

简介
webpack是一个打包模块化 JavaScript 的工具,在 webpack里一切文件皆模块,通过 Loader 转换文件,通过 Plugin 注入钩子,最后输出由多个模块组合成的文件。 webpack专注于构建模块化项目。
简单版打包模型
我们先从简单的入手看,当 webpack 的配置只有一个出口时,不考虑分包的情况,其实我们只得到了一个bundle.js的文件,这个文件里包含了我们所有用到的js模块,可以直接被加载执行。那么,我可以分析一下它的打包思路,大概有以下4步:
- 利用babel完成代码转换及解析,并生成单个文件的依赖模块Map
- 从入口开始递归分析,并生成整个项目的依赖图谱
- 将各个引用模块打包为一个立即执行函数
- 将最终的bundle文件写入bundle.js中
单个文件的依赖模块Map
我们会可以使用这几个包:
- @babel/parser:负责将代码解析为抽象语法树
- @babel/traverse:遍历抽象语法树的工具,我们可以在语法树中解析特定的节点,然后做一些操作,如
ImportDeclaration获取通过import引入的模块,FunctionDeclaration获取函数 - @babel/core:代码转换,如ES6的代码转为ES5的模式
由这几个模块的作用,其实已经可以推断出应该怎样获取单个文件的依赖模块了,转为Ast->遍历Ast->调用ImportDeclaration。代码如下:
// exportDependencies.js
const fs = require('fs')
const path = require('path')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
const exportDependencies = (filename)=>{
const content = fs.readFileSync(filename,'utf-8')
// 转为Ast
const ast = parser.parse(content, {
sourceType : 'module' //babel官方规定必须加这个参数,不然无法识别ES Module
})
const dependencies = {}
//遍历AST抽象语法树
traverse(ast, {
//调用ImportDeclaration获取通过import引入的模块
ImportDeclaration({node}){
const dirname = path.dirname(filename)
const newFile = './' + path.join(dirname, node.source.value)
//保存所依赖的模块
dependencies[node.source.value] = newFile
}
})
//通过@babel/core和@babel/preset-env进行代码的转换
const {code} = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
})
return{
filename,//该文件名
dependencies,//该文件所依赖的模块集合(键值对存储)
code//转换后的代码
}
}
module.exports = exportDependencies
可以跑一个例子:
//info.js
const a = 1
export a
// index.js
import info from './info.js'
console.log(info)
//testExport.js
const exportDependencies = require('./exportDependencies')
console.log(exportDependencies('./src/index.js'))
控制台输出如下图:

单个文件的依赖模块Map
有了获取单个文件依赖的基础,我们就可以在这基础上,进一步得出整个项目的模块依赖图谱了。首先,从入口开始计算,得到entryMap,然后遍历entryMap.dependencies,取出其value(即依赖的模块的路径),然后再获取这个依赖模块的依赖图谱,以此类推递归下去即可,代码如下:
const exportDependencies = require('./exportDependencies')
//entry为入口文件路径
const exportGraph = (entry)=>{
const entryModule = exportDependencies(entry)
const graphArray = [entryModule]
for(let i = 0; i < graphArray.length; i++){
const item = graphArray[i];
//拿到文件所依赖的模块集合,dependencies的值参考exportDependencies
const { dependencies } = item;
for(let j in dependencies){
graphArray.push(
exportDependencies(dependencies[j])
)//关键代码,目的是将入口模块及其所有相关的模块放入数组
