

HBase
HBase是一个开源的非关系型分布式数据库(NoSQL),是Hadoop项目的一部分,运行于HDFS文件系统之上, (Hadoop Database )。主要应用场景是实时随机读写超大规模的数据。
HBase 内部管理的文件全部都是存储在 HDFS 当中的 ,因为是分布式的存储,所以表都是逻辑上的结构,物理上的存储分布在多个RegionServer上,并且需要一个主节点HMaster进行控制
数据模型
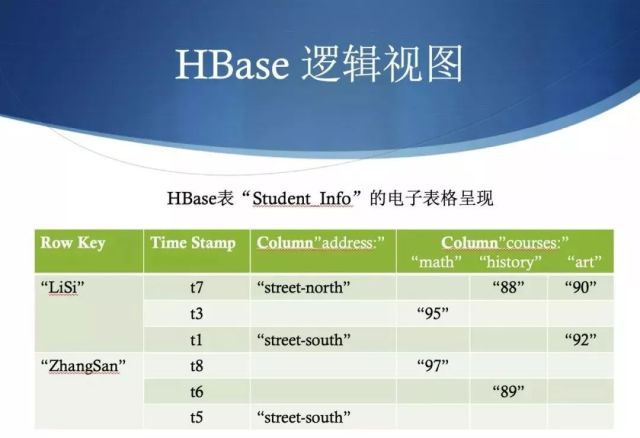
- 行健(Row Key):表的主键,表中的记录默认按照行健升序排序
- 时间戳(Timestamp):每次数据操作对应的时间戳,可以看作是数据的版本号
- 列族(Column Family):表在水平方向有一个或者多个列族组成,一个列族中可以由任意多个列组成,列族支持动态扩展,无需预先定义列的数量以及类型,所有列均以二进制格式存储,用户需要自行进行类型转换。所有的列族成员的前缀是相同的,例如“abc:a1”和“abc:a2”两个列都属于abc这个列族。
- 列(Column ),一般都是从属于某个列族,跟列族不一样,列的数量一般的没有强限制的,一个列族当中可以有数百万个列,而且这些列都可以动态添加的。
- 单元格(Cell):表存储数据的单元。由{行健,列(列族:标签),时间戳}唯一确定,其中的数据是没有类型的,以二进制的形式存储。
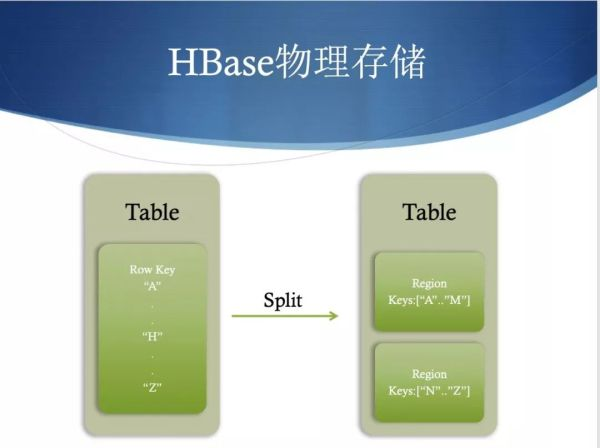
- 表和区域(Table&Region):当表随着记录数不断增加而变大后,会逐渐分裂成多份,成为区域,一个区域是对表的水平划分,不同的区域会被Master分配给相应的RegionServer进行管理

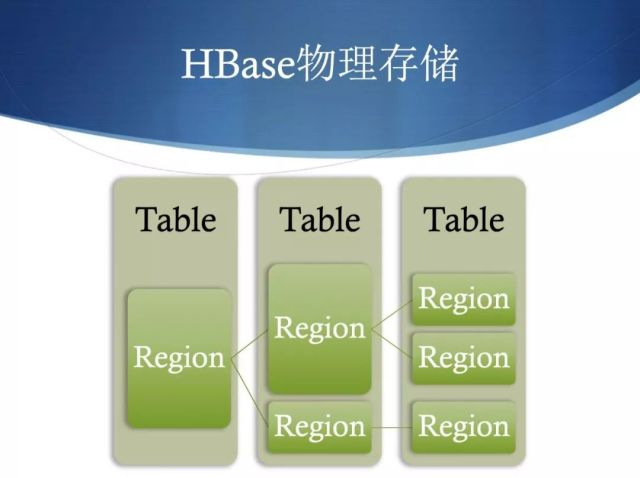
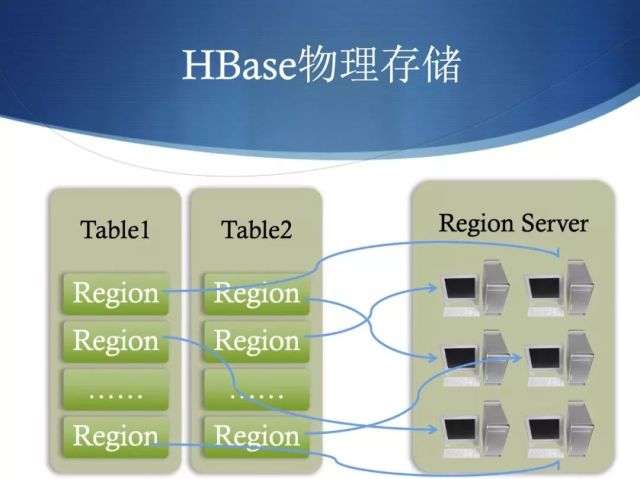
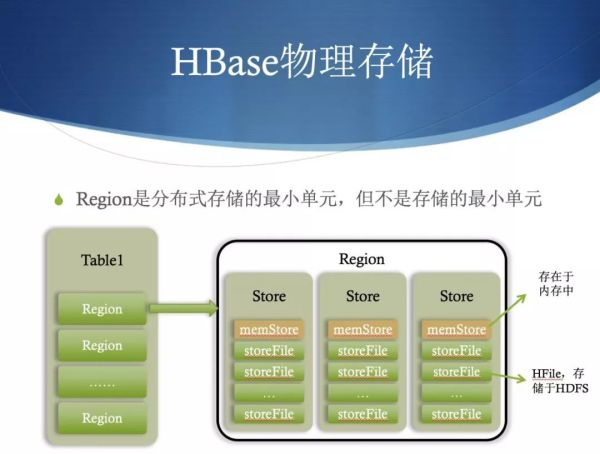
**Region是分布式存储的最小单元,存储在实际机器上,一个 Region 是由一个或多个 Store 组成。**每一个 Store 其实就是一个列族。每个Store 又是由一个 memStore 和 0 个或者多个 storeFile 组成。memStore 是存储在内存中,storeFile 是存储在 HDFS 中,有时候也称作 HFile。数据都会先写入memStore,一旦 memStore 超过给的的最大值之后,HBase 就会将memStore 持久化为 storeFile。
HBASE架构
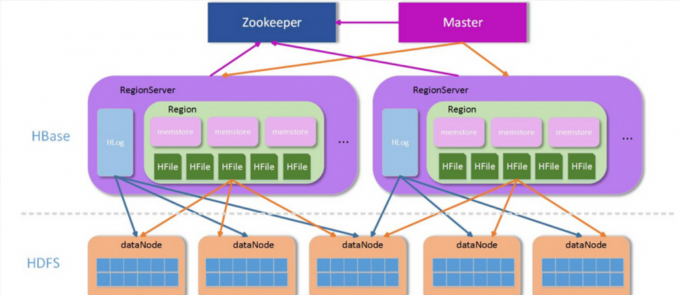
HBase架构中只有一个Master节点,称HMaster,还有多台RegionServer成为HRegionServer,每个RegionServer包含多个Region。
- HBase访问接口:Java,REST,Thrift等
- Master:集群的管理服务器,为RegionServer分配Region,负责RegionServer的负载均衡,处理schema更新请求
- RegionServer:管理HBase的数据存储,维护Region,处理IO请求。
