

全文共12845字,预计学习时长37分钟

来源:Pexels
无论是在高额赌注的扑克比赛中,还是在《星际争霸》比赛中对抗世界一流玩家,人工智能机器都大获全胜,驾驶特斯拉的未来跑车也是游刃有余。那么它们都有哪些共同点呢?一直以来,人们都认为,机器不可能完成这些极其复杂的任务。直到今天,深度强化学习取得的最新进展表明这一切皆有可能。
强化学习已经开始主导世界。
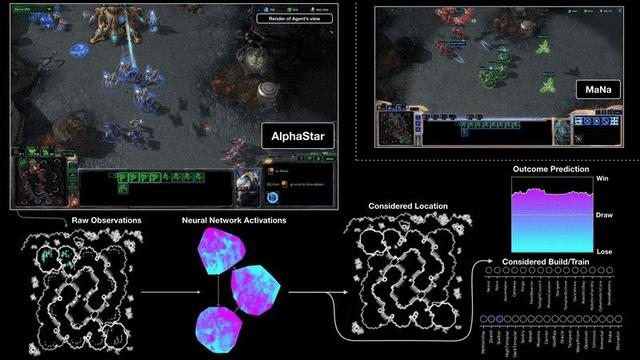
图源: https://deepmind.com/blog/arti
两个多月前,我决定参与到这场伟大的变革中,于是我开始利用最先进的深度强化学习算法,创建一个盈利的比特币交易策略。虽然我在这方面取得了相当大的进展,但我意识到,这种项目使用的工具可能会让人望而却步,很容易迷失在细节中。
我一直在优化以前的分布式高性能计算(HPC)系统项目,在无穷无尽的数据和特征优化中晕头转向;我也一直在思考如何进行高效的模型建立、调整、训练和评估。于是我意识到必须找到一个更好的方法。在花费了大量的时间对现有项目进行研究、观看PyData的演讲、并与RLtrading Discord社区的数百名成员进行了多次互动之后,我意识到现有的解决方案没有一个是完美的。
尽管互联网上有许多零零碎碎的强化学习交易系统,但都不稳定,也不够完善。为此,我决定创建一个开源Python框架,以便有效地用深度强化学习将任意一种交易策略从想法转换为实际运用。
TensorTrade就这样诞生了。它旨在创建一个高度模块化的框架,以组合式的、可维护的方式构建有效的强化学习交易策略。这听起来就是一大堆行话。接下来让我们进入正题吧。
目录
综述
· 强化学习简介
· 入门指南
· 安装
TensorTrade组件
· 交易环境
· 票据转换
· 特征通道
· 行动策略
· 奖励策略
· 学习代理
· 稳定基线
· Tensorforce
· 交易策略
汇总
· 创建环境
· 选择代理
· 训练策略
· 保存和恢复
· 调整策略
· 策略评估
· 实时交易
前景
· 结语
· 致谢
· 参考文献
1. 综述

TensorTrade是一个开源的Python框架,可以通过深度强化学习来训练、评估和部署稳健的交易策略。该框架侧重于高度的可组合性和可扩展性,允许系统从单个CPU上的简单交易策略扩展到运行在HPC机分布上的复杂投资策略。
在此框架下,TensorTrade使用许多现有机器学习库中的API来维护高质量的数据管道和学习模型。其主要目标之一是利用numpy,pandas,gym,keras和tensorflow提供的现有工具和管道,快速试验算法交易策略。
框架的每一部分都能分解为可重复使用的组件,可以使用社区创建的通用组件,同时保持专属特征的私有性。其目的是简化使用深度强化学习测试和部署稳健交易代理的过程,使你我双方都能够专注创建可盈利的策略。
1.1强化学习简介
如果不熟悉强化学习,可以快速回顾一下基本概念。
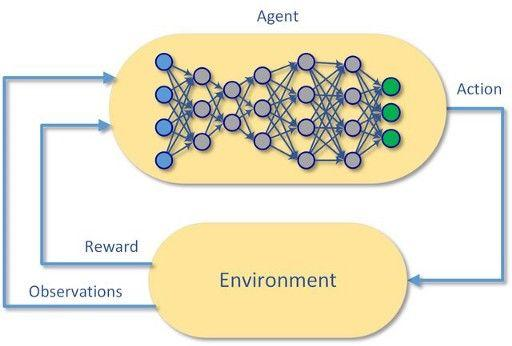
强化学习(ReinforcementLearning,RL)是机器学习的一个研究领域,它关注软件代理如何在一个环境中活动,以谋取最大化的累积回报。
每个强化学习问题都是从一个环境和一个或多个可以与该环境交互的代理开始的。
这种技术的基础可追溯到20世纪50年代的马尔科夫决策过程(MDP)。
代理将首先观察环境,然后根据环境的当前状态和操作的期望值创建一个模型。基于该模型,代理将采取它认为具有最高期望值的操作。
根据所选操作在环境中的效果,代理将获得与该操作实际值相应的奖励。然后,强化学习代理可以通过试错过程(即通过强化)来改进其基础模型,并学习如何在将来获得更多的回报。
如果想了解一些新内容,可以在本文的参考文献中找到《深度强化学习入门》的链接,这篇文章有更深入的细节介绍。
1.2 入门指南
以下教程将提供充足的示例,教你使用TensorTrade创建简单的交易策略。但是很快,你就会知道该框架能够处理更加复杂的配置。
也可以参考Google Colab或Github上的教程。
1.3 安装
安装TensorTrade需要Python3.5及以上版本,因此在用pip安装之前,请确保所用版本有效。
pipinstall tensortrade
要完成整个教程,需要安装一些额外的配件,如
tensorflow, tensorforce, stable-baselines,ccxt, TA-lib,
以及
stochastic.pipinstall tensortrade[tf,tensorforce,baselines,ccxt,talib,fbm]
