

使用nodejs,express,koa各实现一次爬虫实战。
三个项目代码放到了github上,可以直接下载运行。
node爬虫
- 安装爬虫利器
- superagent和cheerio 本文不作介绍。
npm i superagent cheerio --save
- 确定爬虫页面:bbs.tianya.cn/list-45-1.s…
- 分析页面dom结构
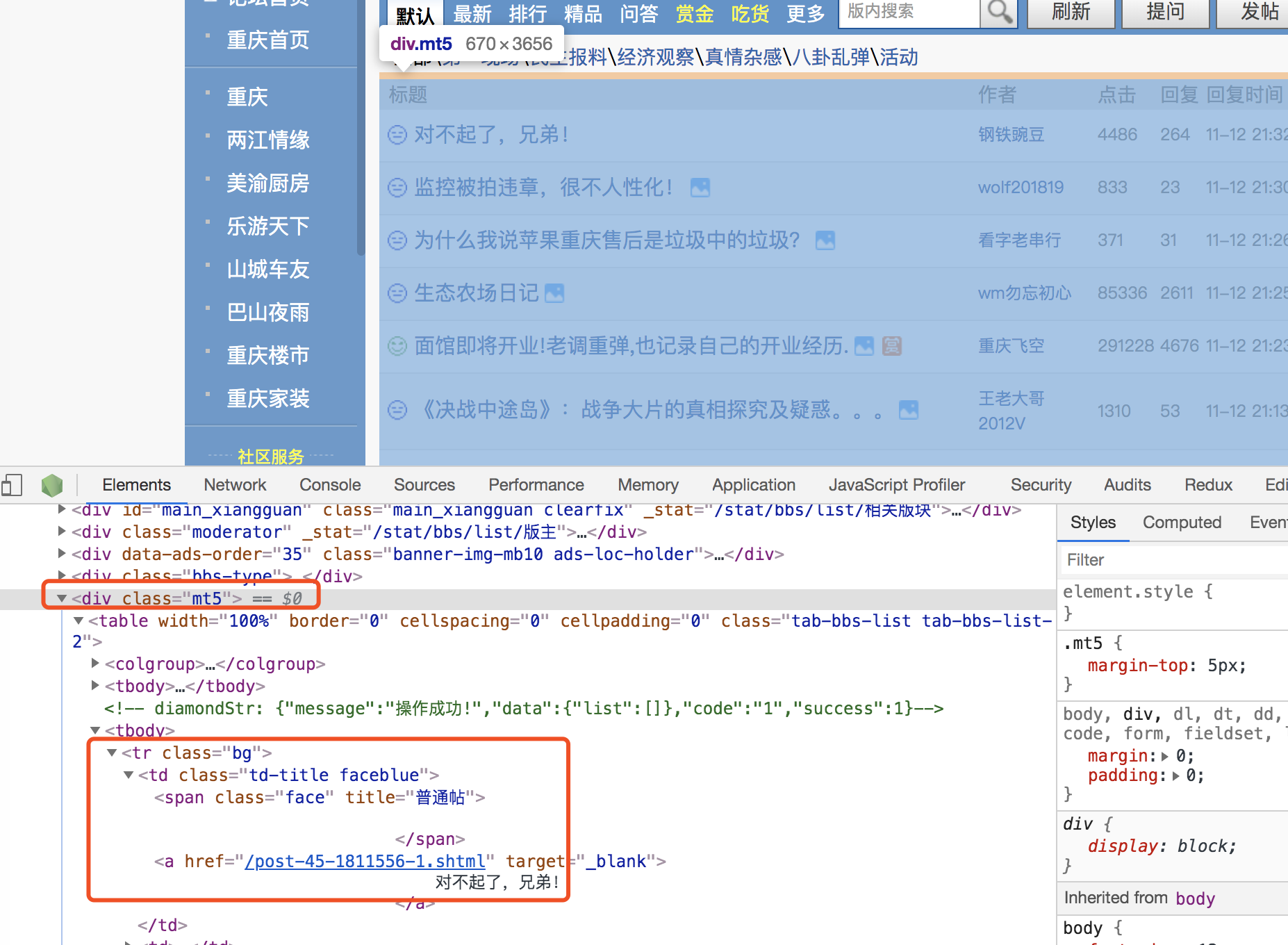
- 看出每个标题都是在class为mt5下的tr下面,所以遍历.mt5下的tr
$('.mt5 table tbody tr').each((index, item) => { let _this = $(item) //根据页面判断是否是文章 if ($(_this.children()[0]).hasClass('td-title')) { //对数据进行存储 let obj let title = $(_this.find('.td-title')).find('span').next().text() // let text = $(_this.find('a')[0]).text() //另一种选择器 let type = $(_this.find('.td-title')).find('.face').attr('title') let goto = $(_this.find('.td-title')).find('span').next().attr('href') let author = $(_this.children()[1]).text() let point = $(_this.children()[2]).text() let time = $(_this.children()[3]).text() obj = { title: title, type: type, url: mainUrl + goto, author: author, point: point, time: time } if (obj.title != "") { //判断如果有内容,则推送到data中 data.push(obj) } } })- 把数据当到data目录下
