价越低。而系数绝对值的大小决定了影响程度。
下面我们对所有的系数按照数值由小到大进行排序:
np.argsort(reg.coef_)
输出:
array([ 4, 7, 10, 12, 0, 2, 6, 9, 11, 1, 3, 8, 5])
将这个返回结果作为索引,返回排序后索引所对应的特征名:
boston.feature_names[np.argsort(reg.coef_)]
输出:
array(['NOX', 'DIS', 'PTRATIO', 'LSTAT', 'CRIM', 'INDUS', 'AGE', 'TAX',
'B', 'ZN', 'CHAS', 'RAD', 'RM'], dtype='<U7')
这也说明了线性回归算法,具有可解释性。