如果想使用所有功能,还需要从此网站安装ta-lib应用程序。
这就是所有必要的安装!下面来说代码。
2. TensorTrade组件
TensorTrade围绕模块化组件构建,这些组件整合成了一个交易策略。交易策略以gym环境的形式将强化学习代理与组合式交易逻辑相结合。交易环境由一组模块化组件组成,这些组件可以混合和匹配,以创建高度多样化的交易和投资策略。后续将进一步解释这一点,但目前,了解这些基本信息就足够了。

与电气部件一样,TensorTrade组件的目的是能够根据需要进行混合和匹配。
本节中代码段的作用应该是指导创建新策略、新组件。确定的组件越多,就可能会缺少一些实施细节,这些细节将在后面的小节中详述。
2.1交易环境
交易环境是遵照OpenAI的gym.Env规范的强化学习环境,允许在交易代理中使用许多现有的强化学习模型。

交易环境是完全可配置的gym环境,具有高度可组合的InstrumentExchange、FeaturePipeline、行动策略和奖励策略组件。
· InstrumentExchange观察环境,并执行代理的交易。
· FeaturePipeline在将交易输出传递给代理之前,将其转换为一组更有意义的特征。
· 行动策略将代理的操作转换为可执行的交易。
· 奖励策略根据代理的效益计算每个时间步的奖励。
现在看起来有点复杂,但其实很简单,这就是它的全部内容。现在只需要将这些组件一一匹配到完整的环境中。
当调用交易环境的reset时,所有子组件也将重置。每个票据转换、特征通道、转换器、行动策略和奖励策略的内部状态将重置为默认值,为下一环节做好准备。
下面从一个示例环境开始。如前所述,初始化交易环境需要一个票据转换、一个行动策略和一个奖励策略,也可以加上一个特征通道。
from tensortrade.environments importTradingEnvironmentenvironment = TradingEnvironment(exchange=exchange,
action_strategy=action_strategy,
reward_strategy=reward_strategy,
feature_pipeline=feature_pipeline)
虽然推荐的用例是将交易环境插入到交易策略中,但显然可以单独使用交易环境,不过也可以使用gym环境。
2.2 票据转换(InstrumentExchanges)
票据转换决定交易环境中可进行的范围,在每个时间步向交易环境返回观测结果,并在交易环境中执行交易。有两种类型的交易工具:实时交易和模拟交易。
实时交易由实时定价数据和实时交易执行引擎支持的交易工具实现。例如,CCXTExchange是一个实时交易,它能够在数百个实时加密货币交易所(如Binance和Coinbase)上返回定价数据并执行交易。
import ccxtfrom tensortrade.exchanges.liveimport CCXTExchangecoinbase = ccxt.coinbasepro()exchange =CCXTExchange(exchange=coinbase, base_instrument='USD')
也有供股票和ETF交易的交易所,如RobinhoodExchange和InteractiveBrokersExchange,但这些仍在开发阶段。
另一方面,模拟交易是由模拟定价数据和交易执行支持的交易工具实现。
例如,FBMExchange是一个模拟交易,它使用分数布朗运动(FBM)生成定价和成交量数据。模拟价格只用于模拟交易。一个简单的滑动模型可以用来模拟交易中的价格和成交量的滑动。和TensorTrade中的所有情况一样,这种滑动模型可以很容易地替换为更复杂的模型。
from tensortrade.exchanges.simulated importFBMExchangeexchange = FBMExchange(base_instrument='BTC', timeframe='1h')
虽然FBMExchange使用随机模型生成虚拟的价格和成交量数据,但它只是模拟交易的实现。模拟交易只需要一个记录历史价格的data_frame就可以生成模拟。此data_frame可以由编码的实现(如FBMExchange)提供,也可以在运行时提供(如以下示例)。
import pandas as pdfrom tensortrade.exchanges.simulatedimport SimulatedExchangedf =pd.read_csv('./data/btc_ohclv_1h.csv')exchange =SimulatedExchange(data_frame=df, base_instrument='USD')