express爬虫
- 安装包
npm install express superagent cheerio superagent-charset --save
- 确定爬虫页面:www.qqtn.com/
- 分析页面结构
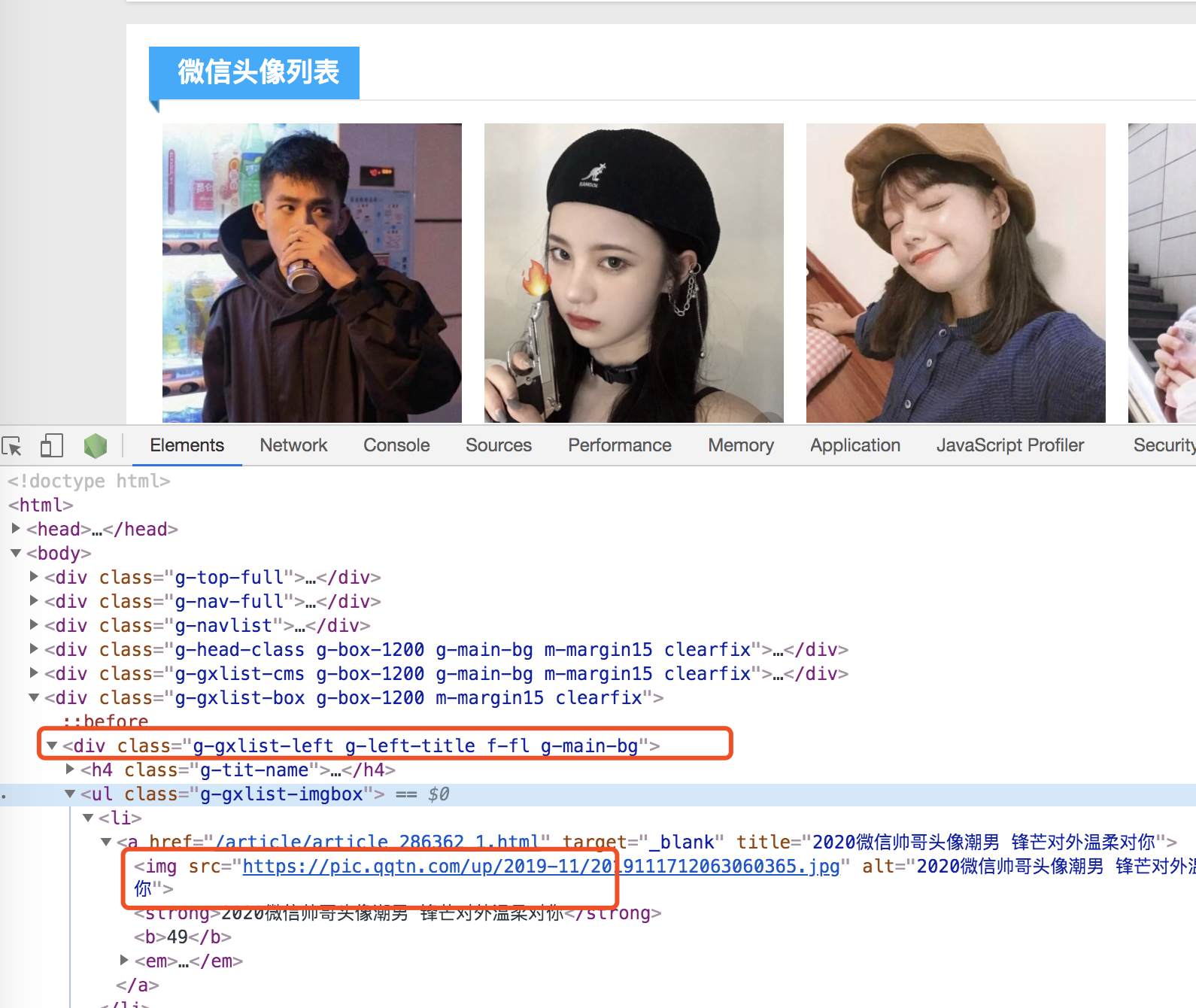
- 看出每个标题都是在div.g-main-bg ul.g-gxlist-imgbox li a下面,进行遍历
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
- 把数据items存到img.json中
fs.access(path.join(__dirname, '/img.json'), fs.constants.F_OK, err => {
if (err) { // 文件不存在
fs.writeFile(path.join(__dirname,'/img.json'), JSON.stringify([
{
route,
items
}
]), err => {
if(err) {
console.log(err)
return false
}
console.log('保存成功')
})
} else {
fs.readFile(path.join(__dirname, '/img.json'), (err, data) => {
if (err) {
console.log(err)
return false
}
data = JSON.parse(data.toString())
let exist = data.some((page, index) => {
return page.route == route
})
if (!exist) {
fs.writeFile(path.join(__dirname, 'img.json'), JSON.stringify([