- Zookeeper:保证集群的高可用性、存储Region的寻址入口,并实时监控RegionServer的状态,存储HBase的Schema。
client访问hbase上数据的过程并不需要Master参与(寻址访问Zookeeper和RegionServer,数据读写访问RegionServer),Master仅仅维护Table和Region的元数据信息,负载很低。
RegionServer主要管理两种文件,一是Hlog(预写日志 write-ahead log WAL),二是region(实际的数据文件)。当用户向hbase请求写入put数据时,首先就要写入Hlog实现的预写日志当中,当hbase服务器崩溃时,hlog可以回滚还没有持久化的数据,以便后续从WAL中恢复数据。 当数据写入预写日志后,数据便会存放当region中的memStore中,同时还会检查memStore是否写满,如果写满,就会被请求刷写到磁盘中。
一般步骤:
1.联系zookeeper,找出meta表(元数据表)所在rs(regionserver) /hbase/meta-region-server
2.定位row key,找到对应region server 3.缓存信息在本地(再次查找数据时,不需要经过1,2步骤)
4.联系RegionServer
5.HRegionServer负责open HRegion对象,为每个列族创建Store对象,Store包含多个StoreFile实例,他们是对HFile的轻量级封装。每个Store还对应了一个MemStore,用于内存存储数据。
HDFS构建了一个分布式文件系统,HBase则是在其基础之上构建一个非关系型数据库,HBase的所有操作最终还是会基于HDFS,映射到HDFS之上,所有逻辑上的操作都是在HDFS之上进行。
安装配置
配置hbase-site.xml
位于 ${HBase-Dir}/conf/hbase-site.xml
单击版配置:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///tmp/hbase-${user.name}/hbase</value>
</property>
</configuration>
伪分布式配置:
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
hbase.rootdir:该参数制定了HReion服务器的位置,即数据存放的位置。主要端口号要和Hadoop相应配置一致。
hbase.cluster.distributed:HBase的运行模式。false是单机模式,true是分布式模式。若为false, HBase和Zookeeper会运行在同一个JVM里面。默认为false.
设置环境变量
修改HBase下的conf目录中的hbase-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export HBASE_MANAGES_ZK=true
为方便使用,将HBase下的bin命令放在系统的/etc/profile下:
sudo vim /etc/profile
# set hbase path
export HBASE_HOME=/opt/hbase-1.2.6
export PATH=$PATH:/opt/hbase-1.2.6/bin