2.3 特征通道(FeaturePipelines)
特征通道用于将交易环境中的观察结果转换为有意义的特征供代理学习。如果已将通道添加到指定的交易中,则观察结果将在输出到交易环境之前将通过FeaturePipeline。例如,在将观察结果返回给代理之前,一个特征通道可以将所有价格价值归一化,使一个时间序列保持不变,添加一个移动平均列,并删除不必要的列。

特征通道可以用任意数量的逗号分隔转换器进行初始化。每个FeatureTransformer都要使用需转换的列集进行初始化,如果没有传送任何内容,则转换所有输入列。
每个特征转换器都有一个transform算法,它从更大的数据集中转换每个观察结果(pandas.DataFrame),并保存转换下一帧所需的状态。为此,通常需要定期用reset重置FeatureTransformer。每次重置上级FeaturePipeline或InstrumentExchange时都会自动执行此操作。
创建一个传输示例并将其添加到现有的交易中。
from tensortrade.features import FeaturePipeline
from tensortrade.features.scalers import MinMaxNormalizer
from tensortrade.features.stationarity import FractionalDifference
from tensortrade.features.indicators import SimpleMovingAverageprice_columns= ["open", "high", "low","close"]normalize_price = MinMaxNormalizer(price_columns)
moving_averages = SimpleMovingAverage(price_columns)
difference_all = FractionalDifference(difference_order=0.6)feature_pipeline =FeaturePipeline(steps=[normalize_price,
moving_averages,
difference_all])exchange.feature_pipeline = feature_pipeline
该特征通道将价格价值归一到0和1之间,然后添加一些移动平均列,并通过对连续值进行分数差分使整个时间序列保持不变。
2.4 行动策略
行动策略定义了交易环境的行动空间,并将代理的行动转换为可执行的交易。例如,如果使用3个行动的离散行动空间(0=持有,1=全部买入,2=全部卖出),则学习代理不需要知道返回操作1等同于买进。相反,代理需要知道在特定情况下返回操作1获得的奖励,并且可以将操作转换为交易的实现细节交由行动策略来完成。
每个行动策略都有一个get_trade算法,该算法将代理的指定行动转换为可执行的交易。通常需要在该策略中存储额外的状态,例如跟踪当前交易状态。每次调用行动策略的reset算法时都应重置此状态,这一步在上级交易环境重置时可以自动完成。
from tensortrade.actions import DiscreteActionStrategyaction_strategy= DiscreteActionStrategy(n_actions=20,
instrument_symbol='BTC')
该离散行动策略使用20个离散操作,相当于5种交易类型(市场买/卖,限买/卖和持有),每种交易类型都有4种离散金额。例如,[0,5,10,15]=持有,1=市场买入25%,2=市场卖出25%,3=限价买入25%,4=限价卖出25%,6=市场买入50%,7=市场卖出50%,等等。
2.5 奖励策略
奖励策略接收每个时间步采取的交易,并返回一个float,对应此操作的收益。例如,如果这一步采取的操作是卖出,引起利润增加,奖励策略可以返回一个正数,以鼓励更多这样的交易。相反,如果此操作是引发损失的卖出行为,则该策略可以返回一个负收益,以告知代理以后不要做出类似的操作。
此示例算法的一个版本在SimpleProfitStrategy中可见,但是显然可以使用更复杂的策略来代替。
