

了解大数据生态系统,大数据技术列举
大数据:历史数据量逐渐攀升、新型数据类型逐渐增多。是企业必然会遇到的问题
新技术:传统方式与技术无法处理大量、种类繁多的数据,需要新的技术解决新的问题。
技术人员:有了问题,有了解决问题的技术,需要大量懂技术的人解决问题。
最佳实践:解决 问题的方法,途径有很多,寻找最好的解决方法。
商业模式:有了最好的解决办法,同行业可以复用,不同行业可以借鉴,便形成了商业模式。
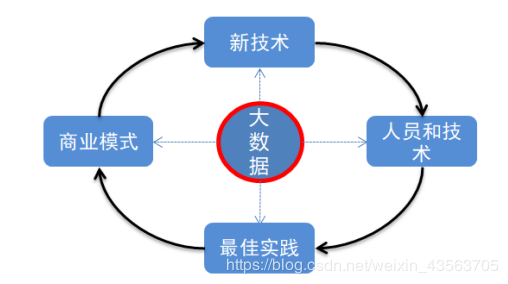
新技术:传统方式不技术无法处理大量、种类繁多的数据,需要新的技术解决新的问题。
技术人员:有了问题,有了解决问题的技术,需要大量懂技术的人解决问题。
最佳实践:解决问题的方法,途径有很多,寻找最好的解决方法。
商业模式:有了最好的解决办法,同行业可以复用,丌同行业可以借鉴,便形成了商业模式。
新技术

Hive:海量数据仓库。 Hbase:海量数据快速查询数据库。 Zookeeper:集群组件协调。
Impala:是一个能查询存储在Hadoop的HDFS和HBase中的PB级数据的交互式查询引擎。
Kudu:是一个既能够支持高吞吐批处理,又能够满足低延时随机读取的综合组件
Sqoop:数据同步组件(关系型数据库与hadoop同步)。
Flume :海量数据收集。
Kafka:消息总线。
Oozie:工作流协调。
Azkaban: 工作流协调。
Zeppelin: 数据可视化。
Hue: 数据可视化。
Flink:实时计算引擎。
Kylin: 分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析。
Elasticsearch: 是一个分布式多用户能力的全文搜索引擎。
Logstash: 一个开源数据搜集引擎。
Kibana: 一个开源的分析和可视化平台。
SPARK
SparkCore:Spark 核心组件
SparkSQL:高效数仓SQL引擎
Spark Streaming: 实时计算引擎
Structured: 实时计算引擎2.0
Spark MLlib:机器学习引擎
Spark GraphX:图计算引擎