启动/停止
在hbase的bin下执行脚本
./start-hbase.sh
./stop-hbase.sh
HBase基于HDFS,因此必须先启动HDFS
启动HBase实例之后,使用 ./hbase shell连接HBase实例到shell
命令 quit退出HBase Shell 并且断开和集群的连接
namespace
将其当做管理多个表的一个Schema即可,如同mysql中的database
- create_namespace:创建一个namespace,后面跟着namespace的名称
create_namespace 'test'
- list_namespace:查看namespace
表管理
默认情况下,是在系统的namespace下建表,在自建的namepace下建表使用namespace名:表名
-
status:查看HBase状态
-
create:建表,指定表名与列族名,所有字段都要用' '包含起来,第一个为表名,剩余都是列族名
hbase(main):001:0> create 'test', 'cf'
- list:查看表信息,后面跟着表名
hbase(main):002:0> list 'test'
- describe:查看表的详细信息,后面跟着表名
- disable/drop:用于删除表,先disable然后drop,后面跟着表名,disable禁用一个表,enable则重新启用
disable 'test'
drop 'test'
- exists:检查表是否存在,后面跟着表名
exists 'test'
数据管理
- put:向表中插入信息,先跟着表名,后面是行名,指定列(列族:列),指定值
put 'test', 'row1', 'cf:a', 'yasuo'
put 'test', 'row2', 'cf:b', 'lsl'
重复put列会直接覆盖
- get:获取某一行的数据,先跟着表名,后跟着行名
get 'test', 'row'
- scan:扫描全表,后面跟着表名
scan 'test'
数据表设计
热点问题
在设计rowkey时,有大量连续编号的rowkey。这就会导致大量rowkey相近的记录集中在个别region里,也就是集中在一台或几台regionServer当中。当client检索记录时,对个别region访问过多,这时此region所在的主机过载,就导致热点问题的出现。 也就是说大量访问集群中的某一台PC导致该PC过载,导致负载不均衡
解决方法:
加盐
在rowkey的前面分配随机数,当给rowkey随机前缀后,它就能分布到不同的region中,这里的前缀应该和你想要数据分散的不同的region的数量有关。
引用例子: www.shiyanlou.com/courses/37/…
我们去电信公司打印电话详单也就是通话记录。对于通话记录来说,每个人每月可能都有很多通话记录,而使用电信的用户也是亿计。这种信息,我们就能存入hbase当中。
对于通话记录,我们有什么信息需要保存呢?首先,肯定应该有主叫和被叫,然后有主叫被叫之间的通话时长,以及通话时间。除此之外,还应该有主叫的位置信息,和被叫的位置信息。
由此,我们的通话记录表需要记录的信息就出来了:主叫、被叫、时长、时间、主叫位置、被叫位置。
我们该如何来设计一张hbase表呢?
