

- Class内部结构中有个方法缓存(cache_t),用
散列表(哈希表)来缓存曾经调用过的方法,可以提高方法的查找速度。
struct cache_t {
struct bucket_t *_buckets; //散列表 (bucket_t, ...)
mask_t _mask; //散列表的长度 - 1
mask_t _occupied; //已经缓存的方法数量
};
|
|
struct bucket_t {
cache_key_t _key; // SEL作为Key
IMP _imp; //函数的内存地址
};
- 缓存查找:
bucket_t * cache_t::find(cache_key_t k, id receiver)
散列表(哈希表)
散列表找元素的原理:
f(key) = index- 通过一个函数,传入一个
key,算出一个索引index。 - 如果这个索引冲突了,那就通过
+ 1、- 1或某个算法再算一遍,直到不冲突为止。
应用
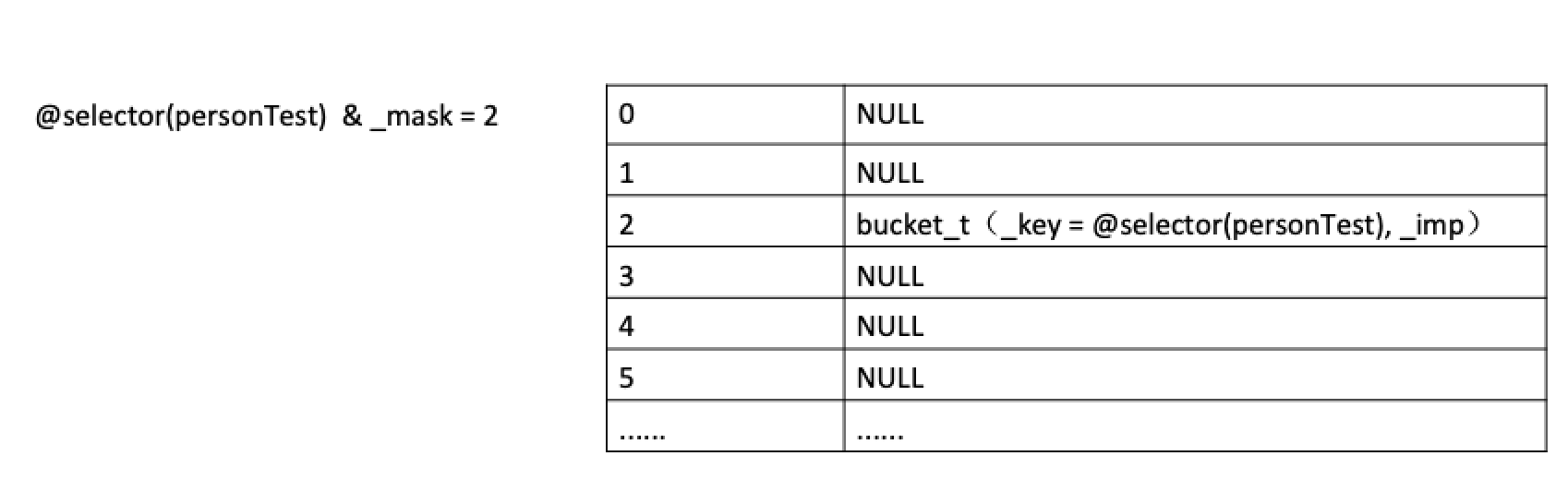
- 在存储
bucket_t时,将这个_key&_mask得到一个值,方法就存在相应的位置; - 取方法时,也是直接
_key&_mask,去对应的值里取bucket_t;
static inline mask_t cache_hash(cache_key_t key, mask_t mask)
{
return (mask_t)(key & mask);
}
- 由图表看到好多空间没有使用到,故,这是一种牺牲空间使用效率,来换取查询效率的方法。
如_key&_mask的结果和之前的重复了怎么办 ?
即: _key&_mask 之后,该位置上已经有bucket_t了或者取出来的bucket_t的_key对不上。
解决:
以存为例:
- 得出的值,位置有
bucket_t; - 值
- 1,如果还有,继续-1; - 值 =
0,就直接等于mask(mask == 散列表的长度 - 1)。
static inline mask_t cache_next(mask_t i, mask_t mask) {
return i ? i-1 : mask;
}
如果方法过多,散列表原来的长度不够了怎么办?
- 扩容为原来空间的2倍;
- 将原缓存清空。
void cache_t::expand()
{
cacheUpdateLock.assertLocked();
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE; // 2倍
.........
reallocate(oldCapacity, newCapacity); //里面有个" cache_collect_free(oldBuckets, oldCapacity);"
}