每个奖励策略都有一个get_reward 算法,该算法接受在每个时间步执行的交易,并返回对应此操作价值的浮点。与行动策略一样,出于种种原因,常常需要在奖励战略中存储额外状态。每次调用奖励策略的reset时都应重置此状态,这在重置上级交易环境时自动完成。
from tensortrade.rewards import SimpleProfitStrategyreward_strategy= SimpleProfitStrategy()
简单利润策略返回收益-1代表不进行交易,1代表进行交易,2代表买入,以及卖出时与交易所得(正/负)利润相对应的值。
2.6 学习代理
到目前为止,本文还没有触及到深度强化学习框架的“深度”。这就是学习代理的用武之地。学习代理是数学(或魔法)发挥作用的地方。

在每个时间步中,代理将从交易环境观察到的结果作为输入,利用其基础模型(大多数是神经网络)来运行,并输出要采取的操作。例如,观察结果可能是交易先前的开盘价、高点、低点和收盘价。学习模型将这些值作为输入,并输出与要采取的操作(如买进、卖出或持有)相对应的值。
重要的是,要记住学习模型对这些值所代表的价格或交易没有判断。相反,该模型只是学习针对特定输入值或输入值序列需要输出哪些值,才能获得最高收益。
2.7 稳定基线
本例将使用稳定基线库来为交易策略提供学习代理。然而,TensorTrade框架与许多强化学习库兼容,例如Tensorforce、Ray的RLLib、OpenAI基线、Intel的Coach,或者TensorFlow的任何相关产品,例如TF Agents。
将来有可能在该框架中添加自定义的TensorTrade交易学习代理,尽管该框架的目标始终是尽可能多地与现有强化学习库进行互操作,以促进该领域的协调增长。
但是目前,稳定基线操作简单,功能强大,足以满足人们的需求。
from stable_baselines.common.policiesimport MlpLnLstmPolicy
from stable_baselines import PPO2model = PPO2
policy = MlpLnLstmPolicy
params = { "learning_rate": 1e-5 }agent = model(policy, environment,model_kwargs=params)
注意:尽管本教程需要稳定基线,但使用TensorTrade则不需要。本例使用支持GPU的PPO(Proximal Policy Optimization)模型,该模型具有分层归一化的LSTM感知器网络。如果想了解更多关于稳定基线的信息,可以查看此文。
2.8 Tensorforce
下面将简要介绍Tensorforce库,它在强化学习框架之间切换自如。
from tensorforce.agents import Agentagent_spec= {
"type": "ppo_agent",
"step_optimizer": {
"type":"adam",
"learning_rate": 1e-4
},
"discount": 0.99,
"likelihood_ratio_clipping": 0.2,
}network_spec = [
dict(type='dense', size=64,activation="tanh"),
dict(type='dense', size=32,activation="tanh")
]agent = Agent.from_spec(spec=agent_spec,
kwargs=dict(network=network_spec,
states=environment.states,
actions=environment.actions))
如果想了解更多关于Tensorforce代理的信息,请查看此文
2.9 交易策略
一个交易策略包括一个学习代理和一个或多个用于调整、训练和评估的交易环境。只有一个交易环境,可以进行调整、培训和评估。如有多个交易环境,在每一步可提供单独的交易环境。
from tensortrade.strategies importTensorforceTradingStrategy,
StableBaselinesTradingStrategya_strategy =TensorforceTradingStrategy(environment=environment,
agent_spec=agent_spec,
network_spec=network_spec)b_strategy =StableBaselinesTradingStrategy(environment=environment,
model=PPO2,
policy=MlpLnLSTMPolicy)
如果还不了解策略初始化,请不要担心,稍后将对其进行更详细的说明。
3. 汇总
既然已经了解了组成交易策略的每一个组件,那么接下来就开始构建和评估一个交易策略。

简单地说,交易策略是由交易环境和学习代理组成。交易环境是一个gym环境,它包含一个Instrument Exchange、一个行动策略、一个奖励策略和一个可选的Feature Pipeline,并返回对学习代理进行培训和评估的观察结果和收益。
3.1 创建环境
第一步是使用上述组件创建一个交易环境。
from tensortrade.exchanges.simulatedimport FBMExchange
from tensortrade.features.scalers import MinMaxNormalizer
from tensortrade.features.stationarity importFractionalDifference
from tensortrade.features import FeaturePipeline
from tensortrade.rewards import SimpleProfitStrategy
from tensortrade.actions import DiscreteActionStrategy
from tensortrade.environments importTradingEnvironmentnormalize_price = MinMaxNormalizer(["open","high", "low", "close"])
difference = FractionalDifference(difference_order=0.6)
feature_pipeline = FeaturePipeline(steps=[normalize_price,
difference])exchange = FBMExchange(timeframe='1h',
base_instrument='BTC',
feature_pipeline=feature_pipeline)reward_strategy = SimpleProfitStrategy()action_strategy= DiscreteActionStrategy(n_actions=20,
instrument_symbol='ETH/BTC')environment =TradingEnvironment(exchange=exchange,
action_strategy=action_strategy,
reward_strategy=reward_strategy,
feature_pipeline=feature_pipeline)
很简单,现在的交易环境是一个gym环境,可以为任何兼容的交易策略或学习代理所用。
3.2 确定代理
现在交易环境已经建立,接下来应该创建学习代理。同样,这里也需要用到稳定基线,可在这里加入任何其他强化学习代理。
由于本文使用的是稳定基线交易策略,所以需要做的就是提供一个模型类型和策略类型对基础神经网络进行训练。本例将用到一个简单的PPO模型和一个分层归一化的LSTM策略网络。
有关模型和策略规范的更多示例,请参见稳定基线文档。
from stable_baselines.common.policiesimport MlpLnLstmPolicy
from stable_baselines import PPO2model = PPO2
policy = MlpLnLstmPolicy
params = { "learning_rate": 1e-5 }
3.3 训练策略
创建交易策略就像插入代理和交易环境一样简单。
from tensortrade.strategies importStableBaselinesTradingStrategystrategy =StableBaselinesTradingStrategy(environment=environment,
model=model,
policy=policy,
model_kwargs=params)
然后,为了训练策略(即在当前交易环境中训练代理),需要做的就是调用strategy.run(),使用想要运行的步骤或episode的总数。
performance= strategy.run(steps=100000,
episode_callback=stop_early_callback)
大约需要三个小时,可以生成数千份报表,可以从中看出代理的完成情况!
如果觉得这个反馈循环有点慢,可以传送一个回调函数来运行,每个episode的末尾可以调用回调函数。回调函数将传入一个数据帧,该数据帧包含代理在该episode中的表现,并期望返回一个布尔值。如果为真,代理将继续训练,否则,代理将停止并返回其整体性能。
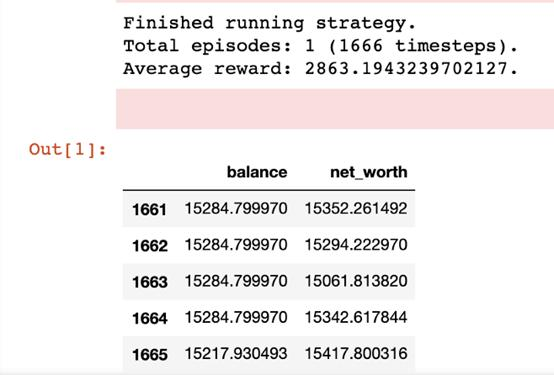
该episode结束后的简单性能输出,包括了代理的最后5项余额和净值。
3.4 保存和还原
所有交易策略都能够将其代理保存到文件中,以便以后的还原。交易环境是无法保存的,因为它无需保存。要将TensorflowTradingStrategy保存到文件中,只需该文件到策略的路径即可。
strategy.save_agent(path="../agents/ppo_btc_1h")
要从文件中还原代理,首先需要对策略进行实例化,然后再调用restore_agent。
from tensortrade.strategies importStableBaselinesTradingStrategystrategy =StableBaselinesTradingStrategy(environment=environment,
model=model,
policy=policy,
model_kwargs=params)strategy.restore_agent(path="../agents/ppo_btc/1h")
策略现在已还原到以前的状态,准备再次使用。
3.5 调整策略
有时,交易策略需要调整交易环境的一组超参数或特征,以充分发挥作用。在本例中,每个交易策略都提供了一个可选的调整方法。
调整模型类似于训练模型,但是除了调整和保存最佳模型的权重和偏差之外,该策略还调整和保存生成该模型的超参数。
from tensortrade.environments importTradingEnvironment
from tensortrade.exchanges.simulated import FBMExchangeexchange =FBMExchange(timeframe='1h',
base_instrument='BTC',
feature_pipeline=feature_pipeline)environment =TradingEnvironment(exchange=exchange,
action_strategy=action_strategy,
reward_strategy=reward_strategy)strategy.environment =environmenttuned_performance = strategy.tune(episodes=10)
在这种情况下,代理将需要10个episode的训练,每episode都有一组不同的超参数。最佳的一组将保存在策略中,并在此后随时调用strategy.run()。
3.6 策略评估
既然已经对代理进行了调整和训练,是时候检验成果了。为了评估策略在不可见数据上的性能,需要在由这些数据支持的新交易环境中运行。
from pandas import pdfrom tensortrade.environmentsimport TradingEnvironment
from tensortrade.exchanges.simulated import SimulatedExchangedf =pd.read_csv('./btc_ohlcv_1h.csv')exchange = SimulatedExchange(data_frame=df,
base_instrument='BTC',
feature_pipeline=feature_pipeline)environment =TradingEnvironment(exchange=exchange,
action_strategy=action_strategy,