首先,hbase表是依靠rowkey来定位的,我们应该将尽可能多的将查询的信息编入rowkey当中。hbase的元数据表mate表就给我们了一个很好的示例。它包括了namespace,表名,startKey,时间戳,计算出来的码(用于分散数据)。
所以,当我们设计通话记录的rowkey时,需要将能唯一确定该条记录的数据编入rowkey当中。即是需要将主叫、被叫、时间编入。
如下所示:
17765657979 18688887777 201806121502 #主叫,被叫,时间但是我们能否将我们设计的rowkey真正应用呢?
当然是可以的,但是热点问题便会随之而来。
例如你的电话是以177开头,电信的hbase集群有500台,你的数据就只可能被存入一台或者两台机器的region当中,当你需要打印自己的通话记录时,就只有一台机器为你服务。而若是你的数据均匀分散到500机器中,就是整个集群为你服务。两者之间效率速度差了不止一个数量级。
注意:由于我们的regionServer就只有一台,没有集群环境,所以我们只介绍方法和理论操作,不提供实际结果因为我们设定整个hbase集群有500台,所以我们随机在0-499之间中随机数字,添加到rowkey首部。
如下所示:
12 17765657979 18688887777 201806121502 #随机数,主叫,被叫,时间在插入数据时,判断首部随机数字,选择对应的region存入,由于rowkey首部数字随机,所以数据也将随机分布到不同的regionServer中。这样就能很好的避免热点问题了。`
hash在大数据中的应用
对于大量重复数据需要统计的时候,利用hash的性质进行一次预处理,将hashcode相同的数据交给同一台PC,这样PC能进行快速计算同时避免进一步合并,即不是将数据均分,而是依据已有数据的性质做一次运算,根据结果分配数据以达到算力分配最优。
引用例子: www.shiyanlou.com/courses/37/…
例如,我们有一个10TB的大文件存在分布式文件系统上,存的是100亿行字符串,并且字符串无序排列,现在我们要统计该文件中重复的字符串。
假设,我们可以调用100台机器来计算该文件。
那么,现在我们需要怎样通过哈希函数来统计重复字符串呢。
首先,我们需要将这一百台机器分别从0-99标好号,然后我们在分布式文件系统中一行行读取文件(多台机器并行读取),通过哈希函数计算hashcode,将计算出的hashcode模以100,根据模出来的值,将该行存入对应的机器中。
根据哈希函数的性质,我们很容易看出,相同的字符串会存入相同的机器中。
然后我们就能并行100台机器,各自分别计算相应的数据,大大加加快统计的速度。
注意:这10TB文件并不是均分成100GB,分给100台机器,而是这10TB文件中不同字符串的种类,均分到100台机器中。如果还嫌单个机器处理的数据过大,可以按照同样的方法,在一台机器中并行多个进程,处理数据。
HBase布隆过滤器
布隆过滤器是一种利用hash算法节约空间的存储方式,最基本的以每一个位(bit)为基本单位,bit是信号量,有0,1两种状态,因此可以根据需要过滤某些数据(如IP黑名单),直接存ip过于耗费内存,因此不存ip,而是根据hash进行映射获得hashcode,根据hashcode对信号量的位置取模变换为0或1,即以时间换空间。但因为基于hash,可能两个不同的数据得到同一个hashcode,因此可能会出现数据误判情况。
引用例子: www.shiyanlou.com/courses/37/…
首先,我们应当知道,hash是内存中使用的经典数据结构。
当我们需要判读一个元素是否在一个集合当中时,我们可以用哈希表来判断。在集合较小的情况下,hash是可行而且高效的。
然而数据量以PT计的大数据场景中,很多时候,hash便力有未逮。这是因为在海量数据下hash要占据巨额内存空间,这远远超过我们能够提供的内存大小。
例如在黑名单过滤当中,我们有100亿的网站黑名单url需要过滤,假设一个url是64bytes。如果我们用hash表来做,那么我们至少需要6400亿字节即640G的内存空间(实际所需空间还远大于此),空间消耗巨大,必须要多个服务器来同时分摊内存。
然而我们是否能用更加精简的结构来做这件事呢?布隆过滤器就是这样一个高度节省空间的结构,并且其时间也远超一般算法,但是布隆过滤器存在一定的失误率,例如在网页URL黑名单过滤中,布隆过滤器绝不会将黑名单中网页查错,但是有可能将正常的网页URL判定为黑名单当中的,它的失误可以说是宁可错杀,不可放过。不过布隆过滤器的失误率可以调节,下面我们会详细介绍。
布隆过滤器实际就是一种集合。假设我们有一个数组,它的长度为L,从0-(L-1)位置上,存储的不是一个字符串或者整数,而是一个bit,这意味它的取值只能为0或1.
例如我们实现如下的一个数组:
int[] array = new int[1000];该数组中有1000个int类型的元素,而每一个int由有4个byte组成,一个byte又由8个bit组成,所以一个int就由32个bit所组成。
所以我们申请含1000整数类型的数组,它就包含32000个bit位。
但是我们如果想将第20001个bit位描黑,将其改为1,我们需要怎样做呢。
首先我们的需要定位,这第20001个bit位于哪个整数,接着我们需要定位该bit位于该整数的第几个bit位。
int index = 20001; int intIndex = index/32; int bitIndex = index%32;然后我们就将其描黑:
array[intIndex] =(array[intIndex] | (1 << bitIndex));这段代码可能有些同学不能理解,下面我们详细解释一下。 我们的数组是0-999的整型数组,但是每个位置上实际保存的是32个bit,我们的intIndex就是代表第几个整数,定位到625,而bitIndex定位到第625个整数中的第几个bit,为1。
所以,我们需要描黑的位置是第625号元素的第1个bit。
而
(1 << bitIndex)代表将1左移到1位置,即是代表只有1位置为1,而其他位置为零。就相当于获得了这样一串二进制数:00000000 00000000 00000000 00000001然后我们将这样的二进制数与array[indIndex]进行逻辑或运算,就能将第625号元素的第一个bit描黑变1,最后我们将描黑后的元素赋值给array[indIndex],完成运算。
这里我们采用的是int类型的数组,如果我们想更加节省空间,我们就能创建long类型的数组,这样申请1000个数组空间,我们就能得到64000个bit。
然后我们还能进一步扩展,将数组做成矩阵:
long[][] map = new long[1000][1000];有了这些基础以后,我们如何设计黑名单问题呢?
假设我们已经有了一个拥有m个bit的数组,然后我们将一个URL通过哈希函数计算出hashcode,然后
hashcode%m将对应位置描黑。然而这还不是真正的布隆过滤器,真正的布隆过滤器是通过多个哈希函数对一个URL进行计算,得到hashcode,然后在对不同位置的bit进行描黑。
注意:布隆过滤器采用的多个哈希函数必须是相互独立的,前面我们已经介绍了如何通过一个哈希函数构造多个独立哈希函数的方法。当我们将一个URL通过n个哈希函数,得到hashcode,模以m,再将对应位置描黑之后。我们可以说该URL已经进入我们的布隆过滤器当中了。
接下来,我们将黑名单中所有URL都通过哈希函数,进入布隆过滤器中(布隆过滤器并不真正存储实际的URL)。
对于一个新的URL,我们要查询其是否在黑名单中,我们便通过同样的n个哈希函数,计算出n个位置,然后我们查询这n个位置是否都被描黑,如果都被描黑,我们就说该URL在黑名单当中。如果n个位置但凡有一个不为黑,我们就说该URL不在该黑名单中。
注意:我们的数组不应该过小,不然很可能数组中的大多数位置都被描黑,这很容易将正常的URL判定为不合法的,这也是布隆过滤器的失误率来源。
参考:
实验楼
知乎
<<Hadoop权威指南 第四版>>