}
}
//接下来生成图谱
const graph = {}
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
//可以看出,graph其实是 文件路径名:文件内容 的集合
return graph
}
module.exports = exportGraph
这里就不贴测试例子图了,有兴趣的可以自己跑以下~~
输出立即执行函数
首先,我们的代码被加载到页面中的时候,是需要立即执行的。所以输出的bundle.js实质上要是一个立即执行函数。我们主要注意以下几点:
- 我们写模块的时候,用的是 import/export.经转换后,变成了require/exports
- 我们要让require/exports能正常运行,那么我们得定义这两个东西,并加到bundle.js里
- 在依赖图谱里,代码都成了字符串。要执行,可以使用eval
因此,我们要做这些工作:
- 定义一个require函数,require函数的本质是执行一个模块的代码,然后将相应变量挂载到exports对象上
- 获取整个项目的依赖图谱,从入口开始,调用require方法。 完整代码如下:
const exportGraph = require('./exportGraph')
// 写入文件,可以用fs.writeFileSync等方法,写入到output.path中
const exportBundle = require('./exportBundle')
const exportCode = (entry)=>{
//要先把对象转换为字符串,不然在下面的模板字符串中会默认调取对象的toString方法,参数变成[Object object]
const graph = JSON.stringify(exportGraph(entry))
exportBundle(`
(function(graph) {
//require函数的本质是执行一个模块的代码,然后将相应变量挂载到exports对象上
function require(module) {
//InnerRequire的本质是拿到依赖包的exports变量
function InnerRequire(relativePath) {
return require(graph[module].dependencies[relativePath]);
}
var exports = {};
(function(require, exports, code) {
eval(code);
})(InnerRequire, exports, graph[module].code);
return exports;
//函数返回指向局部变量,形成闭包,exports变量在函数执行后不会被摧毁
}
require('${entry}')
})(${graph})`)
}
module.exports = exportCode
将最终的bundle文件写入bundle.js中
这里,直接使用node的内置模块,fs来写入文件。根据webpack的output.path,来输出到对应的目录即可。我这里,为了简便,直接固定了输出路径,代码如下:
const fs = require('fs')
const path = require('path')
const exportBundle = (data)=>{
const directoryPath = path.resolve(__dirname,'dist')
if (!fs.existsSync(directoryPath)) {
fs.mkdirSync(directoryPath)
}
const filePath = path.resolve(__dirname, 'dist/bundle.js')
fs.writeFileSync(filePath, `${data}\n`)
}
const access = async filePath => new Promise((resolve, reject) => {
fs.access(filePath, (err) => {
if (err) {
if (err.code === 'EXIST') {
resolve(true)
}
resolve(false)
}
resolve(true)
})
})
module.exports = exportBundle
至此,简单打包完成。我贴一下我跑的demo的结果。bundle.js的文件内容为:
(function(graph) {
//require函数的本质是执行一个模块的代码,然后将相应变量挂载到exports对象上
function require(module) {
//InnerRequire的本质是拿到依赖包的exports变量
function InnerRequire(relativePath) {
return require(graph[module].dependencies[relativePath]);
}
var exports = {};
(function(require, exports, code) {
eval(code);
})(InnerRequire, exports, graph[module].code);
return exports;//函数返回指向局部变量,形成闭包,exports变量在函数执行后不会被摧毁
}
require('./src/index.js')
})({"./src/index.js":{"dependencies":{"./info.js":"./src/info.js"},"code":"\"use strict\";\n\nvar _info = _interopRequireDefault(require(\"./info.js\"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { \"default\": obj }; }\n\nconsole.log(_info[\"default\"]);"},"./src/info.js":{"dependencies":{"./name.js":"./src/name.js"},"code":"\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", {\n value: true\n});\nexports[\"default\"] = void 0;\n\nvar _name = require(\"./name.js\");\n\nvar info = \"\".concat(_name.name, \" is beautiful\");\nvar _default = info;\nexports[\"default\"] = _default;"},"./src/name.js":{"dependencies":{},"code":"\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", {\n value: true\n});\nexports.name = void 0;\nvar name = 'winty';\nexports.name = name;"}})
至此,简单打包模型完成。需要看例子的移步至:github.com/LuckyWinty/…
webpack打包流程概括
webpack的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参
- 开始编译 用上一步得到的参数初始Compiler对象,加载所有配置的插件,通 过执行对象的run方法开始执行编译
- 确定入口 根据配置中的 Entry 找出所有入口文件
- 编译模块 从入口文件出发,调用所有配置的 Loader 对模块进行编译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理
- 完成模块编译 在经过第4步使用 Loader 翻译完所有模块后, 得到了每个模块被编译后的最终内容及它们之间的依赖关系
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再将每个 Chunk 转换成一个单独的文件加入输出列表中,这是可以修改输出内容的最后机会
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,将文件的内容写入文件系统中。
在以上过程中, Webpack 会在特定的时间点广播特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,井且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。其实以上7个步骤,可以简单归纳为初始化、编译、输出,三个过程,而这个过程其实就是前面说的基本模型的扩展。
webpack打包结果简化对比
下面,我们直接看看,webpack4 打包后的代码长什么样,跟我们上文的简化模型有何区别(为了格式好看点,我精简了一下,用图片表示):
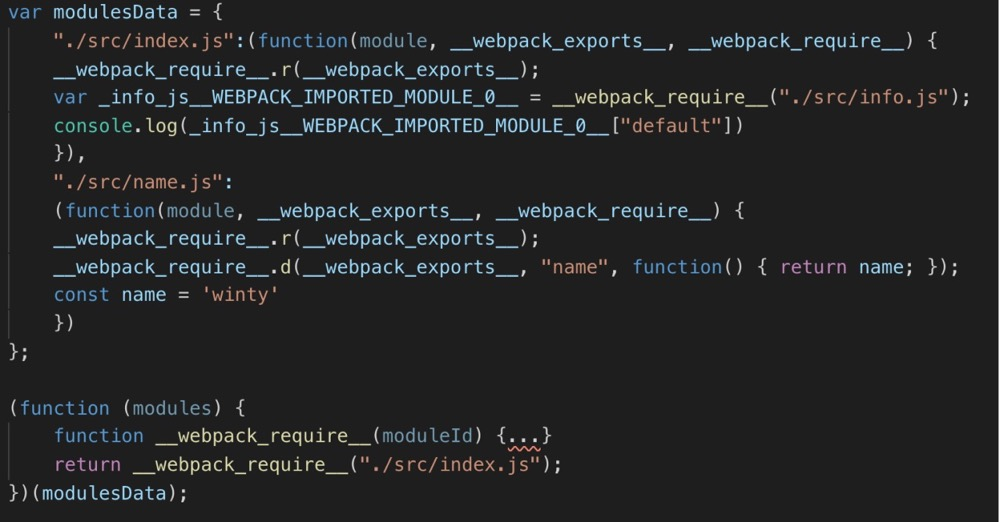
__webpack_require__和__webpack_exports__是不是很眼熟?然后再认真观察,有个Module对象,key是模块名,value是代码块。输出的也是立即执行函数,从入口开始执行...
__webpack_require__实现
这里也是放一个简化的图,因为源码,太多啦!如下:
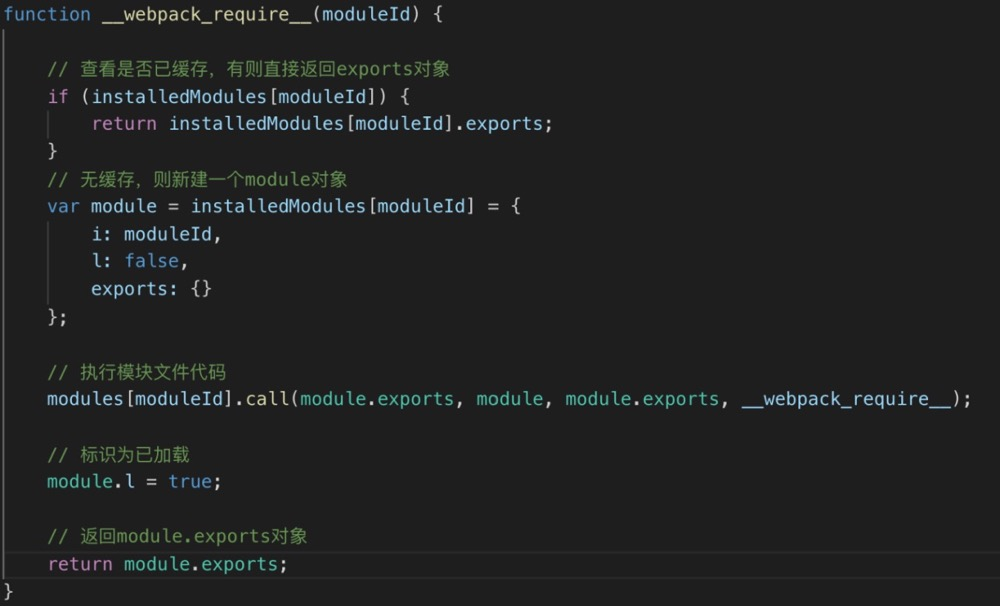
要注意的是,webpack4中只有optimization.namedModules为true,此时moduleId才会为模块路径,否则是数字id。为了方便开发者调试,在development模式下optimization.namedModules参数默认为true。
总结
其实简单模型还是很好理解的。我们理解了之后,就可以更方便地深入去了解webpack的多入口打包(应该同样的机制跑2次就可以了吧),公共包抽离(因为模块加载时有缓存,只有加上一个次数记录就可以知道这个包被加载了多少次,就可以抽离出来做公共包)了。当然还是很多细节的地方,需要耐心细致地去理解的。持续学习吧!
参考资料
- 神三元 《实现一个简单的Webpack》
- 更多资料
最后
- 欢迎加我微信(winty230),拉你进技术群,长期交流学习...
- 欢迎关注「前端Q」,认真学前端,做个有专业的技术人...