reward_strategy=reward_strategy)strategy.environment =environmenttest_performance = strategy.run(episodes=1, testing=True)
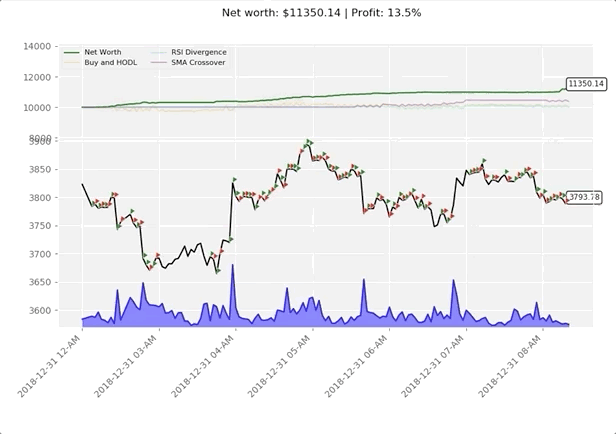
完成后,strategy.run返回代理性能的Pandas数据帧,包括代理在每个时间步的净值和余额。
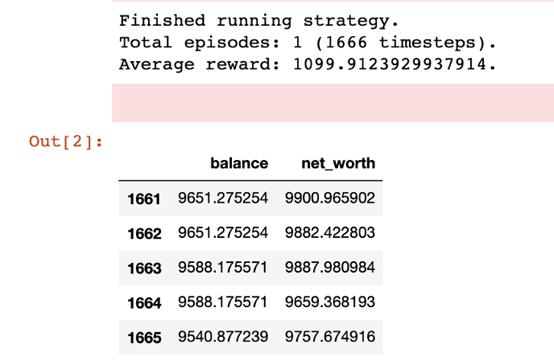
评估性能示例——此代理尚未针对此特征集进行训练,因此其性能具有一定任意性。
3.7 实时交易
目前已经创建了一个盈利的交易策略、训练了代理来进行合理交易、并确保了该策略对新数据集的“通用化能力”,剩下的就是利润了。使用实时交易(如CCXTExchange),就可以插入策略并运行!
投机商人可能喜欢无限制地运行同一个策略,但是风险厌恶程度高的投资者也可以使用trade_callback,在每次策略要交易时调用。此回调函数与上一环节的函数类似,将传入包含代理整体性能的数据帧,并返回一个布尔值。如果为真,代理将继续交易,否则,代理将停止并在会话期间返回其性能。
import ccxtfrom tensortrade.environmentsimport TradingEnvironment
from tensortrade.strategies import StableBaselinesTradingStrategy
from tensortrade.exchanges.live import CCXTExchangecoinbase =ccxt.coinbasepro(...)exchange = CCXTExchange(exchange=coinbase,
timeframe='1h',
base_instrument='USD',
feature_pipeline=feature_pipeline)environment =TradingEnvironment(exchange=exchange,
action_strategy=action_strategy,
reward_strategy=reward_strategy)strategy.environment =environmentstrategy.restore_agent(path="../agents/ppo_btc/1h")live_performance= strategy.run(steps=0, trade_callback=episode_cb)
输入steps=0指示策略运行,否则停止运行。
综上,使用简单的组件和深度强化学习构建复杂的交易策略非常简单。那还在等什么?现在开始动手实践吧,挖掘TensorTrade的更多可能。
4. 前景
该框架目前处于早期阶段。现在的重点是获得一个产品原型,以及所有必要的积累,以期创建高利润战略。下一步是绘制未来蓝图,决定未来的哪些构件可以对社区的发展起到重要作用。
不久,我们将看到框架中添加的高度可视化的交易环境信息,更多有深度的交易策略和训练策略。
之前创建的环境可视化示例。
TensorTrade潜力无限。基础工作(即框架)已经奠定,现在由社区来决定下一步的方向。希望你能参与其中。
结语
TensorTrade是一个强大的框架,能够构建高度模块化、高性能的交易系统。它使用的新交易和投资策略相当简单和容易,同时允许在一个策略中使用另一个策略中的组件。但不要完全照着我的思路来,你也可以创造一个属于自己的策略,开始训练你的机器人,发挥其无限潜能。
这个项目非常实用。不过,个人的时间有限,我相信各位都可以为开源代码库做出宝贵的贡献。因此,如果你是对构建最先进的交易系统感兴趣的开发人员或数据科学家,非常欢迎参与,即使只是一个简单的测试用例!


留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)