...data,
{
route,
items
},
]), err => {
if (err) {
console.log(err)
return false
}
})
}
})
}
res.json({ code: 200, msg: "", data: items });
})
koa爬虫
- 安装
npm i koa koa-router cheerio superagent --save
- 确定爬虫页面:www.freebuf.com/
- 分析页面结构
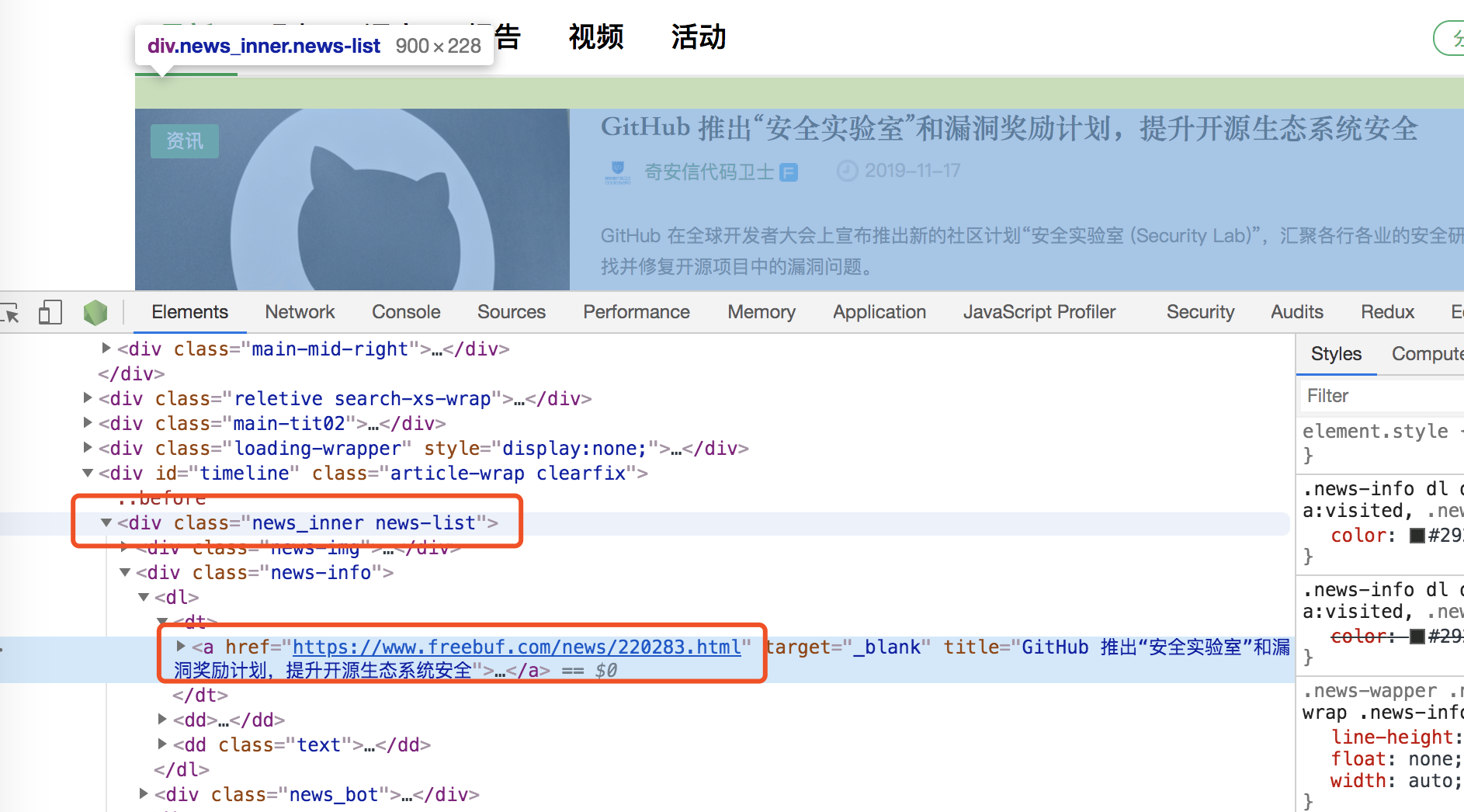
- 遍历div .news-list .news-info dl dt a
$('div .news-list .news-info dl dt a').each((index, ele) => {
data.push({
title: $(ele).attr('title'),
href: $(ele).attr('href')
})
})
- 把数据添加到data.json中
fs.access(path.join(__dirname, 'data.json'), err => {
if (err) {
fs.writeFile(path.join(__dirname, 'data.json'), JSON.stringify([
{
data
}
]), err => {
if (err) {
return;
}
})
} else {
fs.readFile(path.join(__dirname, 'data.json'), (err, res) => {
data = res.toString()
if (err) {
return;
}
})
}
})
以上把node,express,koa都简单的实现了爬虫,面对复杂的页面,还需要不断的学习其他技术。
上面三个项目代码放到了github上,可以直接下载运行。
如果对你有帮助,欢迎star。
微信公众号:

